1 Spatial-Frequency Information Integration Network (SFINet): The first proposal to simultaneously handle the multimodal image fusion problem in both spatial and frequency domains, enhancing the model’s learning ability by combining local spatial information and global frequency information.
2 Dual-Domain Interaction Mechanism: A novel pseudo-burst feature fusion mechanism is proposed, allowing flexible information exchange and complementary representation learning between different modalities by exchanging information between frames.
3 Edge-Enhanced Feature Alignment Module (EBFA): Developed an edge-enhanced feature alignment technique based on deformable convolution to implicitly learn inter-frame alignment, improving alignment accuracy and reducing errors caused by misalignment.
4 Improved SFINet++ Version: On the basis of the original SFINet, the representation ability of spatial information is further enhanced by introducing information-lossless reversible neural operators, achieving better performance in multimodal image fusion tasks.
Abstract
Multimodal image fusion involves tasks such as pan-sharpening and depth super-resolution. These tasks aim to generate high-resolution target images by fusing complementary information from texture-rich guiding images and low-resolution target images. They inherently require the reconstruction of high-frequency information. Although they are related in the frequency domain, most existing methods operate solely in the spatial domain, rarely exploring solutions in the frequency domain. This study addresses this limitation by proposing solutions in both spatial and frequency domains. For this purpose, we designed a Spatial-Frequency Information Integration Network, abbreviated as SFINet. SFINet includes a core module tailored for image fusion, consisting of three key components: a spatial domain information branch, a frequency domain information branch, and dual-domain interaction. The spatial domain information branch integrates local information from different modalities in the spatial domain using reversible neural operators equipped with spatial convolutions. Meanwhile, the frequency domain information branch captures the global receptive field of the image through modality-aware deep Fourier transforms to explore global contextual information. Moreover, dual-domain interaction facilitates the flow of information and learning of complementary representations. We further propose an improved version of SFINet, SFINet++, which enhances the representation of spatial information by replacing the basic convolution units in the original spatial domain branch with information-lossless reversible neural operators. We conducted extensive experiments to validate the effectiveness of the proposed network and demonstrated their outstanding performance in two representative multimodal image fusion tasks: pan-sharpening and depth super-resolution.
Keywords
Multimodal Image Fusion
Spatial-Frequency Information
Pan-Sharpening
Depth Super-Resolution
I. Introduction
Multimodal image fusion is a fundamental task in the field of computer vision, which involves combining multiple images of the same scene captured using different imaging modalities. The goal of multimodal image fusion is to create a single composite image that effectively integrates the most relevant and informative details from each source image, resulting in a more comprehensive and informative representation. Typical tasks involving multimodal image fusion, such as pan-sharpening and depth image super-resolution, become critical due to inherent resolution differences when capturing the same target with different devices. Specifically, pan-sharpening involves the super-resolution of multispectral (MS) images guided by panchromatic (PAN) images, where the MS images are limited in spatial resolution due to hardware constraints, alleviated by combining texture-rich high-resolution (HR) PAN images from the same scene. Similarly, in the context of depth image super-resolution, HR color images play a foundational role in reconstructing depth images, being semantically and structurally consistent with color images. Notably, low-resolution (LR) depth images and HR color images serve as the target and guiding images, respectively. From the perspective of imaging principles, given the inherent constraints of pan-sharpening, satellites typically capture complementary information using both MS and PAN sensors simultaneously. Specifically, MS images exhibit superior spectral resolution but limited spatial resolution, while PAN images provide rich spatial details but lack spectral resolution. The combination of complementary information from PAN and MS images produces a composite representation that offers a rich balance of spatial and spectral details. Similarly, in RGB-guided depth super-resolution, the task revolves around enhancing the depth image resolution by leveraging guidance from high-resolution RGB images. RGB images rely on visible light, providing complex texture details consistent with the human visual system. By combining depth information with the guidance of RGB images, the resulting super-resolved depth images exhibit higher spatial resolution, presenting a comprehensive and detailed representation of the scene. The parallel use of complementary information in both tasks demonstrates a common approach to achieving enhanced spatial and spectral information.The importance of information-rich and spatially detailed images is evident in various applications, including military systems, environmental monitoring, and mapping services. In recent years, both tasks have attracted significant attention from the image processing and remote sensing communities. Inspired by the success of deep neural networks (DNNs) in image processing, a large number of DNN-based multimodal image fusion methods have been developed. In the context of pan-sharpening, the pioneering PNN[1] relies solely on three layers of convolution operations to facilitate the learning of MS pan-sharpening. This method is derived from the influential super-resolution model SRCNN[2]. Subsequently, more complex and deeper architectures have been designed to enhance the ability to map effectively. Despite achieving significant progress, existing multimodal image fusion methods still share common limitations. Firstly, these methods focus on mastering mapping functions in the spatial domain, with little regard for potential remedies in the frequency domain—an aspect worthy of more consideration in the field of image fusion. However, the nature of the challenge lies in the super-resolution problem of guiding images, closely related to the frequency domain, as high-frequency information is chosen to be removed during down-sampling, as stated in [3]. Given this observation, we are committed to addressing this issue from the frequency domain perspective. Our motivation. As shown in Figure 1, our study provides a comprehensive frequency analysis of pan-sharpening and depth super-resolution in the fields of remote sensing and natural images. This analysis involves examining phase and amplitude components through the application of discrete Fourier transforms. Furthermore, this study delves into the differences in amplitude components between these two techniques. Regarding pan-sharpening, two observations in the frequency domain: 1) Our initial observation revealed that the phase of the PAN image is more similar to that of the ground truth (GT) image than the phase of the MS image. This alignment corresponds to spatial perception, indicating that the PAN image contains more complex textures and structures than the MS image. Considering that the phase components of Fourier transforms represent structural information, it is reasonable to utilize the phases of both the PAN and MS images to approximate the phase of the GT image. 2) In the last column, the amplitude differences between PAN and GT are mainly concentrated in the low-frequency range, while amplitude differences between MS and GT exist in both low and high-frequency ranges. This observation suggests that the missing frequency information in the MS may potentially be supplemented by utilizing the corresponding low-frequency components of the PAN. Regarding depth super-resolution, similar observations arise, where depth and RGB images play the roles of MS and PAN images, respectively. Here, depth and MS images help provide structural insights, while RGB and PAN images provide high-frequency details. This frequency domain analysis serves as a powerful tool for understanding degradation and propelling us to seek solutions in both spatial and frequency domains. Guided by the spectral convolution theorem[4], we understand that learning in the frequency domain facilitates the global receptive field of images, capturing universal global context. Therefore, utilizing global frequency information enriches the representation of pixel values in the spatial domain, enhancing information representation and modeling capability. Based on the above analysis, we introduce a new perspective on multimodal image fusion. Specifically, we first attempt to address this problem in the spatial-frequency domain and propose a Spatial-Frequency Information Integration Network called SFINet. To achieve SFINet, we design a basic building block SFIB, consisting of three fundamental components: a spatial domain information branch, a frequency domain information branch, and dual-domain information interaction. The spatial branch employs reversible neural operators equipped with spatial convolutions to integrate local information from two modalities in the spatial domain, while the frequency branch is responsible for extracting and transforming global frequency information through deep Fourier transforms. Inspired by the spectral convolution theorem, we believe that the frequency information branch allows for the global receptive field of images, simulating global contextual information, thereby enhancing the model’s capability. Subsequently, dual-domain information interaction is performed to facilitate information flow and learn complementary representations in both spatial and frequency domains. Furthermore, we propose an improved version SFINet++, which achieves enhanced representation of spatial information by replacing the basic convolution units in the original spatial domain branch with information-lossless reversible neural operators. We conducted extensive experiments to validate the effectiveness of the proposed network and demonstrated their outstanding performance in two prominent multimodal image fusion tasks: pan-sharpening and depth super-resolution. The work presented in this paper is an extension of our previous conference version published at ECCV 2022[5]. We significantly expanded the previous version by introducing a wealth of new materials, detailed as follows. 1) To improve the representation of spatial information, we replaced the basic convolution units in the original spatial domain branch with information-lossless reversible neural operators, resulting in a new improved version called SFINet++. This approach is more effective for multimodal image fusion in the field of remote sensing, such as pan-sharpening and depth super-resolution in the natural image domain. 2) Compared to our conference version, we explored the potential of our proposed framework in RGB-guided depth image super-resolution. Through quantitative and qualitative experiments, we demonstrated the superiority of our developed SFINet++ enhanced version. 3) We conducted additional experiments and provided more detailed feature visualizations to further investigate the potential mechanisms of the proposed spatial-frequency dual-domain integration in pan-sharpening and depth super-resolution tasks. 4) We extensively reviewed the relevant literature on pan-sharpening and depth super-resolution and discussed the strengths and weaknesses of existing methods.
3 Methodology
In this section, we first review the properties of the Fourier transform. Then, we provide an overview of the proposed framework, as illustrated in Figures 2 and 3. Next, we describe the core building blocks of our method, which consists of three key components: (a) the frequency domain component that utilizes discrete Fourier transform (DFT) to extract global frequency information representation, (b) the spatial domain information component that explores local information, and (c) the dual-domain information interaction component that facilitates information flow and enables complementary representation learning. Finally, we introduce the new loss function used in our method.
