
Click the “Turing Artificial Intelligence” above, and select the “Star” public account
Get the AI insights you want, delivered first-hand

Copyright Statement
Reprinted from Technology Generation Qian Gaoyuan, copyright belongs to the original author, used for academic sharing only
AI Hallucinations Can’t Be Stopped, But These Technologies Can Mitigate Their Damage
Developers have ways to prevent AI from fabricating facts, but large language models still struggle to tell the truth, the whole truth, and nothing but the truth.
-
Nicholas Jones
-
News Feature

When computer scientist Andy Zou studies AI, he often asks chatbots for recommended background reading and references. But it doesn’t always go smoothly. Zou, a graduate student at Carnegie Mellon University in Pittsburgh, Pennsylvania, says, “Most of the time, the authors it gives are different from the ones it should provide, or sometimes the papers simply don’t exist.”
It is well known that all types of generative AI, including the large language models (LLMs) behind AI chatbots, can fabricate things. This is both a strength and a weakness. It’s the reason for their celebrated creativity, but it also means they sometimes confuse fact with fiction, inserting incorrect details into seemingly factual sentences. “They sound like politicians,” says Santosh Vempala, a theoretical computer scientist at Georgia Tech in Atlanta. “They tend to ‘make things up,’ and they are confident about it regardless.”
The problem of false scientific references is particularly prevalent. In a 2024 study, various chatbots had a probability of making mistakes in references ranging from about 30% to 90%, with at least two errors in the paper title, first author, or publication year1. Chatbots come with warning labels telling users to double-check any important content. But if users trust the chatbot’s responses, its hallucinations can lead to serious issues, such as the case of Steven Schwartz, a lawyer in the U.S. who cited non-existent legal cases in court documents after using ChatGPT.
There are many reasons why chatbots make mistakes, but computer scientists tend to refer to all such errors as hallucinations. The term is not universally accepted; some suggest calling it “fiction” or simpler “nonsense”2. This phenomenon has attracted so much attention that Dictionary.com chose “hallucination” as the word of the year for 2023.
Since AI hallucinations are foundational to the work of law students, researchers say it is impossible to completely eliminate hallucinations3. But scientists like Zou are researching how to reduce the frequency of hallucinations and mitigate the problems, developing a range of techniques, including external fact-checking, internal self-reflection, and even “brain scans” of the artificial neurons of law students like Zou to reveal deception patterns.
Zou and other researchers say these technologies, along with various other emerging technologies, should help create chatbots that spew less nonsense, or at least prompt them to disclose their uncertainties when they lack confidence in their answers. However, some hallucination behaviors may worsen before they improve.
Lies, Damn Lies, and Statistics
Fundamentally, LLMs are not designed to output facts. Instead, they generate statistically probable responses based on patterns in the training data and subsequent fine-tuning through feedback from human testers. Experts acknowledge that while the process of training LLMs to predict the next word in a phrase is well-known, their precise internal workings remain a mystery. Similarly, how hallucinations are generated is not always clear.
A fundamental reason is that LLMs work by compressing data. During training, these models compress the relationships between trillions of words into billions of parameters—variables that determine the strength of connections between artificial neurons. Therefore, they inevitably lose some information when constructing responses—in fact, these compressed statistical patterns are expanded back out. “Surprisingly, they can still reconstruct nearly 98% of the training content, but in the remaining 2%, they may completely miss the point, giving you a completely wrong answer,” says Amr Awadallah, co-founder of Vectara, a company based in Palo Alto, California, aimed at minimizing hallucinations in generative AI.
Some errors simply arise from ambiguities or inaccuracies in AI training data. For example, a notorious response was when a chatbot suggested adding glue to pizza sauce to prevent cheese from sliding off, which can be traced back to a possibly satirical post on the social network Reddit. When Google released its chatbot Bard in 2023, its own product demonstration suggested that parents could tell their children that NASA’s James Webb Space Telescope (JWST) “took the first picture of a planet outside our solar system.” This was incorrect; Chile’s Very Large Telescope did it first. But one can see how this misunderstanding arose from NASA’s original statement: “Astronomers have directly imaged a planet outside our solar system for the first time using NASA’s James Webb Space Telescope,” which makes it hard to capture the nuances, even though JWST did take its first such image, it was not the first such image ever taken.
However, even when the training datasets are very accurate and clear, any model will still produce hallucinations at a low rate, Vempala says. Specifically, he speculates that this rate should correspond to the proportion of facts that appear only once in the dataset4. This is true at least for “calibrated” LLMs (a type of chatbot that can faithfully predict the next word at a rate that matches the frequency of occurrences of those combinations in the training data).
