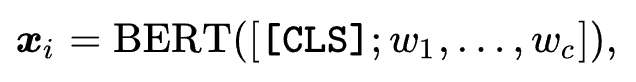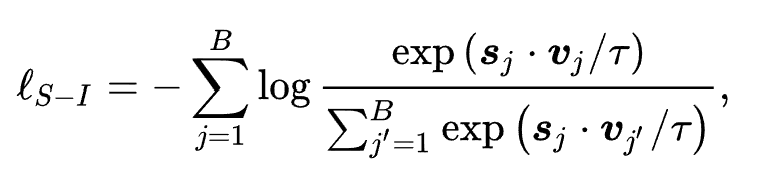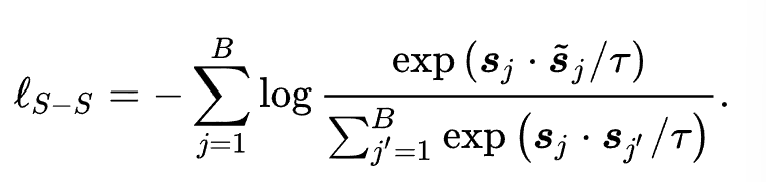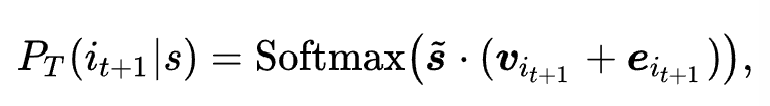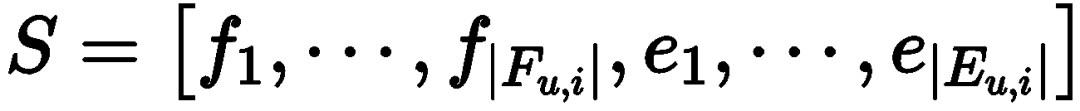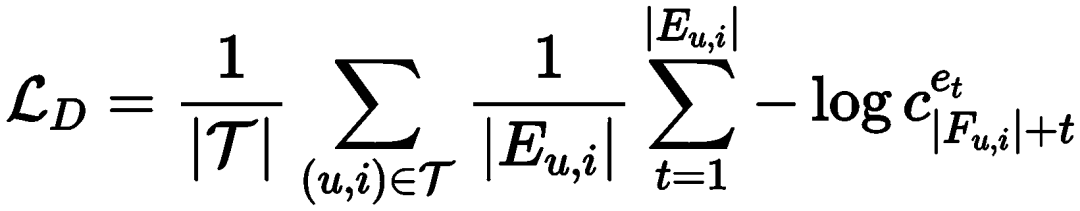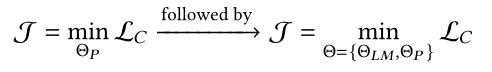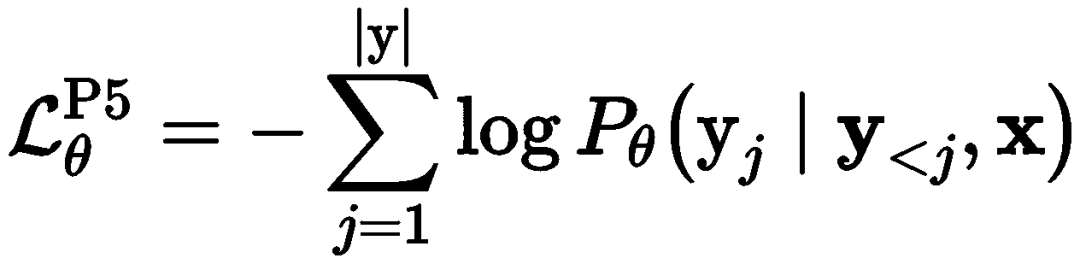MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, covering NLP graduate students, university teachers, and industry researchers.
The Vision of the Community is to promote communication and progress between academia, industry, and enthusiasts in the field of natural language processing and machine learning, especially for beginners.
Reprinted from | RUC AI Box
Institution|Renmin University of China
Research Direction|Recommendation Systems
For a long time, recommendation systems and natural language processing technologies have influenced and promoted each other. For example, some works utilize textual information to enhance the representation of users and products; some works treat the user’s historical interaction sequence as a text sequence in natural language and use language modeling methods to improve recommendation performance. With the continuous development of pre-trained language models, their parameter sizes are becoming larger, and the knowledge stored is becoming more abundant. Some works utilize pre-trained language models to learn general representations; some works gradually attempt to describe recommendation tasks in the form of natural language and solve recommendation tasks using pre-trained language models through designed prompts. This article summarizes some recent works and progress in this area. Everyone is welcome to criticize, correct, and exchange ideas.
