
Follow our public account to discover the beauty of CV technology
With the development of AIGC technology, the detection of fake images generated by AI has become a new research hotspot. However, the experimental conditions and test datasets of existing detection methods are not completely consistent, making it impossible to directly compare detection performance. Therefore, we conduct a comprehensive analysis and comparison of the currently mainstream AIGC image detection methods. Under the condition of ensuring the same training set and experimental conditions, we analyze the detection accuracy and generalization performance indicators of the current detection algorithms, providing a benchmark experimental comparison platform for the field of AIGC image detection, while integrating and open-sourcing various existing detection algorithms for AIGC-generated images.
-
Project Introduction: https://fdmas.github.io/AIGCDetect/ -
Code Link: https://github.com/Ekko-zn/AIGCDetectBenchmark
Introduction
In recent years, AI-generated images have significantly improved in visual quality, semantic complexity, and operational efficiency. The expertise and costs required to generate fake images have also decreased significantly, leading to the emergence of various image generation platforms, allowing everyone to use online tools (such as Midjourney, DALL·E, etc.) to generate fake images according to their needs.

Midjourney is currently the most popular online image generation platform, which has been updated to version 5.2, and users can pay to use it.
DALL·E is developed by OpenAI, allowing users to pay to use the DALL·E 3 model in conjunction with ChatGPT Plus and Enterprise versions. Microsoft has also integrated the DALL·E model into Bing’s chat functionality, providing services to users in the Microsoft Edge browser.
Stability AI has open-sourced several versions of the pre-trained model, including Stable Diffusion v2.0 and v2.1. Users can use online interfaces or utilize the open-source model on local machines. These are powerful text-to-image tools that generate high-quality images based on user input.
In addition, online platforms such as Pixeling and Wukong also support text-to-image functionality with Chinese input.
This unprecedented accessibility has raised concerns about the widespread dissemination of false information.


Swipe right to see the answer

Guess: Which of the six images above was generated by an AI model?
According to the research by Lago et al. [1], respondents marked 68% of images generated by StyleGAN as “real,” while 48% of real images were marked as “fake.” This indicates that generated images can already “deceive” the human eye, making the development of effective detection tools urgent.
Currently, there are many detection works targeting AI-generated fake images [2-9], but there are certain inconsistencies and inadequacies in their performance analysis experiments.

Inconsistency of Training Sets
In practical applications, since the generation model of the AI-generated images to be detected is unknown, the generalization ability of the detector, i.e., its detection performance on data unseen during the training phase, is an important criterion for evaluating the detector. To ensure fairness in comparison, all detectors should be trained on the same training set. However, the pre-trained models provided by current SOTA detection methods generally use different training sets, making it impossible to fairly compare generalization abilities.
Insufficient Diversity of Test Sets
Most detection methods focus on accurately and efficiently distinguishing between GAN-generated images and real images, neglecting the powerful capabilities of diffusion models, and do not test the accuracy on datasets generated by diffusion models. Therefore, it is impossible to evaluate the generalization of these methods on diffusion generation models.
The above issues pose certain obstacles to subsequent research work. Relevant researchers need to spend a lot of time, energy, and computational resources to reproduce existing detection methods to further supplement validation experiments. To address this issue, we trained various AI-generated image detectors using the same training set and conducted a series of benchmark tests on existing methods to evaluate their capabilities in generalization and robustness. We selected a total of 9 SOTA detection methods [2-10] and conducted extensive testing on 16 generated image datasets. The aim is to provide a standardized way to compare the performance of different methods, to identify the strengths and weaknesses of existing methods, and to provide a convenient benchmark analysis framework for subsequent work, as well as valuable reference indicators and improvement directions. In addition, we integrated the testing interfaces of existing SOTA methods and open-sourced all pre-trained models of the detectors.
Experiments
We conducted a series of experiments to analyze the generalization and robustness of these detection methods on various GAN and Diffusion Model generated images.
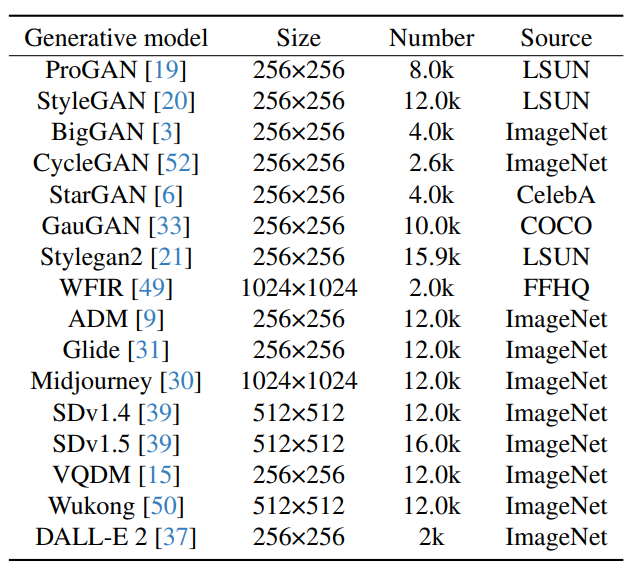
The training dataset we used was the ProGAN generated image dataset provided by Wang et al. [2]. The construction of the test dataset utilized various generation models, including some advanced commercial generators (such as Midjourney, DALL·E 2), to comprehensively evaluate and compare the generalization of each detector. The test set consists of datasets provided by Wang et al. [2] and Zhu [11], as well as our self-constructed generated image datasets, totaling 16.
Some experimental results are as follows:

In Figure 1, the center of each radar chart represents a detection accuracy of 0%, the innermost circle represents a detection accuracy of 20%, and so on, with the outermost circle representing a detection accuracy of 100%. The outermost is labeled with 16 datasets, and each data point represents the detection accuracy of that method on the corresponding dataset. The closer the data point is to the outer circle, the higher the accuracy on that dataset. Overall, a hexagon that is further out (closer to a circular shape) indicates that the detection method has better generalization performance.
Detection Methods Used in Our Experiments
[CNNSpot] Wang et al. [2] proposed using the ResNet50 model to train a binary classifier to distinguish between real and generated images, incorporating random preprocessing of images (JPEG compression, Gaussian blur, image resizing, etc.) during training to enhance the model’s generalization ability.
[FreDect] Frank et al. [3] analyzed the features of fake images generated by various popular GAN models in the frequency domain, discovering that these fake images exhibit similar artifacts left by upsampling operations in the frequency domain. Based on this finding, they proposed a binary classifier based on frequency domain features.
[Gram-Net] Liu et al. [4] focused on detecting fake faces generated by GANs. They found that synthesized faces have significant statistical differences in texture compared to real face images, and that global texture information can effectively enhance the detector’s generalization and robustness against various image distortions. They introduced a Gram module to extract global texture information based on a CNN model, forming Gram-Net.
[Fusing] Ju et al. [5] used a dual-branch framework to combine global image features with information-rich local block features to enhance the generalization ability of synthetic image detection. Additionally, with the help of an attention-based block selection module, they can automatically select multiple blocks without manual labeling to effectively extract local subtle forgery features.
[UnivFD] Ojha et al. [8] analyzed the asymmetry of the decision boundary learned by the CNNSpot classifier. Although it can effectively distinguish GAN-generated fake images, the feature space of real images is not independent, meaning that all non-GAN generated images (real images, Diffusion generated images) are classified into one category. Therefore, Ojha et al. suggested that to improve the generalization of the detector and reasonably distinguish between real and fake images, a balanced decision boundary needs a suitable feature space. They used the pre-trained CLIP:ViT model to extract the feature space.
[LGrad] Tan et al. [7] converted images into gradient maps using a pre-trained CNN model (such as VGG16, ResNet50, ProGAN’s discriminator, etc.) before training the classifier, normalizing them to [0,255]. They trained a binary classifier to distinguish between real and generated images on the gradient map dataset.
[LNP] Liu et al. [6] conducted frequency domain analysis of the noise patterns in real images, finding that there is consistency in these noise patterns among real images, while the noise patterns between generated images vary significantly. Therefore, they classified images based on noise patterns, which are obtained by subtracting the denoised image from the original image, resulting in a pattern free from semantic interference.
[DIRE] Wang et al. [9] noted that existing detection methods for generated images have significantly decreased performance on diffusion models, thus proposing a new detection method. They found that compared to real images, images produced through a pre-trained diffusion model can be reconstructed more accurately. Based on this premise, they proposed the Diffusion Reconstruction Error (DIRE) for detecting images generated by diffusion models.