3.1 Image Fourier Transform
The Fourier transform is a widely used method for analyzing the frequency content of images. In the case of multi-channel images, the Fourier transform is applied to each channel separately. For brevity, we omit the channel notation in the equations below. Let $x \\in \\mathbb{R}^{H \ imes W \ imes C}$ be an image, the Fourier transform $F(\cdot)$ converts it into complex components in Fourier space $F(x)$, which can be expressed as:$$F(x)(u, v) = rac{1}{ ext{sqrt}{HW}} \\sum_{h=0}^{H-1} \\sum_{w=0}^{W-1} x(h, w)e^{-j2 ext{pi}(\frac{hu}{H} + \frac{wv}{W})}.$$The inverse Fourier transform of $F(x)$ is denoted as $F^{-1}(x)$. The fast Fourier transform (FFT) algorithm[4] is used to efficiently implement the Fourier transform and its inverse. The amplitude component $A(x)(u, v)$ and phase component $P(x)(u, v)$ are defined as:$$A(x)(u, v) = ext{sqrt}{R^2(x)(u, v) + I^2(x)(u, v)},$$$$P(x)(u, v) = ext{arctan}{\left(\frac{I(x)(u, v)}{R(x)(u, v)}\right),$$where $R(x)$ and $I(x)$ denote the real and imaginary parts of $F(x)$, respectively. In our work, the Fourier transform and its inverse are applied independently to each channel of the feature maps. In pan-sharpening and depth super-resolution, we utilize the Fourier transform to analyze the frequency characteristics of MS/depth, PAN/RGB, and GT images by examining their phase and amplitude attributes, as shown in Figure 1. This inspires our motivation to explore potential solutions in both spatial and frequency domains. Importantly, we emphasize pan-sharpening as an illustrative case, while depth super-resolution is equally applicable.
3.2 Framework Structure
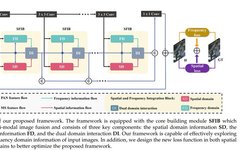
Flowchart. As shown in Figure 2, we designed a pan-sharpening method based on spatial-frequency information integration, where we take PAN image $P \\in \\mathbb{R}^{H \ imes W \ imes 1}$ and MS image $L \\in \\mathbb{R}^{H_r \ imes W_r \ imes C}$ as inputs and use a $1 \ imes 1$-kernel convolution layer to upsample the $M \\in \\mathbb{R}^{H \ imes W \ imes C}$ by $r$ times through multiple cascaded $3 \ imes 3$-kernel convolution layers combined with the nonlinear function ReLU to extract information features $F_i^p$ from $P$, where $i = 0, \\dots, 5$. The obtained modality-aware feature maps of MS and PAN are fed into the core building module SFIB, which performs spatial-frequency information extraction and integration to produce effective feature representations. Subsequently, we utilize a $1 \ imes 1$-kernel convolution layer to convert the features collected from all SFIB modules $SFIBs$ back to image space, and combine them with the input $M$ to obtain the output pan-sharpened image $H$, as follows:$$H = SFIBs(M, F_p) + M.$$Supervised Process. In this study, we introduce a new loss function to optimize the pan-sharpening process and enhance results in both spatial and frequency domains, independent of structural design. The proposed loss function comprises two components: spatial domain loss $L_{spa}$ and frequency domain loss $L_{fre}$, as illustrated in Figure 2. Previous pan-sharpening methods typically employed pixel loss with local guidance in the spatial domain. However, our approach adds an additional frequency domain supervision loss, utilizing the Fourier transform to process global frequency components. This strategy capitalizes on the spectral convolution theorem and emphasizes the frequency content of reconstructing global information, thereby improving pan-sharpening performance.
3.3 Proposed Core Building Blocks
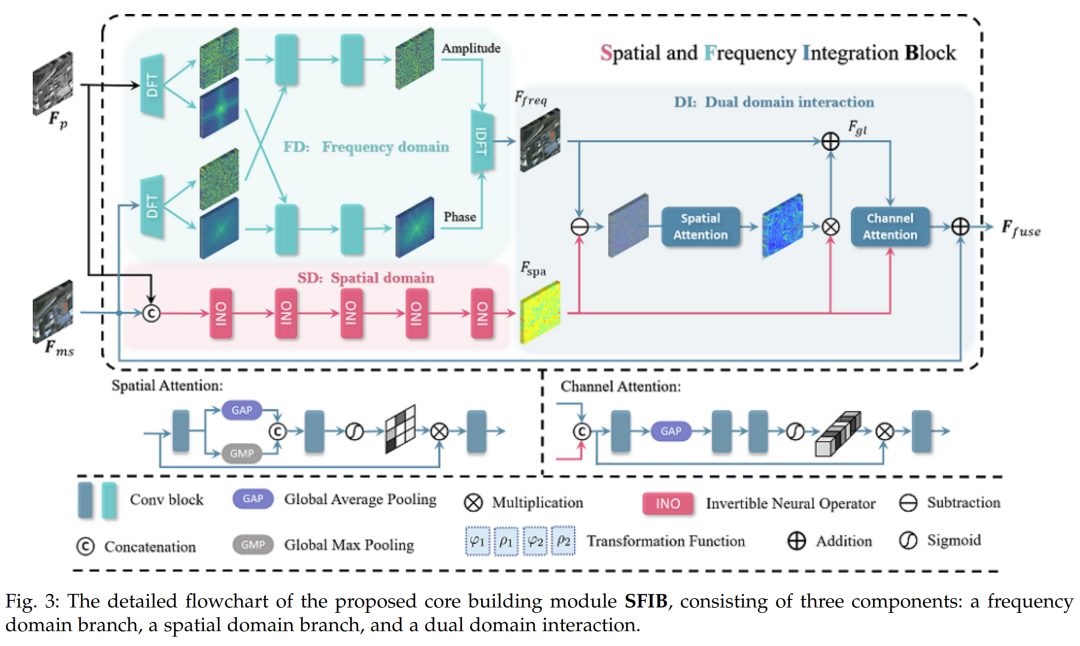
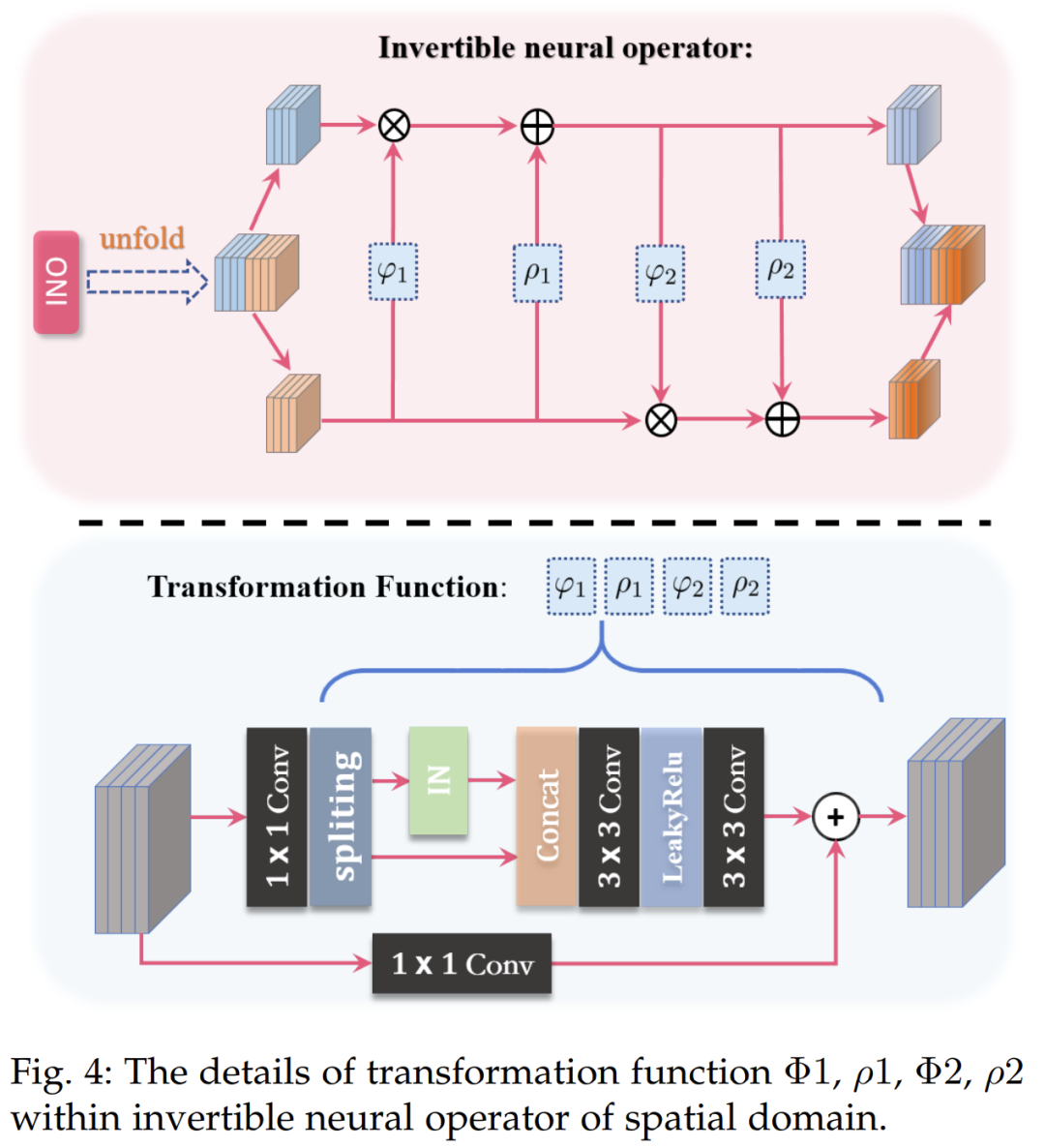
To outline our basic building blocks, Figure 3 depicts its three key components. First, the frequency domain branch utilizes deep Fourier transforms to extract global frequency information representation. Second, the spatial information branch employs reversible neural operators to explore local information. Third, the dual-domain information interaction facilitates the flow of information between frequency and spatial domains, enabling the learning of complementary representations. Frequency Domain Branch. In the frequency branch, we first perform the Fourier transform on the modality-aware features of MS and PAN images to obtain their amplitude and phase components. Specifically, let the feature representations of PAN and MS images be denoted as $F_i^p$ and $F_i^{ms}$, respectively, their Fourier transforms can be expressed as follows:$$A(F_i^p), P(F_i^p) = F(F_i^p),$$$$A(F_i^{ms}), P(F_i^{ms}) = F(F_i^{ms}),$$where the amplitude and phase components are represented by $A(\cdot)$ and $P(\cdot)$, respectively. Then, we adopt two sets of independent operations, denoted as $O_A(\cdot)$ and $O_P(\cdot)$, including $1 \ imes 1$-kernel convolution and ReLU activation function. These operations integrate the respective amplitude and phase components to produce improved global frequency representations:$$A(F_i^{pm}) = O_A(Cat[A(F_i^p), A(F_i^{ms})]),$$$$P(F_i^{pm}) = O_P(Cat[P(F_i^{ms}), P(F_i^{ms})]),$$where $Cat[ \cdot ]$ denotes the channel-wise concatenation operation. Then, we apply the inverse DFT to convert the fused amplitude and phase components back to the spatial domain:$$F_i^{fre} = F^{-1}(A(F_i^{pm}), P(F_i^{pm})).$$The spectral convolution theorem in Fourier theory states that processing information in Fourier space can capture global frequency representations. Therefore, the frequency branch generates a global information representation denoted as $F_i^{fre}$. Spatial Domain Information Branch. In contrast to the frequency domain branch, the spatial branch considers extracting local information from PAN and MS modalities. As shown in Figure 3, it employs a series of lossless information reversible neural operators to integrate the information of MS and PAN features, generating information-rich spatial representations. These operations differ from the basic convolution units used in the original spatial domain branch, resulting in our improved version SFINet++. The first reversible neural operator of the $i$-th SFIB receives $F_i^p$ and $F_i^{ms}$ as inputs and transforms them into $F_i^{sp}$ and $F_i^{sms}$ through coupled affine transformation operations, as detailed in Figure 4:$$F_i^{sp} = F_i^p \\odot \\exp(\varphi_1(F_i^{ms})) + \rho_1(F_i^{ms}),$$$$F_i^{sms} = F_i^{ms} \\odot \\exp(\varphi_2(F_i^p)) + \rho_2(F_i^p),$$where $ ext{exp}(\cdot)$ denotes the exponential function in mathematics, and $ ext{varphi}(\cdot)$ and $
