
In this blog, we will delve into the fascinating world of action recognition using the UCF101 dataset. Action recognition is a key task in computer vision, with applications ranging from surveillance to human-computer interaction. The UCF101 dataset serves as our playground for this exploration. Our goal is to build an action recognition model that combines Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) networks to achieve impressive results.

1. Understanding the UCF101 Dataset
The UCF101 dataset is a goldmine for action recognition researchers. It consists of 101 action categories, suitable for a wide range of applications. Each action is recorded in different scenes, adding complexity to the dataset. In this section, we will explore the details of the dataset, including its size, labels, and video formats. We will also discuss why the UCF101 dataset is the preferred choice for action recognition experiments.

Long Short-Term Memory (LSTM) networks have become a critical component in the field of action recognition, with their adoption transforming the domain. The introduction of these specialized Recurrent Neural Networks (RNNs) was aimed at addressing the limitations of traditional RNNs when handling sequential data, making them an ideal choice for modeling the inherent temporal dynamics in videos. In action recognition, the context of motion and its changes over time play a crucial role. Unlike static image classification tasks (where CNNs are often sufficient), recognizing actions requires a deep understanding of how visual patterns evolve over video sequences.
LSTMs excel at capturing temporal dependencies in data due to their unique memory cells. Each cell can store information for extended periods, ensuring that past observations significantly influence predictions, with even distant events potentially impacting the recognition process. This temporal modeling capability aligns perfectly with the challenges posed by action recognition, where subtle nuances of actions may evolve gradually across multiple frames. For instance, when distinguishing between “running” and “jumping,” the movement of the legs and body posture over time is crucial, and LSTMs excel at capturing these subtleties.
Furthermore, LSTMs provide flexibility in handling sequences of varying lengths, which is common in action recognition datasets. Actions can unfold at different speeds, and LSTM networks can naturally adapt to these dynamics. This adaptability, combined with their robustness in handling long-range dependencies, has led to their widespread adoption in action recognition research. The output of LSTM layers can encapsulate an abstract representation of the entire video sequence, which can then be used for accurate action predictions. Essentially, LSTMs serve as the temporal memory of the model, bridging the gap between the spatial features extracted by Convolutional Neural Networks (CNNs) and the final action recognition decisions.
LSTMs are crucial gears in the mechanism of action recognition, as they effectively model sequential data. They introduce the temporal element into the recognition process, making them indispensable for tasks where temporal dynamics are critical. As we continue to explore the nuances of human behavior through video data, LSTMs are likely to remain a cornerstone of this exciting field, helping us unlock new possibilities in applications such as surveillance and human-computer interaction.
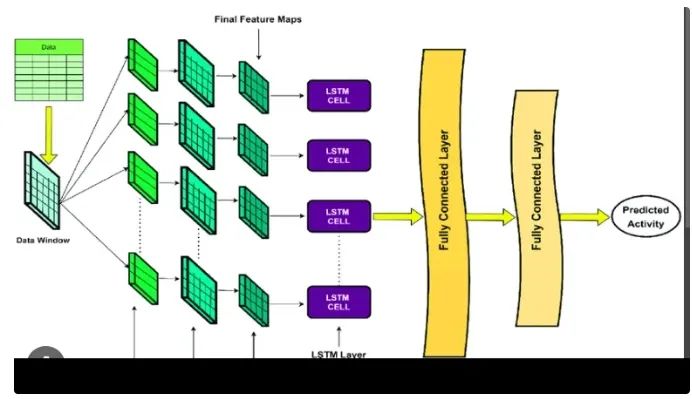
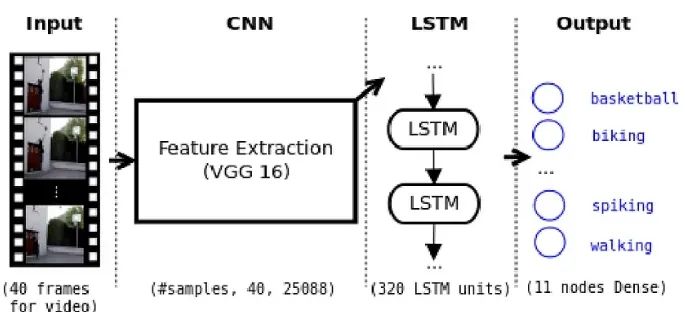

2. Preprocessing and Data Preparation
Before feeding the UCF101 dataset into our model, we need to prepare it appropriately. This involves several essential steps. We will introduce data preprocessing techniques such as resizing, normalization, and data augmentation to ensure our model learns effectively. We will also demonstrate how to split the dataset into training, validation, and test sets for robust evaluation.
