

Source: DeepHub IMBA
This article is about 2700 words long, and it is recommended to read it in 5 minutes.
This article mainly introduces 3 commonly used methods in Langchain.
There are various methods to enhance the capabilities of Retrieval-Augmented Generation (RAG), one of which is called query expansion. Here we mainly introduce 3 commonly used methods in Langchain.
Query expansion techniques involve refining the user’s original query to generate a more comprehensive and informative search. Using the expanded query will retrieve more relevant documents from the vector database.

1. Step Back Prompting
Take A Step Back: Evoking Reasoning Via Abstraction In Large Language Models
This is a method developed by Google DeepMind, which uses LLM to create abstractions of user queries. The method takes a step back from the user query to better gain an overview of the question. The LLM will generate more general questions based on the user query.
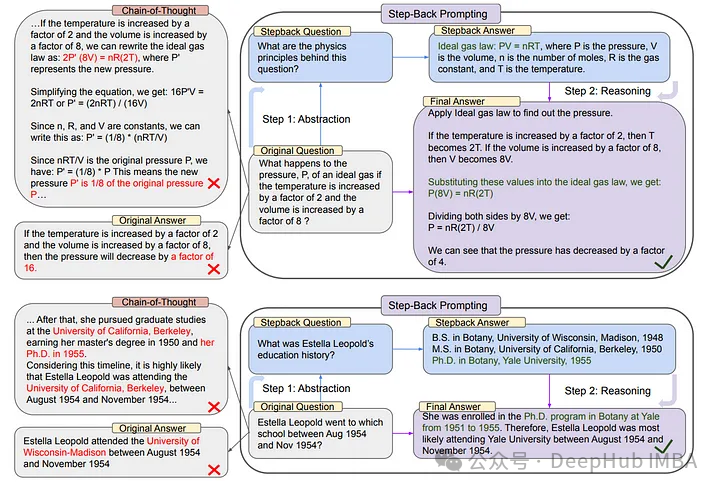
Below are examples of original queries and step-back queries.
{ "Original_Query": "Could the members of The Police perform lawful arrests?", "Step_Back_Query": "what can the members of The Police do?", }, { "Original_Query": "Jan Sindel’s was born in what country?", "Step_Back_Query": "what is Jan Sindel’s personal history?", }The following code demonstrates how to use Langchain for Step Back Prompting.
#---------------------Prepare VectorDB-----------------------------------
# Build a sample vectorDB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
import os
os.environ["OPENAI_API_KEY"] = "Your OpenAI KEY"
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
#-------------------Prepare Step Back Prompt Pipeline------------------------
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate, FewShotChatMessagePromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain.chat_models import ChatOpenAI
retriever = vectordb.as_retriever()
llm = ChatOpenAI()
# Few Shot Examples
examples = [
{
"input": "Could the members of The Police perform lawful arrests?",
"output": "what can the members of The Police do?",
},
{
"input": "Jan Sindel’s was born in what country?",
"output": "what is Jan Sindel’s personal history?",
},
]
# We now transform these to example messages
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""You are an expert at world knowledge. Your task is to step back and paraphrase a question to a more generic step-back question, which is easier to answer. Here are a few examples:""",
),
# Few shot examples
few_shot_prompt,
# New question
("user", "{question}"),
]
)
question_gen = prompt | llm | StrOutputParser()
#--------------------------QnA using Back Prompt Technique-----------------
from langchain import hub
def format_docs(docs):
doc_strings = [doc.page_content for doc in docs]
return "\n\n".join(doc_strings)
response_prompt = hub.pull("langchain-ai/stepback-answer")
chain = (
{
# Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever | format_docs,
# Retrieve context using the step-back question
"step_back_context": question_gen | retriever | format_docs,
# Pass on the question
"question": lambda x: x["question"],
}
| response_prompt
| llm
| StrOutputParser()
)
result = chain.invoke({"question": "What Task Decomposition that work in 2022?"})In that script, our question is
Original Query: What Task Decomposition that work in 2022?Step Back Prompting yields
Step Back Query: What are some examples of task decomposition in the current year?These two queries will be used to extract relevant documents, which will be combined as context, provided to the LLM to generate the final answer.
{ # Retrieve context using the normal question
"normal_context": RunnableLambda(lambda x: x["question"]) | retriever | format_docs,
# Retrieve context using the step-back question
"step_back_context": question_gen | retriever | format_docs,
# Pass on the question
"question": lambda x: x["question"], }2. Multi Query
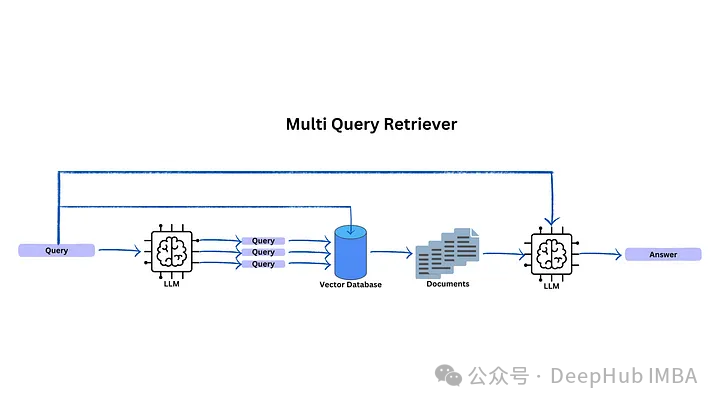
Langchain Multi Query Retriever
Multi-step queries are a technique that uses LLM to generate more queries from the first query. This technique attempts to address situations where the user’s prompt is not very specific. These generated queries will be used to look up documents in the vector database.
The goal of multi-step queries is to improve the queries to make them more relevant to the topic, thus retrieving more relevant documents from the database.
Since Langchain has detailed documentation, we will not include the code here.
3. Cross Encoding Re-Ranking

This method combines multi-query and cross-encoder re-ranking. When a user generates more questions using LLM, each generated query retrieves a pair of documents from the vector database.
These retrieved documents are passed through a cross-encoder to obtain similarity scores relative to the initial query. The relevant documents are then ranked, and the top 5 are selected as the LLM’s return results.
Why select the top 5 documents? To avoid retrieving irrelevant documents from the vector database as much as possible. This selection ensures that the cross-encoder focuses on the most similar and meaningful documents, thereby generating more accurate and concise summaries.
#------------------------Prepare Vector Database--------------------------
# Build a sample vectorDB
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
import os
os.environ["OPENAI_API_KEY"] = "Your API KEY"
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
llm = ChatOpenAI()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
#--------------------Generate More Question----------------------------------
# This function is used to generate queries using LLM
def create_original_query(original_query):
query = original_query["question"]
qa_system_prompt = """ You are an AI language model assistant. Your task is to generate five different versions of the given user question to retrieve relevant documents from a vector database. By generating multiple perspectives on the user question, your goal is to help the user overcome some of the limitations of the distance-based similarity search. Provide these alternative questions separated by newlines."""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)
rag_chain = (
qa_prompt
| llm
| StrOutputParser()
)
question_string = rag_chain.invoke(
{"question": query}
)
lines_list = question_string.splitlines()
queries = []
queries = [query] + lines_list
return queries
#-------------------Retrieve Document and Cross Encoding--------------------
from sentence_transformers import CrossEncoder
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
import numpy as np
cross_encoder = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2')
# Cross Encoding happens here
def create_documents(queries):
retrieved_documents = []
for i in queries:
results = vectordb.as_retriever().get_relevant_documents(i)
docString = format_docs(results)
retrieved_documents.extend(docString)
unique_a = [] # If there are duplicated documents for each query, make them unique
for item in retrieved_documents:
if item not in unique_a:
unique_a.append(item)
unique_documents = list(unique_a)
pairs = []
for doc in unique_documents:
pairs.append([queries[0], doc])
# Cross Encoder Scoring
scores = cross_encoder.predict(pairs)
final_queries = []
for x in range(len(scores)):
final_queries.append({"score":scores[x],"document":unique_documents[x]})
# Rerank the documents, return top 5
sorted_list = sorted(final_queries, key=lambda x: x["score"], reverse=True)
first_five_elements = sorted_list[:6]
return first_five_elements
#-----------------QnA Document-----------------------------------------------
qa_system_prompt = """ Assistant is a large language model trained by OpenAI. \ Use the following pieces of retrieved context to answer the question. \ If you don't know the answer, just say that you don't know. \
{context}"""
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
("human", "{question}"),
]
)
def format(docs):
doc_strings = [doc["document"] for doc in docs]
return "\n\n".join(doc_strings)
chain = (
# Prepare the context using the below pipeline
# Generate Queries -> Cross Encoding -> Rerank -> return context
{"context": RunnableLambda(create_original_query)| RunnableLambda(create_documents) | RunnableLambda(format), "question": RunnablePassthrough()}
| qa_prompt
| llm
| StrOutputParser()
)
result = chain.invoke({"question":"What Task Decomposition that work in 2022?"})The above code mainly creates two custom functions for generating queries and cross-encoding.
create_original_query is used to generate queries, which will return 5 generated questions along with the original query.
create_documents retrieves 24 relevant documents based on 6 questions (the 5 generated questions and 1 original query). These 24 relevant documents may be duplicates, so deduplication is necessary.
Then we use
scores = cross_encoder.predict(pairs)to give the cross-encoding scores between the documents and the original query. After that, we reorder the documents, keeping the top 5 documents.
Conclusion
These are the 3 most commonly used query expansion methods to improve RAG capabilities. When you are using RAG and not getting the correct or detailed answers, you can use the above query expansion methods to resolve these issues. I hope all these techniques can be utilized in your next project.
Editor: Yu Tengkai
Proofreader: Liang Jincheng
