
 Deep Learning and 3D Vision Series ICurrently, deep learning has become the mainstream method in 2D computer vision, and many researchers have started using deep learning to solve some problems in 3D vision, such as multi-view geometry. However, opinions on using deep learning to address multi-view geometry issues are mixed. We aim to summarize some classic articles and algorithms to facilitate learning, thinking, and summarizing.In this article, we will summarize some papers that use deep learning to address SLAM-related issues. The main topics include: end-to-end visual odometry, camera relocalization, semantic SLAM, feature point extraction and matching, and VINet.1. End-to-End Visual Odometry(1) SfMLearner
Deep Learning and 3D Vision Series ICurrently, deep learning has become the mainstream method in 2D computer vision, and many researchers have started using deep learning to solve some problems in 3D vision, such as multi-view geometry. However, opinions on using deep learning to address multi-view geometry issues are mixed. We aim to summarize some classic articles and algorithms to facilitate learning, thinking, and summarizing.In this article, we will summarize some papers that use deep learning to address SLAM-related issues. The main topics include: end-to-end visual odometry, camera relocalization, semantic SLAM, feature point extraction and matching, and VINet.1. End-to-End Visual Odometry(1) SfMLearner
The core idea of the paper is to use the principle of photometric consistency to estimate the depth and pose of each frame. Photometric consistency means that for a point on the same object, the projected points on two different images should have the same intensity. The general process of the method in the paper is shown in the figure below:
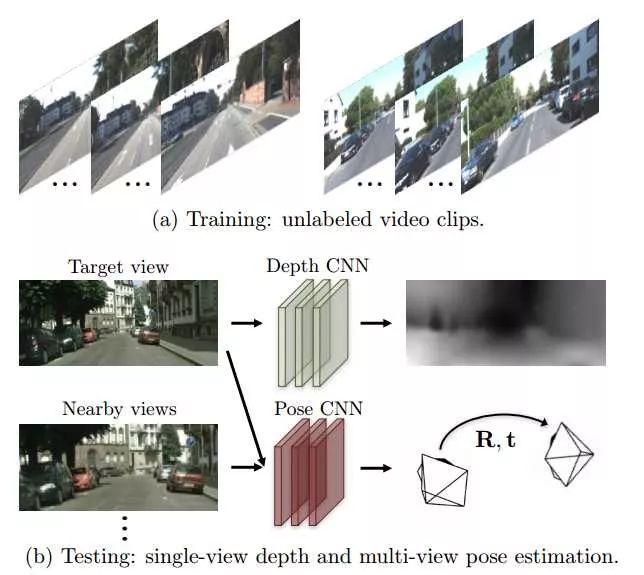
Recall the classic direct method SLAM: LSD-SLAM (LSD-SLAM: Large-Scale Direct Monocular SLAM). Does it feel like the core idea of this paper is similar to LSD-SLAM? Essentially, both optimize photometric error. Let’s take a look at the Loss of SfM-Learner (the final Loss is optimized based on this):
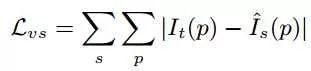
Next, look at the photometric error function that needs to be optimized in LSD-SLAM (the photometric error in the original text has been normalized):
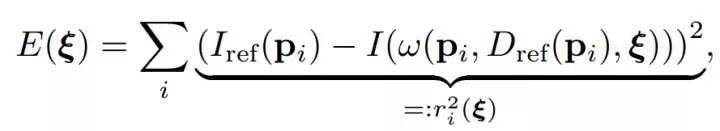
Does it look similar?
GitHub code: /tinghuiz/SfMLearner
Reference article: Unsupervised learning of depth and ego-motion from video, Zhou T, Brown M, Snavely N, et al.(2) SfM-Net
The name sounds similar to SfM-Learner; this paper, like SfM-Learner, comes from Google.The core idea of the paper is also to use photometric constancy to compute pose and depth.In addition, the authors also calculated optical flow, scene flow, 3D point cloud, etc.One could consider SfM-Net as an upgraded version of SfM-Learner.
