Author: Amber
Original submission to SSD Fans, earn >= 100 CNY for articles.
Since AlexNet won the ImageNet challenge in 2012, deep learning technology has been increasingly used in various fields of artificial intelligence. Among them, Convolutional Neural Networks (CNN) have excelled in image classification tasks. However, due to the high computational cost of CNNs, most existing CNN models utilize GPUs for computational acceleration. With the growing demand for deploying CNN models on embedded systems, there is an urgent need for alternatives to GPUs for accelerating CNN calculations, making FPGA a viable option for deep learning model acceleration.
A classic CNN model—LeNet5 is shown in Figure 1. As seen in the figure, LeNet5 contains 2 convolutional layers, 2 pooling layers, and 2 fully connected layers.

Figure 1: LeNet5 Model
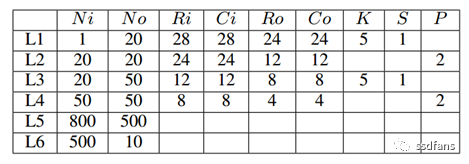
For ease of analysis, we list the details of this structure in Table 1. Here, L1~L6 represent the first to sixth layers of the model, indicating the number of input and output feature maps, as well as the dimensions of the input and output feature maps for each layer. Each convolutional layer contains a certain number of convolutional filters, with each filter having a specified size and convolution stride. Each pooling layer has a defined pooling size. The training process of the entire CNN model is essentially an iterative process that continuously adjusts model parameters using the backpropagation (BP) algorithm.
Table 1: LeNet5 Model Configuration
It can be seen that each iteration during the training process of CNN exhibits similar computational patterns, which reveals the potential for accelerating CNN training on FPGA platforms. Many researchers have been conducting studies in this area. In this article, we will introduce one classic solution: F-CNN.
By analyzing the model structure of Convolutional Neural Networks, we find that to better design a CNN training architecture based on FPGA, we need to consider the following aspects:
1) Modularity. Even the most advanced FPGA cannot independently complete the entire CNN training process, so to train CNN on FPGA, different layers need to be modularized.
2) Unified Data Path. To reduce the coupling overhead between modules and enhance the overall architecture’s efficiency, a unified data flow path should be designed to best utilize storage bandwidth.
3) Runtime Reconfigurability. The entire architecture must be reconfigurable to accommodate the CNN training process.
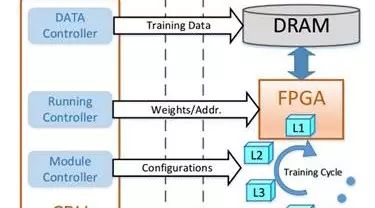
Considering the above three points, a classic FPGA-based CNN training architecture can be designed as shown in Figure 2. This architecture is a CPU/FPGA hybrid platform where the CPU acts as the controller, and the FPGA is used for computational acceleration, while the DRAM on the FPGA card stores the input and output data for each computational module. In this architecture, the module controller is responsible for customizing different computational modules based on the configuration of different layers and reconfiguring them onto the FPGA in a specific order: first, the forward computation modules from bottom to top, followed by the backward computation modules from top to bottom during a training cycle. The data controller divides the training data into different minibatches and loads them into DRAM for training. For multi-FPGA platforms, the data controller also manages data transfers between FPAGs. The runtime controller is responsible for invoking module configurations to complete computations. In this architecture, the read and write addresses of data are passed as parameters, allowing modules to access data in DRAM. Besides data, modules also require corresponding weights. Since the amount of weight data is much smaller than that of training data, and considering that the BP algorithm requires corresponding weights for calculations, in this architecture, weights and biases are stored in the CPU and transferred to the FPGA along with other parameters via PCI-E. This design reduces the I/O load on DRAM and fully utilizes PCI-E bandwidth, making module designs independent of weights. Ultimately, the CPU is responsible for updating weights after receiving the derivatives from the FPGA.
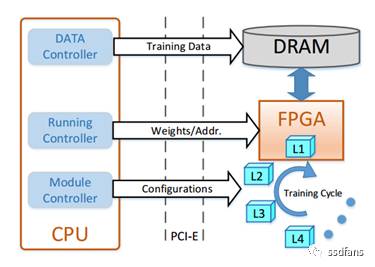
Figure 2: FPGA-based CNN Training Architecture
In summary, for a given CNN model, this architecture first modularizes different layer modules, utilizing the data controller to divide training data into different minibatches. The following iterative training process is then conducted:
1. Reconfigure modules onto the FPGA;
2. Prepare data in DRAM, which can occur in three scenarios:
a) For the first module, load training data from the CPU into DRAM;
b) For the remaining modules in a single FPGA architecture, intermediate data is already in DRAM, so no data transfer is needed;
c) For the remaining modules in a multi-FPGA architecture, intermediate data will be transferred from one FPGA to another;
3. Invoke the model for computation;
4. Read back results and update weights, then check if training should end; if not, return to step one and continue.
With a clear overall architecture design, how can we specifically modularize the CNN model?
The overall framework for parameterized modules is shown in Figure 3. The input controller includes an address generator and a scheduler; the address generator is responsible for generating addresses and reading input data for each clock cycle, while the scheduler caches input data and sends it to the computation unit. The output controller contains an address generator that stores input data into DRAM and is responsible for transferring updated weights back to the CPU via PCI-E.
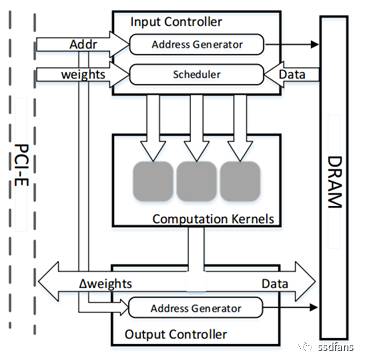
Figure 3: Overall Framework for Parameterized Modules
As is well known, the most important and typical structures in CNN are convolutional calculations and pooling calculations. To achieve parallel acceleration, it is necessary to design convolutional kernels and pooling kernels suitable for calculation in FPGA, thus in this architecture, convolutional kernels and pooling kernels are designed as shown in Figures 4 and 5.
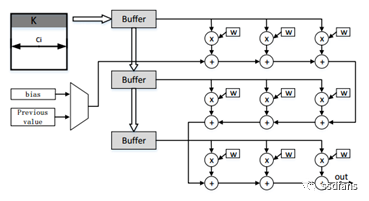
Figure 4: Convolutional Kernel
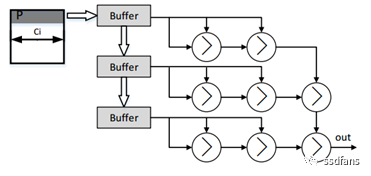
Figure 5: Pooling Kernel
In addition to convolutional and pooling layers, another important component in Convolutional Neural Networks is the fully connected layer. From a mathematical perspective, the computation of the fully connected layer is equivalent to matrix multiplication, and Algorithm 1 depicts the computation method of the fully connected layer in this architecture.

To validate the model’s effectiveness, researchers conducted experiments deploying LeNet5 based on this architecture.
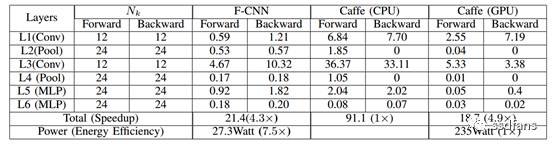
The experimental results are shown in Table 2. The FPGA-based architecture on the LeNet5 model structure is approximately 4 times faster than the CPU architecture implemented using Caffe, while slightly slower than the execution speed of the GPU architecture using Caffe. However, this architecture is 7.5 times more energy-efficient than the GPU architecture using Caffe. From the experimental results of this architecture, using FPGA for CNN acceleration is a very effective approach.
Table 2: Average Execution Time (S) per Iteration of LeNet5 on F-CNN, CPU, and GPU
In today’s environment, where there is an urgent demand for deploying CNN models on embedded systems, utilizing FPGA for accelerating CNN model calculations will increasingly be applied.
References:
Zhao W, Fu H, Luk W, et al. F-CNN: An FPGA-based framework for training Convolutional Neural Networks[C] Application-specific Systems, Architectures and Processors (ASAP), 2016 IEEE 27th International Conference on. IEEE, 2016: 107-114.
If you like it, please share and forward!
How to read other articles from SSD Fans? Click the end of the article Read Original to enter www.ssdfans.com, and use the search box to search for keywords.
Don’t want to miss out on exciting articles? Long press or scan the QR code below to follow SSD Fans!

WeChat Group Introduction
| Heterogeneous Computing Group | Discussing AI and heterogeneous computing architecture and other technical issues |
| ASIC-FPGA Group | Technical discussion group for hardware developers related to chips and FPGAs |
| Enterprise Level | Discussion on AI and big data |
If you want to join these groups, please add nanoarch as a WeChat friend, introduce your nickname – company – profession, and specify the group name to be added.