[RPTC] Zhong et al. [10] utilized the contrast of pixel inter-correlations between rich and poor texture areas within images to detect AI-generated images. They found that pixels in complex texture regions exhibit more significant fluctuations than those in flat texture regions. Based on this principle, they divided the image into multiple blocks and reconstructed them into two images, including complex texture blocks and flat texture blocks. Subsequently, they extracted the features of pixel inter-correlation differences between complex and flat texture areas as a universal “fingerprint” for forensic analysis of generated images across different models.
References
[1] Lago F, Pasquini C, Böhme R, et al. More real than real: A study on human visual perception of synthetic faces [applications corner][J]. IEEE Signal Processing Magazine, 2021, 39(1): 109-116. [2] Wang S Y, Wang O, Zhang R, et al. CNN-generated images are surprisingly easy to spot… for now[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 8695-8704. [3] Frank J, Eisenhofer T, Schönherr L, et al. Leveraging frequency analysis for deep fake image recognition[C]//International conference on machine learning. PMLR, 2020: 3247-3258. [4] Liu Z, Qi X, Torr P H S. Global texture enhancement for fake face detection in the wild[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 8060-8069. [5] Ju Y, Jia S, Ke L, et al. Fusing global and local features for generalized ai-synthesized image detection[C]//2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022: 3465-3469. [6] Liu B, Yang F, Bi X, et al. Detecting generated images by real images[C]//European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022: 95-110. [7] Tan C, Zhao Y, Wei S, et al. Learning on Gradients: Generalized Artifacts Representation for GAN-Generated Images Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 12105-12114. [8] Ojha U, Li Y, Lee Y J. Towards universal fake image detectors that generalize across generative models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 24480-24489. [9] Wang Z, Bao J, Zhou W, et al. DIRE for Diffusion-Generated Image Detection[J]. arXiv preprint arXiv:2303.09295, 2023. [10] Zhong N, Xu Y, Qian Z, et al. Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection[J]. arXiv preprint arXiv:2311.12397, 2023. [11] Zhu M, Chen H, Yan Q, et al. GenImage: A Million-Scale Benchmark for Detecting AI-Generated Image[J]. arXiv preprint arXiv:2306.08571, 2023.
Authors: Zhong Nan, Xu Yiran, Multimedia Intelligent Security Lab, School of Computer Science, Fudan University. Lab Introduction: The Multimedia Intelligent Security Lab (MAS Lab) currently has 3 faculty members (Professor Zhang Xinpeng, Professor Qian Zhenxing, Associate Professor Li Sheng), 2 postdoctoral researchers, 19 doctoral students, and 30 master’s students. The main research areas include multimedia and AI security, including information hiding, multimedia forensics, AI security, virtual robots, and multimedia applications. The lab team has published over 400 academic papers, with many published in top journals and conferences such as IEEE TIFS, TIP, TDSC, TCSVT, TMM, TCYB, TCC, TNNLS, TPAMI, AAAI, IJCAI, NeurIPS, ACM MM, ICCV. Young talents are welcome to join the Fudan Multimedia Intelligent Security Lab! ⭐ Fudan University Multimedia Intelligent Security Lab Homepage: https://fdmas.github.io/ ⭐ Neural Network Model Research Resources: https://fdmas.github.io/research/Neural_Network_Watermarking.html ⭐ Fake News Detection Research Resources: https://fdmas.github.io/research/fake-news-detection.html ⭐ AIGC Forensics Homepage: https://fdmas.github.io/AIGCDetect/

END
Welcome to join the “AIGC“ discussion group👇 Note:AIGC