1. Towards Universal Sequence Representation Learning for Recommender Systems
KDD 2022 | How Far Are We from a Universal Pre-trained Recommendation Model? The Universal Sequence Representation Learning Model UniSRec for Recommendation Systems
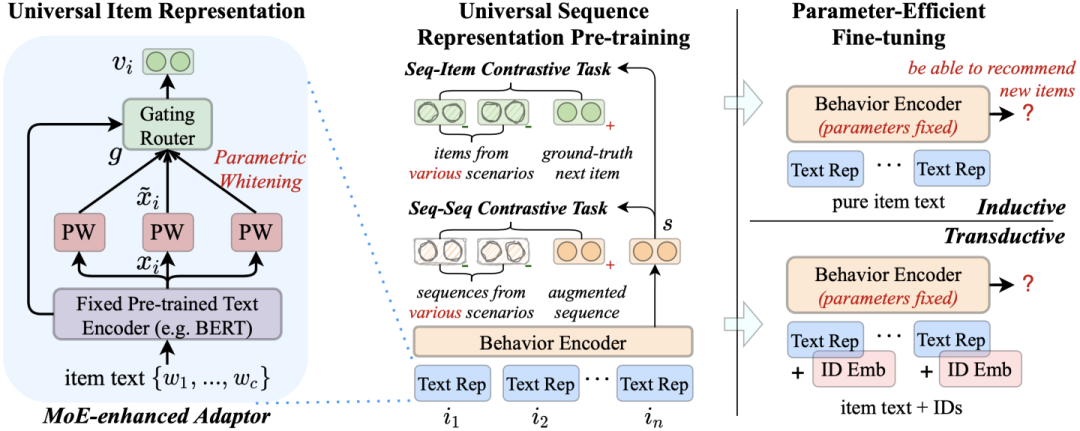
This article points out that traditional sequence recommendation models face issues of poor transferability and cold start for products because product IDs are not shared across domains/platforms. To address this, a new sequence representation learning method, UniSRec, is proposed, aiming to break the limitations imposed by explicitly modeling product IDs by encoding product texts and generating transferable universal product representations, and further pre-training on multiple domains to learn universal sequence representations.
UniSRec learns transferable product representations based on product texts. Specifically, it first uses pre-trained language models (PLM) to learn text representations.
Since text representations from different domains may form different semantic spaces (even if the text encoders are the same), this article proposes to use parameter whitening networks and mixture of experts (MoE) enhanced adapter modules to transform the original text representations into a universal semantic space suitable for recommendation tasks.
Because different domains typically correspond to different user behavior patterns, simply mixing sequences from these different domains will not yield good results. Therefore, this article proposes two contrastive learning-based tasks for pre-training, further promoting the fusion and adaptation between different domains.
1. Sequence-Product Contrast Task. Simply put, given a sequence, predict the next product at the next moment. For a given sequence, its next product is a positive example. Unlike the traditional next item prediction task, in this task, UniSRec uses products from multiple domains in-batch as negative examples, hoping to enhance the fusion and adaptation of universal representations across different domains.
2. Sequence-Sequence Contrast Task. For the second task, this article designs a sequence-level self-supervised task to enhance pre-training. Using two heuristic data augmentation strategies, it generates negative examples for a given sequence. Specifically, for a product sequence, it randomly drops products or words from the product text in the original sequence to construct positive examples, while negative examples are other sequences from multiple domains in-batch.
After pre-training, when adapting to new recommendation scenarios, UniSRec chooses to fine-tune only the parameters of the MoE-enhanced adapter. The authors find that the proposed MoE-enhanced adapter can quickly adapt to unseen domains, integrating features of the pre-trained model with those of the new domain. Depending on whether product IDs are available in the new recommendation scenario, two fine-tuning methods are set, named Inductive and Transductive.
The inductive scenario targets recommendation scenarios where new products frequently emerge. The authors believe that traditional product ID-based models may not be suitable in this case. Since UniSRec inherently does not rely on product IDs, it can learn general text representations for new products. At this point, we can predict products with the following probability:
The transductive scenario targets situations where almost all products appear in the training set. In this case, while learning general text representations, it also learns product ID representations. It simply adds the general text representation and the ID representation for prediction:
2. Language Models as Recommender Systems: Evaluations and Limitations
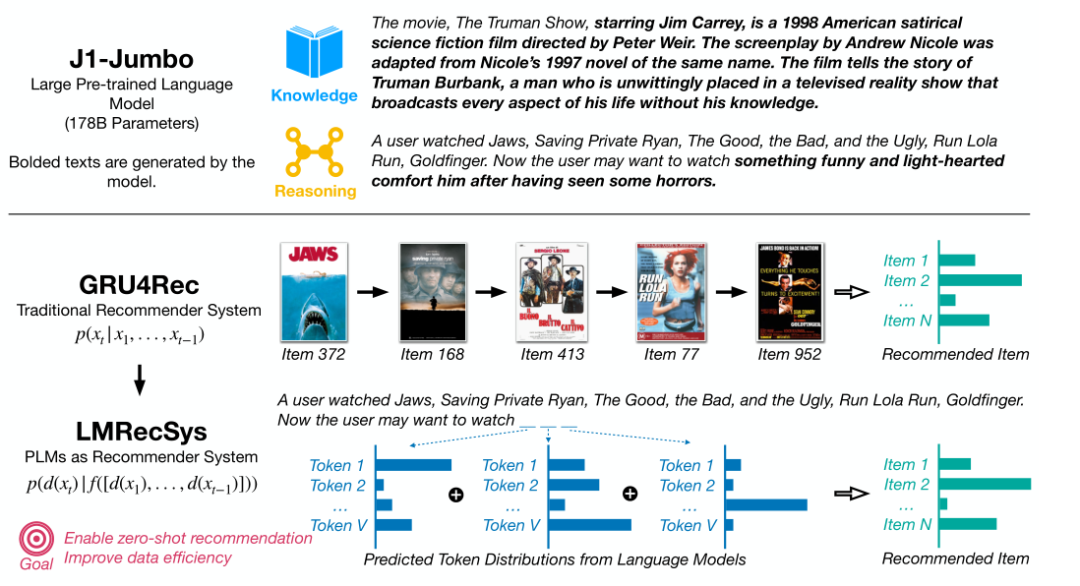
This article proposes to utilize pre-trained language models to solve recommendation tasks by rewriting them as language modeling tasks. Simply put, this article rewrites the user’s historical interaction sequence into a text description (for example: item sequence: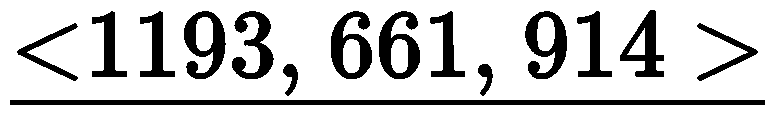 ,to text sequence: A user watched:
Now the user wants to watch ___ , where ___ is
,to text sequence: A user watched:
Now the user wants to watch ___ , where ___ is ), and utilizes the language model to fill in the blanks, thus solving the recommendation task.
The authors hope to use PLM to address two key issues in recommendation systems: Zero-shot Recommendations and Data Efficiency. For recommendation systems, the ability to make correct recommendations without training samples is crucial. Since PLM, due to its large parameters, stores a vast amount of knowledge, the authors believe that PLM can enhance the model’s performance in zero-shot scenarios. Additionally, the general knowledge learned during the pre-training phase can be adapted to numerous downstream tasks through methods such as adding prompts. Therefore, the authors believe that PLM can also be utilized as data-efficient recommender systems.
Specifically, given the user’s historical interaction sequence
), and utilizes the language model to fill in the blanks, thus solving the recommendation task.
The authors hope to use PLM to address two key issues in recommendation systems: Zero-shot Recommendations and Data Efficiency. For recommendation systems, the ability to make correct recommendations without training samples is crucial. Since PLM, due to its large parameters, stores a vast amount of knowledge, the authors believe that PLM can enhance the model’s performance in zero-shot scenarios. Additionally, the general knowledge learned during the pre-training phase can be adapted to numerous downstream tasks through methods such as adding prompts. Therefore, the authors believe that PLM can also be utilized as data-efficient recommender systems.
Specifically, given the user’s historical interaction sequence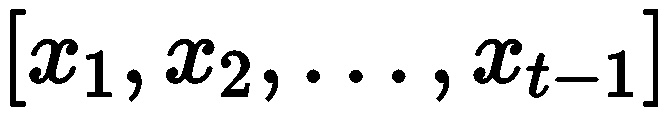 , all items are first mapped to their corresponding word descriptions
, all items are first mapped to their corresponding word descriptions 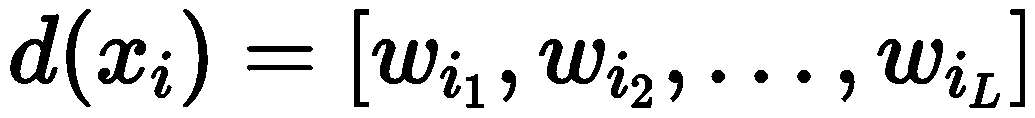 , and utilize prompts
, and utilize prompts 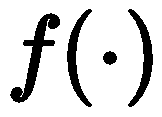 to convert the item sequence into a text sequence
to convert the item sequence into a text sequence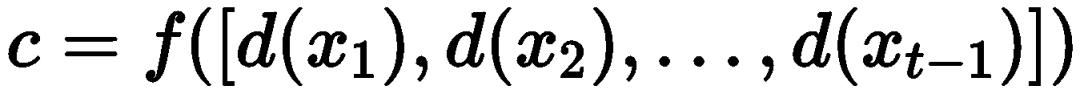 . Then, using multi-token inference, the language model estimates the probability distribution of the next item, i.e., aggregating the probability distributions of each token in the item descriptions:
. Then, using multi-token inference, the language model estimates the probability distribution of the next item, i.e., aggregating the probability distributions of each token in the item descriptions: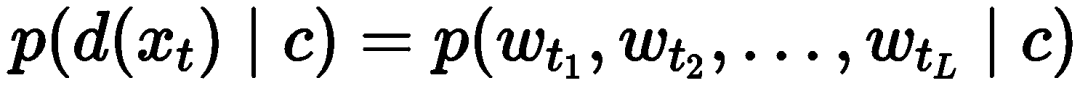 This can also be computed in two ways:
