Skip to content

 Opinion / Liu Run Main Writer / You An Editor / Li Sang
This is the 1841st original article from Liu Run’s public account.
Yesterday, upon waking up, OpenAI in the United States officially announced the large model GPT–4.
It has only been 105 days since the launch of ChatGPT based on GPT–3.5.
The speed and intensity of technological advancement once again astonish people.
It seems that just after marveling at GPT–3.5 passing the Google programmer interview, GPT–4 has already scored in the top 10% of the U.S. bar exam.
Transitioning to the examination hall, it can even achieve scores that qualify for Harvard in the SAT.
Moreover, it has demonstrated tremendous potential in image recognition.
We always think that there is no rush, as there are still many things AI cannot do.
However, AI has accomplished one task after another, and at levels beyond human imagination.
As a result, many people start to feel anxious, eager to find opportunities.
But before seeking opportunities, I suggest you take a moment to calm down and take another look.
Understand what this GPT, which has swept through us time and again, really is.
Opinion / Liu Run Main Writer / You An Editor / Li Sang
This is the 1841st original article from Liu Run’s public account.
Yesterday, upon waking up, OpenAI in the United States officially announced the large model GPT–4.
It has only been 105 days since the launch of ChatGPT based on GPT–3.5.
The speed and intensity of technological advancement once again astonish people.
It seems that just after marveling at GPT–3.5 passing the Google programmer interview, GPT–4 has already scored in the top 10% of the U.S. bar exam.
Transitioning to the examination hall, it can even achieve scores that qualify for Harvard in the SAT.
Moreover, it has demonstrated tremendous potential in image recognition.
We always think that there is no rush, as there are still many things AI cannot do.
However, AI has accomplished one task after another, and at levels beyond human imagination.
As a result, many people start to feel anxious, eager to find opportunities.
But before seeking opportunities, I suggest you take a moment to calm down and take another look.
Understand what this GPT, which has swept through us time and again, really is.
GPT-4
It is known that GPT–4 should be more powerful than GPT–3.5. But what exactly makes it more powerful?
Before the official release of GPT–4, there were two speculations:
1. The machine learning parameters of GPT–4 will increase from 175 billion to 100 trillion. The difference in capability is comparable to that of a person earning 1750 yuan per month versus one earning 1 million yuan per month.
2. GPT–4 will support multi-modal inputs, meaning it can handle text, images, audio, and even video. The difference in capability is akin to that of a deaf and blind person compared to a person who can hear and see.
These are quite shocking speculations.
However, Sam, the boss of OpenAI, responded to this with: “complete bullshit.”
Is it really complete bullshit?
The actual results published show that GPT–4’s capabilities indeed appear to have improved.
1. The specific learning parameters were not disclosed. OpenAI only defined a personality for this iteration: “GPT–4 is more reliable, more creative, and capable of handling more detailed and complex instructions than GPT–3.5.”
2. It supports multi-modal inputs, but it only adds image support, and when GPT produces output, it still only responds in text.
While the extent of progress is not clear, the general direction is roughly accurate.
To truly understand GPT, I suggest you really grasp these two major directions: large models and multi-modal.
Let’s first talk about the most eye-catching update of GPT–4: multi-modal.
Is multi-modal impressive?
Multi-Modal
Imagine a colleague suddenly sends you a WeChat message: “Shh,Mr. Wang is behind you.”
Upon receiving it, you immediately turn around and seeMr. Wang, greeting him: “Mr. Wang.”
Is it impressive to achieve this?
It is indeed impressive. In just a few seconds, you processed multiple types of data: text, sound, and image.
Multi-modal refers to the modes and forms of various information data.
These different types of data, such as the text you recognize in the message, the image you see when you turn around, and the sound you utter, can sometimes point to the same information: “Mr. Wang.”
For you, recognizing and correlating the same “Mr. Wang” in a multi-modal context is quite simple, almost unremarkable.
But for GPT, it represents a grand ideal: to traverse multiple modalities and handle more complex tasks.
