
Jishi Guide
How to adapt a pre-trained visual model to new downstream tasks without specific task fine-tuning or any model modifications? >> Join the Jishi CV technology exchange group and stay at the forefront of computer vision
Table of Contents
1 Completing Visual Prompting through Image Inpainting (from UCB)1 Visual Prompting Paper Interpretation1.1 Can the characteristics of a general model performing multiple downstream tasks in language models be transferred to the visual field?1.2 Introduction to the MAE-VQGAN Method1.3 Adding prompts to trained image inpainting models1.4 Design of Visual Prompt1.5 Dataset1.6 Experimental Results
TL;DR
Proposed solution to the question: How to adapt a pre-trained visual model to new downstream tasks without specific task fine-tuning or any model modifications? Note several keywords: no fine-tuning, no model modifications, pre-trained model, adapt to different new tasks.
This has been done in the NLP GPT-3 model, and the solution is: Prompt.
When facing new tasks, provide GPT-3 with examples of input-output and new input (Prompt) during inference, with the goal of automatically generating output results that are consistent with the given examples.
Therefore, this article aims to achieve this in the visual domain: during inference, provide input-output image examples for new tasks and new input images, with the goal of automatically generating output images that are consistent with the given examples.
So how to solve this problem? The conclusion of this article is: as long as the correct data is used for training and this problem is treated as an image inpainting problem, it can be solved.
The author trained on an 88k unlabeled dataset from Arxiv and demonstrated the effectiveness of the method on many image-to-image downstream tasks, such as foreground segmentation, single object detection, colorization, and edge detection.
What This Article Does
-
Proves that many computer vision tasks can be treated as image inpainting tasks, requiring only input-output examples and query images for some tasks. -
Constructed a large dataset containing 88,000 samples, allowing the model to learn the image inpainting task without any annotation information or task-related descriptions. -
Demonstrated that adding additional data (such as ImageNet) to the training dataset can yield better results.
1 Completing Visual Prompting through Image Inpainting
Paper Title: Visual Prompting via Image Inpainting (NeurIPS 2022)
Paper Link:http://arxiv.org/pdf/2209.00647.pdf
Paper Homepage:http://yossigandelsman.github.io/visual_prompt/
1.1 Can the Characteristics of a General Model Performing Multiple Downstream Tasks in Language Models Be Transferred to the Visual Field?
In recent years, self-supervised learning has become increasingly popular in computer vision and natural language processing. The capacity of modern deep learning models is growing, making them prone to overfitting when trained on smaller labeled datasets. Self-supervised learning provides a good solution to this problem, addressing the data hunger of these high-capacity deep learning models.
However, the features learned through self-supervised learning are not “ready for use” and typically require fine-tuning on some labeled datasets to adapt to specific downstream tasks. So, is it possible to avoid this fine-tuning?
This question has long been resolved in NLP, and the solution is the so-called prompt. A prompt refers to providing corresponding example inputs and query information for a specific language understanding task during testing. For example, here is a piece of prompt information:
Je suis désolé I’m sorryJ’adore la glace
The model’s output is:
I love ice cream
Can the practice of providing prompts for different downstream tasks during testing be extended to the visual field? In other words, unlike the current paradigm where one model performs one task in CV tasks, can we have a general model that can perform multiple user-specified tasks without any weight fine-tuning?
This article proposes that as long as a large-scale image inpainting model is trained on the correct data, it can serve as a tool for visual prompting.
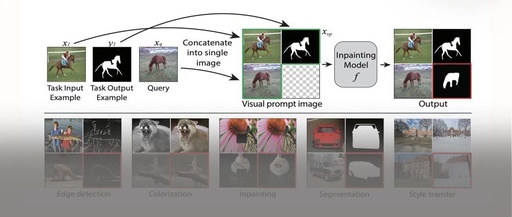
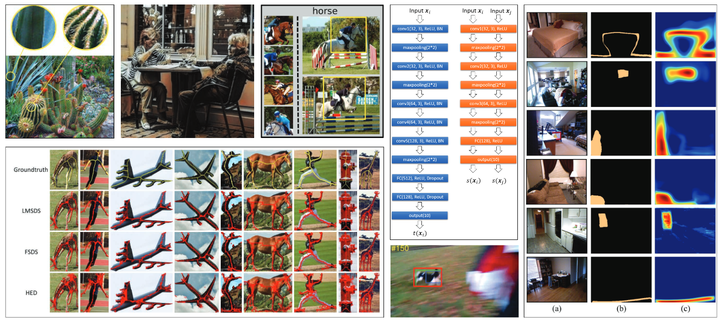
As shown in Figure 1, the author constructed a grid image. The input-output examples and new queries for the task are framed in green, and the model generates results by simply inpainting the remaining parts of the image, with the results framed in red. The only requirement of this method is that the task must be defined as image-to-image translation, which is a very large subset of visual problems.
