Skip to content
Source | Eye on AIOneFlow Compilation and Translation | Jia Chuan, Yang Ting, Xu Jiayu
“The hallucination problem of ‘serious nonsense’ is a common issue that large language models (LLMs) like ChatGPT urgently need to address. Although reinforcement learning from human feedback (RLHF) can adjust the model’s output for errors, it is not efficient or cost-effective, and RLHF alone cannot completely resolve the issue, thus limiting the model’s practicality.
Due to the nature of large language models being based on the ‘statistical probability’ of language, the hallucination phenomenon indicates that LLMs do not truly understand the content they generate and lack a concept of correctness.
Previously, OpenAI Chief Scientist Ilya Sutskever mentioned that he hoped to prevent neural networks from generating ‘hallucinations’ by improving the reinforcement learning feedback process, expressing confidence in solving this issue, but simply stated, ‘Let’s wait and see.’
However, vector embeddings seem to be a simpler and more effective solution to this challenge, as they can create a long-term memory database for LLMs. By converting authoritative and trustworthy information into vectors and loading them into a vector database, the database can provide reliable information sources for LLMs, thereby reducing the likelihood of hallucinations.
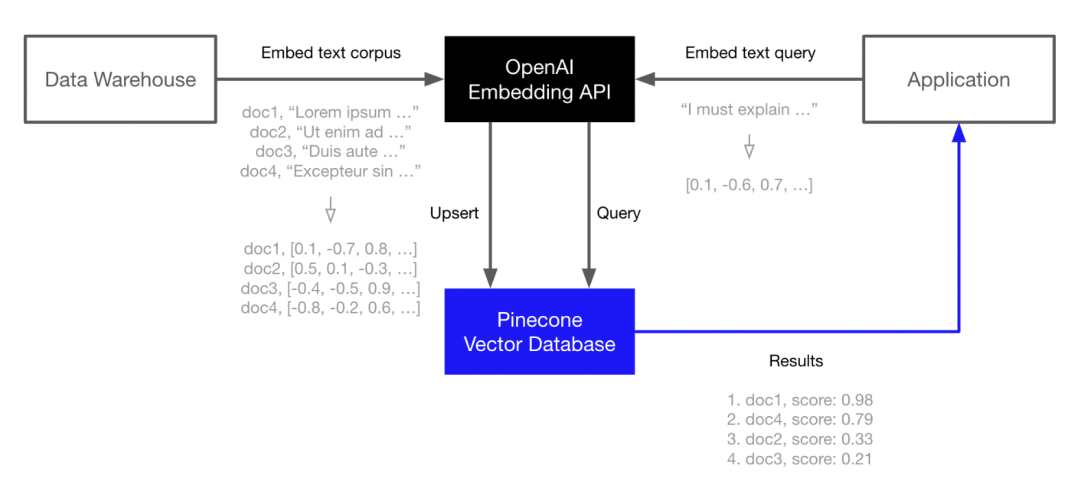
Recently, the popular AutoGPT has integrated the vector database Pinecone, enabling long-term memory storage, supporting context preservation, and improving decision-making.
Pinecone collaborates with LLM generators like OpenAI and Cohere. Now, users can generate language embeddings through OpenAI’s Embedding API and index these embeddings in Pinecone for fast and scalable vector searches.
The term ’embedding’ was first proposed by Yoshua Bengio in 2003. Czech computer scientist Tomas Mikolov introduced the word2vec toolkit for text vector representation in 2013, which can be used for downstream deep learning tasks.
Pinecone founder Edo Liberty was responsible for vector embeddings during his time at Amazon and began developing the Pinecone vector database after leaving Amazon. He holds a PhD in Computer Science from Yale University and previously served as the technical director at Yahoo, managing the AI lab. He later built services including the SageMaker machine learning platform at AWS. In mid-2019, he realized the special significance of large language models, with new methods of representing data through deep learning models becoming a fundamental part of data and AI.
Recently, in a conversation between Eye on AI podcast host Craig S. Smith and Edo Liberty, he discussed how to solve the hallucination problem of LLMs through vector embeddings, sharing technical details and the construction process.
(The following content is published with permission from OneFlow. For reprint authorization, please contact OneFlow. Original: https://www.eye-on.ai/podcast-117; sponsored by Netsuite,netsuite.com/eyeonai)
Solutions to the ‘Hallucination’
EDO:Pinecone is a vector database, but it does not use text representations like structures or syntax trees; instead, it employs a numerical internal representation used in deep learning models, language models, or chat engines for text processing tasks.
Machine learning models are numerical engines that process numerical objects, so the only way to represent data is through lists of numbers, known as vectors or embeddings. If you want to provide long-term memory and context for deep learning models, the ability to truly remember things and understand the world requires using these numerical objects to represent data.
