Editor: Rome
Large language models have astonishing capabilities, but they often incur huge costs during deployment due to their size. Researchers from the University of Washington, in collaboration with the Google Cloud AI Research Institute and Google Research, have proposed a solution to this problem by introducing the Distilling Step-by-Step paradigm to assist model training. This method outperforms LLMs in training smaller models for specific tasks, requiring far less training data than traditional fine-tuning and distillation. Their 770M T5 model outperformed the 540B PaLM model on a benchmark task. Impressively, their model used only 80% of the available data.

While large language models (LLMs) demonstrate impressive few-shot learning capabilities, deploying such large-scale models in real-world applications is challenging. Specialized infrastructure to service a 175 billion parameter LLM requires at least 350GB of GPU memory. Moreover, today’s state-of-the-art LLMs consist of over 500 billion parameters, which means they need even more memory and computational resources. Such computational requirements are out of reach for most producers, especially for applications that require low latency.
To address this issue with large models, deployers often opt for smaller, task-specific models instead. These smaller models are trained using common paradigms—fine-tuning or distillation. Fine-tuning upgrades a pre-trained small model using downstream human-annotated data. Distillation trains a similarly smaller model using the labels produced by a larger LLM. Unfortunately, these paradigms come at a cost: fine-tuning requires expensive human labels to achieve performance comparable to LLMs, while distillation requires a large amount of hard-to-obtain unlabeled data.
In a paper titled “Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes,” researchers from the University of Washington and Google introduced a new simple mechanism—Distilling Step-by-Step—to train smaller models using less training data. This mechanism reduces the amount of training data required for fine-tuning and distilling LLMs, allowing for smaller model sizes.

Paper link: https://arxiv.org/pdf/2305.02301v1.pdf
The core of this mechanism is to view LLMs as reasoning agents rather than sources of noisy labels. LLMs can produce natural language rationales that explain and support the labels predicted by the model. For example, when asked, “A gentleman is carrying equipment for playing golf, what might he have? (a) golf club, (b) hall, (c) meditation center, (d) conference, (e) church,” the LLM can reason through a chain of thought (CoT) to answer “(a) golf club” and rationalize this label by stating, “The answer must be something used for playing golf.” Among the options above, only the golf club is used for playing golf. The researchers used these rationales as additional richer information to train smaller models in a multi-task training setup for label prediction and rationale prediction.
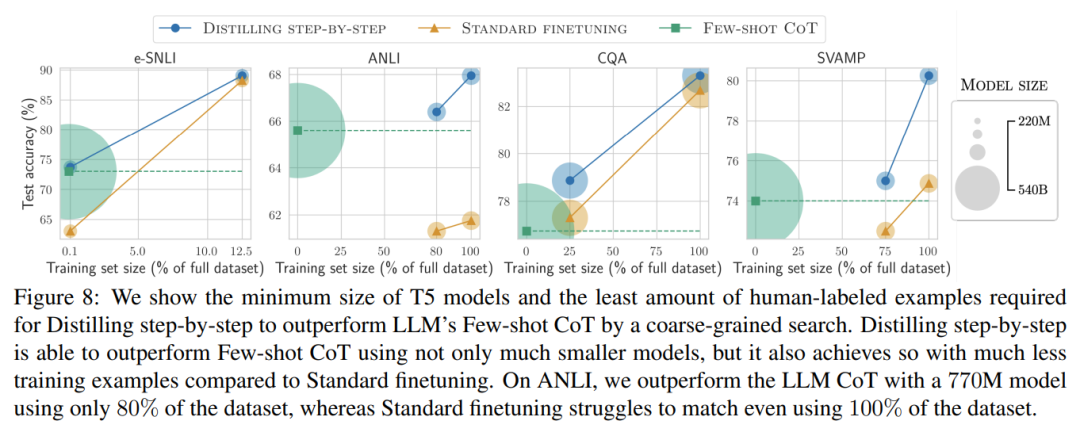
As shown in Figure 1, step-by-step distillation can learn small models for specific tasks, with parameters less than 1/500 of an LLM. Compared to traditional fine-tuning or distillation, the training examples used in step-by-step distillation are significantly fewer.

