
Compiled by Wen Geng | Produced by Quantum Bits | WeChat Official Account QbitAI
A few days ago, Quantum Bits published an article titled “Guide to Fooling VC”. One of the suggestions was that when you pretend to be an AI expert, it’s best not to talk about the well-known TensorFlow. So what should you talk about?
PyTorch.
This isn’t entirely a joke. Compared to TensorFlow, PyTorch indeed has a considerable number of supporters. According to data released by Keras author François Chollet, PyTorch ranks fifth among various deep learning frameworks on GitHub.
However, it should be noted that PyTorch was only officially released on January 19 of this year.
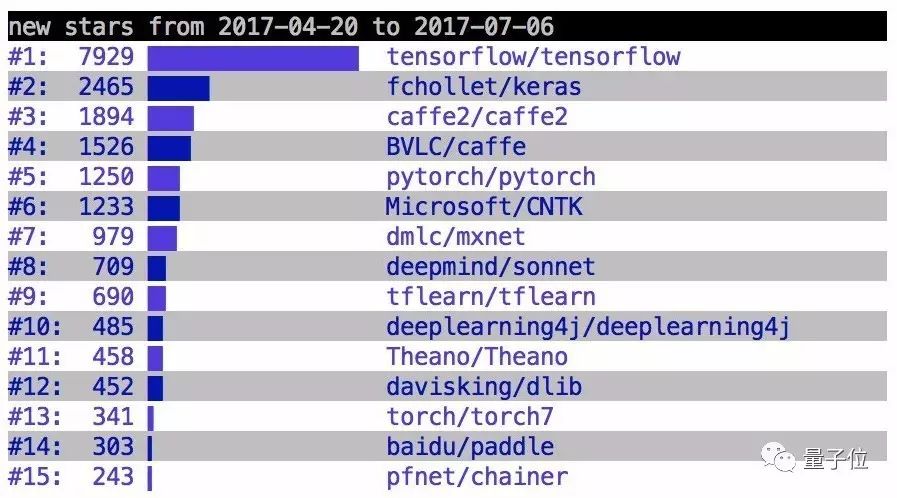
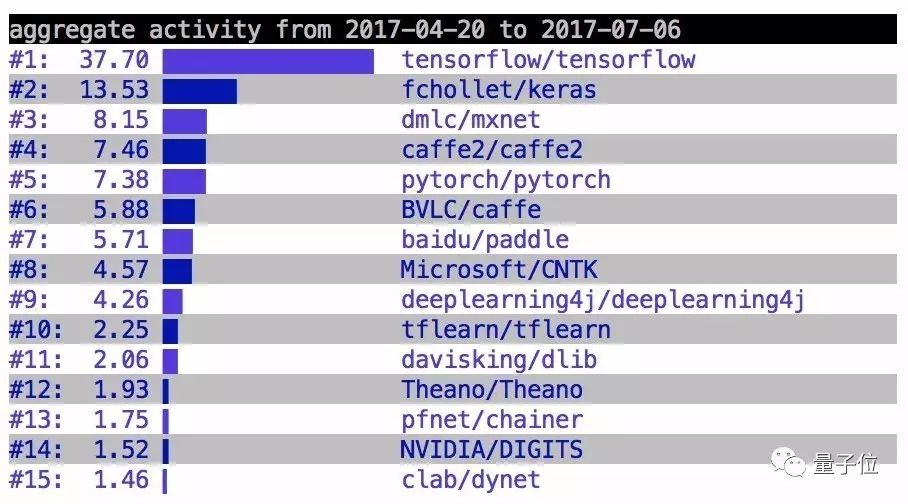
△ Ranking of Deep Learning Frameworks in Q2
Recently, Awni Hannun, a PhD student at Stanford University studying machine learning, conducted an in-depth comparison on the topic of PyTorch vs TensorFlow. Quantum Bits presents the content as follows:
This guide I wrote primarily compares the differences between PyTorch and TensorFlow. I hope it helps those who are looking to start a new project or considering switching deep learning frameworks.
I mainly examined the programmability and flexibility related to training and deploying the deep learning stack. Here, I will not talk much about trade-offs like speed and memory usage.
Let’s Start with the Conclusion
PyTorch is more beneficial for researchers, enthusiasts, and small-scale projects to quickly prototype. TensorFlow is more suitable for large-scale deployments, especially when cross-platform and embedded deployment is required.
