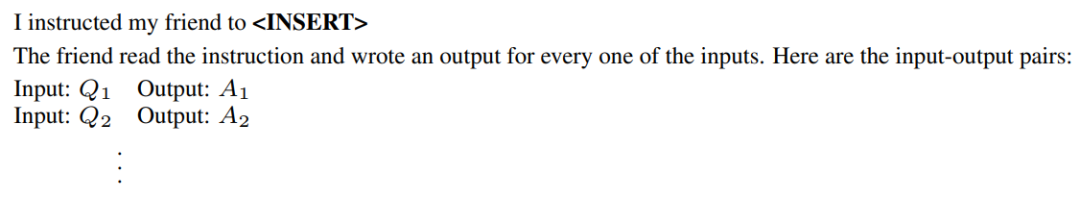MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP master’s and doctoral students, university teachers, and corporate researchers.Community Vision is to promote communication and progress between the academic and industrial circles of natural language processing and machine learning, especially for the progress of beginners.Reprinted from | Xixiaoyao’s Cute Selling HouseAuthor | IQ Dropped All Over
Recently, the most talked-about topic in the NLP field is Prompt, especially when combined with large language models (LLM), which has brought us closer to the application field. When LLM demonstrates extraordinary performance and versatility across various tasks, including few-shot learning, there is still a pressing question to be solved: How to make LLM perform according to our requirements? This is also an important starting point for this paper.
The author views LLM as a black-box computer executing programs specified by natural language instructions and studies how to use model-generated instructions to control LLM’s behavior. Inspired by classical program synthesis and artificial prompting engineering methods, the author proposes the Automatic Prompt Engineer (APE) for automatic instruction generation and selection, treating instructions as “programs” and optimizing them by searching the candidate instruction pool proposed by LLM to maximize the selected scoring function.
Through experimental analysis of 24 NLP tasks, the author points out that automatically generated instructions significantly outperform previous LLM baselines, and the prompts designed by APE can be used to guide model authenticity and information content, as well as improve few-shot learning performance by simply presetting them as standard context learning prompts.
Paper Title: Large Language Models are Human-Level Prompt Engineers
Paper Link: https://openreview.net/pdf?id=92gvk82DE-
1
Exploring Problems
The versatility and outstanding performance of large models on various tasks have attracted widespread attention, while research on guiding large models in the desired direction is ongoing. Recent works have considered fine-tuning, in-context learning, and various forms of prompt generation, including differentiable tuning of soft prompts and natural language prompt engineering, which has sparked public interest in prompt design and generation.
For example, in recent years, large models with natural language interfaces, including those for text generation and image synthesis, have been increasingly used by the public. As finding the right prompt can be challenging, many guides on prompt engineering and tools to help discover prompts have been developed, with links as follows:
Behind the public’s interest lies the fact that simple language prompts do not always yield the expected results, even if these results can be generated by other instructions.
Therefore, due to the lack of knowledge about the compatibility of instructions with specific models, users must try various prompts to guide LLM towards the desired behavior. We can understand this by viewing LLM as a black-box computer executing programs specified by natural language instructions: while they can execute a wide range of natural language programs, the way these programs are processed may not be intuitive to humans, and their quality can only be measured when these instructions are executed in downstream tasks.