This can also be computed in two ways: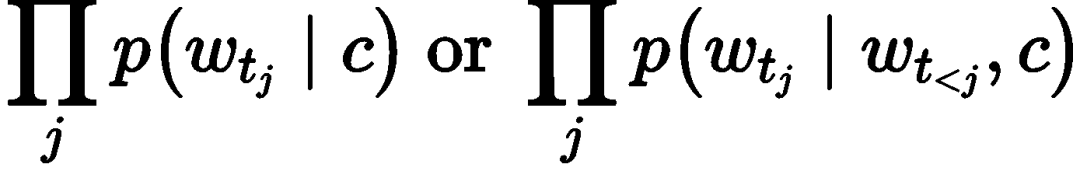 Experiments show that in zero-shot scenarios, the model’s performance is better than the random recommendation baseline, but there still exists a significant language bias, as the language model always attempts to predict some general tokens to make the generated sentences smoother, rather than predicting tokens more relevant to item descriptions. After fine-tuning, although the language bias has decreased compared to the zero-shot scenario and performance has significantly improved, it still lags behind traditional sequence recommendation models like GRU4Rec.
3. Personalized Prompt Learning for Explainable Recommendation
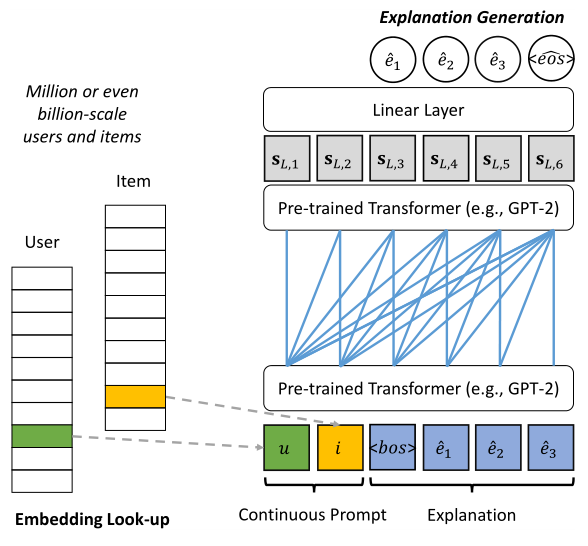
This article proposes that existing explainable recommendation works mostly use LSTM, GRU, or non-pre-trained Transformers to generate explanations, without utilizing powerful pre-trained language models. The authors believe that for recommendation systems, user and item IDs are obviously very important signals, but they do not exist in the same semantic space as the words in the pre-trained models. This presents a challenge in introducing pre-trained language models into explainable recommendations. To address this issue, inspired by prompt learning, this article proposes two solutions: discrete prompt learning and continuous prompt learning, and proposes two training strategies, sequential tuning and recommendation as regularization, to resolve the issue of continuous prompts and pre-trained models not being in the same semantic space.
To address the issue of IDs and language models not being in the same semantic space, a straightforward idea is to use some discrete tokens to represent IDs, such as certain features of items. These discrete words are used as prompts, which is referred to as discrete prompt learning.
Specifically, given a user u (or item i), we can obtain the features of all items related to it in the training set
Experiments show that in zero-shot scenarios, the model’s performance is better than the random recommendation baseline, but there still exists a significant language bias, as the language model always attempts to predict some general tokens to make the generated sentences smoother, rather than predicting tokens more relevant to item descriptions. After fine-tuning, although the language bias has decreased compared to the zero-shot scenario and performance has significantly improved, it still lags behind traditional sequence recommendation models like GRU4Rec.
3. Personalized Prompt Learning for Explainable Recommendation
This article proposes that existing explainable recommendation works mostly use LSTM, GRU, or non-pre-trained Transformers to generate explanations, without utilizing powerful pre-trained language models. The authors believe that for recommendation systems, user and item IDs are obviously very important signals, but they do not exist in the same semantic space as the words in the pre-trained models. This presents a challenge in introducing pre-trained language models into explainable recommendations. To address this issue, inspired by prompt learning, this article proposes two solutions: discrete prompt learning and continuous prompt learning, and proposes two training strategies, sequential tuning and recommendation as regularization, to resolve the issue of continuous prompts and pre-trained models not being in the same semantic space.
To address the issue of IDs and language models not being in the same semantic space, a straightforward idea is to use some discrete tokens to represent IDs, such as certain features of items. These discrete words are used as prompts, which is referred to as discrete prompt learning.