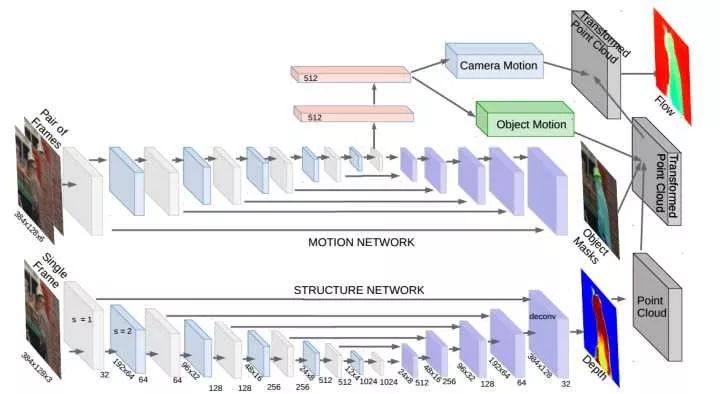
Reference article: SfM-Net: Learning of Structure and Motion from Video, Vijayanarasimhan S, Ricco S, Schmid C, et al.(3) DeMoN
Another article similar to SfM-Net and SfM-Learner: DeMoN, which uses pose and depth as supervisory information to estimate pose and depth, achieving very good results.The core structure of the network is shown in the figure below:

Core structure of the DeMoN network
GitHub code: /lmb-freiburg/demon
Reference article: DeMoN: Depth and Motion Network for Learning Monocular Stereo, Ummenhofer B, Zhou H, Uhrig J, et al.2. Camera Relocalization(1) PoseNet
PoseNet is the pioneering work combining Deep Learning and SLAM.The method uses GoogleNet to perform regression for 6 degrees of freedom camera pose.The training data consists of scene frames with ground truth poses.

The first row is the original image, the second row is the scene image reconstructed based on the estimated camera pose, and the third row shows the overlap between the original and reconstructed scenes.
GitHub code: /alexgkendall/caffe-posenet
Reference article: PoseNet: A convolutional network for real-time 6-dof camera relocalization, Kendall A, Grimes M, Cipolla R3. Semantic SLAM(1) CNN-SLAMCNN-SLAM is a relatively complete pipeline, replacing the depth estimation and image matching in LSD-SLAM with CNN-based methods, achieving more robust results and allowing for the fusion of semantic information.
Similar work includes UnDeepVO,which uses direct methods to estimate camera pose, employs CNN for depth estimation and image semantic segmentation, and then fuses geometry and semantics to generate a map with semantic information.
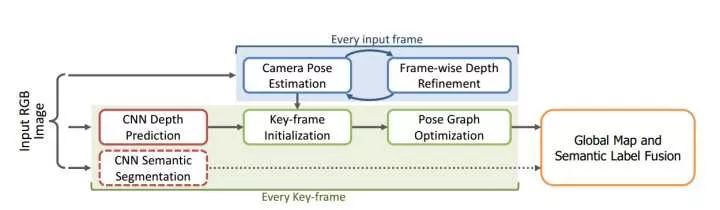
CNN-SLAM pipeline
Project homepage: http://campar.in.tum.de/Chair/ProjectCNNSLAM
Reference article: CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction, Tateno K, Tombari F, Laina I, et al.
Reference article: UnDeepVO: Monocular Visual Odometry through Unsupervised Deep Learning, Li R, Wang S, Long Z, et al.(2) VSOThis paper mainly uses semantic constraints to solve (reduce) the drift problem caused by error accumulation during SLAM reconstruction.In autonomous driving scenarios, due to the prevalence of straight roads, the improvement is more evident in translational error, while the improvement in rotational error is relatively limited.In visual odometry, there are two methods to reduce drift:one is to establish constraints through short-term correspondences between images in consecutive frames to correct drift; the other is to establish long-term constraints through loop closure in frames that are far apart.VSO corrects drift through medium-term continuous tracking of points by utilizing semantic constraints.
One of the main ideas of this paper is to use semantic information as an invariant representation of the scene.Although viewpoint, lighting, and scale variations can affect the low-level representation of objects, they do not affect their semantic representation.The contributions of this paper mainly consist of three parts:
1) Using a new cost function to minimize semantic reprojection error, which can be optimized through EM (expectation maximization);
2) Demonstrating that by integrating the semantic cost function into VO in autonomous driving scenarios, VSO can significantly reduce translational drift, and VSO can be easily implemented in direct or non-direct VO;
3) Analyzing VSO through experiments to explain in what scenarios VSO can enhance existing methods and the limitations of VSO.
Reference article: VSO: Visual Semantic Odometry, Lianos K N, Schönberger J L, Pollefeys M, et al.