ho(\cdot)$ represent the scaling and translation functions, respectively. The Hadamard product is denoted by the symbol $\odot$. Note that the scaling and translation functions are not necessarily invertible. When passing through the final reversible neural operator, the fused spatial representation $F_i^{spa}$ can be obtained. A deeper investigation into the transformation functions $\Phi_1, \rho_1, \Phi_2, \rho_2$ in the reversible neural operators shows that to endow them with transformation capabilities, we adopt the instance normalization as shown in Figure 4, taking $F_i^p$ as an example, which first projects $F_i^p$ onto $F_i^{ep}$ using a $1 \ imes 1$-kernel convolution $Conv(\cdot)$, and then uniformly splits it into two parts $F_i^{1ep}, F_i^{2ep}$, which are processed through identity and instance normalization, respectively, and integrated through convolution units to obtain $F_i^{sip}$:$$F_i^{ep} = Conv(F_i^p),$$$$F_i^{1ep}, F_i^{2ep} = \text{split}(F_i^{ep}),$$$$F_i^{sip} = Conv(Cat[IN(F_i^{1ep}), F_i^{2ep}]).$$The information representations generated by the spatial and frequency domain branches are complementary. Therefore, their interaction and integration can compensate for each other and produce more effective information representations. For visualizations, please refer to Section 4.5 and Figure 8. Dual-Domain Information Interaction. Dual-domain information interaction can be divided into two parts: information compensation and information integration. (a) Information compensation involves extracting different components of local spatial information $F_i^{spa}$ to compensate for global frequency information $F_i^{fre}$, as they are complementary. To achieve this, the absolute difference between $F_i^{fre}$ and $F_i^{spa}$ is computed, utilizing a spatial attention mechanism $SA(\cdot)$ to capture spatial dependencies. The output spatial attention map is multiplied by $F_i^{spa}$ to select information content, which is then applied to the global frequency representation $F_i^{fre}$ to obtain the enriched representation $F_i^{gl}$:$$F_i^{gl} = F_i^{fre} + SA(F_i^{fre} – F_i^{spa}) \times F_i^{spa}.$$$SA(\cdot)$ is detailed in the lower-left corner of Figure 3. By calculating the absolute difference between $F_i^{fre}$ and $F_i^{spa}$, the spatial attention mechanism focuses on “where” the information is. Average pooling and max pooling operations along the channel axis are applied and concatenated to create a simplified feature descriptor, effectively highlighting important areas. Pooling operations along the channel axis have been proven effective for this purpose. Subsequently, a convolution layer is applied to the concatenated feature descriptor, producing our spatial attention map $F_i^{spa}$, which indicates areas to be emphasized or suppressed. We compute the spatial attention as follows:$$F_i^{spa} = \sigma(Conv(Cat[F_i^{avg}, F_i^{max}])),$$where $\sigma$, $Cat(\cdot)$, and $Conv$ denote the sigmoid function, channel-wise concatenation operator, and $3 \ imes 3$-kernel convolution, respectively. (b) Information integration: Once the enhanced global frequency features $F_i^{gl}$ are obtained, they are combined with the local features $F_i^{spa}$ and processed through channel attention $CA(\cdot)$. This process allows for leveraging relationships between channels, enabling complementary learning and providing a more informative feature representation $F_i^{fuse}$. The input MS features $F_i^{ms}$ are subsequently added to the fused features through residual learning:$$F_i^{fuse} = CA(Cat[F_i^{gl}, F_i^{spa}]) + F_i^{ms}.$$In Figure 3, the details of $CA(\cdot)$ are summarized in the lower-right corner. Channel attention involves extracting meaningful “what” from the input features. Similar to $SA(\cdot)$, the spatial dimension is compressed through average pooling. The resulting descriptor is then fed into a hidden-layer multi-layer perceptron (MLP) to generate the channel attention map $F_i^{cha} \\in \\mathbb{R}^{C \ imes 1 \ imes 1}$. In summary, channel attention is computed as follows:$$F_i^{cha} = \sigma(AvgPool(Conv(Cat[F_i^{gl}, F_i^{spa}])))$$$$F_i^{cha} = F_i^{cha} \odot Conv(Cat[F_i^{gl}, F_i^{spa}]).$$Here, $\sigma$ and $Conv$ denote the sigmoid function and $3 \ imes 3$-kernel convolution, respectively. With the core building blocks in place, our proposed network possesses the capability to model and integrate global and local information representations by exploring the potential of spatial and frequency domains.
3.4 Loss Function
Let $H$ and $GT$ denote the network output and the corresponding ground truth, respectively. To enhance the quality of pan-sharpening results, we propose a joint spatial-frequency domain loss to supervise network training. In the spatial domain, we use L1 loss, given as:$$L_{spa} = \|H – GT\|_1.$$In the frequency domain, the proposed method adopts DFT to transform the predicted output $H$ and the corresponding ground truth $GT$ into Fourier space, obtaining amplitude and phase components. We then compute the amplitude and phase differences between $H$ and $GT$, using the L1 norm and summing them to generate the total frequency loss, which can be expressed as:$$L_{fre} = \|A(H) – A(GT)\|_1 + \|P(H) – P(GT)\|_1.$$Finally, the overall loss function is expressed as a weighted sum of spatial and frequency losses:$$L = L_{spa} + \lambda L_{fre},$$where $\lambda$ is a weight factor empirically set to 0.1.