Now let’s go through each point one by one.

Getting Started
Winner: PyTorch
PyTorch is essentially a replacement for Numpy and supports GPUs with advanced features for building and training deep neural networks. If you are familiar with Numpy, Python, and common deep learning concepts (convolutional layers, recurrent layers, SGD, etc.), you will find it very easy to get started with PyTorch.
On the other hand, TensorFlow can be seen as a programming language embedded in Python. The TensorFlow code you write is compiled into a graph by Python, and then executed by the TensorFlow engine. I’ve seen many beginners troubled by this added layer of indirection. For the same reason, TensorFlow has some additional concepts to learn, such as sessions, graphs, variable scoping, placeholders, etc.
Additionally, it requires more boilerplate code to run a basic model. Therefore, the getting started time for TensorFlow is definitely longer than that of PyTorch.
Graph Creation and Debugging
Winner: PyTorch
Creating and running computational graphs may be the two frameworks’ most different aspects. In PyTorch, the graph structure is dynamic, meaning it is constructed at runtime. In TensorFlow, the graph structure is static, meaning it is “compiled” first and then run.
For a simple example, in PyTorch you can write a for loop structure using standard Python syntax:
for _ in range(T):
h = torch.matmul(W, h) + bHere, T can change with each execution of the code. In TensorFlow, this requires using “control flow operations” to construct the graph, such as tf.while_loop. TensorFlow does provide dynamic_rnn for common structures, but creating custom dynamic computations is indeed more challenging.
The simple graph structure in PyTorch is easier to understand, and more importantly, it is also easier to debug. Debugging PyTorch code is like debugging Python code. You can use pdb and set breakpoints anywhere. Debugging TensorFlow code is not easy. You either have to request the variables to check from the session or learn to use TensorFlow’s debugger (tfdbg).
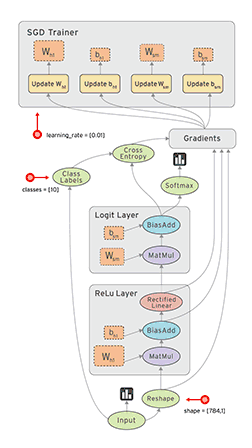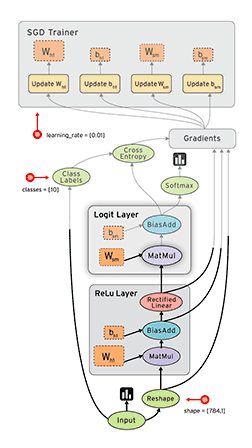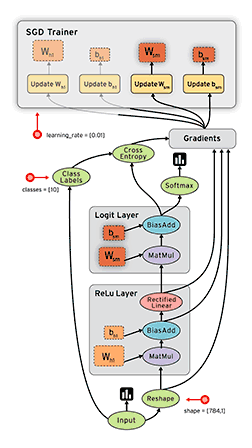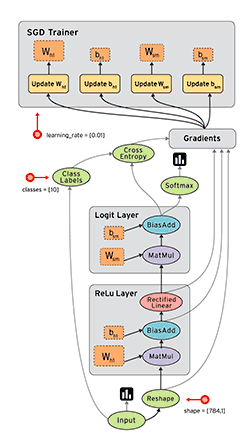
Comprehensiveness
Winner: TensorFlow
As PyTorch matures, I expect the gap in this area to approach zero. However, currently, TensorFlow still has some features that PyTorch does not support. They are:
-
Flipping tensors along dimensions (np.flip, np.flipud, np.fliplr)
-
Checking for infinite and NaN tensors (np.is_nan, np.is_inf)
-
Fast Fourier Transform (np.fft)
TensorFlow supports all these. Additionally, TensorFlow’s contrib package has more advanced features and models that PyTorch lacks.
Serialization
Winner: TensorFlow
Saving and loading models in both frameworks is straightforward. PyTorch has a particularly simple API to save all weights of a model or pickle an entire class. TensorFlow’s Saver object is also easy to use and provides more options for inspection.
The main advantage of TensorFlow serialization is that it can save the entire graph as a protocol buffer, including parameters and operations. However, the graph can also be loaded into other supported languages (C++, Java). This is crucial for deployment stacks. Theoretically, it is very useful when you want to modify the model’s source code but still want to run the old model.
Deployment
Winner: TensorFlow
For small-scale server-side deployments (e.g., a Flask web server), both frameworks are simple.
For mobile and embedded deployments, TensorFlow is superior. Not only is it better than PyTorch, but it is also better than most deep learning frameworks. With TensorFlow, deploying on Android or iOS platforms requires minimal effort, at least without needing to rewrite the model’s inference part in Java or C++.
For high-performance server-side deployments, TensorFlow Serving is also available. Besides performance, a significant advantage of TensorFlow Serving is the ability to easily hot-swap models without causing service downtime.
Documentation
Winner: Tie
For both frameworks, I found everything I needed in the documentation. The Python API is well documented, with enough examples and tutorials to learn the framework.
One exception is that most of PyTorch’s C library lacks documentation. However, this only impacts you if you are writing a custom C extension.
Data Loading
Winner: PyTorch
The API for loading data in PyTorch is excellently designed. The interface consists of a dataset, a sampler, and a data loader. The data loader generates an iterator based on the dataset according to the sampler’s plan. Parallelizing data loading is as simple as passing the num_workers parameter to the data loader.
I did not find particularly useful data loading tools in TensorFlow. Often, you cannot directly incorporate pre-processing code that you intend to run in parallel into the TensorFlow graph. Additionally, the API itself is verbose and difficult to learn.
Device Management
Winner: TensorFlow
TensorFlow’s device management is very user-friendly. Usually, you do not need to adjust it, as the default settings are quite good. For example, TensorFlow assumes you want to run on a GPU (if available). In PyTorch, even with CUDA enabled, you still need to explicitly move everything to the device.
The only downside of TensorFlow’s device management is that by default, it occupies all GPU memory. A simple solution is to specify CUDA_VISIBLE_DEVICES. Sometimes people forget this, so the GPU appears busy while it’s idle.
In PyTorch, I found that the code needs to check for CUDA availability more frequently and requires more explicit device management. This is especially true when writing code that can run on both CPU and GPU. Additionally, you need to convert PyTorch variables on the GPU to Numpy arrays, which can be a bit verbose.
numpy_var = variable.cpu().data.numpy()Custom Extensions
Winner: PyTorch
Both frameworks can build and bind custom extensions written in C, C++, or CUDA. TensorFlow still requires more boilerplate code, although this may be better for supporting multiple types and devices. In PyTorch, you only need to write one interface and corresponding implementation for each CPU and GPU. Compiling extensions in both frameworks is also straightforward, requiring no additional header files or source code beyond what is installed via pip.
About TensorBoard
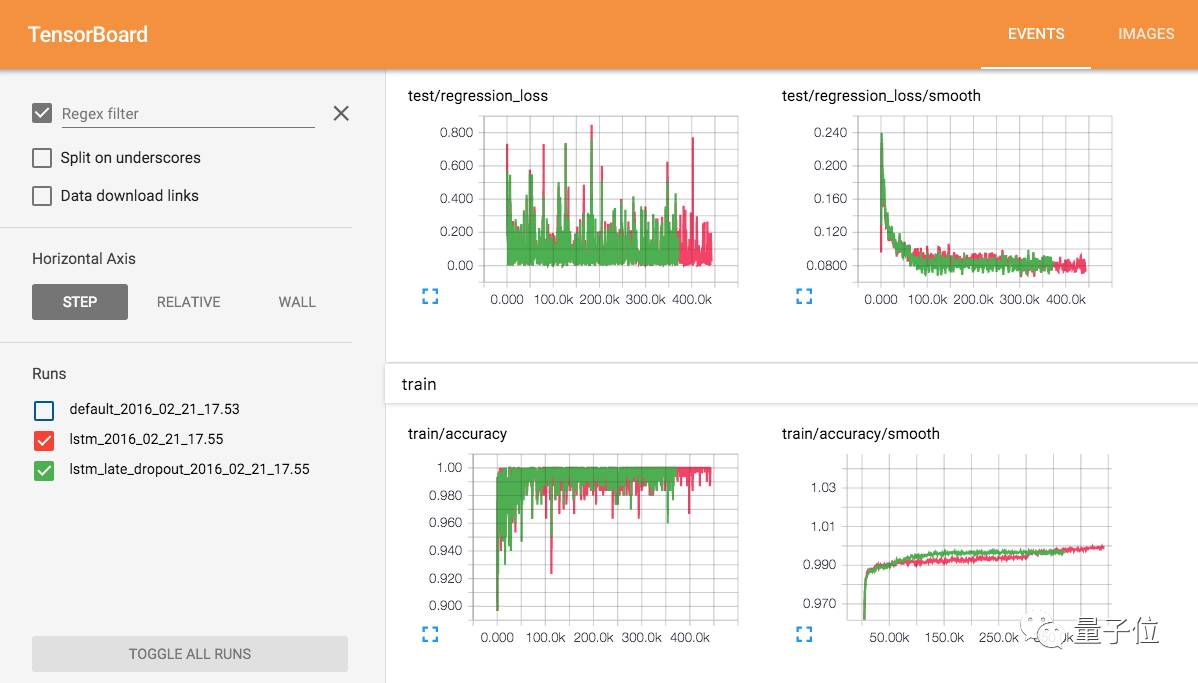
TensorBoard is the built-in visualization tool of TensorFlow, used to view changes in data during machine learning training. With a few code snippets in the training script, you can visualize the training curves and validation results of any model. TensorBoard runs as a web service, making it especially convenient for visualizing results stored on headless nodes.