By doing so, visual prompting can be effectively achieved through image inpainting. The problem can be well solved. When a new downstream task (such as Segmentation) arises, it is only necessary to provide an input-output example and a query. Then arrange them in a grid and feed them into the model to produce the corresponding results.
1.2 Introduction to the MAE-VQGAN Method
Given an input image and a binarized mask matrix, the goal of the image inpainting function is to synthesize a new image by filling in the masked positions:

To train this function, this article proposes the MAE-VQGAN method, which consists of the MAE[1] and VQGAN[2] models, as shown in Figure 2.
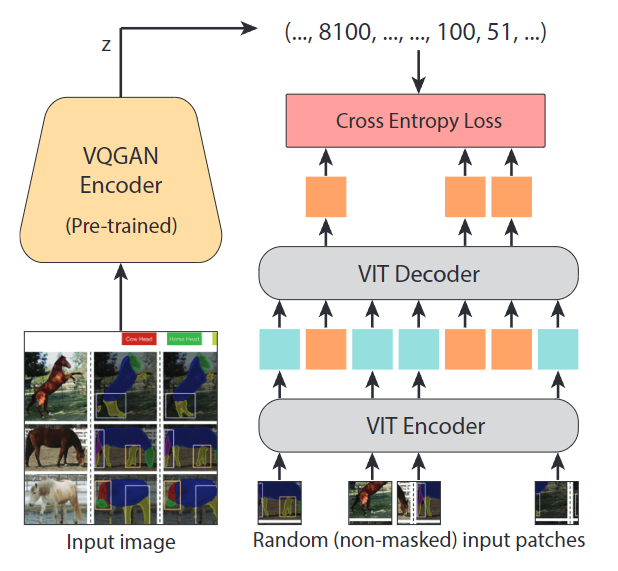
During training, the input image is divided into patches like ViT, some patches are masked, and sent to the MAE. Unlike MAE, which predicts pixels directly, MAE-VQGAN predicts visual tokens through a softmax layer. The author obtains the ground truth (GT) visual tokens by using the VQGAN Encoder to map the image to the indices of the visual tokens. For each masked token, the decoder outputs a distribution over the pre-trained VQGAN codebook. The model is trained using cross-entropy loss.
Let the ordered set of predicted visual tokens be , to obtain , the author uses the function:
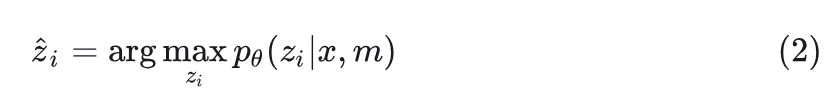
Finally, to decode the visual tokens back into pixels, the VQGAN Decoder is used to output .
1.3 Adding Prompts to Trained Image Inpainting Models
The author constructs a visual prompt, a grid image composed of task input-output examples and new query images. The inpainting model must inpaint the blank parts of the image.
Define as input-output image examples, for example is the input image, is the segmentation mask. Then given a new query image, the goal is to predict the corresponding label . The author needs to define a function , which maps the example set and the query image to new images and masks:

Where, the image is the visual prompt, and the mask defines the part that the inpainting model should predict.
The goal of the inpainting model is to output based on the visual prompt, and obtain the corresponding part of the mask.
1.4 Design of Visual Prompt
The function is designed to map the example set and the query image to new images and masks. The function creates an image that contains cells, where the input-output examples are in the first row, and the query image is on the left side of the last row. The author discusses various design schemes for the Visual Prompt and their corresponding results in the experimental section.
1.5 Dataset
The image generated by the function is not a natural image. Specifically, these images have a grid-like structure because they are stitched together from images from different distributions, such as natural images and segmentation masks. Therefore, models trained on standard datasets like ImageNet may struggle to handle these grid-like images. To address this, the author created a new dataset called Computer Vision Figures.
This dataset contains 88,645 images, which are closer in structure to the visual prompts presented in this article. The dataset was collected from Arxiv, where the author downloaded all papers from 2010 to 2022 and extracted those from the cs.CV partition, as they contain images more similar to grid structures, as shown in Figure 3.
To remove irrelevant source images, such as icons, the author manually labeled 2,000 images and trained a binary image classifier. The classifier assigns high scores to images that have graphic structures and at least one natural image. The author then used this classifier on the entire dataset, retaining only the most informative images from 23,302 different papers. The author randomly split 90% of the data for training, with the remainder for validation.