from google.colab import drive
drive.mount('/content/drive')
!pip install tensorflow
import os
import cv2
import math
import random
import numpy as np
import datetime as dt
import tensorflow as tf
from collections import deque
import matplotlib.pyplot as plt
from moviepy.editor import *
%matplotlib inline
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import *
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras.utils import plot_model
!unrar x UCF50.rarimport random
plt.figure(figsize=(20, 20))
all_classes_names = os.listdir('UCF50')
for counter, selected_class_Name in enumerate(all_classes_names, 1):
video_files_names_list = os.listdir(f'UCF50/{selected_class_Name}')
# Check if there are video files in the folder
if video_files_names_list:
selected_video_file_name = random.choice(video_files_names_list)
video_reader = cv2.VideoCapture(f'UCF50/{selected_class_Name}/{selected_video_file_name}')
_, bgr_frame = video_reader.read()
video_reader.release()
rgb_frame = cv2.cvtColor(bgr_frame, cv2.COLOR_BGR2RGB)
cv2.putText(rgb_frame, selected_class_Name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2)
plt.subplot(5, 10, counter) # Adjust the number of rows and columns as needed
plt.imshow(rgb_frame)
plt.axis('off')
else:
print(f"No video files found in folder {selected_class_Name}")
plt.show()
IMAGE_HEIGHT,IMAGE_WIDTH = 64,64
SEQUENCE_LENGTH = 20
DATASET_DIR="UCF50"
CLASSES_LIST=["PlayingTabla","PommelHorse","JumpingJack","PushUps","PoleVault","HorseRace","HighJump","Drumming","HorseRiding","Diving","BreastStroke",
"Basketball","TrampolineJumping","YoYo","SalsaSpin","WalkingWithDog","VolleyballSpiking","ThrowDiscus","TennisSwing","TaiChi","Swing",
"SoccerJuggling","Skijet","Skiing","SkateBoarding","Rowing","RopeClimbing","RockClimbingIndoor","Punch","PullUps","PlayingViolin","PlayingPiano","PlayingGuitar",
"PizzaTossing","Nunchucks","Mixing","MilitaryParade","Lunges","Kayaking","JumpRope","JugglingBalls","JavelinThrow","HulaHoop","GolfSwing","Fencing",
"CleanAndJerk","Billiards","Biking","BenchPress","BaseballPitch"]
3. Convolutional Neural Networks (CNN) for Feature Extraction
CNNs are the backbone of our action recognition model. In this section, we will explore the role of CNNs in extracting spatial features from video frames. We will discuss popular CNN architectures such as VGG16 and ResNet, which can serve as powerful feature extractors. Additionally, we will introduce a custom CNN architecture tailored for the UCF101 dataset. Code examples will be provided for building and training the CNN model.