However, storage layers, query languages, access patterns, and everything we want from the database do not apply to these objects; you need specific hardware and software to achieve this. Pinecone’s services can achieve this at scale. For instance, if you want to enhance ChatGPT’s contextual capabilities for better responses, you can store your data in a specific database. This data can be user manuals, historical records, images, text, Jira tickets, or emails.
Pinecone has now also released its own retrieval engine plugin, allowing users to insert these elements at the backend, enabling ChatGPT to search Pinecone in real-time for more accurate answers without requiring extensive connection setups.
The advantage of Pinecone is that you do not need to be a machine learning expert; you can simply copy and paste code from the tutorial, make adjustments to train the model, without needing to contact us or pay us any fees.
CRAIG: Does this help solve the hallucination problem of ChatGPT?
EDO:Absolutely. If you now ask ChatGPT how to turn off the automatic reverse brake light for the C70X model, it will give a very authentic and coherent answer, but this is actually just its hallucination. It answers very confidently, but it is of no value. Before explaining how to solve the hallucination problem, I want to emphasize the breakthrough of this technology itself.
I do not intend to belittle language models. For those who have been in the field for 15-20 years, this technology is undoubtedly shocking. ChatGPT’s coherence in language, combination methods, and the amount of data it absorbs are impressive, but the existence of hallucinations greatly diminishes its value. If the Volvo user manual is input as vector embeddings into Pinecone, allowing ChatGPT to search in real-time and obtain the correct context to answer questions, then ChatGPT can provide correct answers.
CRAIG: Ilya Sutskever’s focus is on training models using reinforcement learning from human feedback (RLHF) to avoid hallucinations. However, this method does not seem very efficient, and many people doubt whether the model can learn to align with reality. I have also discussed with Yann LeCun about building a world model for language models to reference. What you are talking about is constructing a specific domain ‘world model’ through Pinecone.
EDO:For example, in medicine, people learn a whole knowledge system, not just medical English. In fact, before entering medical school, people already master English, so what we learn are pieces of knowledge, memories, and facts, which you can then express clearly. What you learn is not fine-tuning the natural language model to the medical domain but injecting knowledge into the language.
In fact, pairing OpenAI with Pinecone is similar. We store data and knowledge in Pinecone, which can be specialized knowledge from any field, such as Jira tickets, sales calls, etc. Then the language model can convert this knowledge into language and summarize, understand questions, etc.
These are completely different functions, so the same mechanism should not be used. For example, ‘understanding what you say’ and ‘determining if what you say is correct’ are two completely different mechanisms. The former is about language processing, while the latter is about memory.
For example, I can say that I can push something with a stick, and I can also say that I can push something with a rope. But in fact, we can only pull things with a rope, not push. This is part of world knowledge and also part of memory, requiring both understanding and judgment. People will talk about the world in a realistic and feasible way, so they will not use unrealistic phrases like ‘pushing with a rope’ to express themselves.
Therefore, if the trained language model is large enough, it can discuss the world like a normal human. But this does not mean that the model truly understands anything; it may also ‘impersonate’ a doctor like the protagonist in ‘Catch Me If You Can’. For example, if you have only stayed in a hospital for five years, you may have encountered many professional terms, so when discussing related knowledge and skills, you sound like an experienced doctor but actually have no practical experience.
Some so-called ‘hallucination solutions’ are like this; they seem to allow people to appear to have certain skills or knowledge but do not truly understand the content. For me, this is hallucination. Just like listening to a doctor discuss many medical terms, we can articulate these terms in English but do not understand medicine at all.
CRAIG: So enhancing memory capacity is what Pinecone is currently doing. Are there other mechanisms for enhancing memory or domain knowledge? As far as I know, large language models can be pre-trained in an unsupervised manner, but there will ultimately be a supervised layer of training. Can we provide domain knowledge to large language models during supervised training?
EDO:I would distinguish between what can be done and what is often done. We can do many things and have tried many ways. However, in my view, the truly exciting point in the AI field is that AI has finally entered people’s lives. Now ordinary engineers, users, etc., can finally utilize AI and build applications based on AI.
Taking the combination of Pinecone and OpenAI as an example, we do not need to retrain or invent anything; we do not need to fine-tune, nor do we need to collect data labels. Essentially, you just need to input data in the form of vector embeddings into Pinecone, and there are many similar examples available online. We can ask OpenAI questions in real-time, allowing it to find relevant information on Pinecone.
For example, I am a salesperson and have input all sales conversations into Pinecone. Then I can ask, ‘Did I give a discount to a certain customer? If I did, what was the discount?’ Now we can use OpenAI or other large language model providers; basically, we just need to input the query, find the part of the conversation related to the answer, and get the answer, along with clear causes. For instance, the email sent to the customer about the discount shows that an 80% discount was given, etc.
In summary, we no longer need to retrain anything; we just need to input the context the large language model requires. When we call the chat API, they will include the query (i.e., the question), and we can also provide context related to the answer to obtain more information.