Reference column: https://zhuanlan.zhihu.com/p/416756514. Feature Point Extraction and Matching(1) LIFT
Frame-to-frame matching is an important part of traditional feature-based SLAM.Here, we first recommend the EPFL article LIFT (Learned Invariant Feature Transform), which learns feature points in images through deep neural networks; its pipeline is shown in the figure below, where LIFT calculates Detector, Orientation Estimator, and Descriptor.
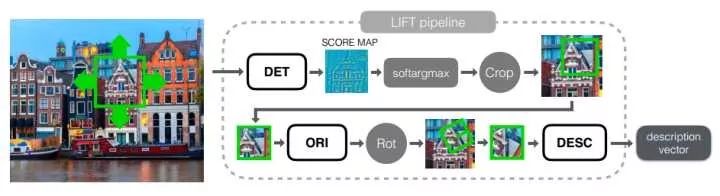
LIFT pipeline
Compared with SIFT features, LIFT can extract denser feature points, as shown in the figure below.

Comparison of feature points extracted by SIFT (left) and LIFT (right)
GitHub code: /cvlab-epfl/LIFT
Reference article: LIFT: Learned Invariant Feature Transform, Yi K M, Trulls E, Lepetit V, et al.(2) SuperPointTwo networks were designed: one is BaseDetector, used to detect corners (note that the extracted points here are not the final output feature points, but can be understood as candidate feature points); the other is SuperPoint network, which outputs feature points and descriptors.
The training of the network is divided into three steps:
1) The first step uses virtual 3D objects as the dataset to train the network to extract corners;
2) Using real scene images, the corners are extracted using the network trained in the first step, this step is called Interest Point Self-Labeling;
3) Performing geometric transformations on the images used in the second step to obtain new image pairs with known pose relationships, feeding these two images into the network to extract feature points and descriptors.
GitHub code: /MagicLeapResearch/SuperPointPretrainedNetwork
Reference column: https://zhuanlan.zhihu.com/p/69515306
Reference article: SuperPoint: Self-Supervised Interest Point Detection and Description, Detone D, Malisiewicz T, Rabinovich A.(3) DeepSLAM
Magic Leap’s article Toward Geometric Deep SLAM introduces an excellent method for feature point (corner) extraction and matching, as shown in the figure:
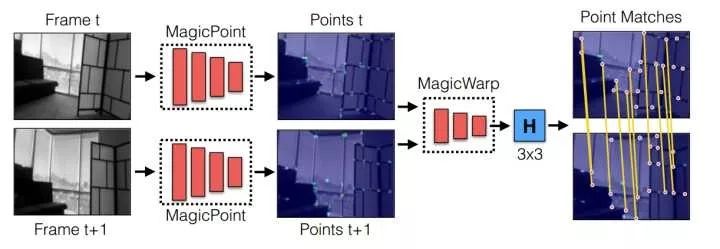
Deep Point-Based Tracking
Let’s take a look at this impressive effect; the points extracted are just right, accurately locating every corner of the object, which is simply a blessing for perfectionists!

Feature point extraction results
The paper also compares with classic feature extraction methods like FAST and Harris, showing that the proposed method is more robust to noise, and the extracted feature points appear more visually appealing than those from FAST and Harris. Those interested can read the paper in detail.I believe the proposed method will shine in future feature-based SLAM systems.
Reference article: Toward Geometric Deep SLAM, DeTone D, Malisiewicz T, Rabinovich A.(4) VINetHigh-precision lane-level navigation and positioning is a core technology for autonomous vehicles.Conventional high-precision positioning methods, such as differential GPS and inertial navigation devices, can have significant errors in scenarios with poor GPS signals (such as overpasses and tunnels).Moreover, these devices are often expensive and not suitable for commercial autonomous vehicle solutions.In contrast, some matching positioning schemes based on semantic maps are relatively inexpensive, but considering the errors in visual semantic perception and the sparsity of semantic elements in semantic maps, such schemes cannot achieve positioning in arbitrary scenes.As a supplement to semantic map matching positioning schemes, Visual Inertial Odometry (VIO) is a combined positioning method that integrates image vision and inexpensive inertial data. It effectively suppresses the drift of inertial devices and overcomes issues such as scale, relative motion, and low frame rates in visual odometry, making it an effective means of achieving low-cost, high-precision positioning.The traditional VIO framework generally consists of three processes: optical flow estimation based on image sequences, integration operations based on inertial data, and motion fusion based on filtering and optimization. According to the disclosed information in the article, deep learning has been involved in all three subfields.
