
Click the “CVer” above and select “Star” to pin it
Heavyweight content delivered first

All the code below is from PaddleClas:
GitHub link:
https://github.com/PaddlePaddle/PaddleClas
Gitee link:
https://gitee.com/paddlepaddle/PaddleClas
Eight Major Data Augmentation Methods
First, let’s take a look at the standard data augmentation methods represented by the ImageNet image classification task. The operational process can be divided into the following steps:
-
Image decoding, which converts the image into Numpy format, abbreviated as ImageDecode. -
Image random cropping, randomly cropping the width and height of the image to 224, abbreviated as RandCrop. -
Random horizontal flipping, abbreviated as RandFlip. -
Normalization of image data, abbreviated as Normalize. -
Rearranging image data. The format of the image data is [H, W, C] (height, width, and channel), while the training data format used by neural networks is [C, H, W]. Therefore, the image data needs to be rearranged, for example, [224, 224, 3] becomes [3, 224, 224], abbreviated as Transpose. -
Batching multiple images into batch data, such as combining BatchSize images of [3, 224, 224] into [batch-size, 3, 224, 224], abbreviated as Batch.
-
Image transformation: Performing some transformations on the 224 images after RandCrop, including AutoAugment and RandAugment. -
Image cropping: Performing some cropping on the 224 images after Transpose, including CutOut, RandErasing, HideAndSeek, and GridMask. -
Image mixing: Mixing or overlaying data after Batch, including Mixup and Cutmix.

Image Transformation
01AutoAugment
Paper link:
https://arxiv.org/abs/1805.09501v1
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ImageNetPolicy
from ppcls.data.imaug import transform
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Using AutoAugment image augmentation method
autoaugment_op = ImageNetPolicy()
ops = [decode_op, resize_op, autoaugment_op]
# Image path
imgs_dir = "/imgdir/xxx.jpg"
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)

02
RandAugment
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import RandAugment
from ppcls.data.imaug import transform
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Using RandAugment image augmentation method
randaugment_op = RandAugment()
ops = [decode_op, resize_op, randaugment_op]
# Image path
imgs_dir = "/imgdir/xxx.jpg"
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)

Image Cropping
The image cropping class mainly involves cropping parts of the images after Transpose, which can be understood as covering parts of the images, with four methods: CutOut, RandErasing, HideAndSeek, and GridMask.
03
Cutout
Paper link:
https://arxiv.org/abs/1708.04552
-
Cutout can simulate classification scenarios where the subject is partially covered in real-world situations. -
It encourages the model to utilize more content in the image for classification, preventing the network from focusing only on prominent areas, thus avoiding overfitting.
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import Cutout
from ppcls.data.imaug import transform
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Using Cutout image augmentation method
cutout_op = Cutout(n_holes=1, length=112)
ops = [decode_op, resize_op, cutout_op]
# Image path
imgs_dir = "/imgdir/xxx.jpg"
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)

04
RandomErasing
Paper link:
https://arxiv.org/pdf/1708.04896.pdf
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import RandomErasing
from ppcls.data.imaug import transform
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Using RandomErasing image augmentation method
randomerasing_op = RandomErasing()
ops = [decode_op, resize_op, tochw_op, randomerasing_op]
# Image path
imgs_dir = "/imgdir/xxx.jpg"
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
img = img.transpose((1, 2, 0))

05
HideAndSeek
Paper link:
https://arxiv.org/pdf/1811.02545.pdf

from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import HideAndSeek
from ppcls.data.imaug import transform
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Using HideAndSeek image augmentation method
hide_and_seek_op = HideAndSeek()
ops = [decode_op, resize_op, tochw_op, hide_and_seek_op]
# Image path
imgs_dir = "/imgdir/xxx.jpg"
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
img = img.transpose((1, 2, 0))

06
GridMask
Paper link:
https://arxiv.org/abs/2001.04086
-
Excessive removal of regions may cause the main subject to be mostly or entirely removed, or lead to the loss of contextual information, resulting in augmented data becoming noise data; -
Retaining too many areas may have little effect on the main subject and context, losing the significance of augmentation.

-
Set a probability p and use GridMask for augmentation with probability p from the start of training. -
Initially set the augmentation probability to 0, and as the number of iterations increases, gradually increase the probability of applying GridMask augmentation to the training images until it reaches p.
from data.imaug import DecodeImage
from data.imaug import ResizeImage
from data.imaug import ToCHWImage
from data.imaug import GridMask
from data.imaug import transform
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Image data rearrangement
tochw_op = ToCHWImage()
# Using GridMask image augmentation method
gridmask_op = GridMask(d1=96, d2=224, rotate=1, ratio=0.6, mode=1, prob=0.8)
ops = [decode_op, resize_op, tochw_op, gridmask_op]
# Image path
imgs_dir = "/imgdir/xxx.jpg"
fnames = os.listdir(imgs_dir)
for f in fnames:
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
img = img.transpose((1, 2, 0))