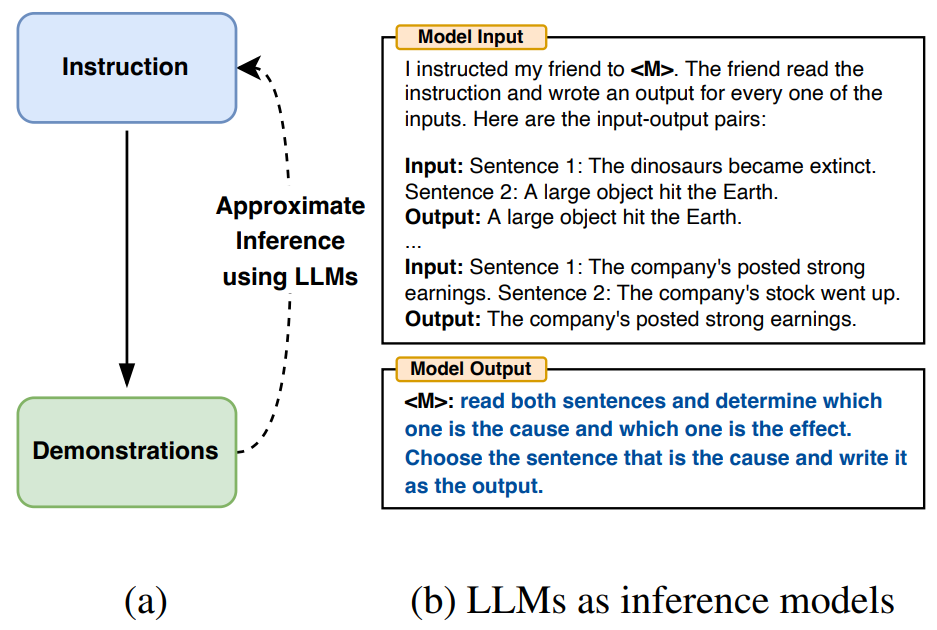
Thus, to reduce the manual costs involved in creating and validating effective instructions, the author proposes to use the Automatic Prompt Engineer (APE) algorithm to generate effective instructions to guide LLM, that is, natural language program synthesis, as shown in the following diagram (a), treating it as a black-box optimization problem and using LLM to generate and search for feasible candidate solutions.
▲ Figure 1 Using LLM as a reasoning model to fill in the blanks
The author will leverage LLM’s general capabilities in three ways:
First, based on a small set of “input-output pairs,” use LLM as a reasoning model to generate candidate instructions, as shown in the above diagram (b), using LLM as a reasoning model to fill in the blanks. This algorithm involves searching for candidate instructions proposed by the reasoning model.
Second, guide the search process by calculating a score for each instruction under the LLM to be controlled.
Finally, propose an iterative Monte Carlo search method, where LLM improves the best candidate instructions by proposing semantically similar instruction variants.
In summary, the algorithm requires LLM to generate a set of candidate instructions based on examples, and then evaluate which ones are more effective. That is, automatically generating instructions for tasks specified by output examples: generating several candidate instructions through direct reasoning or a recursive process based on semantic similarity, executing them with the target model, and selecting the most suitable instruction based on the computed evaluation score.
2
Algorithm Introduction
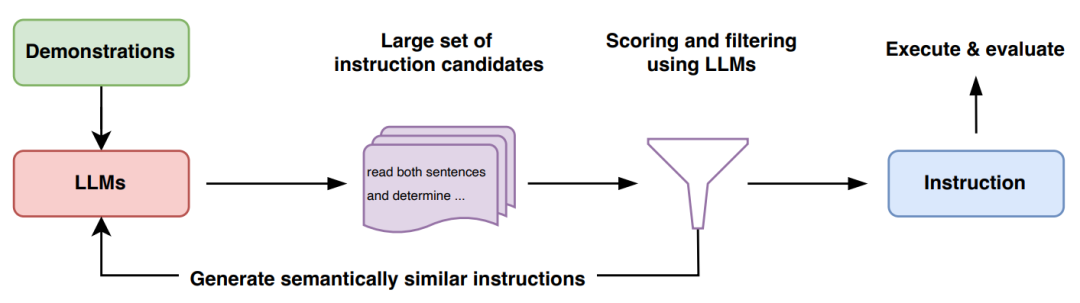
For a dataset containing input-output examples sampled from the population and a task specified by a prompt model, the goal of natural language program synthesis is to find an instruction such that when using the instruction and the given input concatenation as a prompt, it produces the corresponding output. That is, framing it as an optimization problem to find the instruction that maximizes the expected score of each sample over possible outcomes:The algorithm APE uses LLM in both the proposal and scoring key modules. As shown in the diagram and Algorithm 1, APE first proposes several candidate prompts, and then filters and refines the candidate set based on the selected scoring function, ultimately selecting the highest-scoring instruction.▲ Figure 2 Automatic Prompt Engineer (APE) Method▲ Algorithm 1 Automatic Prompt Engineer (APE)
Initial Proposal Distribution
Due to the infinite search space, it is challenging to find the correct instruction, which has always been a difficulty in natural language program synthesis. The author considers using a pre-trained LLM to find a good candidate set to guide the entire search process. Although random samples from LLM are unlikely to produce the desired pair, it can allow LLM to infer the most likely high-scoring instruction under given input/output examples, i.e., approximately sample from .There are two methods to generate high-quality candidates from :First, a method based on a “forward” mode generation is adopted, translating this distribution into words. For instance, using the method in the following diagram to prompt LLM:
This indicates that the output is generated based on the instruction, thus its scoring function will be high. Although the “forward” model is out-of-the-box for most pre-trained LLMs, converting into words requires customized engineering across different tasks. This is because the “forward” model generates text from left to right, while we want the model to predict the missing context before the demonstration.To address this issue, “backward” mode generation was also considered, which uses LLMs with filling capabilities (like T5 and InsertGPT) to infer the missing instructions. The “backward” model samples directly from by filling in the blanks, making it a more general approach than the “forward” model. As shown below:
Scoring Function
To transform the problem into a black-box optimization, a scoring function is selected that can accurately measure the alignment between the dataset and the data generated by the model. In the TruthfulQA experiment, the focus is mainly on the automated metrics proposed by predecessors, similar to execution accuracy. In each case, the quality of the generated instructions is evaluated using equation (1), calculating the expected value over the test set .
Execution Accuracy. The execution accuracy matrix proposed by Honovich et al. is used to evaluate the quality of instruction , represented as . In most cases, execution accuracy is simply defined as 0-1 loss, while in certain tasks, invariants are considered.
Log Probability. A scoring function that leans more towards soft probabilities is further proposed, assuming it may improve optimization by providing more granular signals when searching for low-quality candidate instructions. This considers the log probability of the expected answer given the instruction and question under the target model , based on each sample .
Effective Score Estimation. Estimating the score overhead by calculating the scores of all candidate instructions over the entire training set is computationally expensive. Therefore, a filtering scheme is also adopted here to allocate computational resources such that promising candidates receive more while low-quality ones receive less, which can be achieved by using a multi-stage computational strategy in lines 2-9 of Algorithm 1. First, evaluate all candidates using a small portion of the training set, and for candidates with scores above a certain threshold, sample from the training set and evaluate a new non-overlapping subset to update the moving averages of scores, then repeat this process until a small portion of candidates remains, and evaluate them over the entire training set. This adaptive filtering scheme maintains the precise computational costs of high-quality samples while significantly reducing the computational costs of low-quality candidates, thus significantly improving computational efficiency.
Iterative Proposal Distribution
Although the intention is to sample directly from high-quality initial candidate instructions, it may occur that the aforementioned methods do not yield a good proposal set (either due to lack of diversity or not containing any candidates with suitable high scores). Therefore, the author further investigates the iterative process of re-sampling .Iterative Monte Carlo Search. Consider local exploration of the search space around the current best candidates, rather than sampling solely from the initial proposal, this can generate new instructions that are more likely to succeed, which the author refers to as Iterative APE. At each stage, a set of instructions will be evaluated, and lower-scoring candidates will be filtered out, then LLM is asked to generate new instructions similar to the high-scoring ones. The LLM re-sampling is used here, and the prompt to the model is as follows:Experimental results show that although this method improves the overall quality of the proposal set, the highest-scoring instructions tend to remain unchanged as the stages increase, thus iterative generation provides marginal improvements compared to the relative simplicity and effectiveness of the generation process described earlier. Unless otherwise stated, the subsequent experiments will use APE without iterative search.
3
How Does APE Guide LLM?
This will be studied from three perspectives: zero-shot performance, few-shot performance, and authenticity.