The problem of optical flow estimation
Optical flow reflects the instantaneous velocity of moving objects in pixel space and requires the correspondence of pixels between adjacent frames.
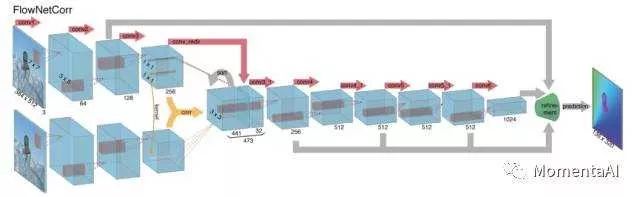
FlowNet network structure is currently the state of the art for addressing optical flow problems using deep learning.Compared to general deep convolutional neural networks, FlowNet has two differences: first, its input consists of two images from adjacent frames; second, it learns the motion differences between the two images by performing correlation operations on feature maps from different images.IMU time-series data
As is well known, RNNs and LSTMs are powerful methods for data-driven temporal modeling in deep learning.The high-frequency angular velocity, acceleration, and other inertial data output by IMU have strict temporal dependencies, making them particularly suitable for models like RNN.
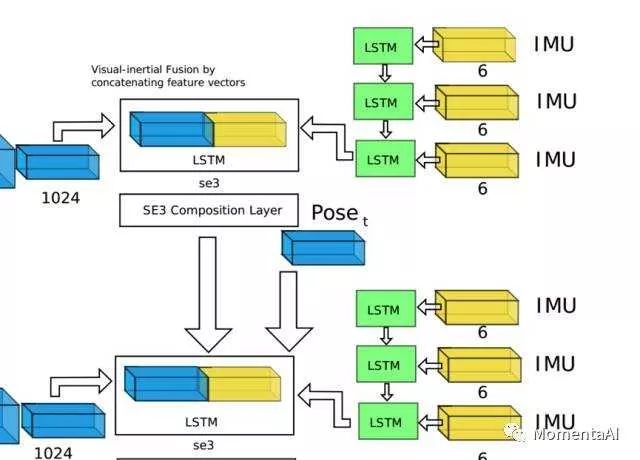
IMU time-series data processing module in VINet; thus, it is natural to consider combining FlowNet and RNN to address VIO issues.
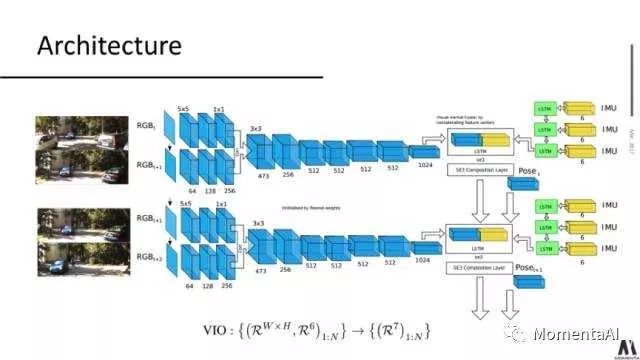
The network architecture of VIO, VINet, is designed based on this motivation; the entire network can be divided into three parts.The CNN part uses a FlowNet to obtain the optical flow motion features between images in adjacent frames (1024 dimensions).
Next, a conventional small LSTM network is used to process the raw IMU data to obtain motion features under IMU data.Finally, the visual motion features and IMU motion features are combined and fed into a core LSTM network for feature fusion and pose estimation.

It is worth mentioning that the mechanism for handling input data with different frame rates in VINet; in VIO problems, the frame rate of IMU data often does not match the frame rate of image data. For example, in the KITTI dataset, the frame rate of IMU is 100Hz, while the frame rate of image data is 10Hz, which requires the neural network to handle input data with different frame rates.
In VINet, the small LSTM network can process high-frequency IMU data at a faster rate, while the parameter-heavy core LSTM works alongside the CNN at the image frame rate.By leveraging the variable-length characteristics of LSTM for input data, it completes feature learning and fusion of visual and inertial data at different rates.
Now that we have the fused features, the question arises: how do we model pose in the neural network?

In robotics and computer vision, pose not only expresses 3D rotation and translation but also requires estimation. To achieve this, we need to perform interpolation, differentiation, and iterative operations on the transformation matrix. We hope to have better mathematical tools to assist us in these tasks, and Lie group and Lie algebra theory provides such tools.