4 Pan-Sharpening Experiments
In this study, our goal is to evaluate the effectiveness of our proposed method in the pan-sharpening task through comprehensive performance comparisons with several representative pan-sharpening methods, including traditional and state-of-the-art deep learning-based methods. Traditional methods include SFIM[42], Brovey[43], GS[44], IHS[45], and GFPCA[46]. The deep learning-based methods considered in the comparison include PNN[1], PANNET[17], MSDCNN[47], SRPPNN[20], GPPNN[48], FAFNet[25], and MutNet[23]. Through this comparison, we aim to demonstrate the superior performance of our proposed method and prove its advantages over existing state-of-the-art methods in pan-sharpening.
4.1 Implementation
In this study, we implemented our network using the PyTorch framework and a single NVIDIA GeForce GTX 2080Ti GPU. During the training phase, we used the Adam optimizer for 1000 epochs with a batch size of 4 and a learning rate of $5 \times 10^{-4}$. The learning rate was reduced by half after 200 epochs. To generate the training set, we used the Wald protocol tool[49], as the ground truth for pan-sharpened images is not available. Specifically, we obtained downsampled MS image $GT \\in \\mathbb{R}^{M \ imes N \ imes C}$ and PAN image $Pa \\in \\mathbb{R}^{M_r \ imes N_r \ imes b}$ by downsampling the MS image and PAN image by $r$ times, respectively. During training, $L$ and $P$ are used as inputs, while $GT$ serves as the ground truth.
4.2 Evaluation
The IQA metrics used for evaluation include ERGAS, PSNR, SSIM, SAM, SCC, Q-index, Dλ, DS, and QNR. These metrics are widely used in the image processing community to assess the quality of pan-sharpened images. The evaluation is conducted on three satellite image datasets: WorldviewII, Worldview-III, and GaoFen2. For each dataset, the PAN images are cropped into $128 \ imes 128$ pixel patches, while the corresponding MS patches are resized to $32 \ imes 32$ pixels. The scarcity of real high-resolution “ground truth” data in pan-sharpening arises from the complexity of the fusion process, challenges in acquiring real-world high-resolution images, potential temporal variations of the Earth’s surface, and the ongoing evolution of pan-sharpening algorithms. This complexity hinders the establishment of accurate and current reference data. Simultaneously acquiring high spatial and spectral resolution images in pan-sharpening faces challenges stemming from the complexities of remote sensing data acquisition, sensor design, and technological limitations. Developing sensors capable of capturing both high spatial and spectral resolution simultaneously requires complex optical and electronic components, introducing higher costs and technical complexities. Furthermore, the pursuit of high spectral resolution may lead to band overlap, reducing the uniqueness of spectral information. Addressing the greater storage and transmission capacity needs for high-resolution remote sensing data introduces additional complexities in data management. Optical and physical limitations may further hinder the simultaneous capture of high spatial and spectral resolution in a single sensor, increasing the complexity of integrating both types of information. To evaluate the generalization performance of our proposed method, we assembled an additional real-world dataset comprising 200 samples from Gaofen-2 and WorldView-II satellites. Unlike the previous synthetic low-resolution dataset, this full-resolution dataset does not include any PAN images downsampled to $32 \ imes 32$ and MS images to $128 \ imes 128$ resolution. PAN and MS images are generated using the same method as before. Given the lack of real MS images, we employed three commonly used IQA metrics—the spectral distortion index Dλ, spatial distortion index DS, and no-reference quality (QNR)—to evaluate our model.
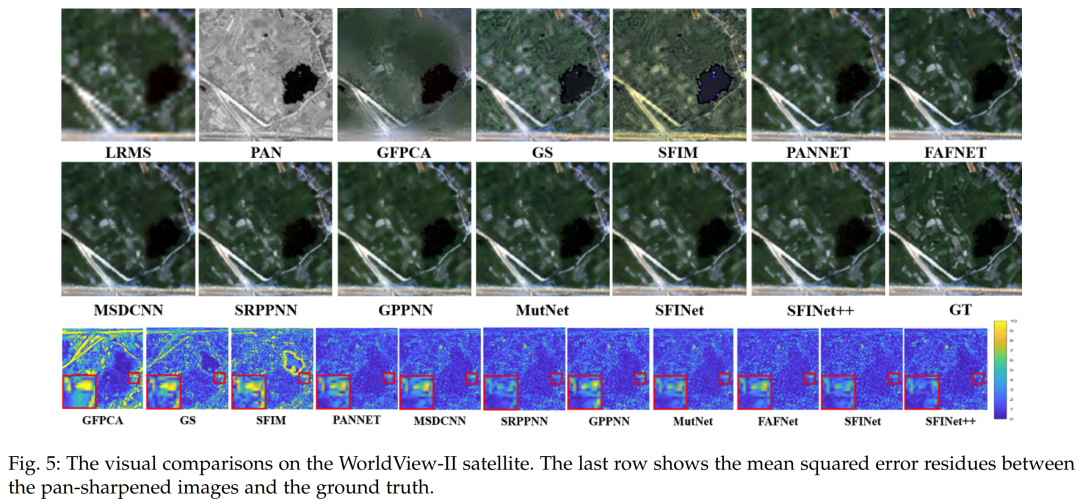
4.3 Comparison
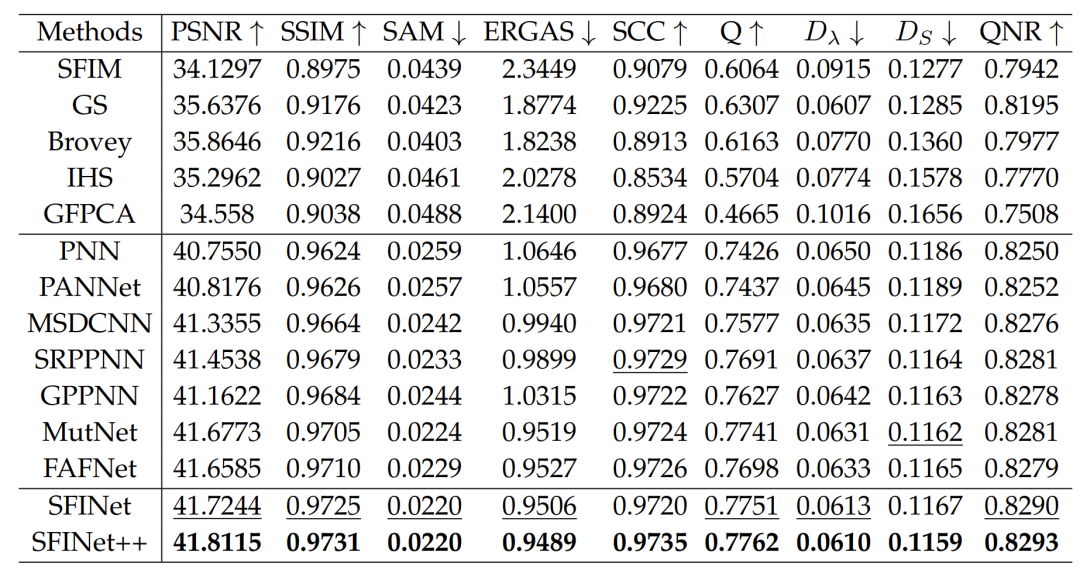
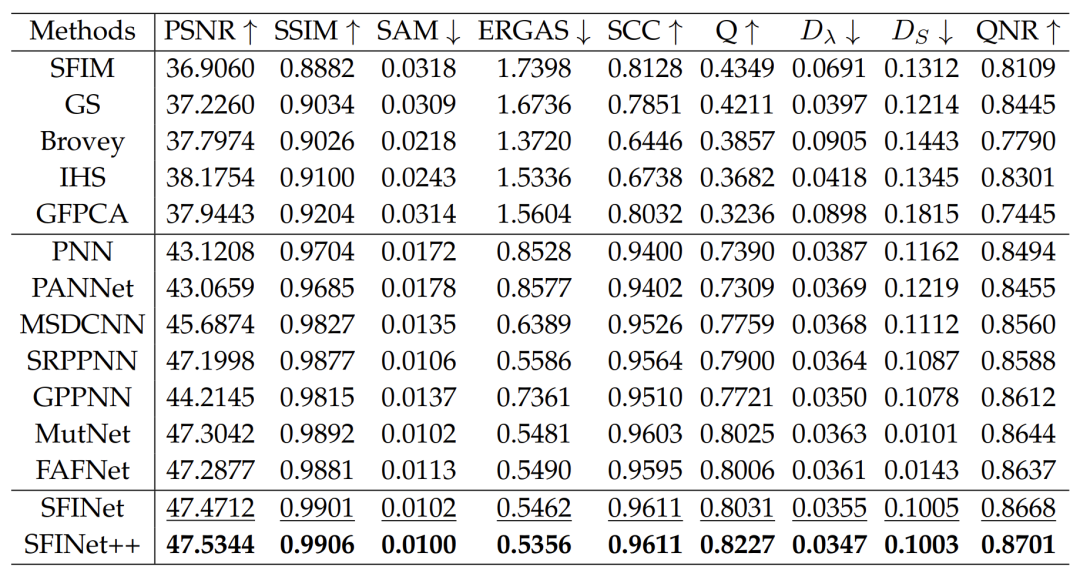
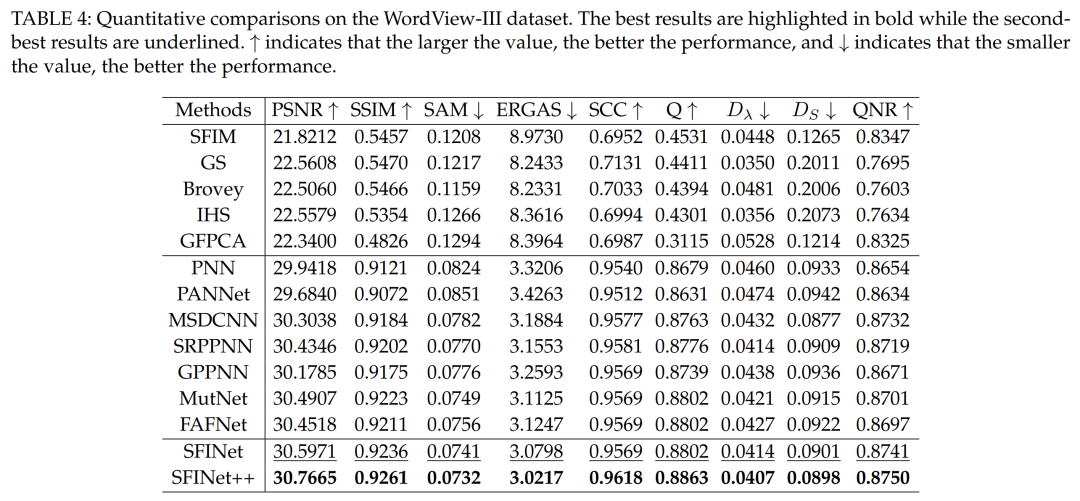
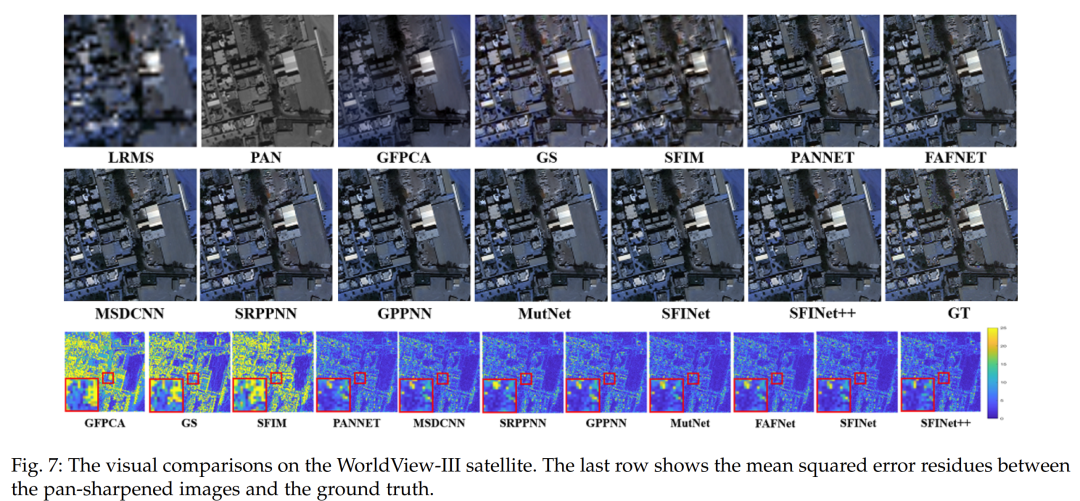
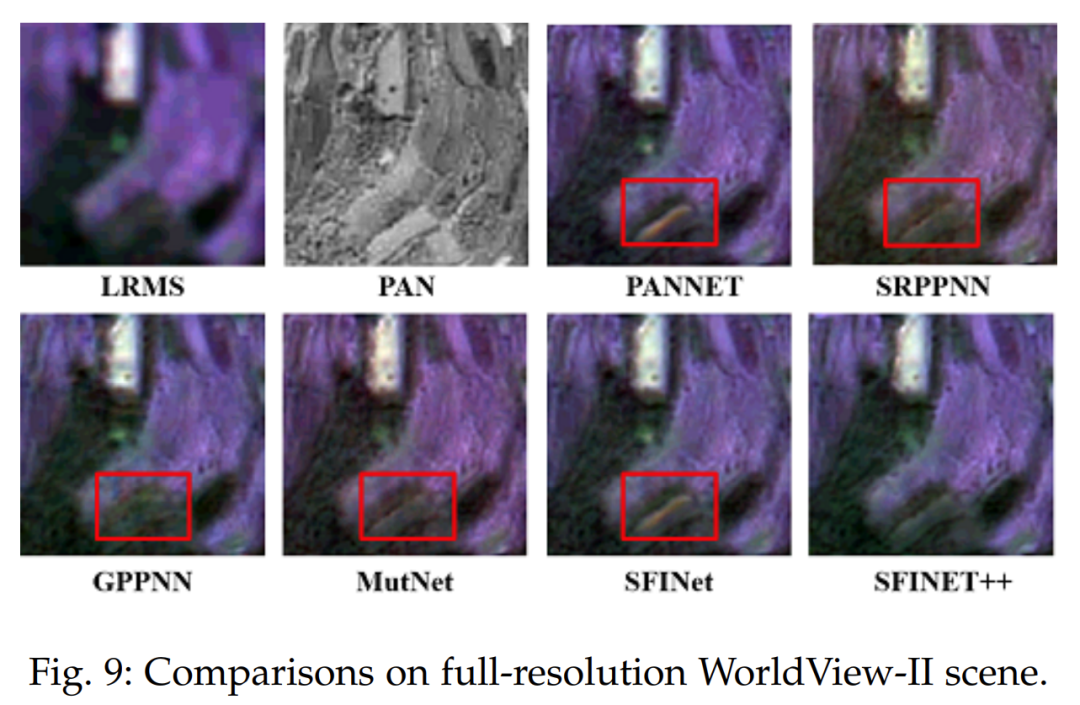
Evaluation in Low-Resolution Scenarios. In this section, we present the performance evaluation results of our proposed pan-sharpening methods, SFINet and SFINet++, on three different satellite datasets, namely WorldView-II, GaoFen2, and WorldView-III. The performance of the proposed methods is evaluated using various assessment metrics, with results listed in Tables 1, 2, and 4, where superior performance is highlighted in bold. The results indicate that our proposed methods, SFINet and SFINet++, outperform the best-performing algorithms by 0.1 dB, 0.17 dB, and 0.09 dB in PSNR results on the WorldView-II, GaoFen2, and WorldView-III datasets, respectively. Furthermore, our methods also demonstrate considerable improvements in other evaluation metrics, confirming their superiority over existing state-of-the-art deep learning-based methods. To further support the effectiveness of our proposed methods, we showcase visual comparisons of representative sample results on the WorldView-II, GaoFen2, and WorldView-III datasets in Figures 5, 6, and 7. The last row of each figure displays the mean square error (MSE) residual between the pan-sharpened images and the ground truth. It can be observed that our proposed methods significantly reduce spatial and spectral distortions compared to other methods, as evidenced by the MSE residual maps. Additionally, the enlarged regions of the MSE residual maps indicate that our proposed methods SFINet and SFINet++ tend to be bluer, while other methods involve more yellow, indicating poorer spatial distortion. These visual comparisons further demonstrate that our proposed methods achieve state-of-the-art performance and surpass existing pan-sharpening algorithms.Evaluation in Full-Resolution Scenarios. To evaluate the generalization capability of our network in full-resolution scenarios, the model trained on the GaoFen2 dataset is applied to previously unseen full-resolution GaoFen2 and WorldView-II satellite datasets. The experimental results are listed in Tables 5 and 6, where it can be observed that our proposed methods significantly outperform other traditional and deep learning-based methods across all evaluation metrics. Compared to the previous version, the improved SFINet++ achieves better performance, demonstrating spectral consistency and spatial texture reconstruction. This proves that our proposed methods exhibit superior generalization capabilities compared to others. Visual comparisons are presented in Figures 9 and 10. In this full-resolution scenario, visual evaluation requires using the PAN image as a spatial reference and the LRMS image as a spectral reference. While many comparative methods achieve enhanced details, SRPPNN [20] and MutNet [23] exhibit compromises in spectral accuracy. Additionally, PANNET [17] and GPPNN [48] show irregular structures or artifacts. In contrast, our enhanced SFINET++ achieves a better balance between spatial enhancement and spectral consistency.