1.6 Experimental Results
To study the impact of model selection on prompting results, the author conducted experiments using different models, including MAE-VQGAN, VQGAN, BEiT, and several other inpainting models.
Downstream Task Experimental Results
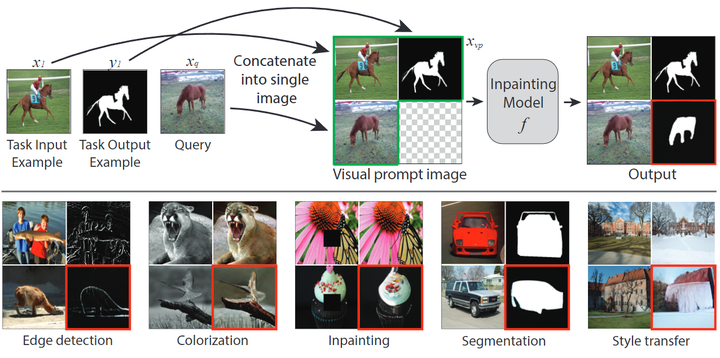
Construction Strategy for Visual Prompt: Given one example pair and one query image, the author constructs the visual prompt for all tasks in the same way: the author builds a 2×2 grid containing four sub-images. The input-output examples are in the first row, and the query image appears in the bottom left of the second row, as shown in Figure 1.
The author evaluates the image inpainting model on three visual tasks.
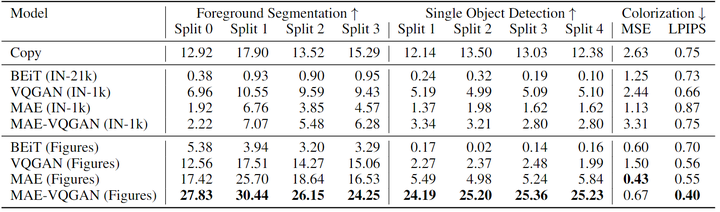
Foreground Segmentation Task: The goal is to binary segment the query image into foreground and background. The input-output example is an image and its corresponding binary segmentation mask, and the query image is a new image, with the goal of obtaining its binary segmentation mask. The author uses the Pascal-5i dataset and reports the mIoU metric.
Single Object Detection Task: Similar to foreground segmentation, the goal of this task is to binary segment the object appearing in the query image. However, this task is more challenging than foreground segmentation because the mask is derived from bounding boxes. The author uses the Pascal VOC 2012 dataset and its related detection boxes. For simplicity, the author uses Pascal annotations that only contain images with single objects and filters out images where the object covers more than 50% of the image. The author follows a similar process to obtain the binary segmentation mask and reports the mIoU metric.
Image Colorization Task: The goal is to map grayscale images to color images. The example pair consists of a grayscale image and its corresponding color image, as shown in Figure 4. The author randomly selects 1,000 example pairs and image queries from the ImageNet validation set, converts them to grayscale to obtain both grayscale and color versions for each image, and reports the MSE loss and LPIPS metrics.

The experimental results are shown in Figures 4 and 5. MAE-VQGAN significantly outperforms other models in detection and segmentation and generates clearer images than MAE. It can be observed that the VQGAN struggles to produce accurate results, possibly due to sequential decoding. The BEiT model performs better than MAE.
Synthetic Data Study
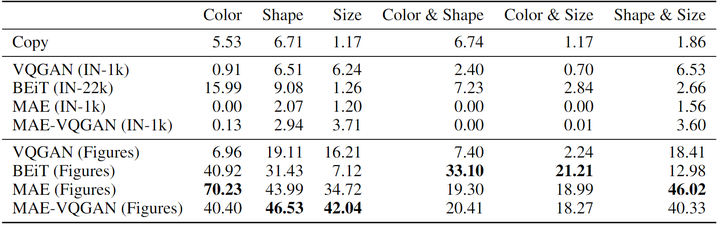
To evaluate the combinatorial predictive capability of the inpainting model, the author created three simple synthetic tasks and their combinations and evaluated each model on 100 examples per task.
Visual Prompt Strategy: Given two example pairs and one query image, the author constructs the visual prompt for all tasks in the same way: the author builds a 3×2 grid containing six sub-images. The input-output examples are in the first two rows, and the query image appears in the bottom left of the third row, as shown in Figure 6.
