
As the year 2024 begins, two significant events have occurred in the AI industry between China and the United States, further pushing the third wave of artificial intelligence, which started in 1993, to its peak: OpenAI launched the GPT store, advancing the commercialization of AI; on January 16, China’s Zhiyu AI launched the GLM-4 model, which rivals GPT-4, adding a competitive edge for China in the global AI landscape.
With over 70 years of ups and downs in artificial intelligence, competing in talent, computing power, funding, and algorithms, which stories should we remember, and which lessons deserve scrutiny?
A Glorious Chapter Spanning Seventy Years
All to Put “Intelligence” into Machines
Alan Turing is a legendary figure; he is not only the “founding father” of every contemporary programmer but also a world-class long-distance runner, with a marathon time of 2 hours, 46 minutes, and 3 seconds, just 11 minutes slower than the gold medal time at the 1948 Olympics. During World War II, he led the “Hut 8” team to decrypt German military codes, which was a key factor in the Allies defeating the Axis naval forces in the Atlantic campaign.

Turing was also a marathon runner | midjourney
Of course, today we are still talking about “artificial intelligence.”
Turing is hailed as the father of computer science and artificial intelligence. In 1950, he first proposed the concept of “Machine Intelligence,” asking, “If humans can use available information and reasoning to solve problems and make decisions, then why can’t machines do the same?”
Since then, countless scientists and tech companies have strived to achieve this—the revolution of endowing machines with ‘intelligence’ quietly began. Over 70 years later, after “three waves and two troughs,” artificial intelligence has finally broken through numerous barriers and entered the daily lives of the public.
Looking back at the three waves of artificial intelligence, we find an interesting phenomenon: theory always precedes reality. It’s not that scientists can’t design better AI, but they are constrained by the computer technology of the time.
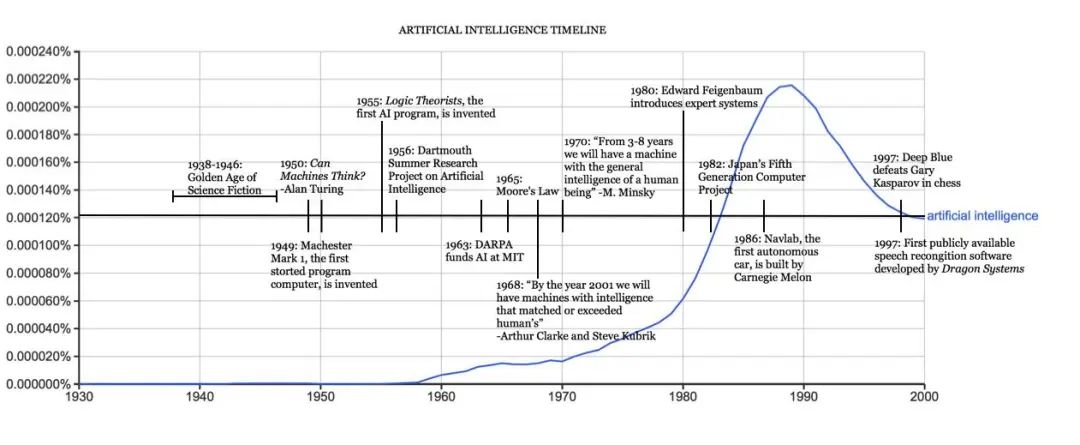
Timeline of Major Events in AI Development | Harvard University Official Website
Turing had already proposed the concept of machine thinking and the famous Turing Test in his 1950 paper “Computing Machinery and Intelligence.” What prevented Turing from starting work on AI? There are two reasons. First, in that era, computers lacked a key prerequisite for intelligence: they could not store commands, only execute them. This meant that computers could only be told what to do but could not remember what they had done. Second, the cost of computing was exorbitantly high in the 1950s; renting a computer cost $200,000 a month, which, when adjusted for inflation, is equivalent to about $2.54 million today, making it a true ‘game for the wealthy’.

A true ‘game for the wealthy’ | midjourney
Scientists are called scientists because their research always looks to the future, even when the conditions to turn ideas into reality are lacking.
Just two years after Turing published his famous paper, computer scientist Arthur Lee Samuel developed a checkers program and coined the term ‘machine learning’. At the Dartmouth Conference in 1956, John McCarthy formally introduced the term “artificial intelligence,” making 1956 the actual starting year of artificial intelligence.
