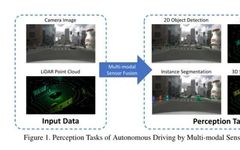
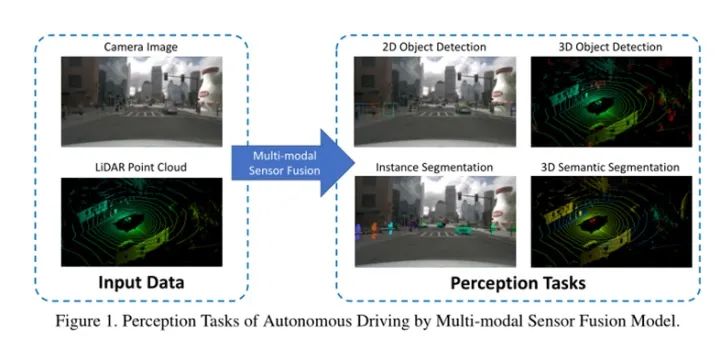
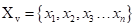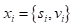Introduction
Multi-modal fusion is a crucial task in the perception of autonomous driving systems. This article will detail the multi-modal perception methods for autonomous driving, including object detection and semantic segmentation tasks involving LiDAR and cameras.
From the perspective of the fusion stage, existing solutions are categorized into data-level, feature-level, object-level, and asymmetric fusion. Furthermore, this article raises challenging questions in the field and opens discussions on potential research opportunities.
Background of Multi-Modal Fusion Perception
Perception using single-modal data has inherent flaws, as camera data is mainly captured at lower positions in the front view. In more complex scenarios, objects may be occluded, posing severe challenges to object detection and semantic segmentation.
Additionally, due to mechanical constraints, LiDAR has varying resolutions at different distances and is susceptible to extreme weather conditions such as heavy fog and rain.
Thus, the complementarity of LiDAR and cameras results in better performance in combined perception. Perception tasks include object detection, semantic segmentation, depth completion, and prediction, with a primary focus on the first two tasks.
Data Format
Cameras provide RGB images rich in texture information. Specifically, for each pixel of the image (u, v), it has a multi-channel feature vector F(u,v) = {R, G, B, …}, typically containing the red, blue, and green channels captured by the camera or other manually designed features as grayscale channels.
However, due to limited depth information that is difficult to extract from monocular cameras, directly detecting objects in 3D space poses challenges. Consequently, many solutions utilize binocular or stereo camera systems to leverage additional information for 3D object detection through spatial and temporal dimensions, such as depth estimation and optical flow.
LiDAR uses a laser system to scan the environment and generate point clouds. Generally, most LiDAR raw data is represented as quaternions, such as (x, y, z, r), where r represents the reflectance of each point.
Different textures lead to varying reflectance; however, the quaternion representation of points may contain redundancy or speed defects. Therefore, many researchers attempt to convert point clouds into voxels or 2D projections before feeding them into downstream modules.
Some works have discretized the 3D space into 3D voxels, represented as:
Where each xix_{i} represents a feature vector, such as:
sis_{i} represents the centroid of the voxel, while viv_{i} represents some statistical local information. Local density is defined as the number of 3D points within the local voxel. Local offsets are typically defined as the offsets between point coordinates and the local voxel centroid.
The voxel-based point cloud representation significantly reduces redundancy in unstructured point clouds compared to point-based representations mentioned above. Furthermore, utilizing 3D sparse convolution techniques not only achieves faster training speeds but also higher accuracy in perception tasks.
Some works attempt to project LiDAR data into image space in two common types, including Camera Plane Map (CPM) and Bird’s Eye View (BEV). By projecting each 3D point as (x, y, z) into the camera coordinate system (u, v), CPM can be obtained. Since CPM has the same format as camera images, it can be seamlessly fused by treating CPM as an additional channel.
However, due to the lower resolution of LiDAR after projection, many pixel features in CPM are destroyed. BEV mapping provides a high view of the scene from above. There are two reasons for using it in detection and localization tasks. Firstly, unlike cameras mounted behind the windshield, most LiDARs are located on the top of the vehicle, resulting in less occlusion.
Secondly, all objects are placed on the ground plane in BEV, allowing the model to generate predictions without distortion in length and width.
