Produced by Big Data Digest
Author: Caleb
Shanghai has not yet been unsealed.
On April 9, at a press conference on epidemic prevention and control work in Shanghai, Vice Mayor Zong Ming stated that since March 1, Shanghai has conducted multiple rounds of nucleic acid screening or antigen testing.
Since Shanghai announced comprehensive nucleic acid testing on April 4, as of 24:00 on April 8, approximately 95.27 million people have been screened, with over 94,400 confirmed positive cases among the completed samples.
Faced with such a large number of nucleic acid reports, manual verification is time-consuming and labor-intensive, and under high pressure, some errors are unavoidable. Is there a better way?
On April 7, according to reports from Fudan University, doctoral student Li Xiaokang used OCR and regular expressions to help the college verify hundreds of nucleic acid completion screenshots in just a few minutes, greatly improving verification efficiency and accuracy.
This topic has also sparked extensive discussion on Zhihu, with over 3 million views to date.

Using OCR and Regular Expressions for Epidemic Prevention
First, we need to briefly introduce OCR.
OCR, or Optical Character Recognition, is a method for automatic text input, also simply known as text recognition.
OCR mainly obtains image information of text on paper through optical input methods such as scanning and photography, and uses various pattern recognition algorithms to analyze text morphological features, converting receipts, newspapers, books, manuscripts, and other printed materials into image information. Then, text recognition technology is used to convert image information into usable computer input.
Li Xiaokang stated, “OCR can recognize text in images and convert it into text information, making verification much easier. Moreover, since nucleic acid screenshots use printed fonts, the recognition rate is very high, almost achieving 100% accuracy.”
There is a lot of text information in a screenshot, including desensitized names, document types, document numbers, sampling times, and organizations, but not all information is useful. Among them, name, sampling time, and whether sampling has been completed are the most critical and need to be filtered.
Based on this, Li Xiaokang thought of using regular expressions in Python. Regular expressions use a single string to describe and match a series of strings that conform to a certain syntactic rule, and are often used in many text editors to search for and replace text that matches a certain pattern.
“Using regular expressions allows us to filter out the information we want from the text recognized by OCR. Finally, after confirming the name, testing time, and whether sampling has been completed in each screenshot, we output the results of everyone to an Excel file for easy manual confirmation.”
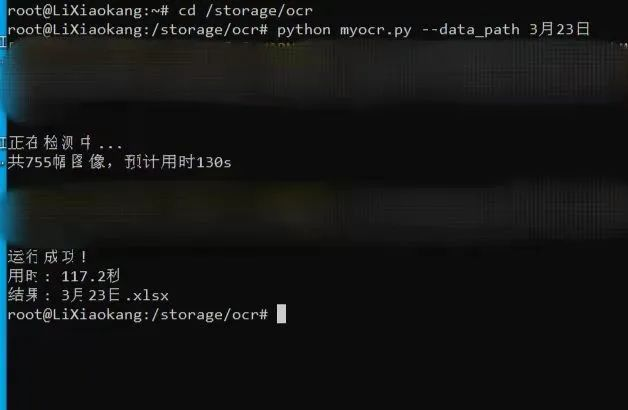
On the night of March 15, Li Xiaokang wrote the initial code in just over an hour, totaling 130 lines. He found that it indeed ran smoothly and was highly efficient. After validating it with his class’s nucleic acid screenshot data, he discovered that the program not only had a high accuracy rate and short running time, but also completed over 80 images in just over 20 seconds and identified issues that manual verification had missed.

800 Images in 2 Minutes, Program Encapsulated
Since early March, Fudan has initiated regular nucleic acid screening, and class counselors must verify, “missing no one.”
As a doctoral student in biomedical engineering, focusing on medical imaging and artificial intelligence, Li Xiaokang often encounters many image processing methods. He stated that the original intention of developing this program was to reduce the workload of himself and his colleagues.
“Although the principle is simple, anyone who knows how to code will understand it right away. However, those not involved in this work do not feel the time and effort it takes, and naturally won’t think of a solution. I just used what I learned to solve practical problems at work.”
After posting this on his social media, many colleagues in student affairs expressed great interest. He also shared the code so that interested teachers could use it in a timely manner.“Since the program is written in Python, the code comments are very complete, anyone who knows how to use Python can quickly get started.””
To make it easier for teachers who do not know programming to use, Li Xiaokang finally encapsulated the program. “When everyone needs it, they just need to type a line of code in the command line to run it, which is very simple.”
Currently, the program is already in service at the college. Li Xiaokang has let other teachers try using his program for verification. 800 screenshots, which used to require several people over an hour to verify, now only takes 2 minutes to get results.

Netizen: ThisAbility and Awareness to Identify and Solve Problems is Worthy of Recognition
Many netizens on Zhihu also expressed considerable admiration for this.
For example, Zhihu user @AimiBritni commented that this product itself is not particularly outstanding, but “this ability and awareness to identify and solve problems is something we should learn from.”
At the same time, many netizens contributed their own ideas regarding epidemic prevention and control.For instance, Zhihu user @第一大明白 wrote:
If epidemiological investigators had a professional application, they could scan the health codes of positive cases to automatically identify their personal information, while this program calls data from various systems such as public security, industry and information technology, and payment to generate a semi-finished action trajectory based on the data already held by various departments. This trajectory content would not be visible to the investigators, and then the application program would generate a form based on time, location, and other factors, allowing investigators to fill in information not in the big data by asking the positive cases, with locations automatically linked to standard place names in the national database, and then generate a preliminary epidemiological report with one click. Investigators would then complete the verification of the epidemiological information through the current verification methods to generate the final report.
Link:
https://www.zhihu.com/question/526681561/answer/2431023725
However, behind this, we still cannot ignore some basic facts. That is, after years of epidemic prevention, there is still no nationally unified open API interface for nucleic acid data, a small function that poses no technical difficulty yet has not been developed and provided by any health code system.
While epidemic prevention is indeed important, it is also necessary to think about how to integrate the process of informatization with epidemic prevention, allowing volunteers to engage in more meaningful work and service.