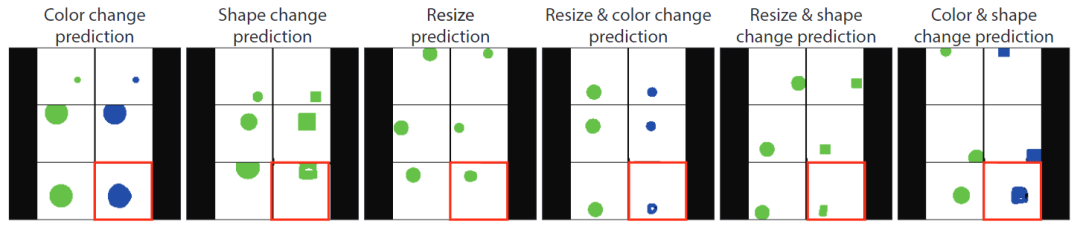
Each example pair consists of a colored shape image and another corresponding image with some variations. These variations can be in color, shape, size, or a combination of both, with detailed descriptions of the example images as follows:
Resize: Each example pair contains a circular image and a corresponding image with a smaller circle. The goal is to predict the image using the resized version given the image query.
Shape: Each example pair consists of an image with a circle and a corresponding image with a rectangle. Both are similar in size and appear in the same location. The goal is to predict the image using the rectangle given a new image query.
Color: Each example pair contains a circular image that appears in the same location, with colors transitioning from green to blue. Given a new image query, the goal is to predict the corresponding image with the circle colored blue.
Evaluation: The author maps each predicted pixel to its nearest neighbor color from a predefined set: black, white, blue, or green. The color-aware mIoU is measured and reported by treating pixels that appear in the GT shape color as foreground and the rest as background.
The experimental results are shown in Figure 7. It can be observed that if the model proposed in this article is not pre-trained on the dataset presented in this article, the image inpainting model cannot generalize to these tasks that it has never encountered before. When all models are pre-trained on the dataset proposed in this article, the performance of all models improves. However, due to increased complexity, the same model may struggle to handle combinations of tasks. The VQGAN model suffers from poor performance due to sequential decoding and lack of context. The MAE model outperforms MAE-VQGAN in color tasks, while BEiT performs poorly in Resize tasks. These models may require dVAE or codebooks, which may not be suitable for these tasks.
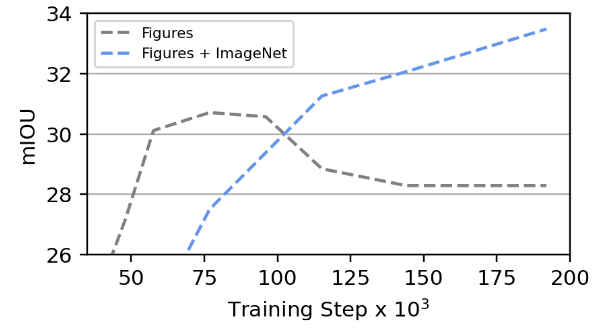
The Impact of Dataset Scale
The author evaluates the impact of dataset scale on pre-training. The author tries several scenarios, including training only on ImageNet, only using the dataset from this article, and a combination of both. As shown in Figure 8, the experimental results for foreground segmentation on Pascal-5i indicate that MAE-VQGAN trained on ImageNet consistently achieves 5 points lower mIoU. The model trained on the combined dataset performs the best, indicating that MAE-VQGAN can benefit from a large number of unlabeled images.
Visual Prompt Engineering
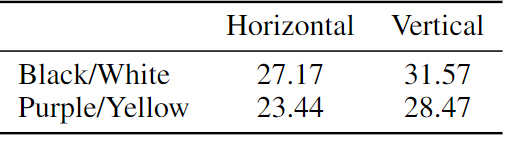
The author explores constructing different visual prompts for the foreground segmentation task and their corresponding MAE-VQGAN results. It can be observed that the model generates reasonable completions when changing the prompt layout, such as horizontal order versus vertical order (as shown in Figure 8) and changing mask colors, textures, or using only edges (as shown in Figure 9).

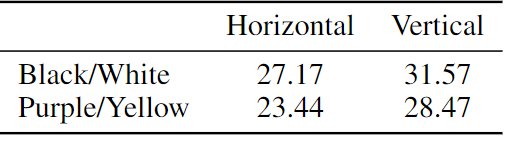
The mIoU results in Figure 11 indicate that the model performs best when the segmentation mask is black and white, and the prompt is in a vertical layout. Interestingly, by analyzing the average attention heads of the mask tokens, it can be observed that attention varies with changes in prompt layout.
References
-
^Masked Autoencoders Are Scalable Vision Learners -
^Taming Transformers for High-Resolution Image Synthesis

Reply “Dataset” in the public account backend to get 100+ resources sorted across various deep learning directions
Jishi Insights

Click to read the original text to enter the CV community
Gain more technical insights