def frames_extraction(video_path):
frames_list=[]
video_reader = cv2.VideoCapture(video_path)
video_frames_count = int(video_reader.get(cv2.CAP_PROP_FRAME_COUNT))
skip_frames_window = max(int(video_frames_count/SEQUENCE_LENGTH),1)
for frame_counter in range(SEQUENCE_LENGTH):
video_reader.set(cv2.CAP_PROP_POS_FRAMES,frame_counter*skip_frames_window)
success,frame = video_reader.read()
if not success:
break
resized_frame = cv2.resize(frame,(IMAGE_HEIGHT, IMAGE_WIDTH))
normalized_frame = resized_frame / 255
frames_list.append(normalized_frame)
video_reader.release()
return frames_list
def create_dataset():
features = []
labels = []
video_files_paths = []
for class_index,class_name in enumerate(CLASSES_LIST[:40]):
print(f'Extracting Data of Class: {class_name}')
files_list = os.listdir(os.path.join(DATASET_DIR,class_name))
for file_name in files_list:
video_file_path = os.path.join(DATASET_DIR,class_name,file_name)
frames = frames_extraction(video_file_path)
if len(frames) == SEQUENCE_LENGTH:
features.append(frames)
labels.append(class_index)
video_files_paths.append(video_file_path)
features = np.asarray(features)
labels = np.array(labels)
return features,labels,video_files_paths
features,labels,video_files_paths = create_dataset()
one_hot_encoded_labels = to_categorical(labels)
4. Long Short-Term Memory (LSTM) Networks for Temporal Modeling
Action recognition involves not only spatial features; it also involves temporal dependencies. LSTM networks can help capture these temporal relationships. We will delve into the theory behind LSTMs and their unique ability to model sequences effectively. You will gain insights into the architecture of our LSTM-based model designed for UCF101. We will address the challenges of handling video sequences as input data.
def create_LRCN_model():
model = Sequential()
#Model Architecture.
#---------------------------------------------------------------------------------------------------------------------------------------------------#
model.add(TimeDistributed(Conv2D(16, (3, 3), padding='same',activation = 'relu'),
input_shape = (SEQUENCE_LENGTH, IMAGE_HEIGHT, IMAGE_WIDTH, 3)))
model.add(TimeDistributed(MaxPooling2D((4, 4))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(32, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((4, 4))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(64, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((2, 2))))
model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Conv2D(64, (3, 3), padding='same',activation = 'relu')))
model.add(TimeDistributed(MaxPooling2D((2, 2))))
#model.add(TimeDistributed(Dropout(0.25)))
model.add(TimeDistributed(Flatten()))
#K-LAYERED LSTM K=1
model.add(LSTM(32))
model.add(Dense(len(CLASSES_LIST[:10]), activation = 'softmax'))
#------------------------------------------------------------------------------------------------------------------------------------------------#
model.summary()
return model
LRCN_model = create_LRCN_model()
print("Model Created Successfully!")-
Layers: The choice of the number of convolutional and pooling layers in the TimeDistributed layer is based on a general architectural pattern for extracting spatial features from video frames, gradually increasing depth (number of filters) while reducing spatial dimensions to capture hierarchical features.
-
Activation Function: ReLU (Rectified Linear Unit) activation function is chosen for convolutional layers as it introduces non-linearity to the model, enabling it to learn complex patterns in the data effectively.
-
Dropout: A Dropout layer with a rate of 0.25 is added after each MaxPooling2D layer to prevent overfitting by randomly deactivating a portion of the neurons during training.
-
LSTM Layer: A single LSTM layer with 32 units is chosen to effectively capture temporal dependencies in video sequences.