Instruction Induction
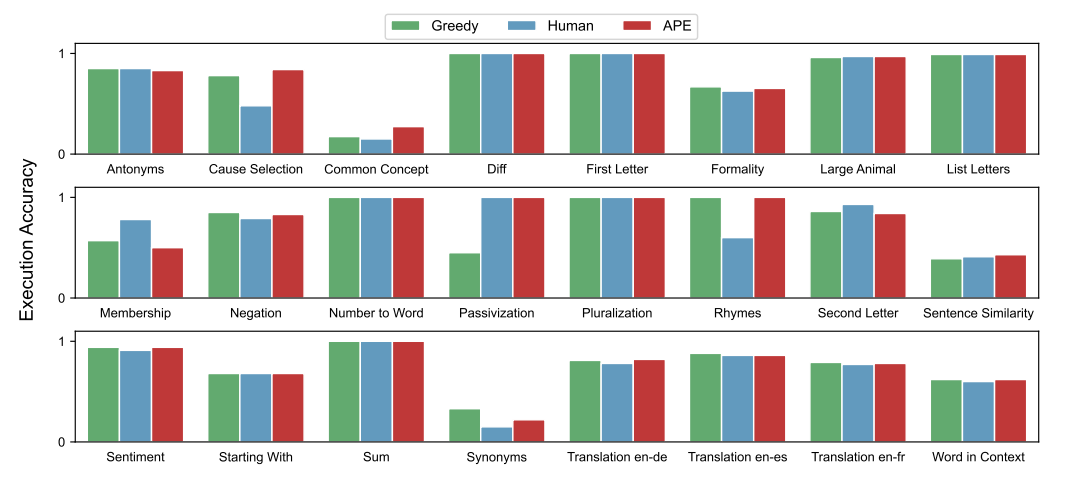
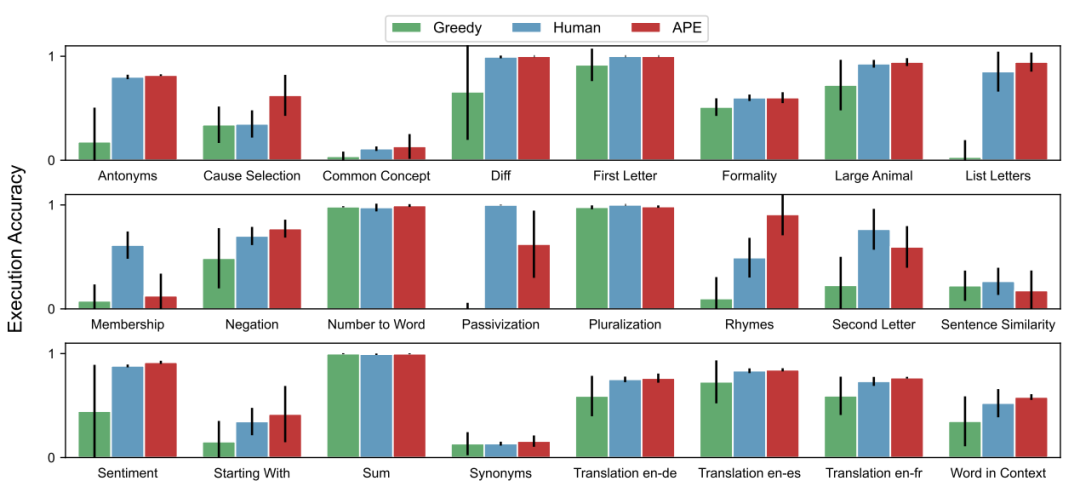
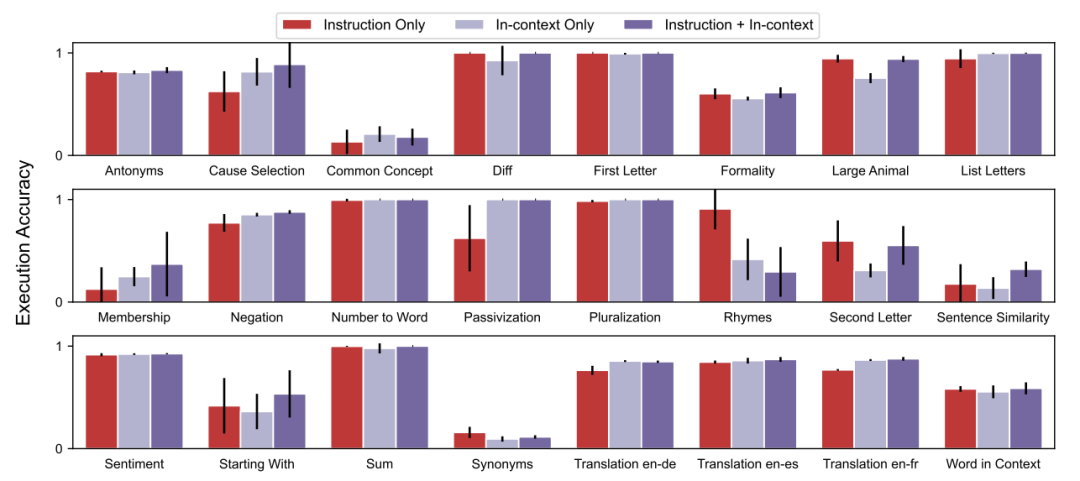
The author evaluates the effectiveness of zero-shot and few-shot context learning on 24 instruction induction tasks proposed by predecessors, covering many aspects of language understanding from simple phrase structures to similarity and causal relationship recognition. For each task, 5 input-output pairs are sampled from the training data, and the best instructions are selected using Algorithm 1, then their quality is evaluated by executing the instructions on InstructGPT, repeating the experiment 5 times with different random seeds, obtaining the average and standard deviation of the best performance results in each case as shown in the following diagram. In 24 tasks, APE achieved human-level performance in 21 tasks.▲ Figure 3 Zero-shot test accuracy of the best executing instruction across 24 instruction induction tasksZero-shot Learning. Here, the author compares the method of this paper with two baselines: human prompt engineers and greedy model-generated instruction algorithms. As shown in the following diagram, in 24 tasks, 19 achieved human-level performance, with some tasks even outperforming human-generated instructions.▲ Figure 4 Zero-shot test accuracy on 24 instruction induction tasksHowever, the comparison of the above two diagrams shows that different combinations of context examples can lead to significantly different results, which also demonstrates the importance of generating candidate instructions based on different examples in the initial proposal phase.Few-shot Context Learning. The author evaluates the instructions generated by APE in a few-shot context learning scenario (inserting instructions before context examples), represented in the following diagram as “instruction + context.” In 21 out of 24 tasks, adding instructions yields test performance comparable to or better than standard context learning performance. Contrary to intuition, adding context examples for Rhymes, Large Animals, and Second Letters reduces the model’s performance.▲ Figure 5 Accuracy of few-shot context tests on 24 instruction induction tasks
