
Case Introduction
This case aims to predict the Boston housing data using the XGBoost algorithm. The Boston housing dataset is a commonly used dataset for house price prediction, containing 506 samples and 13 features, including crime rates in the area, average number of rooms per dwelling, and distance to the city center.
Algorithm Principle
XGBoost (eXtreme Gradient Boosting) is an optimized algorithm based on the Gradient Boosting Tree algorithm. Gradient Boosting Trees are an ensemble model that improves prediction performance by combining multiple weak classifiers (decision trees) into a strong classifier.
The principles of the algorithm can be divided into the following steps:
1. Initialize the model’s prediction value to a constant, usually the average value of the target variable in the training set.
2. Use gradient descent to calculate the negative gradient (residual) of the loss function under the current model’s prediction value.
3. Fit a new weak classifier (regression tree) to predict the negative gradient. At this point, regression trees are generally used for fitting because regression trees can handle both continuous and discrete features, while classification trees are better suited for discrete features.
4. Update the current model’s prediction value based on the negative gradient and learning rate.
5. Repeat steps 2-4 until reaching the predetermined number of iterations (number of trees) or meeting early stopping criteria.
6. Sum the prediction results of all weak classifiers to obtain the final model prediction value.
XGBoost also introduces regularization terms, such as L1 and L2 regularization, to control the model’s complexity and generalization ability.
Formula Derivation
Weighted Loss Function

First and Second Derivatives
Based on the loss function, we can calculate the first and second derivatives of the loss function with respect to the prediction value:
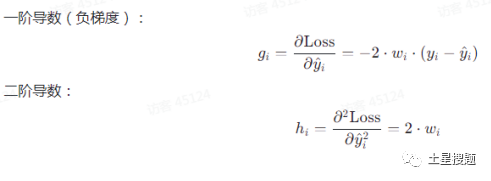
Regression Tree Fitting
The goal of regression tree fitting is to find the optimal split point that minimizes the value of the loss function. The loss function of the regression tree is defined as:

Dataset
The Boston housing dataset is used, which contains 506 samples and 13 features. Each sample represents housing information from a suburb of Boston, and the target variable is the median house price (in thousands of dollars).
Calculation Steps
1. Load the dataset
2. Data preprocessing: Split the dataset into training and testing sets and perform normalization
3. Define the XGBoost model and set the relevant parameters
4. Train the XGBoost model using the training set
5. Make predictions using the trained model on the testing set
6. Calculate performance metrics such as Mean Squared Error (MSE)
Python Coding Process
Load the Boston housing dataset using the load_boston() function.
Use the train_test_split() function to split the dataset into training and testing sets, with 20% for the testing set.
Normalize the training and testing sets, with a mean of 0 and a standard deviation of 1.
Convert the training and testing sets into XGBoost feature matrices, referred to as dtrain and dtest.
Define the parameters for the XGBoost model, such as loss function, learning rate, and maximum depth.
Train the model using the xgb.train() function, passing in the feature matrix dtrain and the number of boosting rounds num_boost_round.
Use the trained model to make predictions on the testing set, obtaining the prediction results y_pred.
Calculate the Mean Squared Error (MSE) between the predicted results and the actual values.
Visualize feature importance using the xgb.plot_importance() function.
The code uses the XGBoost Python library xgboost, converting the dataset into XGBoost feature matrices via xgb.DMatrix. During model training, relevant parameters for the XGBoost model can be adjusted to achieve better fitting results. Finally, by visualizing feature importance, one can analyze the degree of influence of each feature on the target variable.
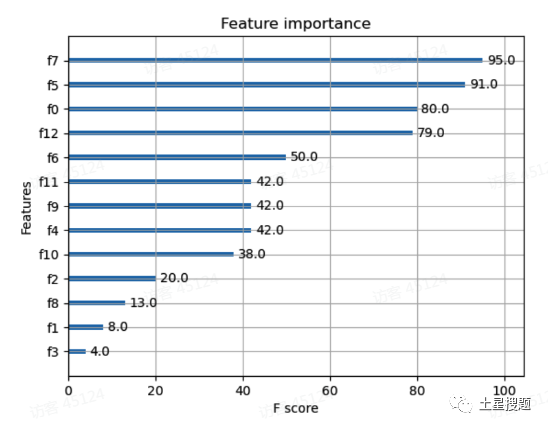
Run Results
Python code (available for paid reading if needed, otherwise you can refer to the above content and practice on your own!)