-
Output Layer Activation: The output layer uses the softmax activation function to convert the model’s logits into class probabilities, suitable for multi-class classification tasks.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
time_distributed (TimeDist (None, 20, 64, 64, 16) 448
ributed)
time_distributed_1 (TimeDi (None, 20, 16, 16, 16) 0
stributed)
time_distributed_2 (TimeDi (None, 20, 16, 16, 16) 0
stributed)
time_distributed_3 (TimeDi (None, 20, 16, 16, 32) 4640
stributed)
time_distributed_4 (TimeDi (None, 20, 4, 4, 32) 0
stributed)
time_distributed_5 (TimeDi (None, 20, 4, 4, 32) 0
stributed)
time_distributed_6 (TimeDi (None, 20, 4, 4, 64) 18496
stributed)
time_distributed_7 (TimeDi (None, 20, 2, 2, 64) 0
stributed)
time_distributed_8 (TimeDi (None, 20, 2, 2, 64) 0
stributed)
time_distributed_9 (TimeDi (None, 20, 2, 2, 64) 36928
stributed)
time_distributed_10 (TimeD (None, 20, 1, 1, 64) 0
istributed)
time_distributed_11 (TimeD (None, 20, 64) 0
istributed)
lstm (LSTM) (None, 32) 12416
dense (Dense) (None, 10) 330
=================================================================
Total params: 73258 (286.16 KB)
Trainable params: 73258 (286.16 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Model Created Successfully!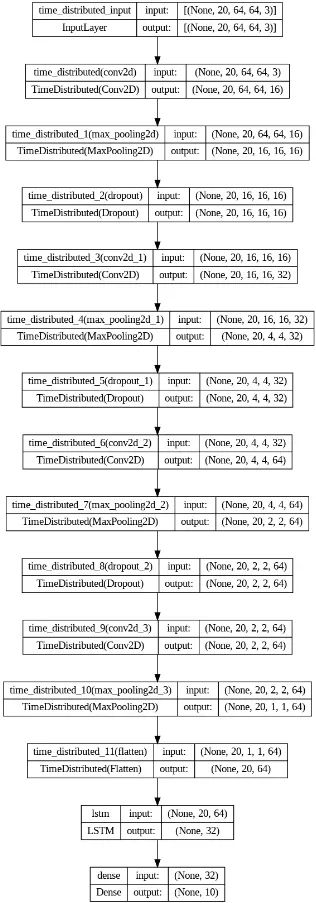
def plot_metric(model_training_history,metric_name1,metric_name2,plot_name):
metric_value1 = model_training_history.history[metric_name1]
metric_value2 = model_training_history.history[metric_name2]
epochs = range(len(metric_value1))
plt.plot(epochs,metric_value1,'blue',label=metric_name1)
plt.plot(epochs,metric_value2,'red',label=metric_name2)
plt.title(str(plot_name))
plt.legend()Learning Rate: The choice of the learning rate (lr) was based on experimentation to find a value that allowed the model to converge effectively without causing divergence, and a value of 0.001 (default for Adam optimizer) was found to work well.
Optimizer: The Adam optimizer was chosen because it combines the benefits of both AdaGrad and RMSProp, providing effective optimization for training deep neural networks.
Epochs: The number of epochs (100) was selected based on early stopping to prevent overfitting while allowing the model to train until convergence.
Batch Size: A batch size of 4 was chosen to strike a balance between computation efficiency and model stability during training.
Loss Function: Categorical Crossentropy was chosen as the loss function because it is suitable for multi-class classification tasks and encourages the model to minimize the difference between predicted and actual class probabilities.import time
# before training
start_time = time.time()
early_stopping_callback = EarlyStopping(monitor='accuracy', patience=10, mode='max', restore_best_weights=True)
LRCN_model.compile(loss='categorical_crossentropy', optimizer='Adam', metrics=["accuracy"])
# Start training
LRCN_model_training_history = LRCN_model.fit(x=features_train, y=labels_train, epochs=100, batch_size=4,
shuffle=True, validation_split=0.2, callbacks=[early_stopping_callback])
# end time after training
end_time = time.time()
# total training time
total_training_time = end_time - start_time
print(f"Total training time: {total_training_time:.2f} seconds")
model_evaluation_history = LRCN_model.evaluate(features_test,lables_test)
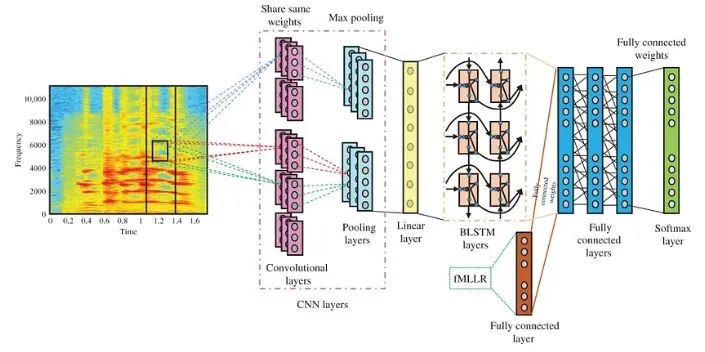
5. Model Integration: CNN + LSTM
When we combine CNN and LSTM layers to form our action recognition model, magic happens. We will explore the concept of 3D convolutions, which seamlessly integrate spatial and temporal features. We will showcase the architecture of the integrated CNN-LSTM model, including input shapes and layer connections. To gain practical experience, we will provide code examples for building this powerful model.