TruthfulQA
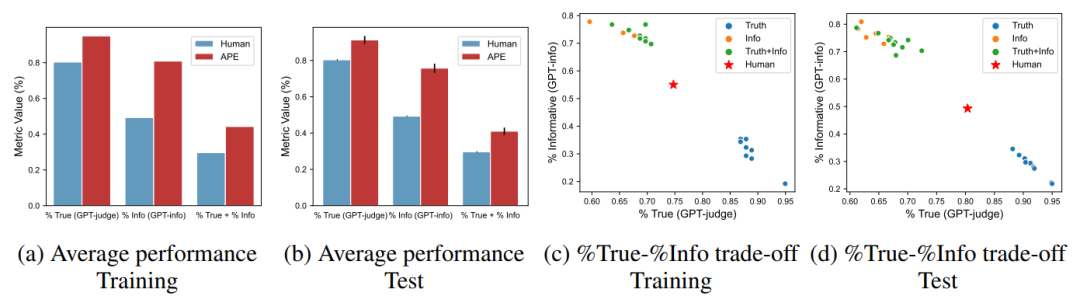
The author applies the method of this paper to TruthfulQA to understand how the instructions generated by APE guide LLM to generate answers of different styles and study the trade-off between authenticity and information content. With the metrics in the original paper, APE is used to learn instructions that maximize three metrics: authenticity (% True), information content (% Info), and a combination of both (%True + %Info). The authors of the original paper used human evaluation to assess model performance, but they found that automated metrics align with human predictions over 90% of the time. In this paper’s experiments, the author relies on the previously fine-tuned GPT-judge and GPT-info to evaluate scores.TruthfulQA Prompt Engineering. Unlike instruction induction, the author aims to find an optimal prompt instruction that performs well across all 38 categories of questions covering health, law, politics, and fiction. Moreover, all the generated instructions are general and do not contain any examples from the dataset.▲ Figure 6 Comparison of APE with “help” (human) prompts in the TruthfulQA taskTrade-off Between Authenticity and Information Content. When APE proposes only 200 candidate prompts in InstructGPT, it outperforms human prompt engineering. The author compares the generated prompts with the “help” (human) prompts from the original TruthfulQA paper, showing that the top 10 selected from 200 candidates can generalize well to the test set, demonstrating the average performance of the top 10 instructions across the three metrics. However, the author notes that the instructions found by APE can achieve high authenticity when answering questions like “No comment,” but provide little information, thus further investigating the trade-off between authenticity and information, visualizing the top 10 samples from three metrics on the authenticity-information graph shown below. Although APE achieves over 40% accuracy in providing answers for authenticity and information content, the instructions found tend to be at the extremes of this %true-%info Pareto boundary.
4
Quantitative Analysis
The author conducts a quantitative analysis to improve the three main components of this method: proposal distribution, scoring function, and iterative search.
LLM for Proposal Distribution and Scoring
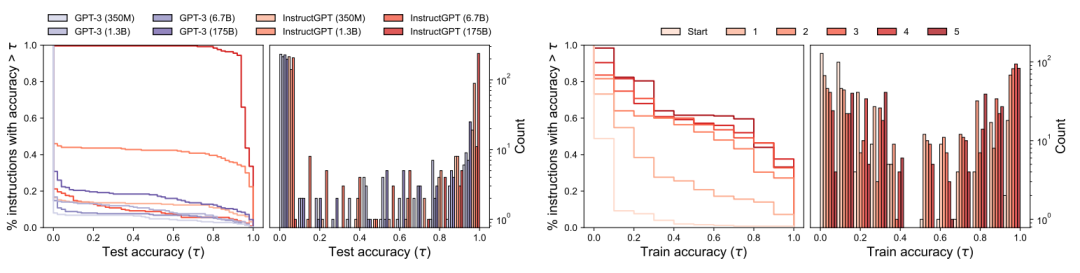
1. How does the quality of proposals change with increasing model size? To understand how model size affects the quality of the initial proposal distribution, this paper studies 8 different models. For each model, 250 instructions are generated, and execution accuracy is calculated on 50 test data to assess the quality of the proposal distribution. We visualize the survival function (percentage of instructions with test accuracy above a certain threshold) and the histogram of test accuracy for a simple task in the following diagram (a). As shown in both diagrams, larger models tend to produce better proposal distributions than smaller ones, and models fine-tuned to follow human instructions also exhibit this trend. In simple tasks, all instructions generated by the best model InstructGPT have reasonable test accuracy, in stark contrast to half of the instructions deviating from the topic and performing poorly in execution accuracy.
▲ Figure 7 Evaluation of proposal distribution quality of different-sized models through test execution accuracy
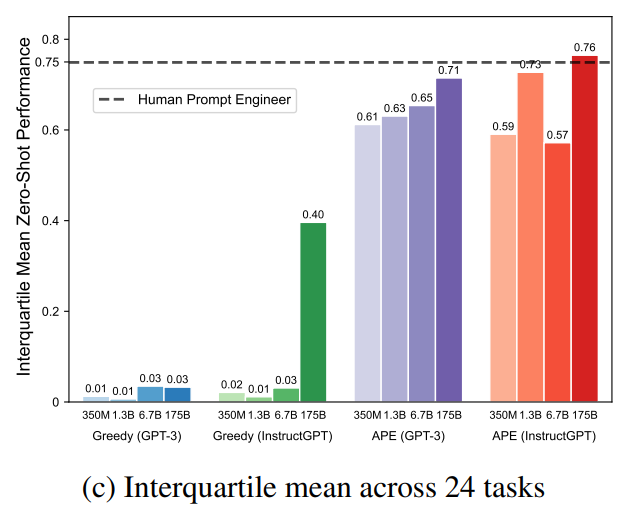
2. Is the quality of proposals important in selection?
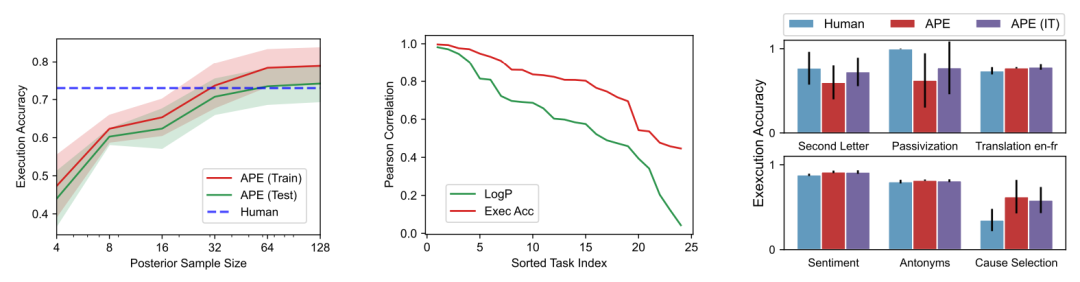
▲ Figure 8 Quartile means of 24 tasks, showing APE exceeding human performance when using InstructGPT modelThe more instructions sampled from LLM, the more likely it is to find better ones. To verify this hypothesis, the author increased the sample size from 4 to 128 and evaluated the changes in test accuracy. The left diagram shows a monotonically increasing trend where 64 instruction samples achieve human-level performance, with diminishing returns, choosing 50 as the default sample size. In this configuration, the impact of proposal distribution on the test accuracy of the best instructions selected by the algorithm is studied. The diagram shows that although small models have low chances of generating good instructions, if enough candidates are sampled, some good instructions will still be produced. Therefore, by running the selection algorithm proposed in this paper, potential instructions can still be found in a small model, which also explains why the method in this paper significantly outperforms greedy methods across the 8 models.
3. Which scoring function is better? The author calculates the correlation between test accuracy and the two proposed metrics on 24 instruction induction tasks to study how the proposed metrics perform. Using InstructGPT in the “forward” mode, 250 instructions are generated for each task, and the metric scores and test accuracy are calculated for 10 test data. Here, the Pearson correlation between test accuracy and the two metrics is visualized, showing that execution accuracy aligns better with test performance across tasks, thus it is chosen as the default metric.
▲ Figure 9
Iterative Monte Carlo Search
Can iterative search improve instruction quality? The author visualizes the survival function and test accuracy histogram for the “Passivization” task in Figure 7 (right). The survival graph shows that the curve increases with the number of rounds, indicating that iterative search indeed generates higher quality proposal sets. We observe diminishing returns in further selection rounds, as quality seems to stabilize after three rounds.
Does this paper need iterative search? The author compares APE and iterative APE on 6 tasks. As shown in Figure 9, iterative search slightly improves performance on tasks where APE does not perform as well as humans, but in other tasks, the performance is nearly the same. This aligns with the previous hypothesis that iterative search is most useful for generating good initial instructions in challenging tasks.
5
Conclusion
This paper aims to reduce the manual costs involved in creating and validating effective instructions by automating the prompt engineering process as a black-box optimization problem. The author uses an efficient search algorithm guided by LLM to solve this problem. The APE method achieves human-level performance across multiple tasks with minimal human input. As large models have shown the ability to follow human instructions in recent years, many future models (including those for formal program synthesis) may have natural language interfaces, and the work in this paper may lay the foundation for controlling and guiding generative AI. However, this exploration requires the collective efforts of more people, and the road ahead is long.Technical Community Invitation
△ Long press to add assistant
Scan the QR code to add assistant WeChat
Please note: Name – School/Company – Research Direction(e.g.: Xiaozhang – Harbin Institute of Technology – Dialogue System)to apply for joining technical communities such as Natural Language Processing/Pytorch
About Us
MLNLP community is a folk academic community jointly constructed by domestic and foreign scholars in machine learning and natural language processing. It has developed into a well-known machine learning and natural language processing community both domestically and internationally, aiming to promote progress among the academic and industrial circles of machine learning and natural language processing, as well as enthusiasts.The community can provide an open communication platform for relevant practitioners’ further education, employment, and research. Everyone is welcome to follow and join us.