Fusion Methods
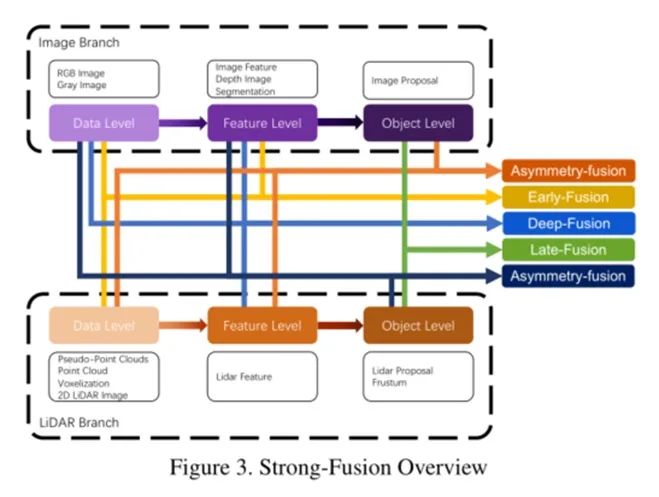
This section will review various fusion methods for LiDAR and camera data. From a traditional classification perspective, all multi-modal data fusion methods can conveniently be divided into three paradigms: data-level fusion (early-fusion), feature-level fusion (deep-fusion), and object-level fusion (late-fusion).
Data-level fusion or early fusion methods directly integrate the raw sensor data of different modalities through spatial alignment. Feature-level fusion or deep fusion methods focus on mixing cross-modal data in the feature space. Object-level fusion methods combine the prediction results of models in each modality to make the final decision.
Data-Level Fusion
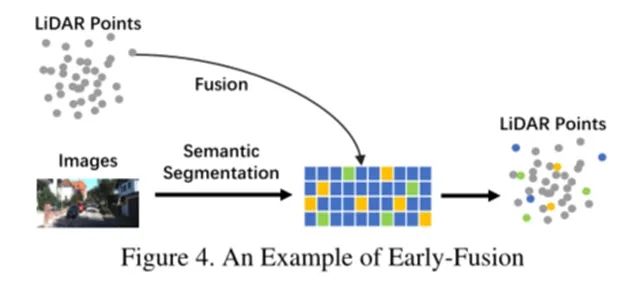
An example of a method that directly fuses each modality’s data through spatial alignment and projection is the model shown in Figure 4. It integrates semantic features from the image branch with the raw LiDAR point cloud, resulting in improved performance in object detection tasks.
3D LiDAR point clouds are converted into 2D images, utilizing mature CNN techniques to fuse feature-level representations in the image branch for better performance.
Feature-Level Fusion
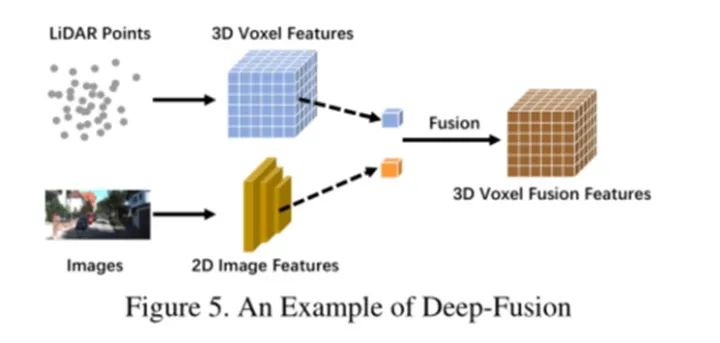
Feature-level fusion uses feature extractors to obtain embedded representations of LiDAR point clouds and camera images separately, and fuses the features of the two modalities through a series of downstream modules.
Deep fusion sometimes cascades the fusion of features, both utilizing original and high-level semantic information. An example of deep fusion can be seen in the model shown in Figure 5.
Object-Level Fusion
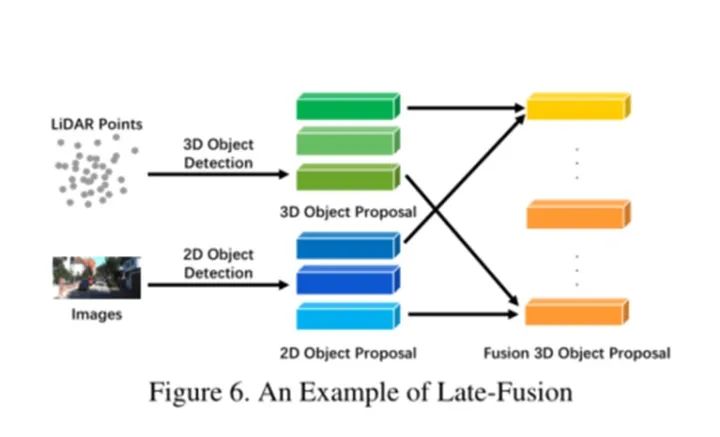
Late fusion, also known as object-level fusion, refers to methods that merge different results from each modality. For instance, some late fusion methods utilize outputs from both the LiDAR point cloud branch and the camera image branch to make final predictions based on the results of both modalities.