Thus, “artificial intelligence” crossed the chaotic early stage and entered a period of rapid development. Years later, when the public looks back at that era, it will be referred to as the ‘first wave of artificial intelligence’.

The Father of Computer Science and Artificial Intelligence—Alan Turing
Let’s first look at what legacies the “first wave” has left for our lives today. It may come as a surprise that most of the software we use today can trace its roots back to the “first wave” of artificial intelligence, or rather, to a type of artificial intelligence known as “handcrafted knowledge.” For instance, our Windows system, smartphone applications, and traffic lights that change from red to green when you press a button on the sidewalk. All of these are considered artificial intelligence (as defined during the first wave).
Is this really “artificial intelligence”?
It is.
People’s understanding of artificial intelligence has always been changing. Thirty years ago, if you asked a passerby whether Google Maps is considered artificial intelligence, the answer would be yes. This software can help you plan the best route and clearly instruct you on how to drive; why wouldn’t it be considered AI? (Google Maps is indeed a typical example of the first wave of artificial intelligence.)
The first wave of artificial intelligence was primarily based on clear and logical rules. The system would check the most important parameters for each situation that needed to be solved and draw conclusions about the most appropriate actions to take in each case. The parameters for each situation were predetermined by human experts. Therefore, these systems struggled to cope with new situations and found it difficult to abstract knowledge and insights from certain situations to apply to new problems.
In summary, the first wave of AI systems could implement simple logical rules for well-defined problems but could not learn and struggled to handle uncertainty.
In 1957, Rosenblatt invented the perceptron, the earliest model of neurons in the theory of artificial neural networks, which also made significant breakthroughs in the theory of artificial neural networks. Optimism spread in the scientific community, and the first wave of artificial intelligence gradually reached its peak—only to face setbacks.
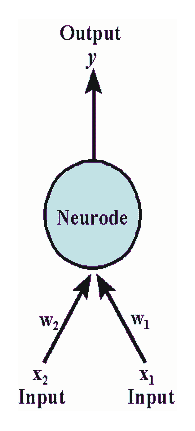
Perceptron Principle Diagram | California State University
By 1966, it seemed that artificial intelligence was going astray. Logic provers, perceptrons, reinforcement learning, and other systems could only perform very simple, highly specialized, and narrow tasks, and they were unable to cope with anything slightly beyond their scope. To better understand, we suggest readers recall their experience using the Windows system: every function is pre-designed, and you cannot teach the system to do anything; it cannot learn additional knowledge by itself.
On the other hand, at that time, computers faced challenges of limited memory and insufficient processing speed, making it very difficult to solve practical artificial intelligence problems. Researchers quickly realized that expecting programs to possess a child-like level of world cognition was an overly ambitious expectation. At that time, no one could build a massive database that met the demands of artificial intelligence, nor did anyone know how to enable programs to acquire such rich information. Meanwhile, the complexity of many computational tasks increased exponentially, making it almost impossible to complete these tasks.
Scientists found themselves in a dead end, and the development of artificial intelligence entered a “hibernation period.”
This wait lasted more than a decade.
When the time reached the 1980s, two key breakthroughs reignited the “second wave of artificial intelligence”: deep learning and expert systems.
John Hopfield and David Rumelhart promoted the technology of “deep learning,” allowing computers to learn from experience. This meant that artificial intelligence could handle problems “not pre-set”; it gained the ability to learn. On the other hand, Edward Feigenbaum introduced expert systems that mimicked the decision-making processes of human experts.
Overall, the second wave of artificial intelligence changed the direction of AI development. Scientists abandoned the symbolic approach and instead adopted a statistical approach to study artificial intelligence. The introduction of deep learning and expert systems enabled machines to infer answers to specialized problems based on domain expertise.
Therefore, the second wave of artificial intelligence is also called the ‘Statistical Learning Era’.
Regarding this wave, I want to emphasize two points: first, why is it so important? Second, what are its insurmountable drawbacks?
The second wave was short-lived, but by introducing “statistical learning systems,” engineers and programmers no longer had to painstakingly teach systems the precise rules to follow (as in the first wave). Instead, they developed statistical models for certain types of problems and then “trained” these models on many different samples to make them more accurate and efficient.
Moreover, the second wave systems introduced the concept of artificial neural networks. In artificial neural networks, data passes through computational layers, each processing the data differently and passing it to the next level. By training each layer and the entire network, they can produce the most accurate results.

Neural Network Diagram | Pixabay
These developments laid the foundation for the third wave of artificial intelligence and left a vast legacy that we still use today. For example, facial recognition, speech transcription, image recognition, and some functions of autonomous vehicles and drones all stem from the results of this wave.