Image Mixing
The image transformations and cropping methods mentioned earlier are operations performed on single images, whereas image mixing involves merging two images to generate one. The main difference between Mixup and Cutmix lies in how the mixing is done.
07
Mixup
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import transform
from ppcls.data.imaug import MixupOperator
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Image data rearrangement
tochw_op = ToCHWImage()
# Using HideAndSeek image augmentation method
hide_and_seek_op = HideAndSeek()
# Using Mixup image augmentation method
mixup_op = MixupOperator()
ops = [decode_op, resize_op, tochw_op]
imgs_dir = "/imgdir/xxx.jpg" # Image path
batch = []
fnames = os.listdir(imgs_dir)
for idx, f in enumerate(fnames):
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
batch.append( (img, idx) ) # fake label
new_batch = mixup_op(batch)

08
Cutmix
Paper link:
https://arxiv.org/pdf/1905.04899v2.pdf
from ppcls.data.imaug import DecodeImage
from ppcls.data.imaug import ResizeImage
from ppcls.data.imaug import ToCHWImage
from ppcls.data.imaug import transform
from ppcls.data.imaug import CutmixOperator
size = 224
# Image decoding
decode_op = DecodeImage()
# Image random cropping
resize_op = ResizeImage(size=(size, size))
# Image data rearrangement
tochw_op = ToCHWImage()
# Using HideAndSeek image augmentation method
hide_and_seek_op = HideAndSeek()
# Using Cutmix image augmentation method
cutmix_op = CutmixOperator()
ops = [decode_op, resize_op, tochw_op]
imgs_dir = "/imgdir/xxx.jpg" # Image path
batch = []
fnames = os.listdir(imgs_dir)
for idx, f in enumerate(fnames):
data = open(os.path.join(imgs_dir, f)).read()
img = transform(data, ops)
batch.append( (img, idx) ) # fake label
new_batch = cutmix_op(batch)

Experiments
Experimental verification shows that the classification accuracy using different data augmentation methods based on PaddleClas on the ImageNet1k dataset is as follows, indicating that data augmentation methods can effectively improve model accuracy.
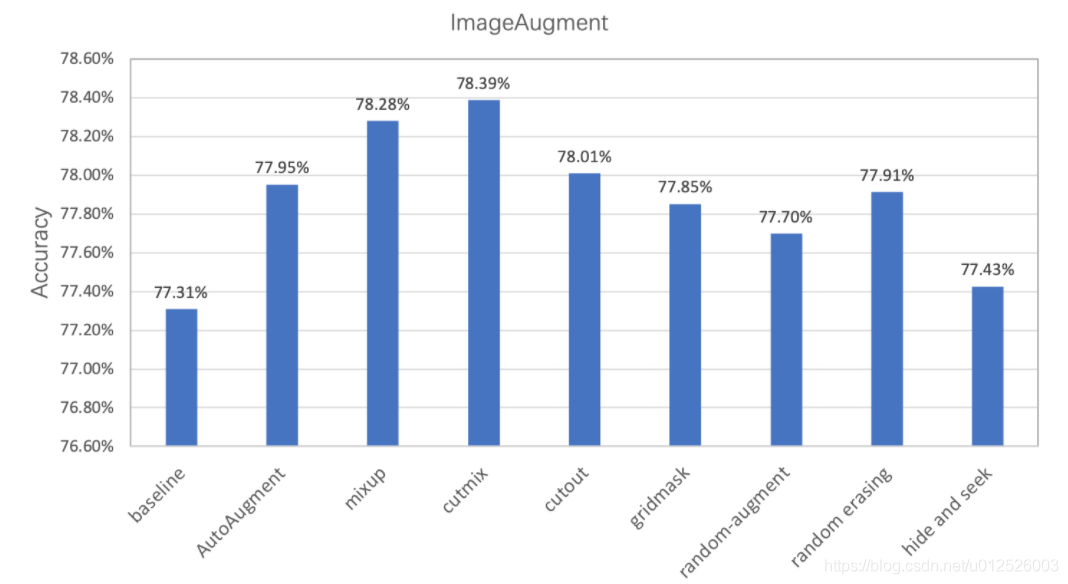
PaddleClas Data Augmentation Pitfalls
Guide and Some Precautions
Finally, here are some small tricks for using data augmentation in PaddleClas:
-
When using image mixing data processing, you need to set use_mix to True in the configuration file. Additionally, since labels need to be mixed during image mixing, the training accuracy cannot be calculated, so the training accuracy is not printed during training. -
After using data augmentation, the training data becomes more challenging, so the training loss function may be larger, and the accuracy of the training set may be relatively low, but it has better generalization ability, leading to higher validation set accuracy. -
After using data augmentation, the model may tend to underfit. It is recommended to appropriately reduce the value of l2_decay to achieve higher validation set accuracy. -
Almost every type of image augmentation contains hyperparameters. PaddleClas only provides hyperparameters based on ImageNet-1k; users need to adjust hyperparameters for other datasets. If you are unclear about the meaning of hyperparameters, you can read the relevant papers, and the methods for tuning can be referenced in the training tips section (https://github.com/PaddlePaddle/PaddleClas/blob/master/docs/zh_CN/models/Tricks.md).




END
Exciting Event Recommendations