Specifically, given a user u (or item i), we can obtain the features of all items related to it in the training set . For each user-item pair, we can divide its features into two groups: user and item-related features
. For each user-item pair, we can divide its features into two groups: user and item-related features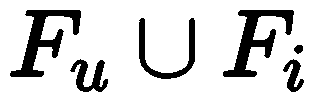 and other features
and other features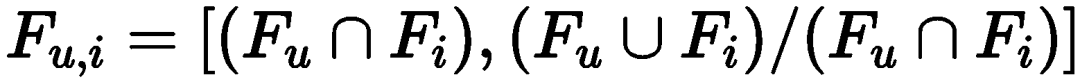 . Clearly, the former contains more information as it includes common features of both user and item. At this point, the discrete prompt is as follows:
The model’s input can be represented as
. Clearly, the former contains more information as it includes common features of both user and item. At this point, the discrete prompt is as follows:
The model’s input can be represented as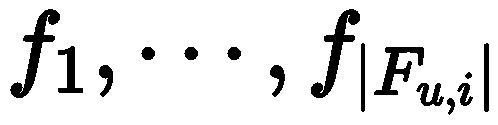 , where
, where 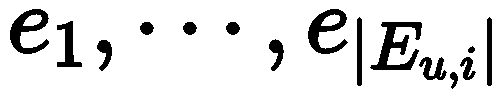 is the discrete prompt,
is the discrete prompt, 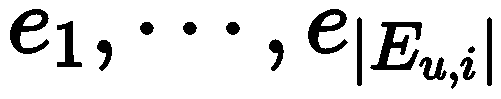 is the explanation to be generated.
The model is optimized through NLL loss, which is:
is the explanation to be generated.
The model is optimized through NLL loss, which is:
-
Continuous Prompt Learning
Although the idea of using discrete prompts is feasible, the conversion from ID to discrete feature words inevitably loses information. Considering that prompts do not have to be natural language, they can also be vectors or soft-prompts, this article proposes to directly use user and item embeddings as soft prompts, which is referred to as continuous prompt learning. However, these randomly initialized embeddings still do not exist in the same semantic space as the already trained pre-trained models. This article proposes two training strategies to address this issue:
1) Sequential Tuning Strategy:
First, freeze the parameters of the language model 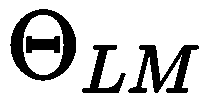 , and optimize the continuous prompts separately
, and optimize the continuous prompts separately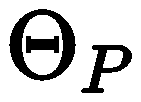 , when
, when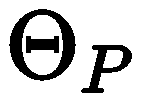 converges, then optimize both simultaneously
converges, then optimize both simultaneously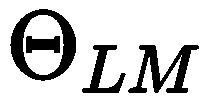 ,
, 2) Recommendation as Regularization
This article introduces the rating prediction task as a regularization term. The authors believe that ratings contain interaction information between users and items, thus can be used to learn better user and item representations.
By introducing these two learning strategies, continuous prompts can be aligned to the semantic space of the pre-trained model, thus enabling continuous prompt learning.
4. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
This article points out that different recommendation tasks often require designing task-specific model architectures and training objectives. Therefore, it is challenging to transfer knowledge and representations learned from one task to another, limiting the model’s generalization capability. However, different recommendation tasks often share the same user-item set and have common features. Therefore, the authors believe that a unified framework to integrate these recommendation tasks can transfer the implicit common knowledge between different tasks, enhancing the performance of each task and improving the model’s generalization ability.
2) Recommendation as Regularization
This article introduces the rating prediction task as a regularization term. The authors believe that ratings contain interaction information between users and items, thus can be used to learn better user and item representations.
By introducing these two learning strategies, continuous prompts can be aligned to the semantic space of the pre-trained model, thus enabling continuous prompt learning.
4. Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5)
This article points out that different recommendation tasks often require designing task-specific model architectures and training objectives. Therefore, it is challenging to transfer knowledge and representations learned from one task to another, limiting the model’s generalization capability. However, different recommendation tasks often share the same user-item set and have common features. Therefore, the authors believe that a unified framework to integrate these recommendation tasks can transfer the implicit common knowledge between different tasks, enhancing the performance of each task and improving the model’s generalization ability.
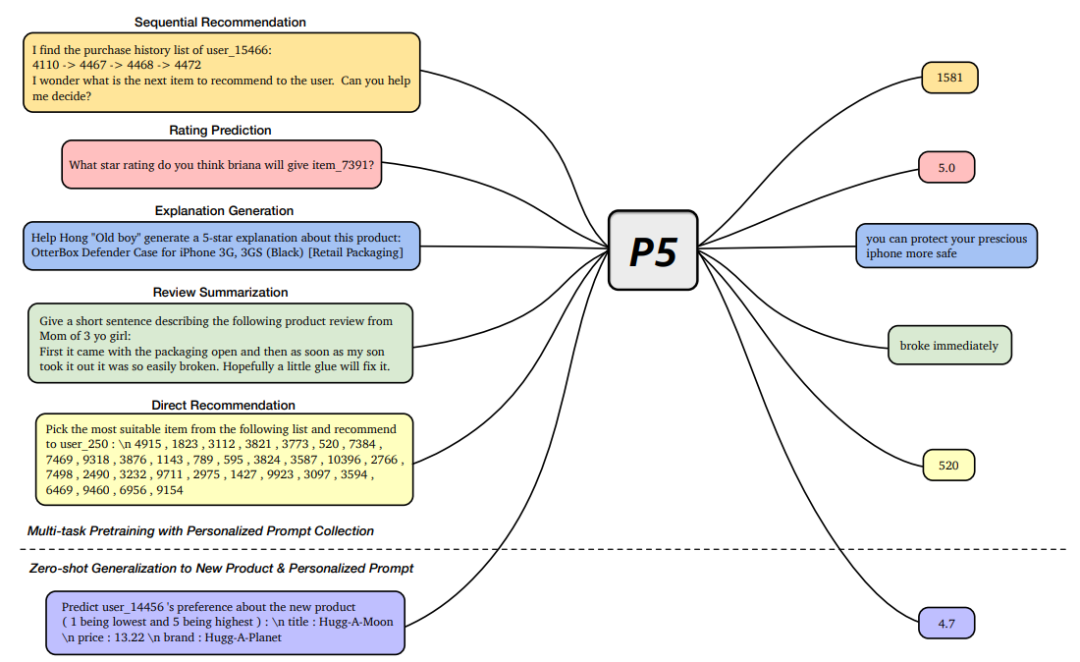 To solve these problems, considering that language can flexibly describe various tasks and issues, this article proposes a flexible and general text-to-text framework: Pretrain, Personalized Prompt, and Predict Paradigm (P5). By designing a series of personalized prompts covering different recommendation tasks and converting all data such as user-item interactions, product metadata, and user reviews into the same input-output text pair format, P5 can jointly learn different recommendation tasks in a sequence-to-sequence manner.
Under this general framework, P5 has the following advantages:
1. P5 utilizes personalized templates to convert all recommendation tasks into natural language processing tasks, benefiting from the flexibility of natural language, which can express various features in text templates. P5 does not require designing feature-related encoders, thus fully leveraging the rich semantics and knowledge embedded in the training corpus of different tasks.
2. P5 integrates various recommendation tasks into a unified text-to-text encoder-decoder architecture, treating different tasks as the same conditional text generation task. In this case, the same language model loss can be used to jointly train these tasks, eliminating the need to design task-specific structures and objective functions.
3. Thanks to the instruction-based prompts used during training, P5 can exhibit good zero-shot performance when generalizing to new personalized templates or unseen products.
This article designs different personalized prompts for different recommendation tasks, such as:
To solve these problems, considering that language can flexibly describe various tasks and issues, this article proposes a flexible and general text-to-text framework: Pretrain, Personalized Prompt, and Predict Paradigm (P5). By designing a series of personalized prompts covering different recommendation tasks and converting all data such as user-item interactions, product metadata, and user reviews into the same input-output text pair format, P5 can jointly learn different recommendation tasks in a sequence-to-sequence manner.
Under this general framework, P5 has the following advantages:
1. P5 utilizes personalized templates to convert all recommendation tasks into natural language processing tasks, benefiting from the flexibility of natural language, which can express various features in text templates. P5 does not require designing feature-related encoders, thus fully leveraging the rich semantics and knowledge embedded in the training corpus of different tasks.
2. P5 integrates various recommendation tasks into a unified text-to-text encoder-decoder architecture, treating different tasks as the same conditional text generation task. In this case, the same language model loss can be used to jointly train these tasks, eliminating the need to design task-specific structures and objective functions.
3. Thanks to the instruction-based prompts used during training, P5 can exhibit good zero-shot performance when generalizing to new personalized templates or unseen products.
This article designs different personalized prompts for different recommendation tasks, such as:
-
Rating prediction task: 1) Given user and product information, directly predict the corresponding rating. 2) Given user, product, and rating, predict whether the user will give this rating to the product. 3) Given user and product, predict whether the user likes the product.
-
Sequence recommendation task: 1) Given the user’s historical interaction sequence, directly predict the next product. For example: 2) Given the user’s historical interaction sequence and the candidate product set, predict the possible next product. 3) Given the user’s historical interaction sequence and product, predict whether the product will be interacted with.
-
Explanation generation task: 1) Given user and product information, directly generate explanation text. 2) Given a certain feature word as a prompt, generate explanation text.
-
Review-related tasks: 1) Review summarization. 2) Given a review, predict the relevant rating.
-
Direct recommendation tasks: 1) Predict whether to recommend the product to the user. 2) Select the most suitable product to recommend from the candidate product set.
The model uses the T5 pre-trained model, and the common optimization objective for various recommendation tasks during the pre-training phase is
Thus, various recommendation tasks can be jointly optimized byone model, one loss, one data format.