However, this system has a significant drawback. According to the U.S. Defense Advanced Research Projects Agency (DARPA), we do not understand the actual operating rules behind artificial neural networks, meaning that while this system works well, we do not know why it works so well. It’s akin to a person throwing a ball into the air and being able to roughly judge where it will land; if you ask them how they made that judgment, whether it was based on Newton’s laws of motion, they cannot answer, but they just know.
This exposes a challenge of causality because “causality is not visible.” The second system relies on data input and data output to make decisions; lacking causality can lead to severe consequences: this system is prone to learning incorrectly.
Microsoft once designed a chatbot called “Tai,” which could chat smoothly with people, but if more and more people told it that “Hitler was a good person,” it would gradually accept that conclusion.
These challenges have been left to the third wave of artificial intelligence to solve.
This wave is also the one we are currently experiencing, often referred to as ‘Contextual Adaptation’. If one had to pinpoint a time frame, it should be after 1993. Moore’s Law has rapidly enhanced computing power, and the development of big data has made the storage and analysis of massive amounts of data possible.

Source: Open Source Image Library Pixabay
To better illustrate the differences from the previous wave of artificial intelligence, we can use an image as an example. If you use the second wave system to answer, “What animal is in the picture?” you would get, “The probability of the picture being a cow is 87%.” If the same question is posed to the third wave system, it not only tells you that it’s a cow but also provides logical reasoning, such as four legs, hooves, and spots, etc.
In other words, the third wave system is more logical.
I believe there are three crucial milestones in the third wave of artificial intelligence (usually considered to be the first two). In 2006, Geoffrey Hinton published a paper on “A Fast Learning Algorithm for Deep Belief Networks,” achieving several significant breakthroughs at the foundational theory level. In 2016, Google’s DeepMind developed AlphaGo, which defeated South Korean professional Go player Lee Sedol in a man-machine battle, marking the transition of “artificial intelligence” from the research field to the public domain, shifting from academic-led to commercially-led.
Then, on November 30, 2022, OpenAI released ChatGPT, making AI a consumer-grade product. “Generative AI” and “large language models” became hot topics of public discussion.
The Competition of Generative AI,
What Are We Competing For?
“Generative AI” is a branch of artificial intelligence that utilizes the powerful capabilities of large language models, neural networks, and machine learning to mimic human creativity in generating novel text, images, audio, and video content.
The public saw how brilliant OpenAI was, but it was equally struggling in its early days. At that time, OpenAI faced two dilemmas: one was a lack of funding, and the other was that its technical route was not recognized by the mainstream.
According to estimates, until 2019, OpenAI had received a total of only $130 million in donations, which is about 1 billion RMB, with Musk being the largest individual donor. Of course, this amount pales in comparison to the hundreds of millions of financing that domestic startups often receive. Due to a lack of funding, OpenAI had to rely on donations; in 2016, NVIDIA donated a DGX-1 supercomputer to OpenAI, helping it shorten the time to train more complex models (from six days to two hours).
In 2018, even Musk, the previous largest donor, left OpenAI. He had proposed taking over OpenAI but was rejected by the board, leading to his departure, and he did not donate again thereafter.
On the other hand, OpenAI chose a difficult path—developing pre-trained models first. In 2018, OpenAI launched the GPT-1 (Generative Pre-training Transformers) model, which has 117 million parameters, marking the year as the starting point for pre-trained models.
Why was the release of this pre-trained model so important? It marked a shift in the evolution of AI; prior to this, neural network models were supervised learning models, which had two drawbacks:
First, they required a large amount of labeled data, and high-quality labeled data is often difficult to obtain because in many tasks, image labels are not unique or instance labels do not have clear boundaries; second, models trained for one task struggled to generalize to other tasks, and such models could only be called “domain experts” rather than truly understanding NLP (Natural Language Processing).
Pre-trained models effectively solved the above problems.
In 2020, OpenAI released the third-generation Generative Pre-trained Transformer, GPT-3. This event also marked a turning point for another Chinese AI startup across the ocean—Zhiyu AI.
The release of GPT-3 sent a clear signal that large models were truly usable. After much debate and discussion, Zhiyu AI finally decided to fully engage in large model development, becoming one of the earliest companies in China to invest in this area.