Because to achieve this, you first need to have eyes and ears.
The pre-upgrade ChatGPT could only communicate with you through text.
But after upgrading to GPT–4, ChatGPT has gained “eyes.”
You send it an image, it can “see,” understand it, and based on that, help you with more tasks.For example, help you edit out “Mr. Wang.”
This is the significance of multi-modal for GPT–4: it has evolved to have eyes.
Impressive. But this is not all of GPT–4’s evolution.
Large Models
Another frequently mentioned advancement is GPT–4’s fundamental skill—language ability.
In just 105 days, the language model of GPT has undergone a new round of evolution.
On one hand, the “maximum output limit of words” has been increased to 25,000 words.
Previously, if you gave it an article that was slightly longer, it might not be able to process it fully; now, many people even directly throw web pages or PDFs at it for processing.
Moreover, in understanding and answering questions, especially complex ones, GPT–4 also seems smarter.
How did it become smarter?
Simply put, GPT-4’s “brain” has become larger, and it has more “neurons.”
In 2018, GPT had 117 million parameters.
In 2019, GPT–2 had 1.5 billion parameters.
In 2020, GPT–3, and later ChatGPT based on GPT-3.5, had 175 billion parameters.
Yesterday’s released GPT–4, although the official parameter count was not disclosed, no one would underestimate its parameter count.
When GPT is unleashed, it’s in the billions of parameters. Moreover, it continues to double every year.
This is why when mentioning GPT, people often talk about “large models.”
A large number of parameters, like a large number of neurons, often means a greater probability of “guessing the answer you want.”
People often refer to this characteristic as being “smart.”
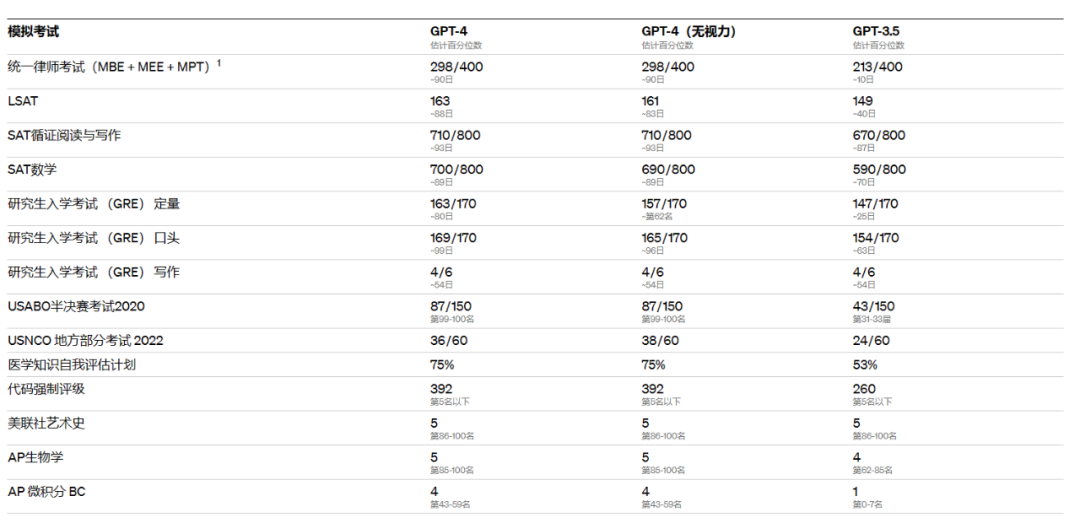 GPT-4’s partial report card
Think about this scale of parameters, and then look at GPT–4’s exam scores that “crushed” humans, and it seems more psychologically balanced.
However, it’s still hard to accept: does it really only require a sufficiently large parameter count to be smart enough to crush 90% of humans?
GPT-4’s partial report card
Think about this scale of parameters, and then look at GPT–4’s exam scores that “crushed” humans, and it seems more psychologically balanced.
However, it’s still hard to accept: does it really only require a sufficiently large parameter count to be smart enough to crush 90% of humans?
Training
Have you ever thought about how ChatGPT on the other side of the screen does the problem when you open the ChatGPT dialogue box and type a question?
For example, if you ask in the dialogue box: “The bright moonlight before the bed, what is the next line?”
As an artificial intelligence, rather than a human, ChatGPT’s approach to answering questions might be completely different from yours from the start:
It does not recall; instead, it immediately goes online to grab data. It checks where the phrase “The bright moonlight before the bed” appears.
Then it uses its “brain” that can simultaneously consider billions of parameters to calculate:
What words are likely to follow this line based on the context? What is the probability of these words being the correct answer?
Then it selects the text with the highest probability and responds to you in the dialogue box.
Finding combinations, calculating probabilities, comparing sizes.
You asked a language question, but it’s doing a math problem.
Because doing math problems is the essence of the model.
Yes. If the data samples it finds online happen to come from many erroneous pirated books, it might end up responding with something incorrect.
Clearly, the model doesn’t care about right or wrong, but humans do.
At this point, humans will do one thing: optimize it, train it.
Think back to how you solved this problem.
First, you must have seen this poem in your textbook.
Then, you did some exercises. After finishing, you checked the answers and someone told you whether you were right or wrong.
If you got it right, you receive points, and you’re happy, thus you remember the answer.
If you got it wrong, you lose points, you’re unhappy, and you go find the correct answer.
It first “reads” by inputting massive data.
Then it “takes exams” and receives “feedback.”
If correct, it gains points. If incorrect, it loses points.
The difference is that AI doesn’t feel happy or sad.
But who doesn’t like high scores?
Billions of parameters and their corresponding weights are adjusted based on this feedback, over and over again.
Until it approaches accuracy infinitely.
Doesn’t it sound perfect? But there is a significant difficulty.
Cost
Training comes at a cost.
The more astounding the parameter count, the more astounding the cost.
When a “brain” that needs to simultaneously consider hundreds of billions or even more parameters is running, what costs are involved?
Firstly, each training session can cost as much as several apartments in Shanghai.
Data shows that training a model based on GPT–3.5 for ChatGPT costs between 4.6 million to 5 million USD.
Additionally, to enter the GPT level of products, the “entrance ticket” is also very expensive.
For example, to achieve the necessary computing power, the earlier GPT–3 alone required 10,000 NVIDIA GPU chips during training.
Taking the currently mainstream NVIDIA A100 chip as an example, each costs about 80,000 yuan.
With 10,000 chips at 80,000 yuan each, the initial chip costs exceed 800 million yuan.
If you still have the courage to consider this, you might refer to OpenAI, the company behind ChatGPT.
OpenAI has already spent at least two large sums on the ChatGPT based on GPT–3.5:
Money paid to the “data center” for computing power and data was nearly 2 billion yuan.
Money paid to “people” such as scientists and engineers was nearly 500 million yuan.
This does not include daily electricity costs that can reach tens of thousands of dollars.
As for the newly released GPT–4, as a “smarter” brain, the computing power costs may be another new level.
These are the prices of being “smart.”
Despite being so expensive, there are always those willing to pay.
Final Words
For instance, Microsoft, which has invested nearly 90 billion yuan in ChatGPT.
Currently, Bing’s share in the global search engine market is in the single digits, with Google holding over 90% market share ahead of it.
However, after integrating ChatGPT, Bing proudly set this phrase in its search box:
Yesterday, after the release of GPT–4, Microsoft proudly announced:
The new version of Bing has already been using GPT–4 for some time; what many people experienced in the past five weeks was enhanced by GPT–4.
Today, Baidu also officially released Wenxin Yiyan.
Will it grow to become China’s OpenAI?
Currently, it remains uncertain.
Will China have its own GPT–4?
At present, it is also unknown.
However, it is clear that it will not be easy.
Data is hard to come by, and chips are also difficult to obtain.
But aren’t we facing such difficulties already?
Just as we dealt with challenges in the past, we will do the same now.






