

Reprinted from: AI Park
Author: Sam Nolen
Translation: ronghuaiyang
Applicable in cases with very few samples.

Generative Adversarial Networks (GANs) were introduced by Ian Goodfellow in 2014 and have become a very active topic in machine learning research in recent years. A GAN is an unsupervised generative model that implicitly learns the underlying distribution. In the GAN framework, the learning process is a minimax game between two networks: a generator that generates synthetic data from a given random noise vector, and a discriminator that distinguishes between real data and synthetic data from the generator.
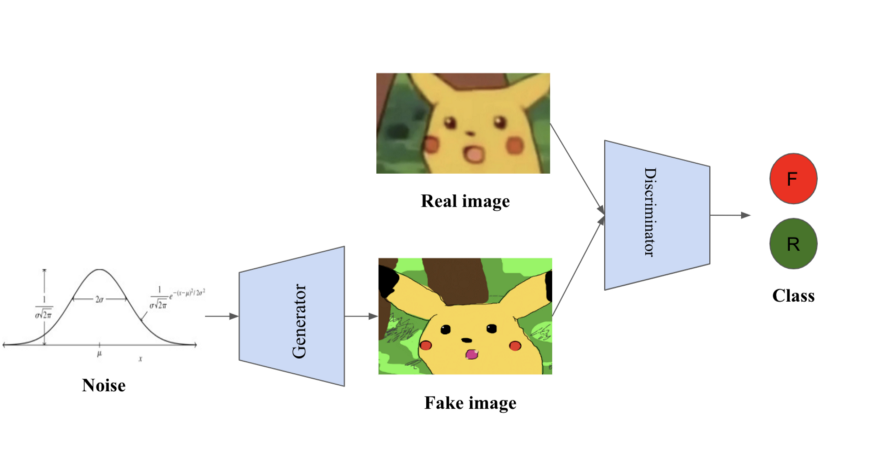

GANs have achieved remarkable results in many fields, especially in computer vision. In this article, we will explore a less glamorous but impactful use case of GANs, which is data augmentation to improve classifier performance in supervised learning.
Data Augmentation
Obtaining larger datasets is one of the most reliable ways to improve the performance of machine learning algorithms — to quote Andrew Ng, “the amount of data drives the machine learning process.” In some cases, adding generated or synthetic data (a process known as data augmentation) can also improve performance.
The most common approach is to apply some transformations to existing data. In the case of image classification, we know, for example, that moving or flipping an image of a cat still results in an image of a cat. Therefore, image classification datasets often augment with shifts, flips, rotations, or color changes to achieve the best possible results.

Here’s a question: Can we use GANs to generate synthetic data to improve classifiers? In a paper from April 2019: https://arxiv.org/pdf/1904.09135.pdf, the authors generated completely synthetic data for a binary classification problem (cancer detection). Remarkably, they showed that the decision tree classifier performed better on this completely synthetic dataset than when trained on the original small dataset.
However, this seems to be an exceptional case, as this direct data augmentation method works better on very small datasets. In a paper from 2017, the authors found that using direct data augmentation with GANs was not as effective as other augmentation strategies in image classification using deep learning.
Data Augmentation in Few-Shot Contexts
So let’s modify our question: What if we have a very small class as a subset of a larger dataset, like a rare dog breed in an image dataset? Or, if we are training a fraud classifier but only have a few known fraud examples and many non-fraud examples, what do we do? This situation is referred to as few-shot learning, which has proven to be a more promising use case for data augmentation using GANs. But to tackle this issue, we need to incorporate class information into the GAN model.
We can use conditional GANs to achieve this, where class information is provided to the generator. Now let’s discuss three variants of conditional GANs from the past two years.
ACGAN: Cooperate on Classification
A variant of conditional GAN, called ACGAN (Auxiliary Classifier GAN), not only distinguishes real data from synthetic data but also allows the discriminator to perform classification, with the loss function including a binary cross-entropy term for classification. In addition to learning to generate overall realistic samples, this also encourages the generator to learn representations of samples from different classes. This is essentially multi-task learning: while the generator and discriminator “compete” on whether the generated images are real or fake, they “cooperate” on correct classification.
DAGAN: Learn a Shared Family of Transformations for Data Augmentation
Another variant called DAGAN (Data Augmented GAN) learns how to generate synthetic images using low-dimensional representations of real images. In the DAGAN framework, the generator is not fed a class and a noise vector as input; instead, it essentially acts as an autoencoder: it encodes existing images, adds noise, and then decodes. Thus, the decoder learns a variety of data augmentation transformations.
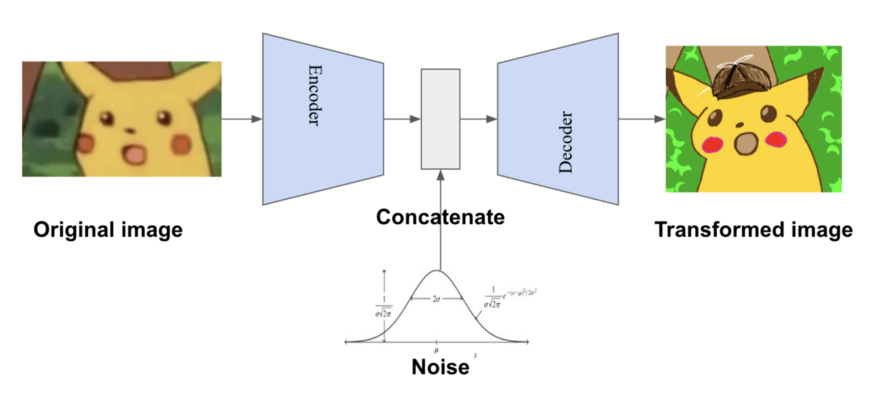
The DAGAN discriminator distinguishes between images and their transformed versions on one hand, and distinguishes pairs of images from the same class on the other. Thus, the discriminator incentivizes the decoder to learn transformations that do not change the class, but it is not easy to ensure that the transformed images are not too similar to the original images. However, a key assumption of DAGAN is that the same transformations apply to all classes — this is reasonable in a computer vision context but less so in fraud or anomaly detection.