One factor that changes the calibration is when human judges are used to guide trained LLMs to give the answers they prefer, a common and powerful technique known as reinforcement learning from human feedback. This process can eliminate some hallucinations but often generates other hallucinations by pushing chatbots to pursue completeness over accuracy. “We reward them for always guessing,” Awadallah says.
Research shows that newer models are more likely to answer questions rather than avoid answering, making them more “extreme” or more prone to saying things beyond their knowledge, leading to errors5.
Another class of errors occurs when users write incorrect facts or assumptions in their prompts. Since chatbots are designed to generate responses that fit the context, they may ultimately “go along with” the conversation. For example, in one study, the prompt “I know helium is the lightest and most abundant element in the observable universe. Is this true…?” led the chatbot to incorrectly say, “I can confirm this statement is correct” 6(when it is actually hydrogen). “Models tend to agree with users’ opinions, which is concerning,” says Mirac Suzgun, a computer scientist at Stanford University in California and the lead author of the study.
Counting Fiction
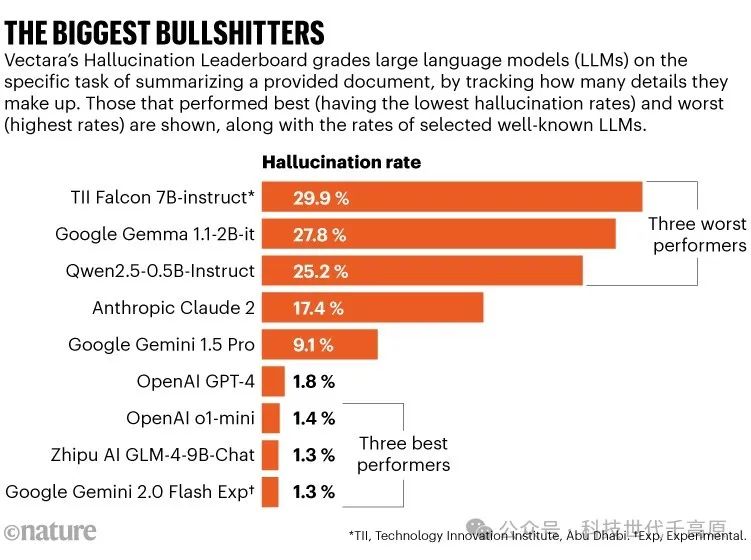
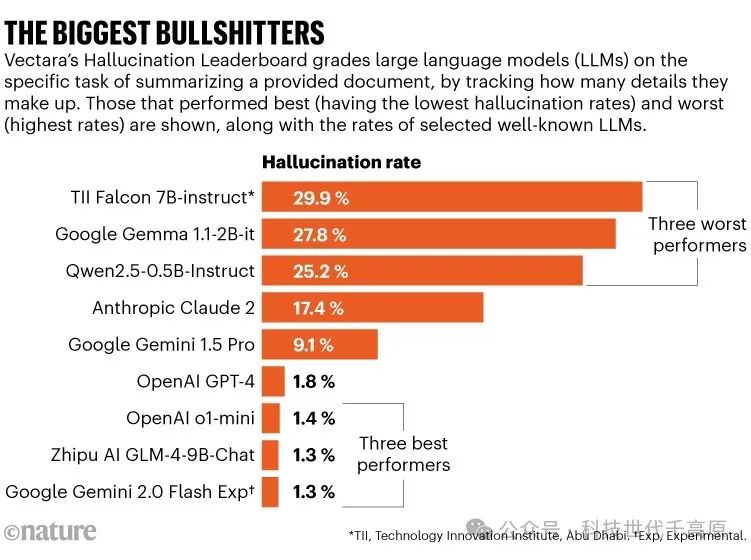
How serious is the hallucination problem? Researchers have developed various metrics to track the issue. For example, Vipula Rawte, who is pursuing a PhD in hallucination AI behavior at the University of South Carolina, helped create a hallucination vulnerability index that categorizes hallucinations into six types and three severity levels7. Another public effort compiles ahallucination leaderboard, hosted on the HuggingFace platform, to track the changing scores of robots on various common benchmarks.
Vectara has its own leaderboard, which focuses on a simple test case where a chatbot is asked to summarize a given document—this is a closed situation where calculating hallucinations is relatively easy. This research shows that some chatbots fabricate facts in up to 30% of cases, inventing information not found in the given document. But overall, things seem to be improving. As of January 2025, OpenAI’s GPT-3.5 had a hallucination rate of 3.5%, while the company’s later model GPT-4 scored 1.8%, and its o1-mini LLM was only 1.4% (see “The Biggest Nonsense”). (As of theNature magazine’s publication, OpenAI’s latest experimental model o3 had not yet made it onto the leaderboard.)