Similarly, Zhiyu AI invested heavily in research and development of pre-trained models. In 2022, GLM-130B was released, and the Stanford University Model Center conducted a comprehensive evaluation of 30 mainstream large models worldwide, with GLM-130B being the only Asian model selected. The evaluation report showed that GLM-130B was comparable to or on par with GPT-3 175B (davinci) in terms of accuracy and fairness, and it outperformed GPT-3 175B in robustness, calibration error, and bias.

In fact, GLM-130B is a “pre-trained model” released by the Chinese technology company Zhiyu AI. A “pre-trained model” is a model trained to create a “large predictive model.” It is positioned even earlier than the “generative AI” that the public interacts with, serving as the underlying infrastructure buried beneath the surface. Currently, there are not many pre-trained models available on the market, with the more mainstream ones being GPT from OpenAI and Bert from Google. GLM-130B is a domestically developed pre-trained model that combines the advantages of the two frameworks mentioned above.
Zhiyu AI is striving to catch up, benchmarking against OpenAI and becoming the only company in China to match OpenAI’s entire model product line.
In 2020, OpenAI launched GPT-3
In 2021, OpenAI launched DALL-E
In December 2022, OpenAI released the sensational ChatGPT
In March 2023, OpenAI launched GPT-4
Comparing the product lines of Zhiyu AI and OpenAI, we can see:
GPT vs GLM
– ChatGPT vs. ChatGLM (Dialogue)
– DALL.E vs. CogView (Text-to-Image)
– Codex vs. CodeGeeX (Code)
– WebGPT vs. WebGLM (Search Enhancement)
– GPT-4V vs. GLM4 (CogVLM, AgentTuning) (Image and Text Understanding)
Why is it so crucial to seize the high ground of generative AI?
A statement from 2023 can answer this question: “All products deserve to be redone with AI”. The efficiency improvement brought by AI across various industries is revolutionary, occurring in services, new drug development, cybersecurity, and manufacturing upgrades.
According to data from the China Academy of Information and Communications Technology, in 2023, China ranked first in the world in terms of AI patent applications and paper publications, and the scale of China’s AI market is continuously expanding, expected to reach $513.2 billion by 2023, accounting for nearly a quarter of the global market.
“To do a good job, one must first sharpen one’s tools.” Under the training of the “tool” GLM-130B, Zhiyu AI launched its self-developed third-generation dialogue large model ChatGLM3 in October 2023, only four months after the release of the previous generation ChatGLM2.
On January 16, 2024, less than three months after the release of ChatGLM3, the company launched GLM-4, which boasts a comprehensive performance improvement of 60% compared to GLM-3. Its various parameters have reached levels comparable to GPT-4. In foundational capability indicators, MMLU 81.5, GSM8K 87.6, MATH 47.9, and BBH 82.25, GLM-4 has already reached over 90% of GPT-4’s level. HumanEval 72 has reached 100% of GPT-4’s level.
In terms of alignment capability, based on the AlignBench dataset, GLM-4 surpassed the version of GPT-4 released on June 13, approaching the latest effects of GPT-4, and exceeded GPT-4 in accuracy in professional capabilities, Chinese understanding, and role-playing.
GLM-4 also significantly enhanced multi-modal capabilities and agent capabilities, allowing it to autonomously understand and plan complex instructions based on user intent, freely invoking WebGLM search enhancements, Code Interpreter, and multi-modal generation capabilities to complete complex tasks. The personalized intelligent agent customization capability of GLMs has also been launched, allowing users to create their own GLM intelligent agents using simple prompt commands without needing coding skills.
In fact, the development path of Zhiyu AI also conforms to the inherent laws of the AI industry. “Artificial intelligence is not a simple process of progressing from 1 to 100; it often tends toward two extremes: either above 90 points, or all others below 10 points.” In other words, either ‘rapid breakthroughs’ or ‘treading water’, if one does not strive to move forward, one can only slide into the other extreme.
Returning to the historical timeline, we are currently in the third wave of artificial intelligence. Since there are waves, there will be peaks and troughs. The third wave will end; what will be the key driving force behind it?
Some believe that the technological dividends brought by “deep learning algorithms” will support our progress for 5-10 years, after which bottlenecks will emerge. Before these bottlenecks arrive, we urgently need a “technological singularity” to take the baton and push this wave to greater heights.
Where the “technological singularity” will be is still unknown. But one thing is certain: its emergence relies on long-term investment, deep research and development, and belief in technology from enterprises.
Cover image source: midjourney
– Produced by Guokr Commercial Technology Communication Department –
– Advertisement –