Note that the two branches should have the same data format as the final result, but quality, quantity, and accuracy may differ. Late fusion can be viewed as an integration method that optimizes the final proposal using multi-modal information. An example can be seen in the model shown in Figure 6.
As mentioned above, late fusion is used to refine the scores of each 3D region proposal, combining 2D proposals from the image branch with 3D proposals from the LiDAR branch. Additionally, for each overlapping region, it utilizes statistical features such as confidence scores, distances, and IoU.
Asymmetric Fusion
In addition to early fusion, deep fusion, and late fusion, some methods have different privileges for cross-modal branches. Other methods treat the two branches as seemingly equal, while asymmetric fusion has at least one branch that dominates, while the other branch provides auxiliary information to perform the final task.
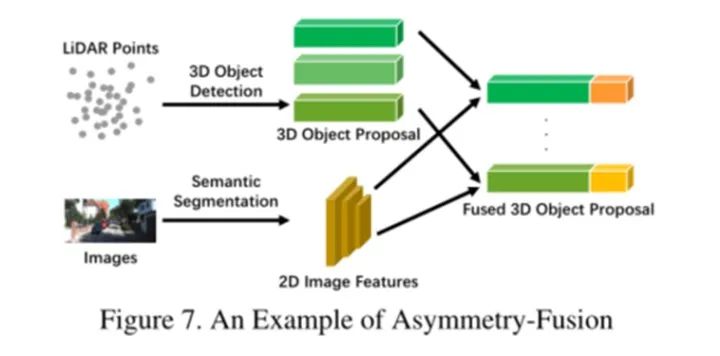
An example of late fusion can be seen in the model shown in Figure 7. Notably, compared to late fusion, although they may use proposals with the same extracted features, asymmetric fusion only has one proposal coming from one branch.
This fusion method is reasonable because using convolutional neural networks on camera data performs excellently, filtering out semantically useless points in the point cloud, extracting the frustum from the original point cloud, and the corresponding pixel’s RGB information to output the parameters of the 3D bounding box.
Using a LiDAR backbone to guide the 2D backbone in a multi-view style achieves higher accuracy. It utilizes 3D region proposals from the LiDAR branch and reprojects them to 2D, combining image features to output the final 3D proposal.
Challenges and Opportunities
In recent years, multi-modal fusion methods for autonomous driving perception tasks have made rapid progress, from more advanced feature representations to more complex deep learning models. However, some unresolved issues remain. These can be summarized in the following aspects:
Misalignment and Information Loss
The intrinsic and extrinsic differences between cameras and LiDAR are significant. Data from both modalities needs to be reorganized in a new coordinate system. Traditional early and deep fusion methods utilize external calibration matrices to directly project all LiDAR points onto corresponding pixels.
However, this pixel-wise alignment is not sufficiently accurate. Thus, we can see that, besides this strict correspondence, some methods that utilize surrounding information as a supplement yield better performance. Additionally, there are other information losses during the transformation process in input and feature spaces.
Typically, projection operations in dimensionality reduction inevitably lead to significant information loss, such as mapping 3D LiDAR point clouds to BEV images. Therefore, future work could effectively leverage original data while reducing information loss by mapping the two modalities’ data into another high-dimensional representation designed specifically for fusion.
More Rational Fusion Operations
Current research works use intuitive methods to fuse cross-modal data, such as concatenation and element-wise multiplication. These simple operations may fail to fuse data with significantly different distributions, making it challenging to bridge the semantic gap between the two modalities.
Some works have attempted to use more refined cascading structures to fuse data and improve performance. Future research could explore mechanisms such as bilinear mappings to fuse features with different characteristics.
Multi-Source Information Trade-offs
Existing methods lack effective utilization of information from multiple dimensions and sources. Most of them focus on single-frame multi-modal data in the frontal view. As a result, other meaningful information is not fully utilized, such as semantic, spatial, and scene context information.
In autonomous driving scenarios, many downstream tasks with explicit semantic information could greatly enhance the performance of object detection tasks. For example, lane detection can intuitively provide additional assistance for detecting vehicles between lanes, and semantic segmentation results can improve object detection performance.
Future research can construct a complete semantic understanding framework of urban landscape scenes by jointly detecting lanes, traffic lights, and signs, to assist the execution of perception tasks.
References
[1] Huang, K., Shi, B., Li, X., Li, X., Huang, S., & Li, Y. (2022). Multi-modal Sensor Fusion for Auto Driving Perception: A Survey. arXiv preprint arXiv:2202.02703.
ABOUT
About Us
Deep Blue Academy is committed to creating a top-notch platform for learning and communication in cutting-edge technology in China. Currently, tens of thousands of partners are learning at Deep Blue Academy, including many from renowned institutions such as Peking University and Tsinghua University.

Thank you for reading. Please share, like, or comment!🙏