If we can provide the correct context, we can get better answers. It’s like asking others; for example, if you ask a salesperson a question, if they know the relevant information, they can integrate it and provide an answer; if they do not know the relevant information, humans will honestly say they do not know, but now chatbots may fabricate answers.
How to Convert Information into Vector Embeddings
CRAIG: OpenAI has stated that ChatGPT would be applied in the medical field, but it is currently still not very reliable. Without doctor verification, we cannot rely on any medical advice given by ChatGPT. However, if we could let large language models reference trusted medical documents or textbooks, then we wouldn’t need a doctor and could directly refer to the answers provided by large language models. So, how can we import practical medical texts into Pinecone?
EDO:First, I do not recommend referring to the answers given by large language models for medical issues, especially when facing health crises for oneself or loved ones. But I understand the desire to try, as having something is better than nothing; after all, a less skilled doctor is still preferable to no doctor. In summary, I do not advocate this behavior.
In fact, achieving this is very simple. We can obtain medical textbooks or medical notes, split them into sentences or paragraphs, and then feed the split sentences and paragraphs into the embedding model. These language models represent text through deep learning models, and this numerical representation is called a vector or embedding.
Then we save them to Pinecone; while saving, we can also store useful information, such as text sources or source texts, but the numerical representation is the operable part. During actual queries, for instance, when we have some symptoms or medical questions, it’s essentially doing the same thing. You can embed questions, search embeddings, request related documents, or content similar to the query topic. After querying, if we get a hundred files or a hundred paragraphs of sentences related to the answer, we can add them as context to the query and tell the chat engine, ‘These are my symptoms; I want to know about these aspects.’
If we retrieve 50 different sources of data related to the answer, we can integrate this data in a short time, just like the hackathons held in San Francisco, New York, etc., where participants can integrate this information in one day. Integrating this information is actually very easy because we don’t need to retrain anything; everything can be handled by hosted services, without needing to start hardware or deal with a lot of nonsense; we just need to call the API and let them process and adjust the data. This way, we can complete a large project in one day.
CRAIG: I’m curious about the pipeline; if I want to feed an authoritative history book into Pinecone, how should I do it? How to convert information into vector embeddings?
EDO:First, the text must be digitized; you can do this by scanning or other means, or you can use data in formats like PDF or Word. Then we need to break down this text into smaller parts, such as sentences or paragraphs that are coherent. You cannot directly feed an entire book or just one or two words; instead, you need meaningful, human-readable, and logically coherent refined content.
After completing the text splitting, you can embed it into the deep learning model. Additionally, there are many free text resources available online that people can use; they just need to write a few lines of Python code to import this text into the computer and then use these resources for training, or you can use an API to train in the cloud.
In this way, you will get vector embeddings returned by the model, which is a list containing hundreds or thousands of numbers. Then, pass the vectors to the Pinecone database and tell it which information is useful, such as the introduction of Napoleon’s invasion on page 712 of the history book; this process is equivalent to establishing your own database. Now, you can build machine models based on this and use the content of that history book as the knowledge source for model dialogues.
CRAIG: Does Pinecone provide a frontend to complete all operations? Or do users need to prepare vector embeddings in advance to integrate them into Pinecone?
EDO:Currently, our company only provides the database, so the decision on which machine learning model or language model to use still lies with the user. We only provide the most convenient tools to help users easily find the model. We collaborate with companies like OpenAI, Hugging Face, Cohere, Google, Amazon, and Azure to build new types of language models. About 50 or 60 startups are supported by us, aiming to build better language models.
CRAIG: If Pinecone converts information into vector embeddings, does this involve copyright issues?
EDO:The way customers use Pinecone is similar to other database services like MongoDB, Elasticsearch, Redis, Dynamo DB, Spanner, etc. As a customer data infrastructure, we store and manage customer data through Pinecone, but as a service provider, we do not access, use, share this data, nor do we use it for model training.
The practical reason why people prefer using tools like vector databases to create context rather than retraining or optimizing modelsis that the former allows data deletion. For example, if you need to delete some data to comply with GDPR regulations, you can say, ‘For existing data, perform a clear operation, namely delete data point 776.’ Then you can execute the delete operation to permanently remove the data point.
If these data points are input into an optimized model and attempts are made to use these data points to improve task execution, then these data points will remain in the model because there is no mechanism to delete them.
CRAIG: What challenges are you currently facing?
EDO:The biggest challenge is launching enough hardware to support all training needs, which is an issue our core engineering team needs to solve daily. The current hardware usage demand is enormous, and the emergence of ChatGPT has further increased this demand.
-
AI算力碎片化:矩阵乘法的启示
-
推演语言模型的大小与计算开销
-
GPT-4创造者:第二次改变AI浪潮的方向
-
谷歌科学家:ChatGPT秘密武器的演进与局限
-
比快更快,开源Stable Diffusion刷新作图速度
-
OneEmbedding:单卡训练TB级推荐模型不是梦
-
试用OneFlow: github.com/Oneflow-Inc/oneflow/