Experimental results show promising conclusions in three out of four NLP benchmarks.
-
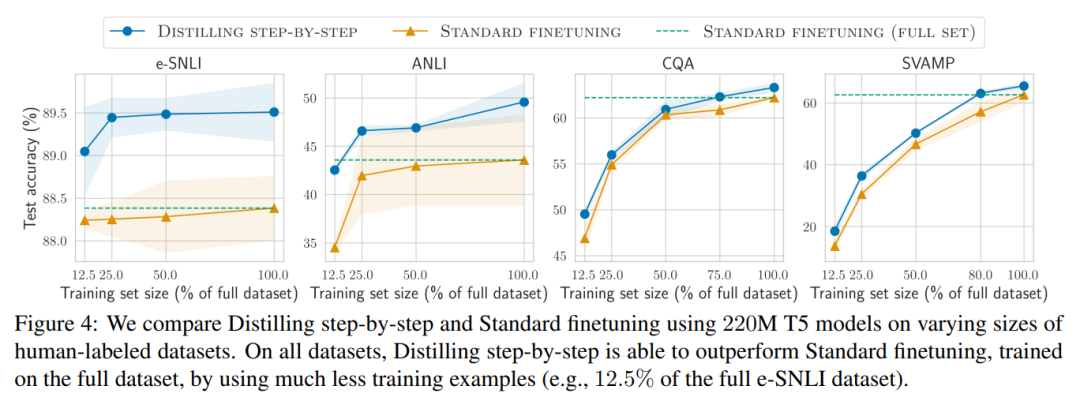
First, compared to fine-tuning and distillation, step-by-step distillation models achieved better performance across datasets, reducing the average training instances by more than 50% (with reductions of over 85% possible).
-
Second, our model outperformed LLMs with a smaller model size (up to 2000 times smaller), drastically reducing the computational costs required for model deployment.
-
Third, this research reduced the amount of data needed to surpass LLMs while shrinking model size. The researchers used a 770M T5 model to outperform a 540B parameter LLM. This smaller model used only 80% of the labeled dataset from existing fine-tuning methods.
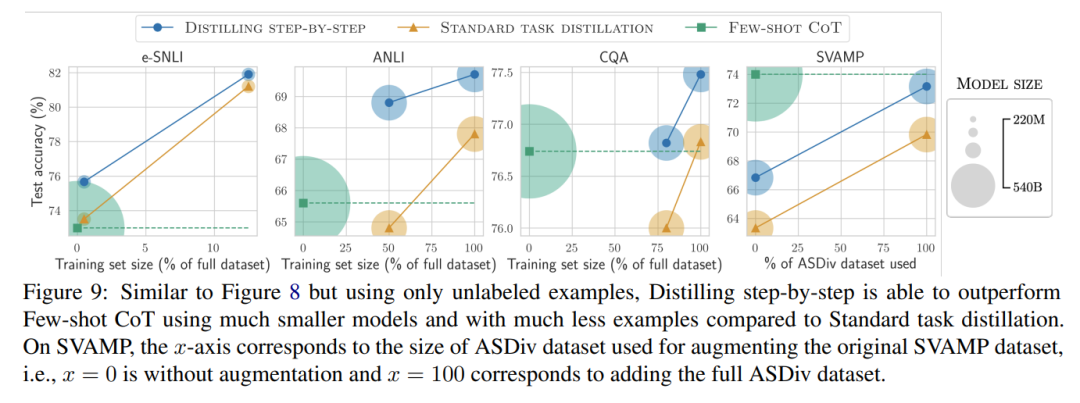
When only unlabeled data is available, the performance of the small model still surpasses that of LLMs—just using an 11B T5 model exceeded the performance of the 540B PaLM.
This study further demonstrates that when a smaller model performs worse than LLMs, step-by-step distillation can more effectively utilize additional unlabeled data to make the smaller model comparable to LLM performance compared to standard distillation methods.
Step-by-Step Distillation
The researchers proposed the new paradigm of step-by-step distillation to leverage the reasoning capabilities of LLMs for efficiently training smaller models with data. The overall framework is shown in Figure 2.
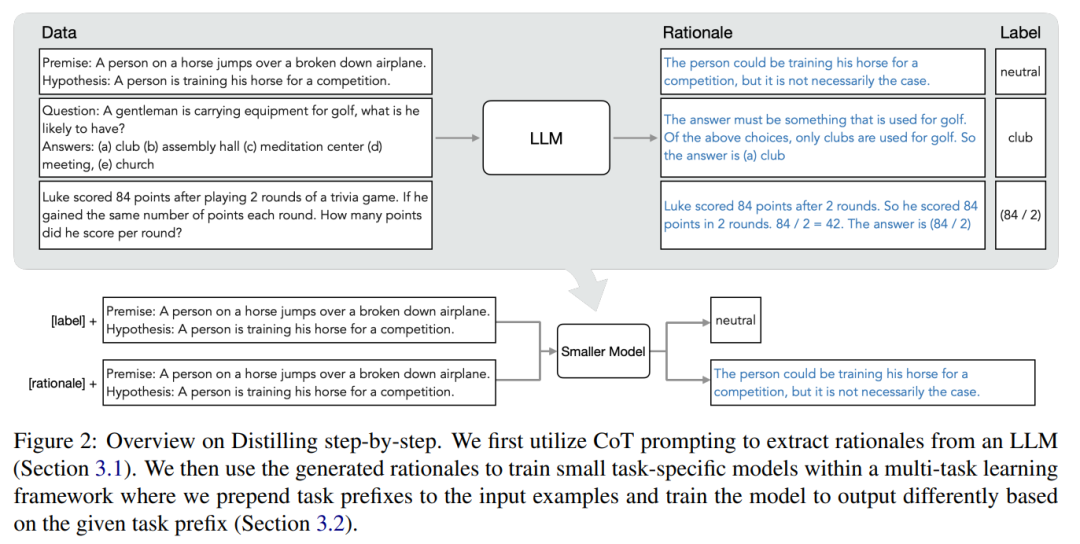
This paradigm consists of two simple steps: first, given an LLM and an unlabeled dataset, prompt the LLM to generate output labels along with rationales that justify those labels. The rationales are natural language explanations that support the predicted labels (see Figure 2). Rationales are an emergent behavior of current self-supervised LLMs.
Then, in addition to the task labels, these rationales are used to train smaller downstream models. In simple terms, rationales provide richer, more detailed information to explain why an input maps to a specific output label.
Experimental Results
The researchers validated the effectiveness of step-by-step distillation in experiments. First, compared to standard fine-tuning and task distillation methods, step-by-step distillation helps achieve better performance with far fewer training instances, significantly improving the data efficiency of learning small task-specific models.
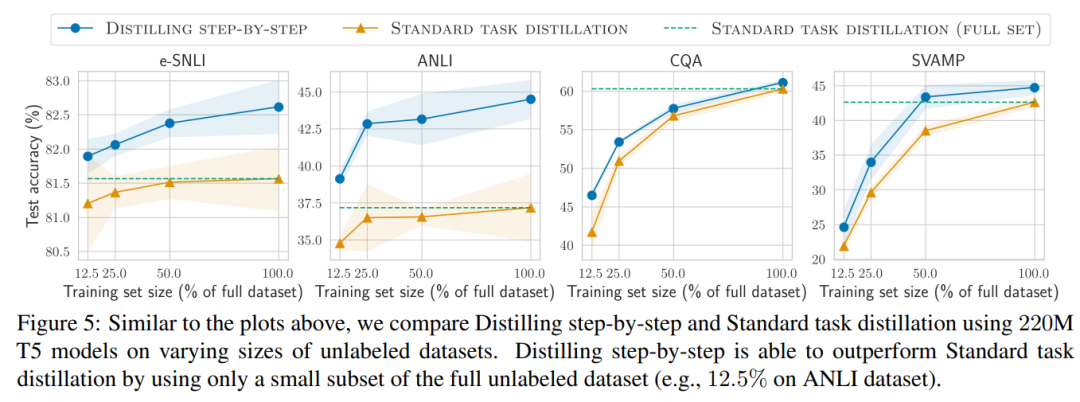
Second, the research indicates that the step-by-step distillation method surpasses LLM performance with smaller model sizes, significantly reducing deployment costs compared to LLMs.
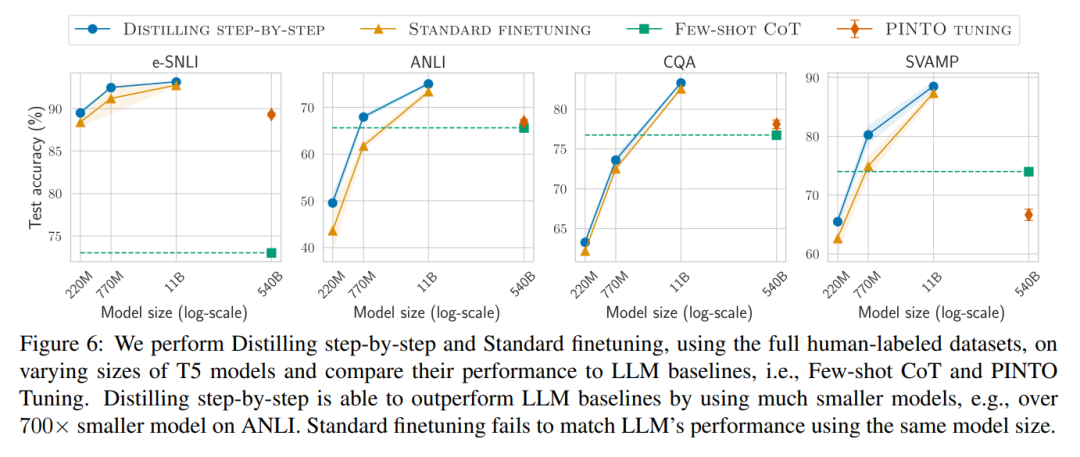
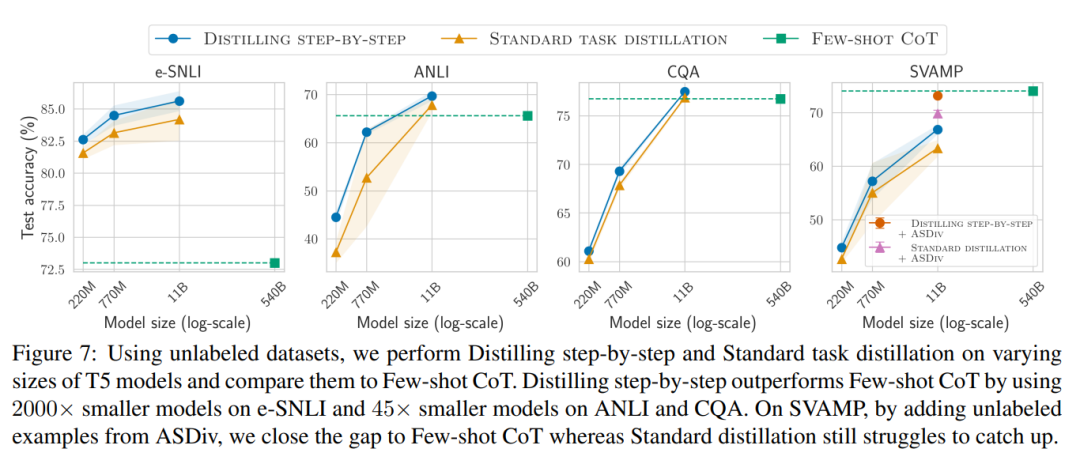
Lastly, the researchers investigated the minimum resources required for the step-by-step distillation method to outperform LLM performance, including the number of training examples and model size. They demonstrated that the step-by-step distillation method improves data efficiency and deployment efficiency while using less data and smaller models.