6. Training and Evaluation
Training our model is a critical step, involving the selection of appropriate loss functions and optimizers. We will explain the importance of hyperparameter tuning for optimal performance. Evaluation metrics such as accuracy, confusion matrices, and F1 scores will be discussed in detail. Get ready for an in-depth analysis of our model’s results on the UCF101 test set.
import os
from moviepy.editor import VideoFileClip
test_videos_directory='test_videos'
os.makedirs(test_videos_directory,exist_ok=True)
input_video_file_path = '/content/drive/MyDrive/Cognitica/Test_dir/v_Diving_g25_c02.avi'
video_title = os.path.splitext(os.path.basename(input_video_file_path))[0]
print(f"Video Name: {video_title}")def predict_on_video(video_file_path, output_file_path, SEQUENCE_LENGTH):
video_reader = cv2.VideoCapture(video_file_path)
original_video_width = int(video_reader.get(cv2.CAP_PROP_FRAME_WIDTH))
original_video_height = int(video_reader.get(cv2.CAP_PROP_FRAME_HEIGHT))
video_writer = cv2.VideoWriter(output_file_path, cv2.VideoWriter_fourcc('M', 'P', '4', 'V'),
video_reader.get(cv2.CAP_PROP_FPS), (original_video_width, original_video_height))
frames_queue = deque(maxlen=SEQUENCE_LENGTH)
predicted_class_name = ''
while video_reader.isOpened():
ok, frame = video_reader.read()
if not ok:
break # Exit the loop when there are no more frames
# Check if the frame is empty before resizing
if not frame.size:
continue
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
normalized_frame = resized_frame / 255
frames_queue.append(normalized_frame)
if len(frames_queue) == SEQUENCE_LENGTH:
predicted_labels_probabilities = LRCN_model.predict(np.expand_dims(frames_queue, axis=0))[0]
predicted_label = np.argmax(predicted_labels_probabilities)
predicted_class_name = CLASSES_LIST[predicted_label]
cv2.putText(frame, predicted_class_name, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
video_writer.write(frame)
video_reader.release()
video_writer.release()%%capture
output_dir = "/content/drive/MyDrive/Cognitica/Output"
output_video_file_path = f'{output_dir}/{video_title}-Output-SeqLen{SEQUENCE_LENGTH}.mp4'
predict_on_video(input_video_file_path, output_video_file_path, SEQUENCE_LENGTH)
processed_video = VideoFileClip(output_video_file_path, audio=False, target_resolution=(300, None))
processed_video.ipython_display()Classification Report:
%%capture
true_labels = [] # true labels for each frame
predicted_labels = [] # predicted labels for each frame
#predict labels for a video
def predict_on_video(video_file_path, true_label):