4.4 Parameter and Model Performance Analysis
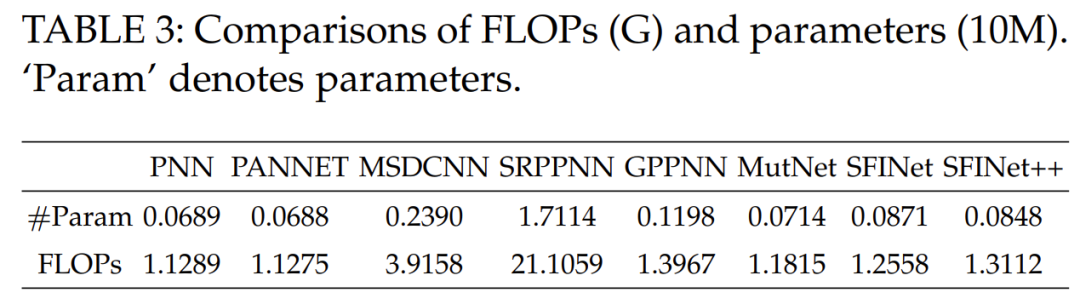
To comprehensively analyze the proposed method, we investigated its complexity in terms of the number of parameters (in 10M) and floating-point operations (FLOPs), as shown in Table 3. The proposed method achieves optimal performance while containing the second least number of parameters. Notably, PNN [1] and PANNET [17] have the least number of parameters due to their simple network architectures, but they perform poorly. Additionally, while SRPPNN [20] and MutNet [23] achieve promising performance, their number of parameters exceeds that of our proposed method. Our proposed method strikes a good balance between model complexity and performance. Therefore, our network achieves optimal performance with a relatively low number of parameters, indicating a favorable balance between complexity and performance.
4.5 Dual-Domain Feature Visualization
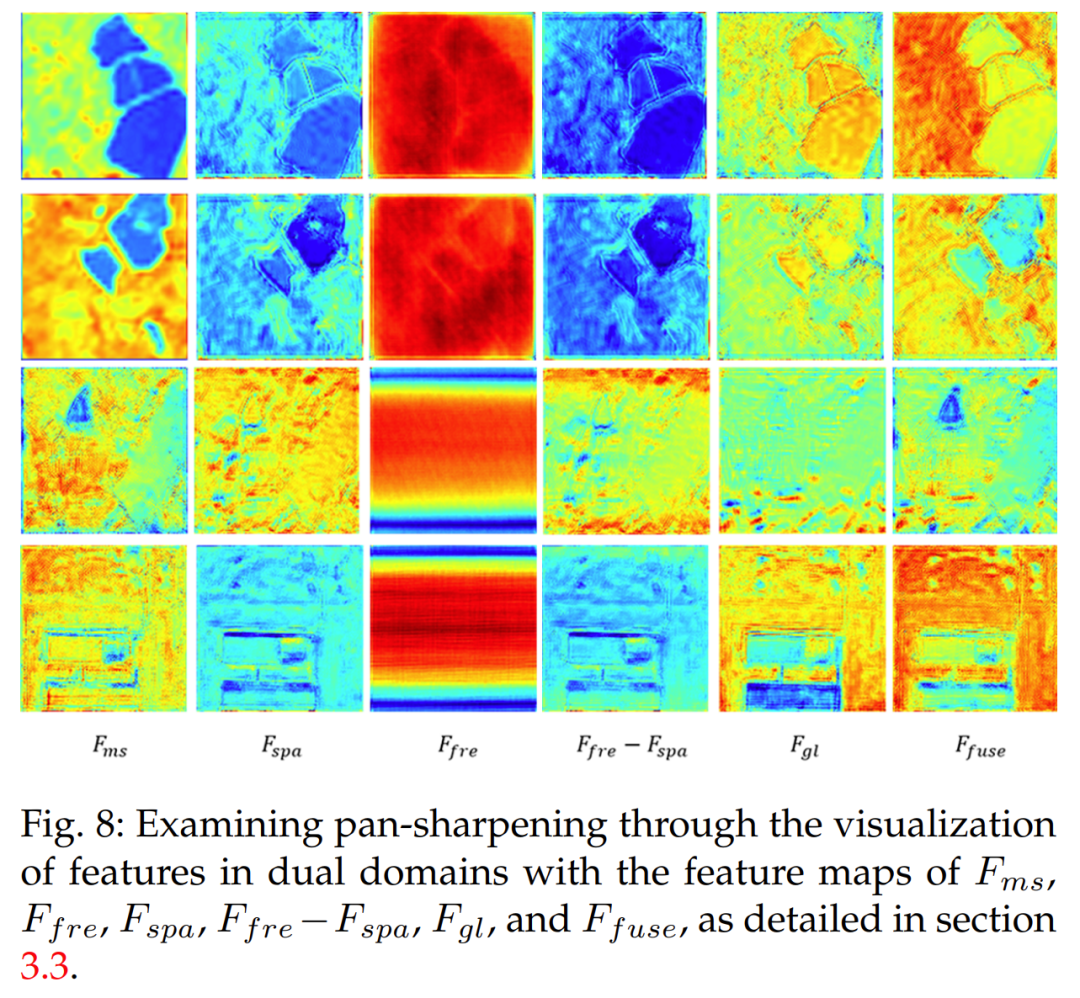
To validate the contribution of the designed dual-domain information integration mechanism, we deeply investigated the feature maps of Fms, Ffre, Fspa, Ffre − Fspa, Fgl, and Ffuse. As described in Section 3.3, the frequency features Ffre and spatial features Fspa are complementary. Figure 8 shows that Ffre captures global information but lacks detailed specifics, while Fspa focuses on capturing local texture details. The frequency-spatial differential feature Ffre − Fspa captures spectral information but neglects spatial details. The fused feature map Ffuse provides a comprehensive representation of the input image by integrating these features. These results indicate that the proposed dual-domain information integration mechanism effectively fuses complementary information from multiple domains, thereby enhancing model performance.
5 Depth Image Super-Resolution Experiments
This section presents a series of experiments aimed at evaluating the effectiveness of our proposed method in the depth image super-resolution task. To this end, we adopted the experimental protocol proposed in [39], where the evaluation datasets are generated using two different down-sampling operations: bicubic down-sampling and direct down-sampling. In the following sections, we will detail the experimental settings and results.
5.1 Datasets and Metrics
The NYU v2 dataset[50], which contains 1449 pairs of RGB-D images captured using structured light by the Microsoft Kinect sensor, was used as a widely recognized benchmark for evaluating depth image SR methods. As in previous works[39],[51], the first 1000 pairs of RGB-D images were used for training the proposed network, while the remaining 449 pairs were used for model evaluation. To generate low-resolution depth maps, we followed the experimental protocol in [39], applying bicubic and direct down-sampling operations to down-sample the images at different ratios (×4, ×8, and ×16). The performance of the model is evaluated using the root mean square error (RMSE) metric, which is commonly used in the depth image SR field. To assess the potential generalization capability of our proposed model, we adopted the same experimental settings as in [39] and directly applied our trained model to two additional benchmark datasets: Middlebury[52] and Lu[53]. The Middlebury dataset contains 30 pairs of RGB-D images, including 21 pairs from 2001[54] and 9 pairs from 2006[55]. On the other hand, the Lu dataset consists of 6 pairs of RGB-D images. To ensure a fair evaluation, we quantized all reconstructed depth maps to 8 bits before calculating the mean absolute error (MAE) or root mean square error (RMSE) values. As in previous works[39],[56],[57], lower values of these metrics indicate superior performance.
5.2 Implementation
In our experiments, we utilized the baseline implementation from [39] during the training phase. To optimize our model, we adopted the Adam optimizer[58] with β1 = 0.9, β2 = 0.999, ϵ = 1e − 8. We initialized the learning rate to 2 × 10 − 4 and decayed it by half every 100 epochs. Additionally, to generate our model inputs, we applied bicubic upsampling to the low-resolution depth images. We also provide the implementation in MindSpore.