5. M6-Rec: Generative Pretrained Language Models are Open-Ended Recommender Systems
Similar to P5, this article focuses on how to design a unified foundational model based on pre-trained language models to address different tasks across various domains in recommendation systems.
This article points out that industrial recommendation systems are becoming increasingly complex, potentially involving different domains and tasks. However, current mainstream methods still design separate algorithms for each task. Therefore, the authors believe that building a unified foundational model that supports open domains and tasks is necessary. First, improvements on the foundational model can directly enhance all downstream domains and tasks. Secondly, such a pre-trained foundational model can reduce the demand for task-specific data, which is beneficial for handling data-sparse scenarios. Most importantly, it can significantly reduce the consumption of computational resources.
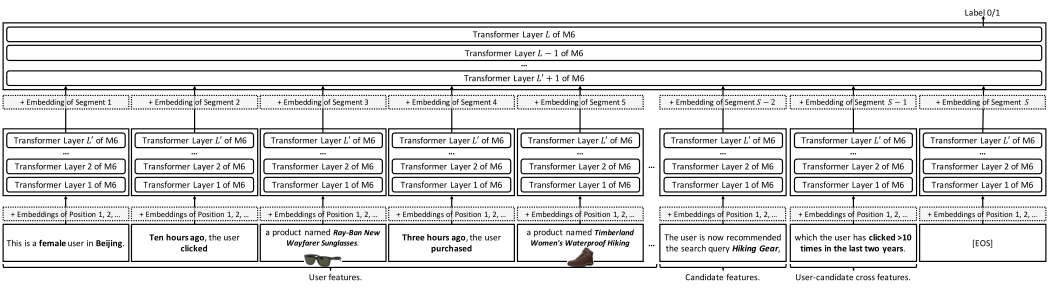
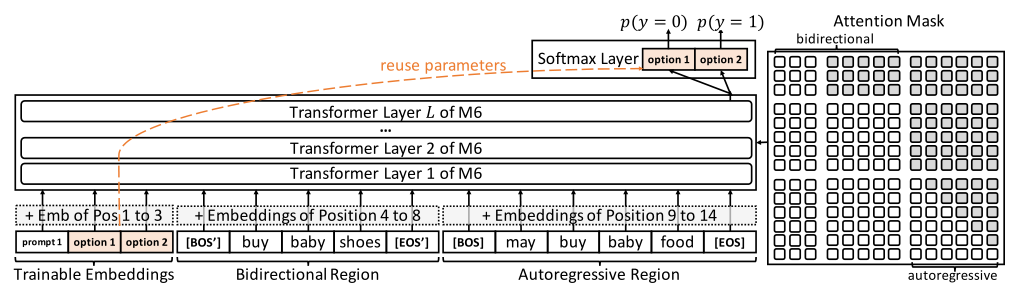 To this end, this article proposes M6-Rec based on the existing generative pre-trained language model M6, transforming the tasks in recommendation systems into language understanding or generation tasks that can be handled by language models. Specifically,M6-Rec converts user behavior data into plain text, for example: “A male user in Beijing, who clicked product X last night and product Y this noon, was recommended product Z and did not click it.”. Similarly, to achieve better generalization capability, M6-Rec does not use item IDs but uses item-related texts for representation. Different templates are designed for different downstream tasks:
[BOS′] and [EOS′] texts are used to describe user-related features and input into M6’s bidirectional encoding area. The texts in [BOS] and [EOS] are used to describe candidate product-related features and user-product interaction features and are input into M6’s autoregressive area. Subsequently, M6-Rec uses the last layer vector at the [EOS] position as the sample representation, optimizing the rating task by inputting this representation into the classifier.
[BOS′] . . . [EOS′] [BOS] The user now purchases a product of category “. . . ” named “. . . ”. Product details: . . . The user likes it because . . . [EOS]
1) For explanation generation tasks, during inference, add ‘because’ to the input text, and use the text generated by the model as the explanation for this recommendation.
2) For personalized product design tasks, the model is required to predict “a product of category __ named __” based on user attributes and historical interactions. This can be used to identify keywords that the user may be interested in.
User:[BOS′] . . . [EOS′] [BOS] [EOS]
Item: [BOS′] [EOS′] [BOS] . . . [EOS]
For the retrieval task, M6-Rec first inputs user-related information into [BOS′] and [EOS′], and uses the last layer representation at [EOS′] as the user vector; it inputs item-related information into [BOS] and [EOS], and uses the last layer representation at [EOS] as the item vector. By optimizing
To this end, this article proposes M6-Rec based on the existing generative pre-trained language model M6, transforming the tasks in recommendation systems into language understanding or generation tasks that can be handled by language models. Specifically,M6-Rec converts user behavior data into plain text, for example: “A male user in Beijing, who clicked product X last night and product Y this noon, was recommended product Z and did not click it.”. Similarly, to achieve better generalization capability, M6-Rec does not use item IDs but uses item-related texts for representation. Different templates are designed for different downstream tasks:
[BOS′] and [EOS′] texts are used to describe user-related features and input into M6’s bidirectional encoding area. The texts in [BOS] and [EOS] are used to describe candidate product-related features and user-product interaction features and are input into M6’s autoregressive area. Subsequently, M6-Rec uses the last layer vector at the [EOS] position as the sample representation, optimizing the rating task by inputting this representation into the classifier.