Usually, we use the special Euclidean group SE(3) to represent the camera pose.However, the rotation matrix in SE(3) must be orthogonal, which is difficult to guarantee during parameter learning.
To decouple this orthogonality, Lie algebra se(3) can be used to represent such transformations.Mathematically, it can be proven that the tangent space expressed by Lie algebra se(3) has the same degrees of freedom compared to the original SE(3) group. More importantly, through simple exponential mapping, we can easily map the transformation vectors in se(3) back to transformation matrices in Euclidean space.
With this modeling approach, we can at least obtain the following two types of loss functions.
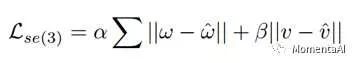
One is based on SE(3) group pose constraints (Full pose), and the other is based on relative motion (Frame-to-frame) constraints in se(3) space.Experimental results show that when these two loss functions are jointly constrained, the effect that VINet can achieve is optimal.
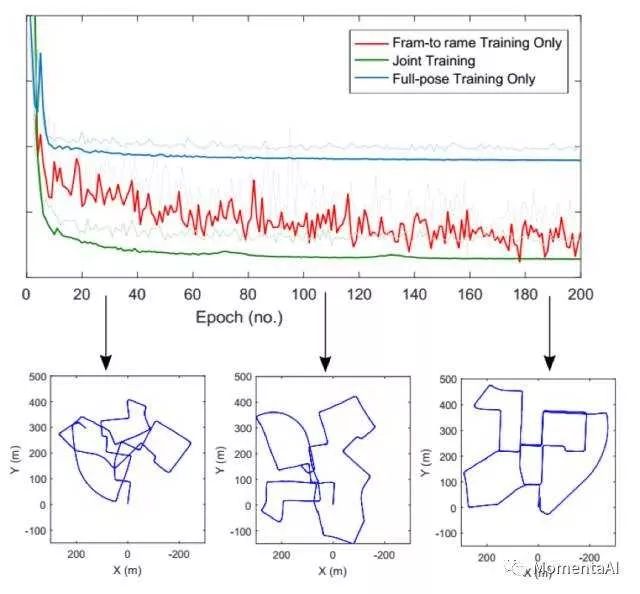
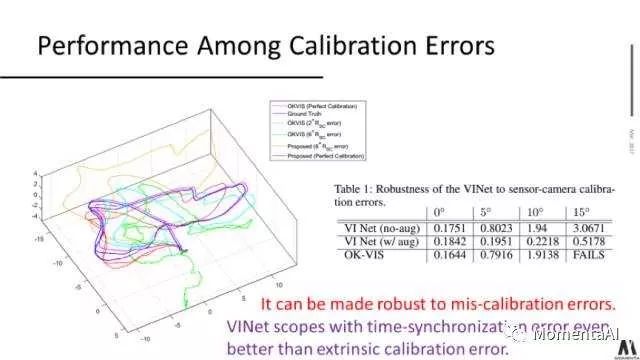
In traditional VIO applications, whenever camera and inertial device data fusion is involved, joint calibration of the two sensors cannot be avoided.Calibration between sensors can be divided into time and spatial dimensions; in the time dimension, it is called data frame synchronization, while in the spatial dimension, it is called extrinsic calibration.
Traditional VIO often requires the calibration to be nearly perfect; otherwise, the algorithm is difficult to function properly.However, experimental results on VINet indicate that when calibration parameters of the sensors deviate, the deep learning-based VIO method exhibits certain robustness compared to conventional methods.
For data-driven models like VINet, there is often significant potential to learn patterns from the data; thus, regarding disturbances like calibration errors, the model has strong modeling and fitting capabilities, which is the greatest charm of data-driven models.
In summary, we introduced VINet, an end-to-end trainable deep neural network architecture designed to address the visual inertial odometry problem in robotics.This network uses FlowNet to model visual motion features, LSTM to model IMU motion features, and finally models pose using the SE(3) flow in Lie group and Lie algebra, employing a frame-stacked LSTM network to predict pose.
On real autonomous driving and drone datasets, VINet achieved results comparable to state-of-the-art methods.At the same time, VINet demonstrated certain advantages when dealing with time desynchronization and inaccurate extrinsic calibration in multi-visual inertial data.
Overall, VINet is the first to use a DL framework to solve the VIO problem, and the disclosed experimental results show a certain practical value, warranting our continued attention.
Reference article: VINet: Visual-Inertial Odometry as a Sequence-to-Sequence Learning Problem, Clark R, Wang S, Wen H, et al.