

Author: Ben Sanders
Translator: Wu Huicong
Proofreader: Zheng Zi
This article contains approximately 2400 words, and it is recommended to read in 10 minutes.
This article will briefly introduce what machine learning is, how it works, and two main algorithms in machine learning.
Introduction
In this article, Greg Lamp, co-founder of the data science startup Yhat and currently co-founder and CTO of Waldo, will share his insights on machine learning for us beginners.

Table of Contents
1. What is Machine Learning?
-
Machine learning is a melting pot of knowledge – there is nothing new.
2. How Does Machine Learning Work?
3. Machine Learning Algorithms: Classification and Regression
-
Introduction to algorithms
-
Overfitting
4. What is TensorFlow?
5. Why is Machine Learning So Popular?
1. What is Machine Learning?
I define machine learning as using data to find data models. This mainly involves two key concepts:
-
Using knowledge of mathematics and statistics to optimize models;
-
This optimization process is called training.

The internet’s portrayal of machine learning
A potentially unpopular opinion is coming.
Artificial intelligence and machine learning are the same thing.
Indeed, machine learning and AI are essentially the same, but it is often overstated. When my marketing colleagues talk about artificial intelligence, they think it might eventually evolve to dominate humanity. I agree with this view. This is indeed a good summary of machine learning, as it can learn from any input data.
Furthermore, there is potential for AI to develop in the future.

The internet’s portrayal of artificial intelligence. Look, how similar it is.
-
There is nothing new.
I think the most interesting aspect of machine learning is that it does not really introduce new knowledge. The popular machine learning algorithms have been around for some time. The biggest change in machine learning during this period is that computers have become:
-
Faster
-
Cheaper
-
More convenient
Because of these three developments in computers and the continuous expansion and ease of use of machine learning libraries, such as scikit-learn, TensorFlow, and R (a commonly used language for statistical machine learning), more and more people are getting involved in machine learning. Accessibility, in limited usage, in turn promotes dissemination.
2. How Does Machine Learning Work?
Different algorithms can be used in machine learning to find data models. Although these algorithms all do the same thing: read data and assign weights to this data. These weights can be used to predict future data of the same form.
In recent years, there has been a significant leap in data reading in machine learning, and the strict constraints on algorithms for reading data have been relaxed. However, fundamentally all algorithms require concise and consistently formatted data to improve computational efficiency.
Now, when these algorithms need to train and calibrate, it essentially requires finding the minimum distance between a set of points. Let’s look at the diagram for clarity.
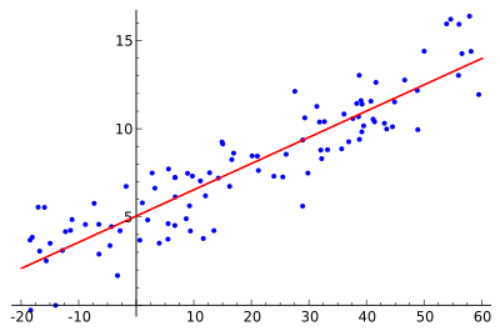
The above diagram is a classic example of Simple Linear Regression. The blue points represent the data you want to predict. The red line represents the “best fit line,” which is the line that best represents the features of the dataset in the machine learning algorithm (in the case of linear regression).
You can use this line to predict future observations.
3. Classification and Regression
I know what my readers are thinking; next, I might talk about TensorFlow and how to use it to fulfill your wildest hopes and dreams while making the business profitable. But you might be mistaken.
The following will outline the two main algorithms in machine learning.
The vast majority of machine learning tasks fall into two categories:
-
Regression: Predicting a numerical value (e.g., price or failure time)
-
Classification: Predicting the category of something (dog/cat, good/bad, wolf/cow)
In regression, you are trying to compute a line that will lie “in the middle” of all the data points (as shown above). In classification, you are trying to compute a line that will “classify” the data points.
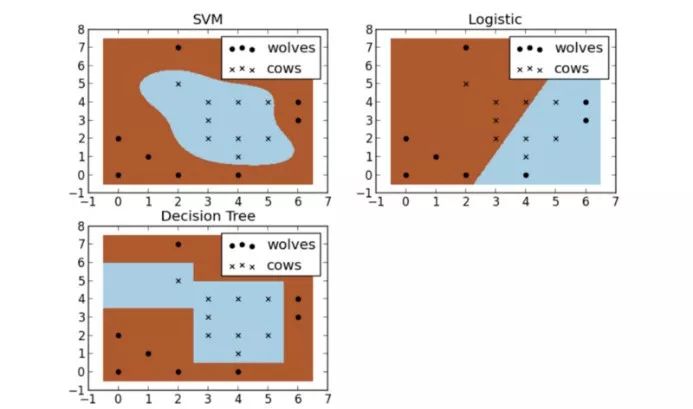
-
Introduction to Algorithms
This is the coolest part. Different algorithms can use different shapes, numbers, and types of lines to compute the middle line or separating line. For example, in the above wolf and cow example, there are three different algorithms used to separate each category. As you can see, the support vector machine (SVM) method is non-linear, which means it does not have to use a straight line. However, when using the logistic regression method, because it is linear, it can only separate data points with a straight line. The third example is the decision tree, which uses a set of automatically generated rules to separate categories.
So why can’t we just use the most complex method?
-
Overfitting
Now is still not the time to talk about TensorFlow.
Well, sometimes your model might be too smart. I know it seems like a step backward, but it’s true. The model is indeed correct. Your AI model might be very good at understanding the dataset you show it. Therefore, it becomes inaccurate for predicting the future.
For example, in product management, if you talk to a customer who says they won’t buy your product unless the button is cyan because that’s the lovely cyan shade used in their logo and branding.

Cyan button
If you are a bad product manager, you might listen to that customer and make all your website buttons cyan. That’s overfitting.
But you are not a bad product manager. You know that while this customer may not purchase your product because of the lack of a cyan button, you also know that many other customers would not be dissatisfied with the button color. This is because you have an inherent mental model of what typical customers care about.
4. Are You Going to Talk About TensorFlow?
Well, now let’s talk about TensorFlow. TensorFlow is a machine learning library produced by Google. However, it is not that easy to use. You need to know what you are doing to get a higher return on investment compared to using simpler libraries (like scikit-learn).

TensorFlow indeed does a great job of providing a simple and intuitive way to define and train neural networks. Neural networks are another type of algorithm used to compute lines. Neural networks and their cousins, deep neural networks, are user-friendly methods because they can handle unstructured data (like images, videos, etc.). I say that data is unstructured because ultimately they are still input into the algorithm in a tabular format. You don’t have to worry too much about the precision and purity of the data. Very easy to use!
5. Why is Machine Learning So Popular?
Learning machine learning is no longer difficult because it has a rich library. If you can’t see the difference in libraries, I really like using Scikit-learn. There are many reasons:
-
You don’t need to write a lot of code when using it;
-
It can implement most or some machine learning functions, so anything I do related to machine learning can be done without leaving this library;
-
It’s old, which means its functionalities are mature, and mature functionalities mean you won’t have to deal with those brain-damaging code errors;
-
The creators and maintainers have very kindly established excellent usage instructions;
-
If I have to listen to a lecture on machine learning, I prefer those like Olivier Grise, who brings a slight French accent to add entertainment value.

My French enthusiasts who love machine learning can reduce a very complex machine learning model to 5 lines of code using scikit-learn. Programming machine learning does not require many lines of code. You don’t need a PhD in astrophysics or even a technical degree background to learn about machine learning.
Here’s an example of code using Random Forest:
from sklearn.ensemble import RandomForestClassifier # Importing the Random Forest libraryclf = RandomForestClassifier() # clf is the random forest classification functiontarget_variable = 'does-make-more-than-50k' # target_variable is the standard for random forest classificationcolumns = ['age', 'education', 'hours-worked-per-week'] # Nodes of the random forestclf.fit(df[columns], df[target_variable]) # Forming the treeOriginal Title:
Machine Learning for People Who Don’t Care About Machine Learning —— AI vs. ML explained for the rest of us
Original Link:
https://towardsdatascience.com/machine-learning-for-people-who-dont-care-about-machine-learning-4cf0495dee2c
Translator’s Profile

Wu Huicong, a graduate of Dalhousie University in Canada with a double major in Computer Science and Statistics, focusing on data science. Preparing to pursue a Master’s in Data Analysis (AI direction). Highly sensitive to numbers, skilled in various data models and analysis, hoping to go further in the field of data science, and eager to meet more like-minded friends.
Translation Team Recruitment Information
Job Description: Accurately translate selected cutting-edge foreign articles into fluent Chinese. If you are an international student majoring in data science/statistics/computer science, or working overseas in related fields, or confident in your foreign language skills, the Datapi translation team welcomes you to join!
What You Will Gain: Improve your understanding of cutting-edge data science, enhance your awareness of foreign news sources, and overseas friends can stay connected with domestic technological applications. The academic and research background of the Datapi team provides good development opportunities for volunteers.
Other Benefits: Collaborate and communicate with data scientists from well-known companies and students from prestigious universities such as Peking University and Tsinghua University.
Click the end of the article “Read the Original” to join the Datapi team~
Reprint Notice
If you need to reprint, please indicate the author and source prominently at the beginning (transferred from: 数据派THU ID: DatapiTHU), and place the prominent QR code of Datapi at the end of the article. If there are original marked articles, please send [Article Name – Awaiting Authorization Public Account Name and ID] to the contact email to apply for whitelist authorization and edit as required.
After publication, please provide the link feedback to the contact email (see below). Unauthorized reprints and adaptations will be legally pursued.


Click “Read the Original” to embrace the organization