[BOS′] . . . [EOS′] [BOS] The user now purchases a product of category “. . . ” named “. . . ”. Product details: . . . The user likes it because . . . [EOS]
1) For explanation generation tasks, during inference, add ‘because’ to the input text, and use the text generated by the model as the explanation for this recommendation.
2) For personalized product design tasks, the model is required to predict “a product of category __ named __” based on user attributes and historical interactions. This can be used to identify keywords that the user may be interested in.
User:[BOS′] . . . [EOS′] [BOS] [EOS]
Item: [BOS′] [EOS′] [BOS] . . . [EOS]
For the retrieval task, M6-Rec first inputs user-related information into [BOS′] and [EOS′], and uses the last layer representation at [EOS′] as the user vector; it inputs item-related information into [BOS] and [EOS], and uses the last layer representation at [EOS] as the item vector. By optimizing
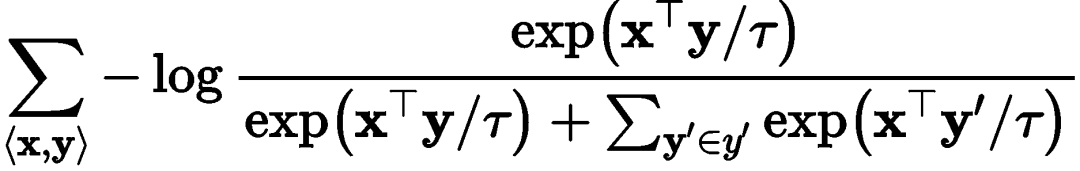 To reduce the inference latency of the recommendation system, this article proposes multi-segment late interaction based on late interaction. In simple terms, M6-Rec will precompute and cache the results of the first L’ layers of the Transformer, and when a user request arrives, it will compute the results of the last L-L’ layers in real-time. Notably, when computing the results of the first L’ layers, it does not compute on the complete input but divides these inputs into several segments and computes them separately. For example, when the input is “Male. Clicked X. Clicked Y. Will click Z?”, it will first segment into “Male. ”, “Clicked X. ”, ”Clicked Y. ”, and “Will click Z?”, and compute them separately, caching the results. When the input is “Female. Clicked Y. Will click Z?”, it can directly read the results of “Clicked Y. ” and “Will click Z?”.
This article provides a brief introduction to recent works that utilize pre-trained language models to solve recommendation tasks. From these articles, we can see that as large models continue to develop, the knowledge they store becomes more abundant, and their capabilities become increasingly powerful. By describing recommendation tasks as natural language processing tasks that can be modeled by language models, pre-trained language models can be effectively applied to the recommendation field to solve recommendation tasks. This also represents a further integration of natural language processing and recommendation systems.
To reduce the inference latency of the recommendation system, this article proposes multi-segment late interaction based on late interaction. In simple terms, M6-Rec will precompute and cache the results of the first L’ layers of the Transformer, and when a user request arrives, it will compute the results of the last L-L’ layers in real-time. Notably, when computing the results of the first L’ layers, it does not compute on the complete input but divides these inputs into several segments and computes them separately. For example, when the input is “Male. Clicked X. Clicked Y. Will click Z?”, it will first segment into “Male. ”, “Clicked X. ”, ”Clicked Y. ”, and “Will click Z?”, and compute them separately, caching the results. When the input is “Female. Clicked Y. Will click Z?”, it can directly read the results of “Clicked Y. ” and “Will click Z?”.
This article provides a brief introduction to recent works that utilize pre-trained language models to solve recommendation tasks. From these articles, we can see that as large models continue to develop, the knowledge they store becomes more abundant, and their capabilities become increasingly powerful. By describing recommendation tasks as natural language processing tasks that can be modeled by language models, pre-trained language models can be effectively applied to the recommendation field to solve recommendation tasks. This also represents a further integration of natural language processing and recommendation systems.
Technical Community Invitation

△Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(For example: Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join the Natural Language Processing/Pytorch and other technical groups
About Us
MLNLP Community is a grassroots academic community jointly built by machine learning and natural language processing scholars both domestically and internationally, and has developed into a well-known community for machine learning and natural language processing, including 10,000-person top conference exchange group, AI Selection Exchange, MLNLP Talent Exchange and AI Academic Exchange and other well-known brands, aimed at promoting progress between academia, industry, and enthusiasts in machine learning and natural language processing.
The community can provide an open communication platform for related practitioners’ further studies, employment, and research. Everyone is welcome to follow and join us.