video_reader = cv2.VideoCapture(video_file_path)
frames_queue = deque(maxlen=SEQUENCE_LENGTH)
while video_reader.isOpened():
ok, frame = video_reader.read()
if not ok:
break
if not frame.size:
continue
resized_frame = cv2.resize(frame, (IMAGE_HEIGHT, IMAGE_WIDTH))
normalized_frame = resized_frame / 255
frames_queue.append(normalized_frame)
if len(frames_queue) == SEQUENCE_LENGTH:
predicted_labels_probabilities = LRCN_model.predict(np.expand_dims(frames_queue, axis=0))[0]
predicted_label = np.argmax(predicted_labels_probabilities)
predicted_class_name = CLASSES_LIST[predicted_label]
true_labels.append(true_label)
predicted_labels.append(predicted_class_name)
video_reader.release()
return true_labels, predicted_labels
#test vids
class_name_mapping = {
'v_Diving_g25_c02': 'Diving',
'v_Drumming_g25_c07': 'Drumming',
'v_HighJump_g25_c04': 'HighJump',
'v_HorseRace_g25_c04': 'HorseRace',
'v_HorseRiding_g25_c21': 'HorseRiding',
'v_JumpingJack_g25_c07': 'JumpingJack',
'v_PlayingTabla_g22_c04': 'PlayingTabla',
'v_PoleVault_g17_c09': 'PoleVault',
'v_PommelHorse_g05_c04': 'PommelHorse',
'v_PushUps_g26_c04': 'PushUps',
}
all_true_labels = []
all_predicted_labels = []
test_videos_directory = '/content/drive/MyDrive/Cognitica/Test_dir'
for video_file in os.listdir(test_videos_directory):
if video_file.endswith(".avi"):
video_file_path = os.path.join(test_videos_directory, video_file)
video_title = os.path.splitext(os.path.basename(video_file_path))[0]
# Map video_title
class_name = class_name_mapping.get(video_title, 'Unknown')
true_labels_video, predicted_labels_video = predict_on_video(video_file_path, true_label=class_name)
all_true_labels.extend(true_labels_video)
all_predicted_labels.extend(predicted_labels_video)
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=UndefinedMetricWarning)
report = classification_report(all_true_labels, all_predicted_labels)
print(report)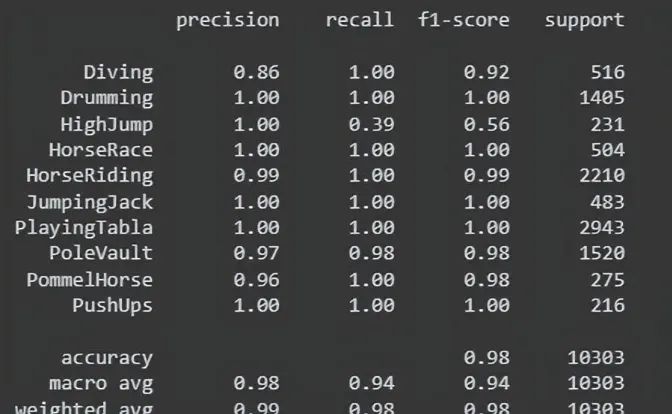
confusion = confusion_matrix(all_true_labels, all_predicted_labels)
print("Confusion Matrix:")
print(confusion)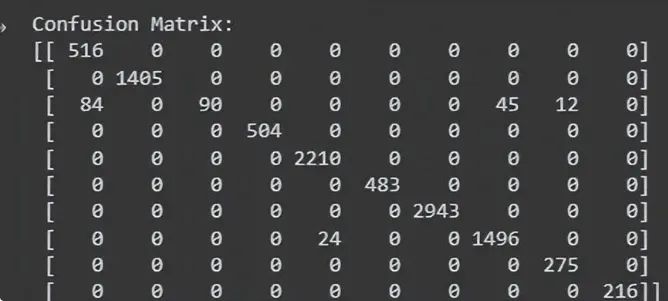

7. Practical Applications
The LSTM + CNN (Long Short-Term Memory + Convolutional Neural Network) architecture has applications across various domains due to its ability to capture spatial and temporal features. Here are some notable applications:
-
Action recognition in videos: LSTM + CNN models are widely used to identify human actions in video sequences. They can leverage CNNs to capture spatial details and use LSTMs to model temporal dependencies across frames, effectively distinguishing complex actions.