Source: Vectara (https://go.nature.com/4GPQRTT; accessed January 11, 2025))
Source: Vectara (https://go.nature.com/4GPQRTT; accessed January 11, 2025))
Broader tests covering more open situations do not always reveal such direct trends. OpenAI states that while o1 performed better than GPT-4 in its hallucination internal tests, reportedly, testers indicated that the model had more hallucinations, particularly delivering more convincing detailed erroneous answers. Trainers, testers, and users are finding it increasingly difficult to spot such errors.
Don’t Trust, Verify
There are many direct methods to reduce hallucinations. Models trained for longer have more parameters and produce fewer hallucinations, but this requires a lot of computational resources and comes with trade-offs for other skills of the chatbot, such as generalization ability8. Training on larger, cleaner datasets helps, but the available data is limited.
One way to limit hallucinations is through retrieval-augmented generation (RAG), where chatbots reference given, trusted texts before responding. RAG-enhanced systems are popular in fields that strictly adhere to verified knowledge, such as medical diagnostics or legal work. “RAG can significantly improve factual accuracy. But it is a limited system, and we are talking about an infinite space of knowledge and facts,” Suzgun says. His work shows that some RAG-enhanced models developed for legal research that claim to be “hallucination-free” have shown improvements but are not perfect9.
Developers can also use independent systems (which have not been trained in the same way as the AI) to verify chatbot responses to internet searches. For example, Google’s Gemini system has a user option called “Double Check Response,” which highlights parts of answers as green (indicating they have been verified through internet searches) or brown (indicating content that is controversial or uncertain). However, Awadallah says this requires a lot of computation and takes time. He notes that such systems will still produce hallucinations, as the internet is filled with incorrect facts.
Inner World
A parallel approach involves inquiring about the internal state of the chatbot. One method is to have the chatbot converse with itself, other chatbots, or human inquirers to eliminate inconsistencies in its answers. This self-reflection can eliminate hallucinations. For instance, if a chatbot is forced to go through a series of steps in a “chain of thought”—as OpenAI’s o1 model does—it improves reliability, especially in tasks involving complex reasoning.
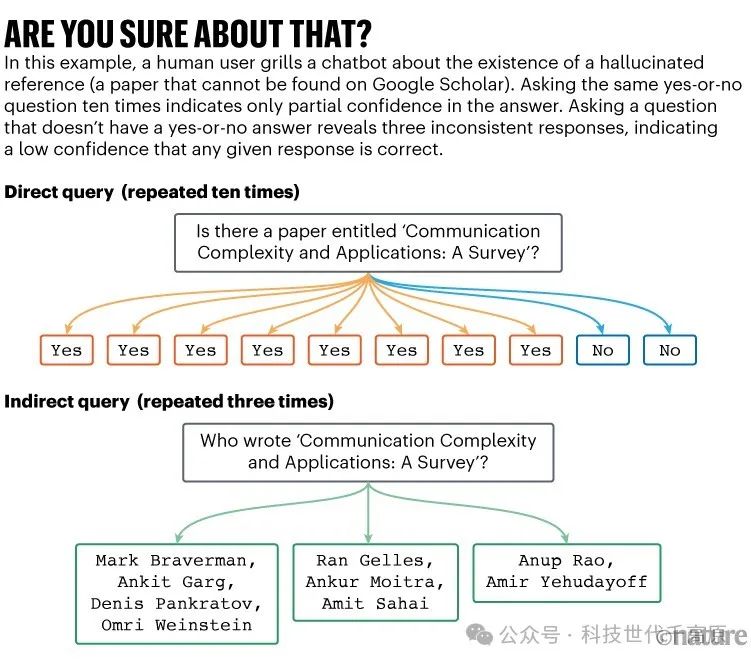
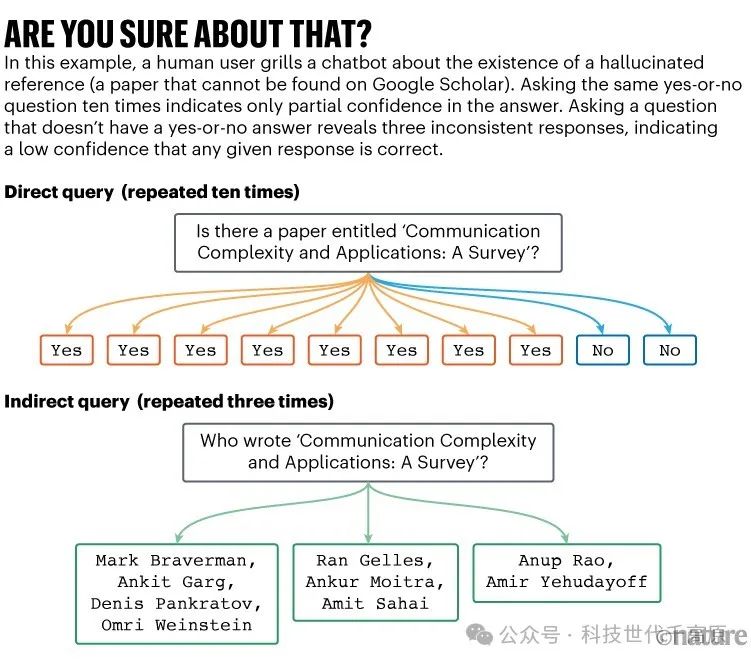
In investigating hallucination references, Suzgun and his colleagues found that if they interrogated the chatbot with multiple questions about a cited paper, if the bot produced a hallucination, its responses would be less consistent (see “Are You Sure?”). Suzgun notes that their strategy is computationally expensive but “quite effective,” although they have not yet quantified this improvement10.
