

Source: New Intelligence
This article is about 4700 words long and is recommended to read in 10 minutes.
OpenAI's first AI video model, Sora, has made its debut, once again creating history. This technical report, which can be considered a "world model," was also released today, but specific training details remain undisclosed.

Recently, the phrase “reality no longer exists” has gone viral online.
“Have we really entered the next era so quickly? Sora is simply explosive.”

“This is the future of filmmaking!”

Google’s Gemini Pro 1.5 hasn’t even been out for a few hours, and by dawn, the spotlight of the world was focused on OpenAI’s Sora.
With the release of Sora, all video models bow down.

Just hours later, the technical report for OpenAI Sora was also released!
Among them, “milestone” has become a keyword in the report.

Report link: https://openai.com/research/video-generation-models-as-world-simulators
The technical report mainly covers two aspects:
(2) A qualitative evaluation of Sora’s capabilities and limitations.
However, unfortunately, the report does not include model and implementation details. Well, OpenAI is still the “OpenAI” we know.
Even Musk was shocked by Sora’s generated effects, stating “gg humanity”.
Creating a Virtual World Simulator
Previously, OpenAI researchers have been exploring a challenging question: how to apply large-scale training generative models to video data?
To this end, researchers trained videos and images with varying durations, resolutions, and aspect ratios, a process based on text-conditioned diffusion models.
They adopted the Transformer architecture, which can handle the latent codes of spatiotemporal segments in videos and images.
The resulting most powerful model, Sora, has the capability to generate high-quality videos lasting up to one minute.
OpenAI researchers discovered an exciting point: scaling up video generation models is a very promising direction for building a universal simulator of the physical world.
In other words, if developed in this direction, LLMs could indeed become world models!
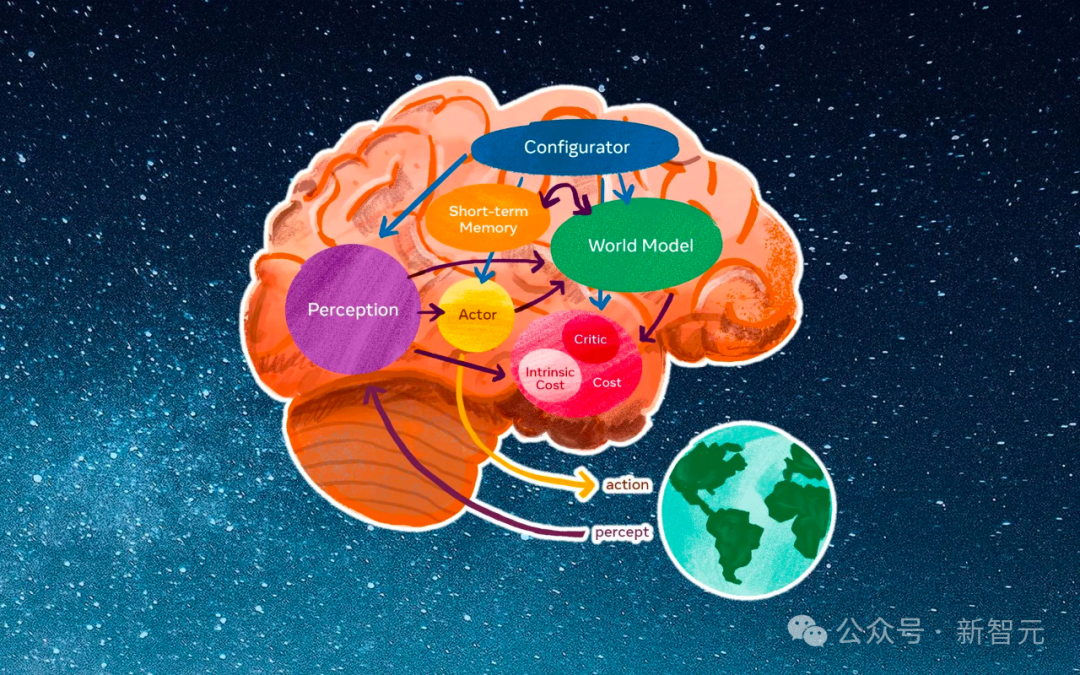
What makes Sora unique?
It is important to note that many previous studies modeled video data through various techniques, such as recurrent networks, generative adversarial networks, autoregressive Transformers, and diffusion models.
They often focused only on specific types of visual data, shorter videos, or videos of fixed sizes.
In contrast, Sora is a general visual data model capable of generating videos and images of various durations, aspect ratios, and resolutions, including high-definition videos lasting up to one minute.
Some netizens commented, “While Sora has some imperfections (which can be detected), such as its artificial synthesis being evident from physical effects, it will revolutionize many industries.
Imagine being able to generate dynamic, personalized advertising videos for precise targeting; this will be a trillion-dollar industry!”