5.3 Experimental Results of Bicubic Down-Sampling
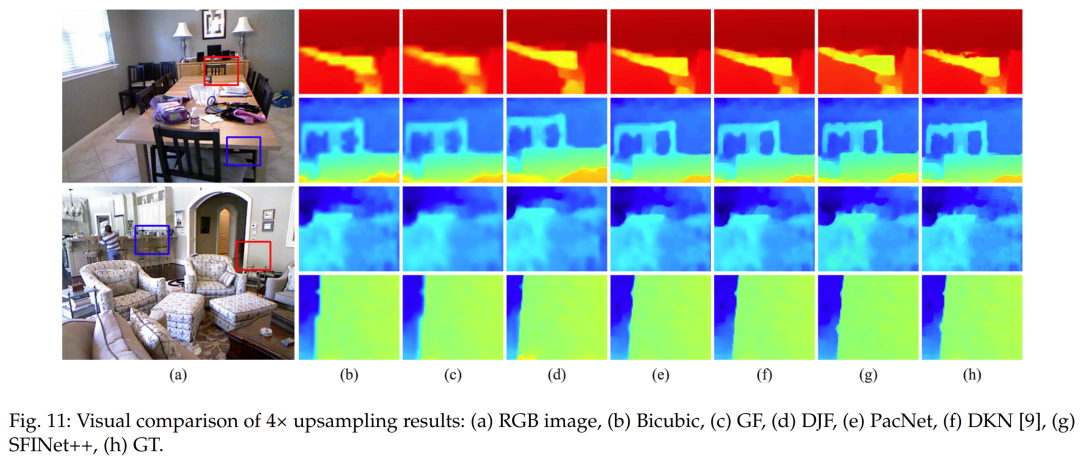
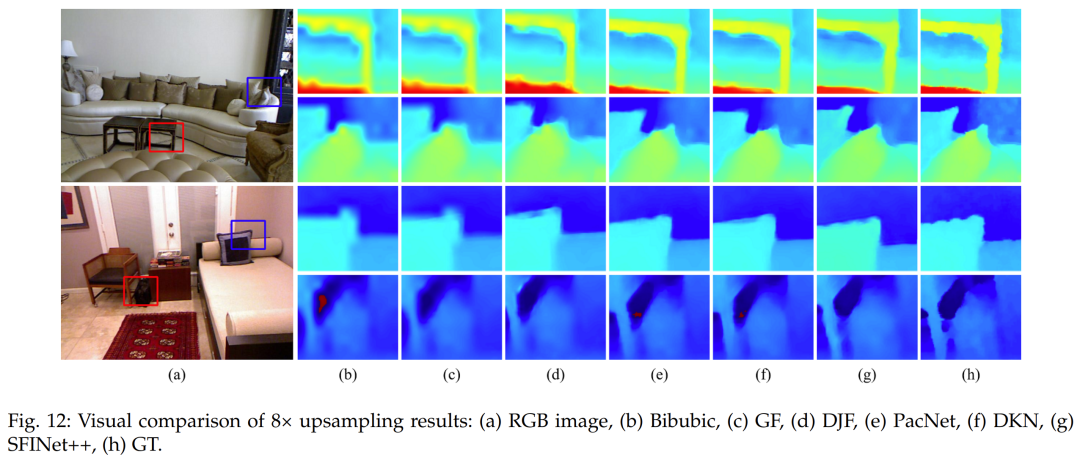
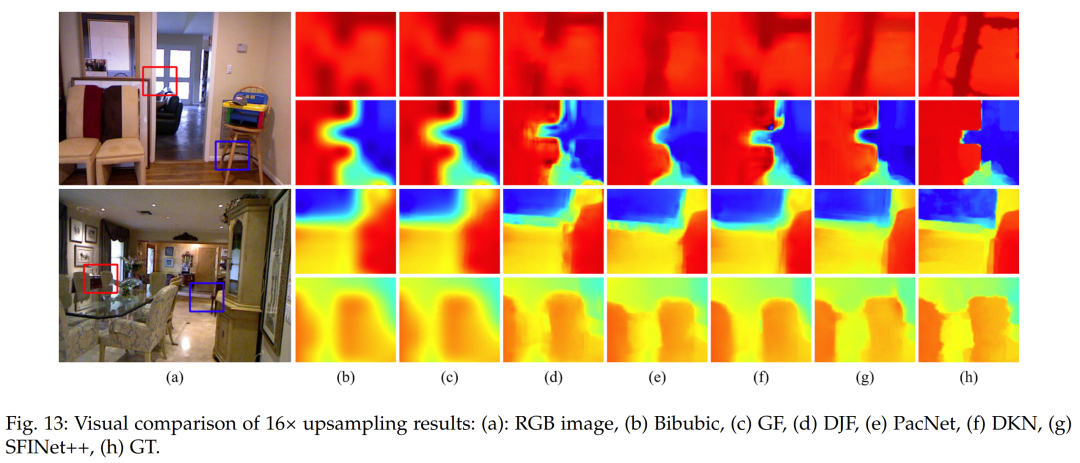
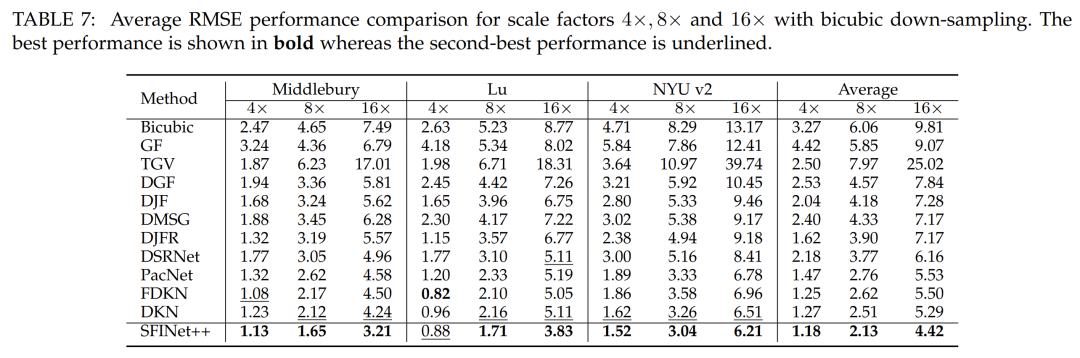
To evaluate the effectiveness of our proposed method in the case of bicubic down-sampling, we conducted a comparative analysis with other state-of-the-art depth image SR algorithms outlined in [39]. Selected algorithms include traditional methods such as guided image filtering (GF)[59] and total variation (TGV)[60], as well as deep learning-based methods such as DGF[61], DJF[62], DMSG[63], deep joint image filtering (DJFR)[51], depth super-resolution network (DSRNet)[56], pixel-adaptive convolution (PacNet)[64], fast deformable kernel network (FDKN)[39], and deformable kernel network (DKN)[39]. To ensure a fair comparison, we report the quantitative evaluation results, namely the average RMSE values between the generated HR depth maps and the ground truth, as reported in the original papers for each method. We report results for different down-sampling ratios, i.e., ×4, ×8, and ×16, in Table 7. Table 7 presents the quantitative evaluation of several state-of-the-art depth image super-resolution algorithms for the specific bicubic down-sampling case. Our proposed method outperforms the comparative methods in average RMSE values across scaling factors of ×4, ×8, and ×16. The deep learning-based techniques, namely DKN[39], DSRnet[56], PacNet[64], DMSG[63], and DJFR[51], exhibit a considerable performance boost compared to traditional methods like GF[59] and TGV[60]. This superiority can be attributed to the strong learning and mapping capabilities of deep neural networks. Our proposed method outperforms the second-best performer, DKN[39], in average RMSE on all three datasets by 0.09 (4×), 0.38 (8×), and 0.87 (16×). Our model was trained solely on the NYU v2 dataset and was not fine-tuned on other datasets such as Middlebury and Lu. Nevertheless, our method still reduces the average RMSE on the Middlebury dataset[52] by 0.1 (4×), 0.47 (8×), and 1.03 (16×) compared to DKN[39], and reduces it by 0.08 (4×), 0.45 (8×), and 1.28 (16×) on the Lu dataset[53]. Thus, our method demonstrates superior generalization capabilities compared to other methods. In addition to the quantitative analysis, visual assessments were also conducted to further evaluate the performance of our proposed method against others. Figures 11, 12, and 13 showcase the HR depth maps generated by various methods. Notably, other methods exhibit certain limitations, such as GF[59] producing overly smoothed images due to the limited capacity of local filters to capture global information. Similarly, DJFR[51] and DKN[39] have artifact issues. While PacNet[64] retains local details, it performs poorly in reconstructing boundaries. In contrast, our proposed method enhances the spatial details of the LR depth maps, generating accurate and clear edges.
5.4 Experimental Results of Direct Down-Sampling
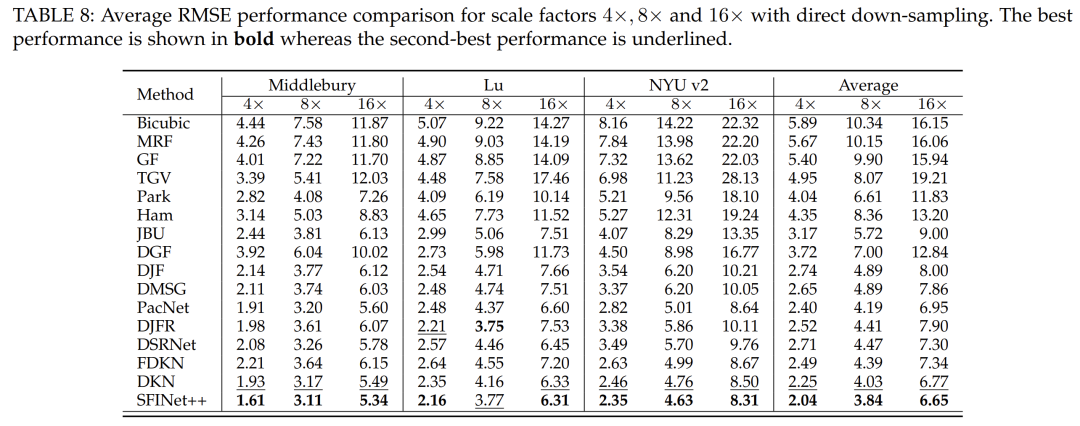
In this study, we compared our proposed method with several state-of-the-art techniques in the context of direct down-sampling. These techniques include bicubic upsampling, MRF, GF, TGV, Park, JBU, DJF, dDMSG, PacNet, DJFR, DSRNet, FDKN, and DKN. To ensure fairness, the average RMSE values of other competing methods are obtained directly from their original papers. Comparisons are made at three different down-sampling ratios, namely ×4, ×8, and ×16, with results listed in Table 8. As shown in Table 8, our method achieves the best performance across all scaling factors. Specifically, for the most challenging 16× scenario, our method outperforms all other methods across all datasets. Compared to the second-best method, DKN [39], our method reduces the average RMSE by 0.21 (4×), 0.19 (8×), and 0.12 (16×). Furthermore, to evaluate generalization capabilities, we trained our model on the NYU v2 dataset and then applied it to two other datasets, namely the Middlebury dataset and the Lu dataset. Our method outperformed other methods on these datasets, demonstrating its strong generalization capabilities. For instance, compared to DKN [39], our method reduces the average RMSE on the Middlebury dataset [52] by 0.32 (4×), 0.06 (8×), and 0.15 (16×). Similarly, our method reduces the average RMSE on the Lu dataset [53] by 0.19 (4×), 0.39 (8×), and 0.02 (16×).
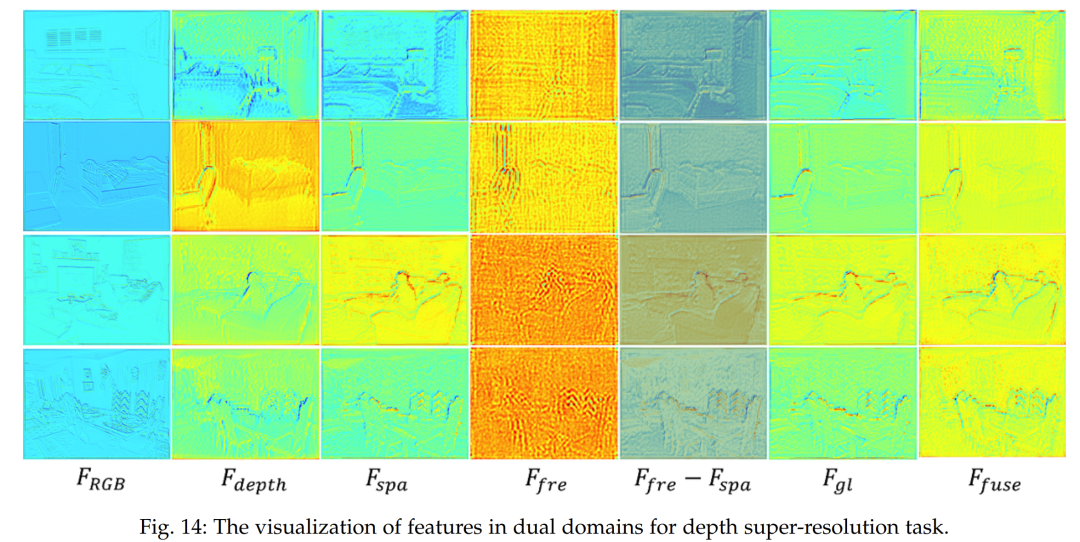
5.5 Dual-Domain Feature Visualization for Depth Image Super-Resolution
To explore the potential mechanisms of the proposed core module, we visualized the feature maps Fdepth, FRGB, Ffre, Fspa, Ffre − Fspa, Fgl, and Ffuse, which are targeted for the direct down-sampling case in the depth image super-resolution task. As recognized, depth images and RGB images play roles in depth image super-resolution equivalent to those of MS and PAN in the pan-sharpening task. Thus, as described in Section 3.3, the definitions of Fdepth and FRGB are analogous to Fms and Fp. In the case of pan-sharpening, similar evidence can be gathered, where frequency features Ffre and spatial features Fspa exhibit complementary characteristics. Figure 14 visually confirms that Ffre captures global information while Fspa highlights local content. The resulting feature map Ffuse provides a more informative response by integrating these features.
6 Ablation Studies
This section details the ablation studies conducted to assess the effectiveness of the proposed modules in our network. The experiments were performed on the WorldView-II dataset, and the model performance was measured using IQA metrics, including ERGAS, PSNR, SSIM, SCC, Q-index, SAM, Dλ, DS, and QNR.
6.1 Impact of the Number of Core Building Modules
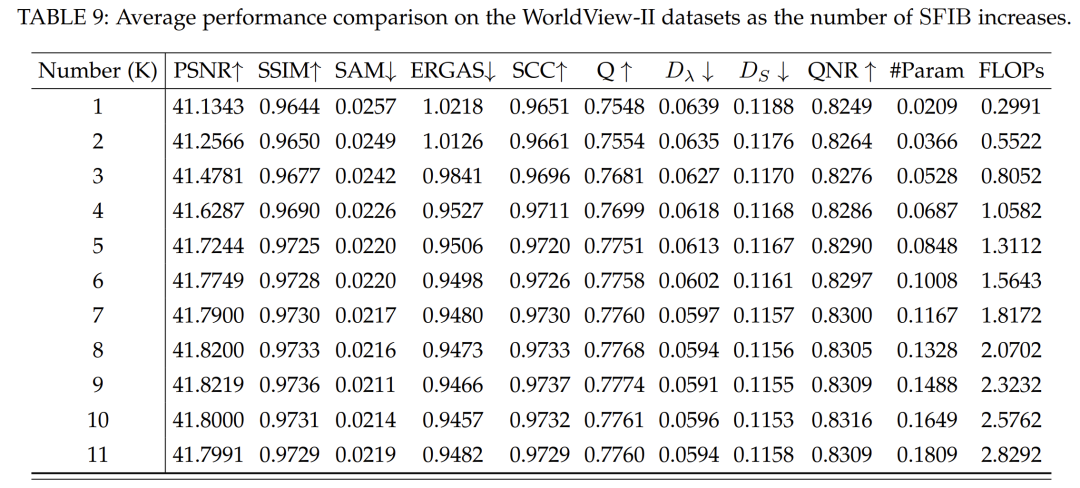
To evaluate the impact of the core building modules in our network, experiments were conducted with different K values ranging from 1 to 11, with results listed in Table 9. The results indicate that the model performance improves when K=8, increasing with computational demands. Beyond this point, the performance gain diminishes, indicating saturation. For K>9, performance declines, suggesting overfitting or redundancy, leading to complexity-related issues. In summary, there exists an optimal range of core modules that significantly enhances performance, proving cost-effective. However, beyond a threshold, diminishing returns occur. To strike a balance, K=5 is set as the default value to ensure a balance between enhancement capability and practical computational considerations.
6.2 Effectiveness of the Frequency Information Branch
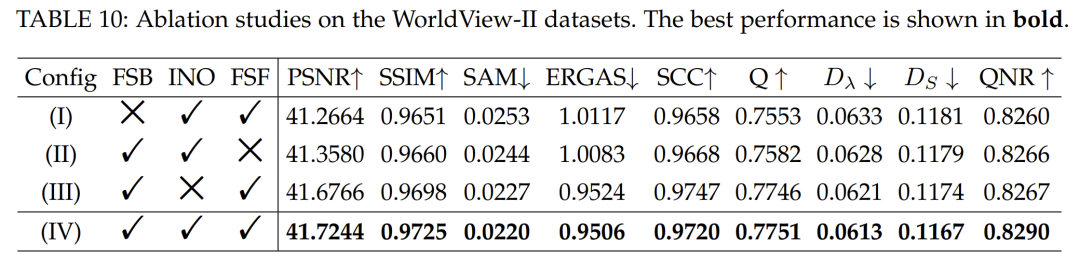
In the first set of experiments, we evaluated the impact of the frequency information branch in the core building module. This involved a performance comparison between the complete network and a variant that omitted the frequency information branch, implementing a 3×3 convolution-equipped ResNet block while maintaining consistent model parameters. The aim is to assess the effectiveness of frequency information. The results in Table 10 indicate that removing the frequency information branch leads to a significant decline in performance. This is because the frequency information branch is crucial for simulating global frequency information to produce high-quality pan-sharpened images. Without it, the network fails to capture frequency information accurately, thus degrading pan-sharpening performance.
6.3 Effectiveness of Reversible Units
In the next set of experiments, we conducted evaluations to study the role of reversible units (INO) within the core building module. This included a comparative analysis of the overall performance of the network with and without reversible units. The variant without reversible units was implemented using 3×3 convolution blocks while keeping model parameters consistent. The primary objective is to distinguish the specific impact of reversible units on the pan-sharpening process. The results in Table 10 indicate that removing the reversible units results in significant changes in performance metrics.
6.4 Effectiveness of Frequency Loss
In this study, we introduced a new frequency loss function, primarily aimed at directly optimizing global frequency information. To evaluate its effectiveness, the second experiment in Table 10 involved removing the frequency loss. Experimental results indicate that the removal of frequency loss leads to severe degradation of all metrics, as observed in the significant drops noted in Table 10. This finding underscores the critical role of the frequency loss function.
7 Conclusion
In this work, we proposed a novel approach to address the multimodal image fusion problem by integrating high spatial resolution guiding images and low-resolution target images in both spatial and frequency domains. This is the first attempt to re-examine the inherent mechanisms of the corresponding degradation and tailor an effective spatial-frequency dual-domain information integration framework. To validate the effectiveness of our method, we conducted extensive experiments and comparisons with state-of-the-art methods. The experimental results in the two typical multimodal image fusion tasks of pan-sharpening and depth super-resolution demonstrate the good performance of our method.
Statement
The content of this article is a sharing of learning outcomes from the paper. Due to limitations in knowledge and ability, there may be deviations in understanding the original text, and the final content shall be subject to the original paper. The information in this article aims for dissemination and academic exchange, and the content is the responsibility of the author and does not represent the views of this account. If any content, copyright, or other issues related to works such as text and images in this article are involved, please contact us in a timely manner, and we will respond and handle it as soon as possible.