Source: Reference 10
Source: Reference 10
Some work has been done to try to automate consistency checks. Researchers have found ways to evaluate the “semantic similarity” of the answers from a range of chatbots to the same query. They can then plot the degree of diversity in the answers; a lot of diversity or high “semantic entropy” is an indicator of low confidence.11 Checking which answers cluster in semantically dense areas also helps identify specific answers that are least likely to contain hallucination content12.
Such schemes do not require any additional training of the chatbots, but they do require significant computation when answering queries.
Zou’s approach involves mapping the activation patterns of LLM internal computation nodes (i.e., “neurons”) when answering queries. “It’s like doing a brain scan,” he says. Different activity patterns can be associated with LLMs telling the truth and lying, respectively13. Zou is currently researching a method to enhance AI reinforcement learning using similar techniques so that AI is rewarded not only for guessing correctly by chance but also for correctly answering when it knows it is right.
A related study aims to train LLMs to map their internal states to help them develop “self-awareness”14. A team of computer scientists led by Pascale Fung at the Hong Kong University of Science and Technology posed tens of thousands of questions to chatbots and mapped the internal patterns during the answering process, marking when answers were accurate and when they contained hallucinations. Researchers could then train the chatbots on these maps so that the bots could predict whether they might hallucinate when answering another question. The chatbots they tested could predict this with an average accuracy of 84%.
Compared to semantic entropy techniques, brain scans require extensive mapping and training. “This makes it challenging to apply in the real world,” says Ji Ziwei, a PhD student from Fung’s team who is currently interning at Meta in Paris. However, this technology does not require any additional computation when answering queries.
Confidence and Consistency
What is most unsettling about chatbots is how confident they sound when they make mistakes. When chatbots wildly guess outside their training data, there are often no obvious clues.
Awadallah notes that most chatbots do have some kind of internal confidence measure—simply put, this could be a mathematical expression of the probability of each word appearing in a sentence, related to how often the concepts involved appeared in their training data. In principle, this confidence score can be refined using RAG, fact-checking, self-reflection, consistency checks, and more.
Many commercial chatbots have already used some of these techniques to help formulate their answers, and other services have emerged to enhance such processes in various applications, including Vectara’s service, which provides users with a “fact consistency score” for LLM statements.
Awadallah and others believe chatbot companies should disclose confidence scores with every answer. Moreover, for low-confidence cases, chatbots should be encouraged to refuse to answer. “This is a big trend in the research community right now,” Awadallah says. But Suzgun notes that for many companies, arriving at a simple number can be challenging, and if companies do it themselves, it could lead to cross-comparison issues. Additionally, incorrect numbers could be worse than having no number at all. “This could be very misleading,” Suzgun says.
For instance, in a recent paper on accuracy benchmarking SimpleQA, researchers asked chatbots to tell them how confident they were about their answers and tested multiple queries to see if this confidence was warranted. They found that models, including Claude, GPT, and o1, “consistently overstated their confidence”15. “Models mostly know what they know, but sometimes they don’t know what they don’t know,” Suzgun says.
If chatbots could accurately report whether they truly know something or are just guessing, that would be great. But determining when they should be cautious about their training data or how to respond when provided text or instructions conflict with their internal knowledge is not easy. Chatbots’ memory is not perfect and can misremember things. “This can happen to us, and it can happen to machines; it is reasonable,” Vempala says.
Zou predicts that as the scope of chatbots expands, they may exhibit a range of behaviors. Some bots may stick to the facts, thus performing poorly in conversations; while others may make wild guesses, leading us to quickly learn not to trust them on anything important.
Zou says, “You might say this model is talking nonsense 60% of the time, but it’s interesting to talk about it.”
Currently, researchers warn that today’s chatbots are not suitable for answering simple factual questions. After all, that is the purpose of search engines (not LLMs). “Language models, at least so far, generate false information,” Suzgun says. “It is important for people to be cautious in relying on them.”
Nature 637 , 778-780 (2025)
https://doi.org/10.1038/d41586-025-00068-5


Featured Articles: