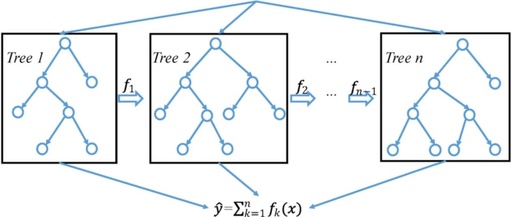
On Kaggle, 90% of fields including finance, tree models (like XGBoost) outperform deep learning neural network models. Let’s analyze the reasons.
01
Tree VS NN
Deep learning neural network models excel in fields such as image processing and natural language, but in tabular data, such as OHLC candlestick data, neither neural networks nor transformers outperform tree-based models like XGBoost or LightGBM.
We will analyze the reasons in conjunction with two papers: Tabular Data: Deep Learning is Not All You Need and Why do tree-based models still outperform deep learning on tabular data?
02
Deep Learning is Not All You Need
OHLC Data
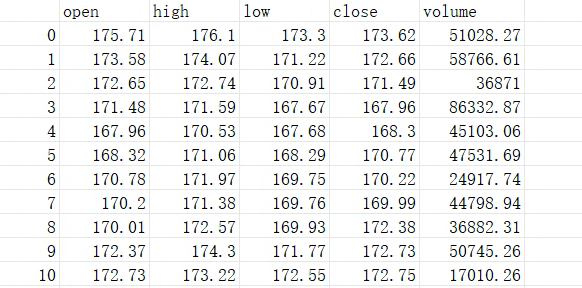
What is tabular data? Data represented in rows and columns such as OHLC data, trade data, and order book data are all types of tabular data.
Such data features are often sparse, requiring manual construction of factors for the model to learn, and typically, the data volume is relatively small.
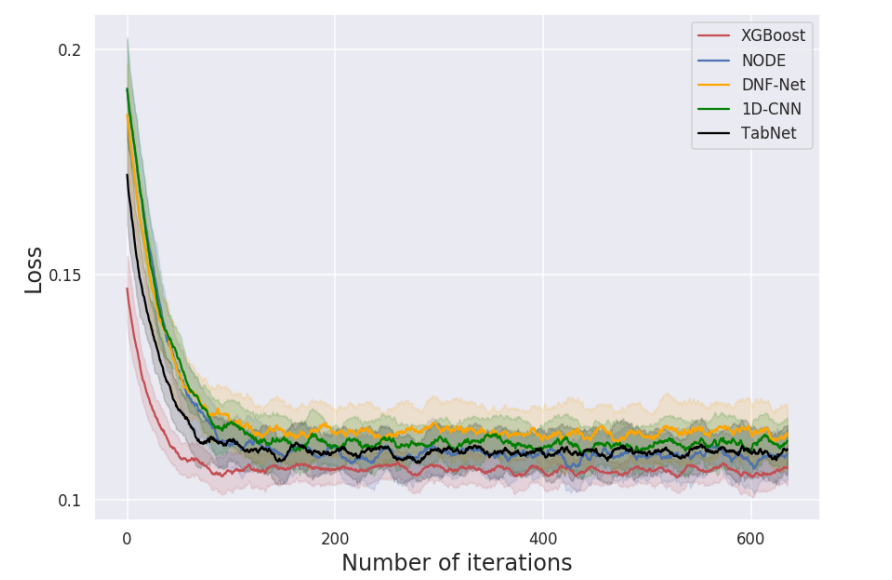
In the paper Tabular Data: Deep Learning is Not All You Need, a comparative experiment was conducted using 11 tabular datasets representing various classification and regression problems. The datasets included between 10 to 2,000 features, 1 to 7 classes, and 7,000 to 1,000,000 samples. Additionally, they varied in the number of numerical and categorical features, with some datasets having heterogeneous features.The conclusion from the experiment was that the XGBoost model outperformed deep learning models on most datasets.
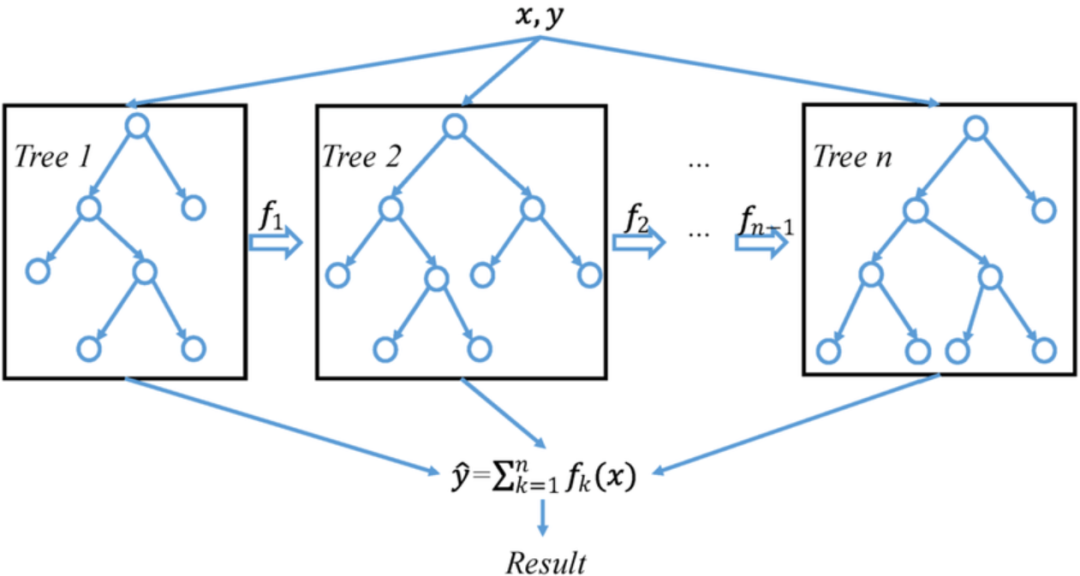
However, deep learning is not completely useless; the authors found that the integration of XGBoost with deep models exceeded the performance of XGBoost alone. If the factors have reached a bottleneck, it might be worth trying an ensemble of XGBoost and deep learning.
03
Analysis
Based on Léo Grinsztajn’s paper, we will analyze the reasons for this phenomenon.
1. Non-differentiability
Deep learning neural network models are based on gradient optimization, meaning the model’s objective should be a continuous function for better fitting. Abstractly, the model’s objective manifold should be smooth. However, financial data often behaves like a non-differentiable Brownian motion, containing limited signal features amidst a lot of noise. Tree models are particularly suitable for irregular, jagged data scenarios.
2. Non-informative Features
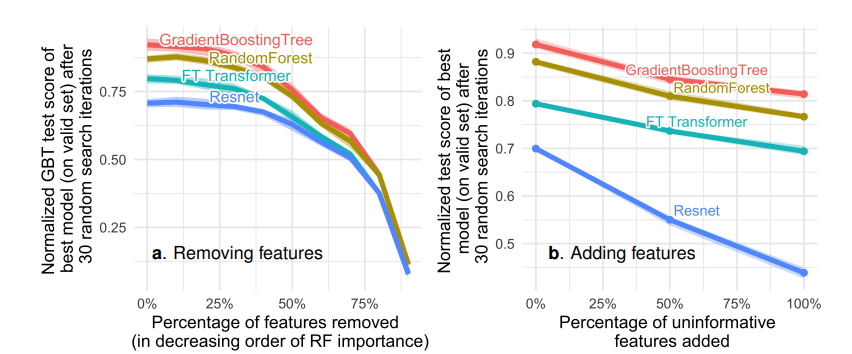
Deep learning models spend a lot of time optimizing useless features. The paper conducted a set of experiments testing the model performance when adding random features and removing non-informative features. The experiments found that removing features with little information reduced the gap between deep learning and tree models; tree models are less sensitive to random noise, likely because tree models can determine the usefulness of features, thus avoiding the impact of non-informative features.
3. Symmetry
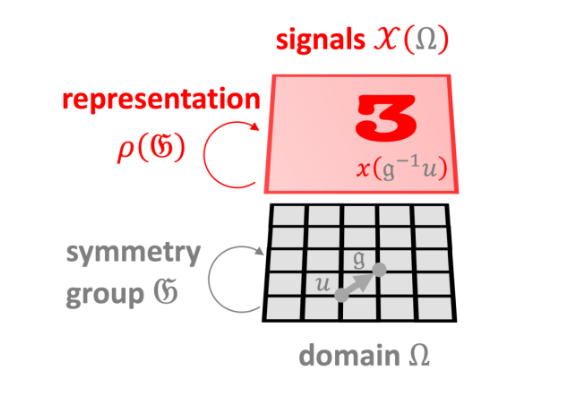
Let’s first understand a theorem: Any linear mapping that preserves group symmetry is a convolution. Therefore, convolutional neural networks have certain symmetric characteristics, such as translational and rotational invariance. The authors found that when rotating data by multiplying with a unitary matrix and then training the model, significant differences appeared in models other than CNNs. Therefore, data with certain symmetric features is more suitable for CNNs. In quantitative trading, we typically construct a large number of nonlinear feature factors, which almost lack symmetry, making tree models more suitable.
PS:
I am lazy and, at the request of fans, I opened an ML/RL quantitative community course. So where is everyone?
Unlike those watered-down courses online, this course combines AFML’s processing methods, starting from order flow to construct features.
Within the community, there are domestic experts in order flow; if interested, contact WeChat: sigma-quant
For community course inquiries, contact WeChat: sigma-quant
END
「 Previous Recommendations 」
Microstructure Basics – Starting from the 2760 Point Reversal in A-shares
2024-01-22
Reinforcement Learning in Quantitative Trading: Problem Analysis and Basics
2024-01-11
Heavy-tailed Distribution and Machine Learning Quantitative Regression Imbalance (2) – Features and Density
2023-12-21
Reasons for Failure of Machine Learning in Financial Quantitative (5) – Non-Independent Identically Distributed and Sample Imbalance
2023-11-28

Scan the QR code
Get more exciting content
sigma –
Quantitative and Freedom