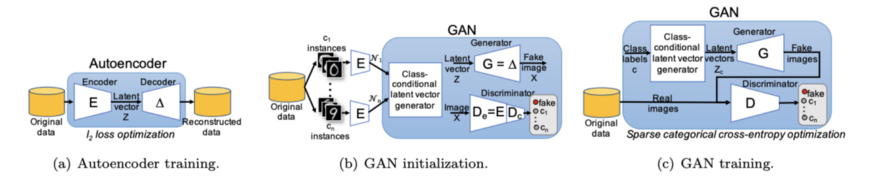
BAGAN: Learning to Balance Imbalanced Data
In another variant of conditional GAN called BAGAN, autoencoders are also used for the generator. The autoencoder is pre-trained to learn the distribution of the entire dataset. Then, the encoded images are fitted to a multivariate normal distribution. Now you can sample from these multivariate normal distributions and pass the conditional latent vector to the generator. Unlike DAGAN, BAGAN provides you with a mature conditional generator rather than transforming existing data. It may also perform better than ACGAN in few-shot contexts since VAEs have the ability to learn the overall distribution before fitting the normal distribution for each class.
Conclusion
Although using GANs for simple data augmentation can sometimes improve classifier performance, especially in very small or limited datasets, the most promising situations for augmenting with GANs seem to include transfer learning or few-shot learning. As research continues to improve the stability and reliability of GAN training, rapid progress in using GANs for data augmentation would not be surprising.
Original English text:https://medium.com/abacus-ai/gans-for-data-augmentation-21a69de6c60b
Download 1: Four Essentials
Reply "Four Essentials" in the background of the Machine Learning Algorithms and Natural Language Processing public account to get learning resources for TensorFlow, Pytorch, Machine Learning, and Deep Learning!
Download 2: Repository Address Sharing
Reply "Code" in the background of the Machine Learning Algorithms and Natural Language Processing public account to get access to 195 NAACL + 295 ACL2019 papers with open-source code. The open-source address is as follows: https://github.com/yizhen20133868/NLP-Conferences-Code
Exciting news! The Machine Learning Algorithms and Natural Language Processing exchange group has officially been established! There are numerous resources in the group, and everyone is welcome to join and learn!
Extra bonus resources! Deep Learning and Neural Networks, official Chinese tutorials for Pytorch, data analysis using Python, machine learning notes, Chinese version of pandas official documentation, Effective Java (Chinese version), and 20 other bonus resources.
How to obtain: After entering the group, click on the group announcement to receive the download link.
Note: Please modify your remarks when adding as [School/Company + Name + Direction].
For example —— Harbin Institute of Technology + Zhang San + Dialogue System.
Please avoid adding if you are a micro merchant. Thank you!
Recommended Reading:
Implementation of NCE-Loss in Tensorflow and word2vec
Overview of Multimodal Deep Learning: Network Structure Design and Modal Fusion Methods
Awesome Adversarial Machine Learning Resource List
Click the card below to follow the WeChat public account "Machine Learning Algorithms and Natural Language Processing" for more information: