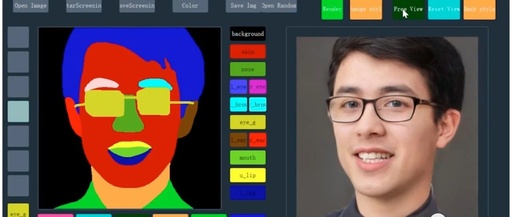
The evolution of AI is advancing at an exponential rate, evolving from recognition through photos to the ability to draw and generate dynamic images. Today, I would like to share an AI system for interactive drawing of facial images.
This is a paper shared by ACM SIGGRAPH Asia 2022, developed collaboratively by Tsinghua University, Tencent AI Lab, and ByteDance. It primarily addresses the issues of image quality and editability in face drawing, as existing systems either generate low-resolution editable results or high-quality results with no editing flexibility. In the research and development of this project, a new method that achieves the best of both worlds is proposed, consisting of an editing system with three main components:
(1) A semantically aware 3D model that associates separated facial images with semantic encoding to generate a unified image;
(2) A hybrid GAN inversion method that initializes latent encoding from semantic and texture encoders and further optimizes them for faithful reconstruction to the 3D description;
(3) A standard editor that can effectively manipulate semantic encoding in a normative view and produce high-quality editing results. This method is applicable to various applications, such as free facial drawing, editing, and sample control.
https://arxiv.org/pdf/2205.15517.pdf
https://github.com/MrTornado24/IDE-3D
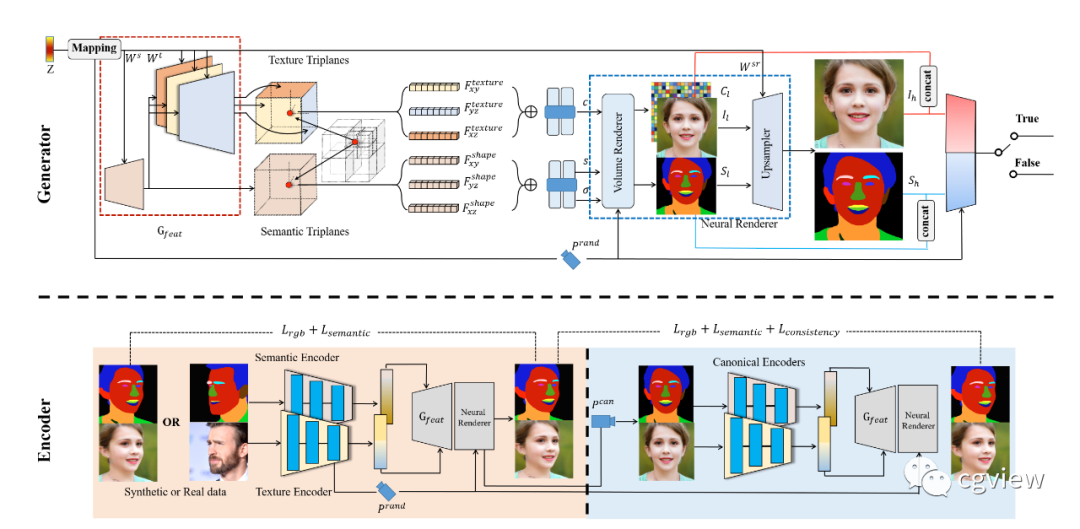
The system’s 3D generator and encoder pipeline is as follows:
The 3D generator (as shown at the top of the figure) consists of several parts: first, the StyleGAN feature generator Gfeat builds a spatial alignment of semantics and textures in an efficient tri-plane representation within 3D space. To decouple different facial attributes, shape and texture codes are injected separately into the shallow and deep layers of Gfeat. Additionally, deep designs are employed for the three parallel branches corresponding to each feature plane to reduce entanglement among them. Given the generated 3D space, RGB images and semantic encoding are jointly rendered through volume rendering and a 2D CNN-based upsampler.
The encoder (as shown at the bottom of the figure) embeds portrait images and corresponding semantic encoding into texture and semantic latent encoding through two independent encoders. With the predicted camera position, the fixed generator can reconstruct the portrait under the predicted camera position. To eliminate the perspective distortion effect of the camera position, we jointly trained a normative editor that takes portrait images and semantic masks under the normative view as input and enforces them.
————————————————–
The editor is currently committed to deeply penetrating the global film and television industry, sharing relevant film technologies from both domestic and international perspectives for everyone to learn from and improve together.WeChat ID: cg_view