To validate SORA’s effectiveness, industry leader Gabor Cselle compared it with Pika, RunwayML, and Stable Video.
First, he used the same prompt as in OpenAI’s example.
Results showed that other mainstream tools generated videos of only about 5 seconds, while Sora could maintain consistency in action and visuals over a scene lasting 17 seconds.

Subsequently, he used Sora’s starting frame as a reference, attempting to produce effects similar to Sora’s with other models by adjusting command prompts and controlling camera movements.
In contrast, Sora significantly outperformed in handling longer video scenes.

Seeing such stunning effects, it’s no wonder industry insiders are exclaiming that Sora indeed has revolutionary significance in the field of AI video production.
Transforming Visual Data into Patches
The success of LLMs is largely due to their training on internet-scale data, gaining extensive capabilities.
A key to their success is the use of tokens, allowing various forms of text—code, mathematical formulas, and various natural languages—to be elegantly unified.
OpenAI researchers found inspiration from this.
How can the generative model for visual data inherit the advantages of tokens?
Note that, unlike the text tokens used by LLMs, Sora uses visual patches.
Previous studies have shown that patches are very effective for modeling visual data.
OpenAI researchers were pleasantly surprised to find that this highly scalable and effective representation form is suitable for training generative models that can handle various types of videos and images.
From a macro perspective, researchers first compressed videos into a low-dimensional latent space, then decomposed this representation into spatiotemporal patches, achieving the conversion from video to patches.

Video Compression Network
Researchers developed a network to reduce the dimensionality of visual data.
This network can take raw video as input and output a latent representation that is compressed in both time and space.
Sora is trained in this compressed latent space, which is then used to generate videos.
Additionally, researchers designed a corresponding decoder model to convert the generated latent data back into pixel space.
Latent Space Patches
For a compressed input video, researchers extract a series of spatial patches to be used as tokens for the Transformer.
This scheme is also applicable to images, as images can be viewed as a single-frame video.
Based on the patch representation method, researchers enable Sora to handle videos and images of different resolutions, durations, and aspect ratios.
During inference, the size of the generated video can be controlled by appropriately arranging randomly initialized patches in a grid of suitable size.
Extending the Transformer
Thus, the video model Sora is a diffusion model; it can accept noisy patches (and conditional information, such as text prompts) as input and is trained to predict the original “clean” patches.
Importantly, Sora is a diffusion model based on the Transformer. Historically, Transformers have demonstrated excellent scalability across various fields, including language modeling, computer vision, and image generation.

Surprisingly, in this work, researchers found that the diffusion Transformer as a video model can also scale effectively.
The following image shows a comparison of video samples used during training with fixed seeds and inputs.
As training computational resources increase, sample quality significantly improves.

Diverse Video Output
Traditionally, image and video generation technologies often adjust videos to a standard size, such as 4 seconds, resolution 256×256.
However, OpenAI researchers found that training directly on the original sizes of videos brings numerous benefits.
Flexible Video Production
Sora can produce videos of various sizes, from widescreen 1920×1080 to vertical 1080×1920, everything is available.
This means Sora can create content that fits different screen ratios for various devices!
It can also quickly produce video prototypes at lower resolutions and then use the same model to create full-resolution videos.

Better Visual Performance
Experiments found that training directly on videos’ original aspect ratios significantly enhances the visual performance and composition of the videos.
Therefore, researchers compared Sora with another version of the model, which cropped all training videos to square, a common practice in generative model training.
In comparison, Sora’s generated videos (on the right) showed significant improvements in composition.

Deep Language Understanding
Training a text-to-video generation system requires a large number of videos equipped with text descriptions.
Researchers applied the re-labeling technique from DALL·E 3 to videos.
First, researchers trained a labeling model capable of generating detailed descriptions, which was then used to generate text descriptions for all videos in the training set.
They found that training with detailed video descriptions not only improved text accuracy but also enhanced overall video quality.
Similar to DALL·E 3, researchers also used GPT to convert users’ brief prompts into detailed descriptions, which were then input into the video model.
This way, Sora can generate high-quality, accurate videos based on specific user requirements.
Diverse Prompts for Images and Videos
Although the showcased cases are all demos of Sora converting text into video, its capabilities extend beyond that.
It can also accept other forms of input, such as images or videos.
This allows Sora to perform a range of image and video editing tasks, such as creating seamless looping videos, adding dynamics to static images, and extending the length of videos on the timeline, etc.
Bringing DALL·E Images to Life
Sora can accept an image and text prompt, then generate a video based on these inputs.
Below is a video generated by Sora based on DALL·E 2 and DALL·E 3 images.

A Shiba Inu wearing a beret and a black turtleneck.

An illustration of a family of five monsters, designed in a simple and bright flat design style. It includes a fluffy brown monster, a sleek black monster with antennas, a green spotted monster, and a small polka-dotted monster, all playing together in a cheerful scene.

A realistic photo of clouds with the word “SORA” written on it.

In an elegant old hall, a massive wave is about to crash down. Two surfers skillfully glide on the crest of the wave.
Flexible Expansion of Video Timeline
Sora can not only generate videos but also extend videos along the timeline, either forward or backward.
In the demos, all videos start from the same video segment and extend into the past on the timeline. Although the beginnings differ, they ultimately converge at the same ending.


Through this method, we can extend videos in both directions, creating a seamless looping video.

Image Generation Capability
Similarly, Sora also has the capability to generate images.
To achieve this, researchers arranged Gaussian noise patches in a spatial grid, with a time span of one frame.
The model can generate images of various sizes, with a maximum resolution of 2048×2048 pixels.

Left: A close-up photo of a lady in autumn, rich in detail, with a blurred background.
Right: A vibrant coral reef inhabited by colorful fish and marine creatures.

Left: A digital painting depicting a juvenile tiger under an apple tree, utilizing an exquisite matte painting style.
Right: A snow-covered mountain village, with cozy cottages and magnificent northern lights, the scene is delicate and realistic, shot with a 50mm f/1.2 lens.
Changing Video Styles and Environments
Using diffusion models, one can edit images and videos through text prompts.
Here, researchers applied a technique called SDEdit to Sora, enabling it to change the style and environment of videos without requiring any prior samples.

Seamless Connections Between Videos
Additionally, Sora can create smooth transitions between two different videos, even if the themes and scenes of the two videos are completely different.
In the following demo, the middle video achieves a smooth transition from the left video to the right video. One is a castle, and the other is a small house in the snow, blending into one scene very naturally.
Emergent Simulation Capabilities
As large-scale training progresses, the video model exhibits many exciting new capabilities.
Sora utilizes these capabilities to simulate certain characteristics of humans, animals, and natural environments without needing specific rules for 3D space, objects, etc.
The emergence of these capabilities is entirely due to the model’s scale expansion.
Realism in 3D Space
Sora can create videos with dynamic perspective changes, making the movement of characters and scene elements in three-dimensional space appear very natural.
For example, a couple strolling in snowy Tokyo; the generated video and real camera effects are nearly indistinguishable.

Another example shows Sora having a broader field of view, generating videos of mountain landscapes and people hiking, giving the feeling of a grand aerial shot.

Consistency in Video and Persistence of Objects
Maintaining continuity of scenes and objects over time during long video generation has always been a challenge.
Sora can handle this issue well, maintaining the presence of objects even when they are obscured or leave the frame.
In the example below, the spotted dog on the windowsill maintains its appearance consistently, even as multiple passersby walk by.

For instance, it can showcase the same character multiple times in a video while maintaining the character’s appearance throughout.
A cyber-style robot rotates around from front to back without any frame jumps.

Interaction with the World
Furthermore, Sora can simulate simple behaviors that affect the state of the world.
For example, a cherry blossom tree painted by an artist leaves lasting brush strokes on watercolor paper.

Or, when a person eats a hamburger, the bite marks are clearly visible, and Sora’s generation adheres to the rules of the physical world.

Simulation of the Digital World
Sora can not only simulate the real world but also the digital world, such as video games.
Taking “Minecraft” as an example, Sora can render the game world and dynamic changes in a highly realistic manner while controlling the player character.
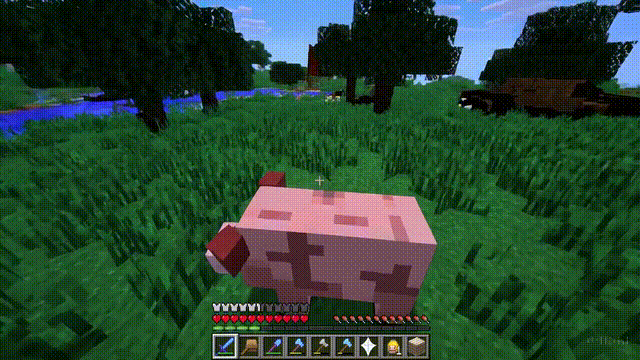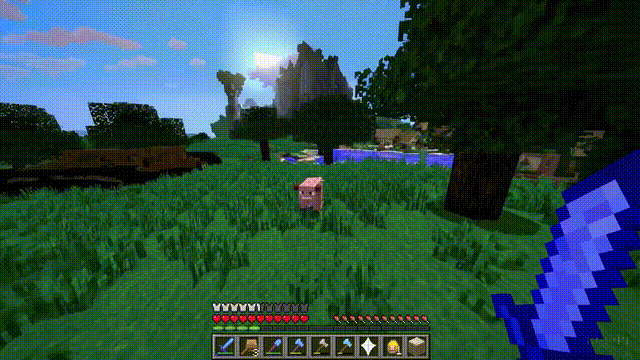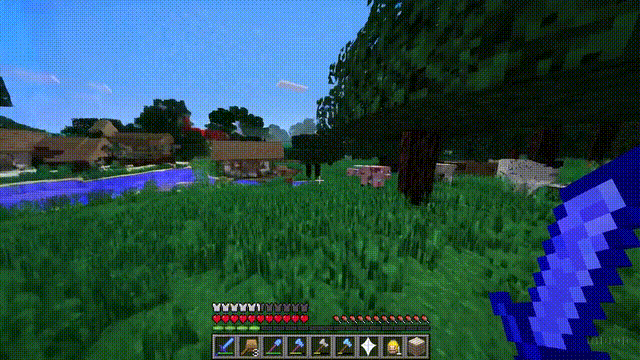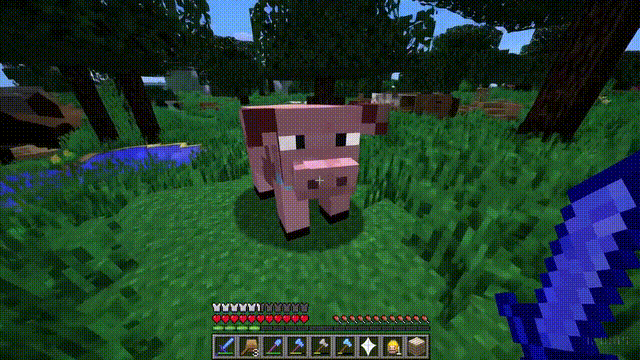
Moreover, simply mentioning “Minecraft” in a prompt allows Sora to exhibit these capabilities.
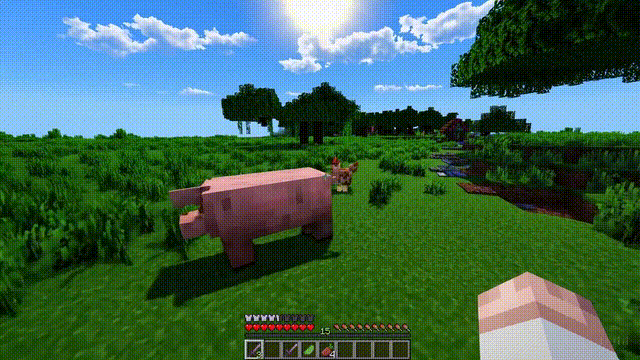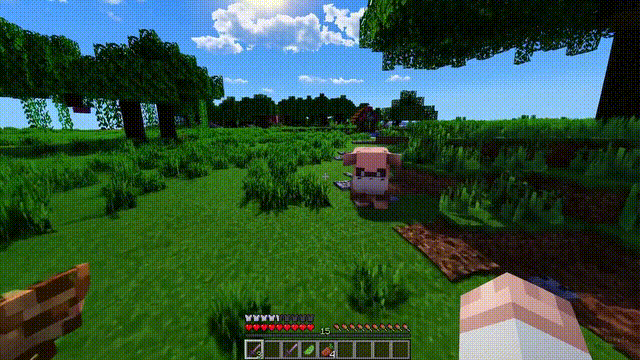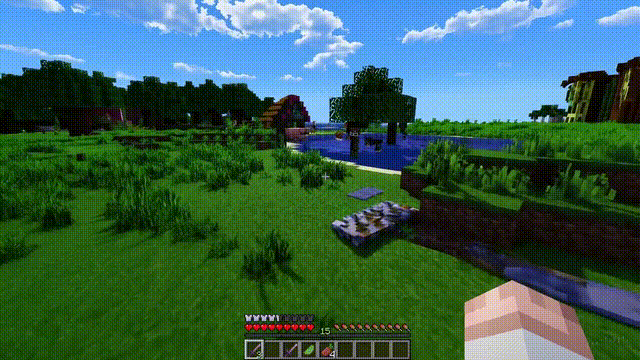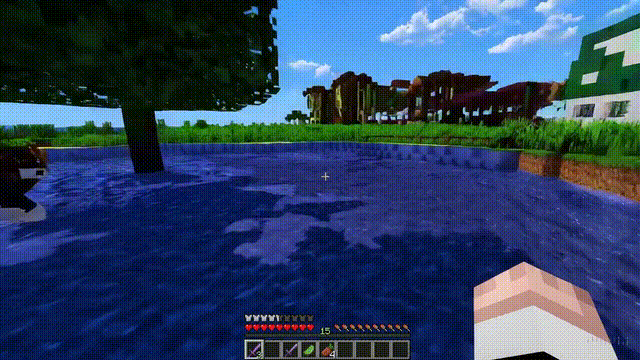
These new capabilities indicate that continuously expanding the scale of video models is a very promising direction, allowing models to develop into advanced simulators that accurately simulate the physical and digital worlds, as well as the organisms and objects within them.
Limitations
Of course, as a simulator, Sora currently has several limitations.
For instance, while it can simulate some basic physical interactions, such as the shattering of glass, it is not precise enough.

Simulating the process of eating food does not always accurately reflect changes in the state of objects.
On the website’s homepage, OpenAI lists common issues with the model, such as logical incoherence in long videos or objects appearing out of nowhere.

Finally, OpenAI states that the capabilities demonstrated by Sora prove that not only is enhancing the scale of video models an exciting direction.
Continuing down this path, perhaps one day, a world model will emerge.
Netizens: The Future of Gaming is Mouth-Based
OpenAI has provided numerous official demonstrations, indicating that Sora seems to pave the way for generating more realistic games—generating program games purely from text descriptions.
This is both exciting and frightening.
FutureHouseSF’s co-founder speculated, “Perhaps Sora can simulate my world. Maybe the next generation of gaming consoles will be the ‘Sora box,’ with games released in 2-3 segments of text.”
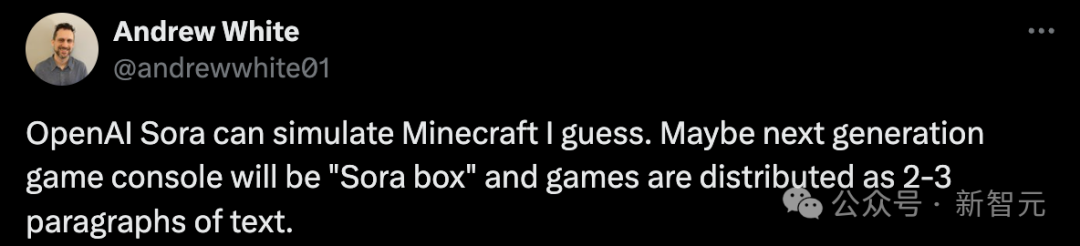
OpenAI technician Evan Morikawa stated, “In the Sora video released by OpenAI, the following video opened my eyes. Rendering this scene with a classic renderer is very difficult. Sora simulates physics in a way that is different from ours. It will definitely still make mistakes, but I did not predict it could do this realistically.”


Some netizens remarked, “People didn’t take the phrase ‘everyone will become a filmmaker’ seriously.”
I created this 1920s trailer in 15 minutes using clips from OpenAI Sora, David Attenborough’s voice from Eleven Labs, and sampled some natural music from YouTube in iMovie.


Others even expressed, “In 5 years, you will be able to generate fully immersive worlds and experience them in real-time; the ‘holographic deck’ is about to become a reality!”
Some people were completely stunned by the excellent effects of Sora’s AI video generation.
“It makes existing video models look like silly toys. Everyone will become a filmmaker.”

“The next generation of filmmakers is about to emerge with OpenAI’s Sora. In 10 years, it will be an interesting competition!”

“OpenAI’s Sora will not replace Hollywood for now. It will provide tremendous momentum for Hollywood as well as individual filmmakers and content creators.
Imagine, with just a 3-person team, completing a first draft of a 120-minute A-list feature film and audience testing within a week. That is our goal.”

Editor: Huang Jiyan
Proofreader: Yang Xuejun