-
Gesture recognition: Gesture recognition in sign language or human-computer interaction scenarios benefits from LSTM + CNN architectures. They can interpret the static hand positions of gestures (spatial features) and the dynamic changes over time (temporal features).
-
Video surveillance: Detecting and classifying activities in surveillance footage is crucial for security. LSTM + CNN models excel at identifying suspicious behaviors by analyzing spatial and temporal patterns in video streams.
-
Autonomous driving: Autonomous vehicles utilize a combination of LSTM and CNN to interpret traffic scenes. They can identify objects, predict their movements, and make decisions based on temporal context, contributing to safer autonomous driving.
-
Human pose estimation: Estimating human poses from images or videos often requires capturing spatial relationships of body parts and their temporal evolution. LSTM + CNN can effectively handle this task.
-
Speech recognition: Although not directly visualized, LSTM + CNN architectures can be used in automatic speech recognition systems. They handle audio spectrograms (spatial features) and model the sequential nature of speech signals (temporal features).
-
Medical image analysis: In medical imaging, recognizing anomalies or tracking changes in patient scans over time is crucial. LSTM + CNN models help analyze 3D or time-series medical images effectively.
-
Natural language processing: While primarily used for images and videos, LSTM + CNN is also applicable to handling spatio-temporal data in natural language processing tasks. They can process sequences of word embeddings and capture context in textual data.
-
Financial time series forecasting: Predicting stock prices or trends in financial markets involves analyzing historical data with temporal dependencies. LSTM + CNN models can capture complex patterns in financial time series data.
-
Gesture-controlled devices: Devices controlled by gestures, such as TVs or smart appliances, use LSTM + CNN models to interpret hand movements and gestures, enabling intuitive user interactions.
-
Robotics: Robots equipped with cameras and sensors can benefit from LSTM + CNN architectures to navigate complex environments, recognize objects, and make decisions based on visual and temporal cues.
-
Emotion recognition: Understanding human emotions from facial expressions in videos requires analyzing spatial details of faces and the temporal evolution of expressions, making LSTM + CNN valuable in this context.


8. Conclusion
As we conclude our exploration of action recognition on the UCF101 dataset, let us summarize the key points. We witnessed the significance of the dataset, the powerful capabilities of CNNs and LSTMs, and the synergy of their combination. We encourage you to embark on the journey of action recognition, experiment with CNN-LSTM models, and leverage the UCF101 dataset to push the boundaries of artificial intelligence. If you enjoy hands-on practice, the code from this article can be obtained here.
These applications showcase the versatility of LSTM + CNN architectures in handling various tasks involving spatio-temporal data. Their ability to combine spatial and temporal information makes them a powerful choice for tasks where context and time are crucial.
Copyright Notice
Reproduced from New Brain in a Jar, copyright belongs to the original author, used for academic sharing only.
Meanwhile, Hangzhou Ruishu Technology (Dolphin Lab) has launched the “Free Support Plan for Thousands of Schools” to contribute to the development of big data and artificial intelligence education in universities nationwide. Teachers are welcome to call for consultation ☎️.

Scan to apply, and a specialist will contact you within 24 hours.
The 【Dolphin Artificial Intelligence and Big Data Laboratory】 is a “one-stop” educational training and research platform for big data analysis and artificial intelligence, independently developed by Hangzhou Ruishu Technology Co., Ltd., founded by a team returning from North America. Through an “immersive” and “interactive” online virtual experiment platform, combined with rich real industry cases and datasets, we effectively solve the pain points in big data and artificial intelligence education and training. Through our comprehensive solutions, we achieve the cultivation of interdisciplinary talents in “Big Data + X” and “Artificial Intelligence + X”, fully supporting the rapid development of China’s artificial intelligence and big data industry!
National universities, training institutions, and channel partners are welcome to contact us for cooperation!
Please visit the official website www.dolphin-labs.com for online customer service, providing 7×24 hour consultation services.
Or contactemail [email protected]
Orcontacthotline 400-001-3538