If it weren’t for similar functionalities, I wouldn’t want to use PyTorch. Fortunately, two open-source projects can achieve this. The first is tensorboard_logger, and the second is crayon. The tensorboard_logger library is even easier to use than TensorBoard’s “summary,” although you need to install TensorBoard first to use it.
crayon can completely replace TensorBoard, but it requires more setup (docker is a prerequisite).
About Keras
Keras is a high-level API with a configurable backend. Currently, TensorFlow, Theano, and CNTK all support it. Perhaps in the near future, PyTorch will also provide support. As part of tf.contrib, Keras is also distributed with TensorFlow.
Although I did not discuss Keras above, its API is particularly easy to use, making it one of the fastest ways to work with common deep neural network architectures. However, using the API is not as flexible as using PyTorch or core TensorFlow.
Keras is one of the fastest methods to run many commonly used deep neural network architectures.
About TensorFlow Fold
In February of this year, Google launched TensorFlow Fold. This library builds on TensorFlow’s intelligence and allows for the construction of more dynamic graphs. The main advantage of this library is dynamic batching. Dynamic batching can automatically batch compute inputs of different sizes (e.g., recurrent networks on parse trees).
In terms of programmability, the syntax is not as simple as PyTorch, although in some cases, the performance gains from batching are worth considering.
Well, that’s all from Awni Hannun’s sharing. I hope it helps everyone. Additionally, it’s important to listen to multiple perspectives; Quantum Bits will continue to relay comments from readers on Reddit.
Reader Reiinakano:
I don’t think the “documentation” section should be a tie for both sides.
The official TensorFlow documentation is quite poor. For example, in the PyTorch documentation, the explanation of transfer learning uses practical, useful code and explains how to build it. In TensorFlow’s documentation, the entire explanation is just running a bash script with no practical code.
Reader ThaHypnotoad:
PyTorch still has a long way to go. A few days ago, I found that int tensor does not have a neg() definition. However, I dislike debugging static graphs. So I choose to endure the growing pains of PyTorch.
Reader trias10:
Another downside is that PyTorch does not have official support for Windows, whereas TensorFlow does. Many situations (usually in finance and insurance) use Windows for development and prototyping and Linux for production deployment, so you need a framework that supports both.
Alright, that’s all for today. I hope this helps you~
— The End —
Join the Community
The Quantum Bits AI Community Group 7 is now recruiting. Welcome students interested in AI to add the assistant WeChat qbitbot2 to join the group;
In addition, Quantum Bits is recruiting for specialized sub-groups (Autonomous Driving, CV, NLP, Machine Learning, etc.), aimed at engineers and researchers currently working in related fields.
To join the group, please add the assistant WeChat account qbitbot2 and be sure to note the corresponding group’s keyword~ After passing the review, we will invite you to join the group. (The review for specialized groups is strict, please understand.)
Sincere Recruitment
Quantum Bits is recruiting editors/reporters, with the workplace in Zhongguancun, Beijing. We look forward to talented and passionate students joining us! For related details, please reply “recruitment” in the dialogue interface of the Quantum Bits WeChat official account (QbitAI).

Quantum Bits QbitAI
վ’ᴗ’ ի Tracking the New Dynamics of AI Technology and Products