

Participants of the 1956 Dartmouth Conference. Left 2: Rochester, Left 3: Solomonoff, Left 4: Minsky, Right 2: McCarthy, Right 1: Shannon
Introduction:
The secret behind the success of OpenAI’s popular GPT series lies in next token prediction (essentially: predicting the next word), which is mathematically grounded in Solomonoff’s Induction.
This method is the theoretical cornerstone of large language models, revealing the core mechanism of GPT. As we celebrate the 60th anniversary of this theory, this article summarizes the significance of Solomonoff’s Induction and its unique contributions alongside other scholars. The article also explores the latest developments of this theory, its applications in the AI field, and its philosophical implications. Readers interested in AI should not miss it.

Solomonoff (July 25, 1926 – December 7, 2009)
Scientific development often involves a blend of theory and practice. The history of Natural Language Processing (NLP) is complicated, especially the development of large language models, which involves both theory and practice, influenced by commercial factors. Although engineers have attempted to find its mathematical foundations, true theoretical foundations are rarely discovered. In fact, mathematician Solomonoff laid the mathematical groundwork for large models as early as the 1960s, and his theories still hold guiding significance today.
In 1956, McCarthy and Minsky, supported by Shannon from Bell Labs and Rochester from IBM, held the summer workshop on artificial intelligence at Dartmouth College, marking the birth of artificial intelligence as an independent discipline. Solomonoff was the most serious participant at this conference, spending the entire summer at Dartmouth. His academic career was influenced by philosopher Carnap, focusing on inductive reasoning.
Pitts, the founder of neural networks, and pioneering AI researcher Simon also benefited from Carnap’s ideas. After meeting Minsky and McCarthy, Solomonoff began to focus on the study of logic and recursive functions. Recursive functions gradually evolved into computability theory, which in turn led to computational complexity. Minsky’s textbook on computational theory had a significant impact on the early development of computational theory, and his view that “AI spawned computational theory” holds some truth. In 1953, McCarthy and Minsky worked at Bell Labs, studying the foundations of Turing machines and intelligent activities around information theory expert Shannon. At that time, the older Wiener released his new book “Cybernetics,” but Shannon and McCarthy disagreed with it. McCarthy suggested to Shannon to publish a collection, inviting leading researchers of the time to write articles, which was published in 1956 as “Research on Automata.” McCarthy published a short piece in it discussing the inverse function problem of Turing machines, namely how to infer the input from the output of a Turing machine. McCarthy believed that all mathematical problems could be solved by inverting Turing machines. During the Dartmouth conference, McCarthy and Solomonoff had long discussions, where Solomonoff transformed McCarthy’s problem into the question of deriving subsequent sequences from a given initial segment. Initially, McCarthy did not understand this idea, but later recognized its importance. Their so-called “sequence continuation,” “next word,” or “next symbol” is now referred to as “next token.”

50th Anniversary of the Dartmouth Conference in 2006. Left 2: McCarthy, Left 3: Minsky, Right 1: Solomonoff
This saying originates from a 1913 article by French mathematician Borel, who considered whether a monkey randomly typing on a typewriter could produce “Hamlet,” pointing out that while the probability is low, it is not zero, known as the “Infinite Monkey Theorem.” Argentine writer Borges envisioned a perfect library in his works, containing all possible books. Today’s large model training also strives in this direction, attempting to exhaust all human knowledge. Borges’s starting point is rationalism, while the random monkey represents empiricism, but both can be unified by McCarthy’s inverse problem into the enumeration process of Turing machines. Turing’s 1948 article “Intelligent Machines” mentioned methods of machine learning and pointed out that all learning can be reduced to enumeration processes, but this process is non-terminating or non-computable.

After discussions with McCarthy, Solomonoff completed a memorandum on inductive reasoning titled “An Inductive Inference Machine” before the Dartmouth conference ended, dated August 14, 1956. He circulated this typed manuscript among the participants and sent an improved version to Simon at Carnegie Mellon University by the end of 1956.
Solomonoff’s work was first publicly presented at the 1960 “Brain Systems and Computers” conference, and in the same year, it was widely disseminated through reports by Zator Company and the US Air Force AFOSR. In 1961, Minsky mentioned this work in his article “Steps Toward Artificial Intelligence.” After further revisions, Solomonoff formally published it in 1964 under the title “Formal Theory of Inductive Inference” in the journal “Information and Control.” The article was too long and was split into two parts, with the first half discussing theory and the second half discussing examples.
Solomonoff’s Induction is defined as follows: Given a sequence (x1, x2, …, xn), predict xn+1. Inductive reasoning seeks the smallest Turing machine that models (x1, x2, …, xn) to accurately predict the subsequent sequence. The description length of the sequence corresponds to the size of the Turing machine, aligning with what McCarthy initially recognized as “effectiveness.” For example, the description length of the sequence (1, 1, 1, …) is O(log(n)).
Supervised learning can be viewed as a special case of self-supervised learning. Supervised learning gives sequence pairs (x1,c1), (x2,c2), …, (xn,cn) and xn+1 to predict cn+1. The learning process is to find the fitting function c=f(x). This type of problem can easily be transformed into self-supervised learning: Given the sequence (x1,c1,x2,c2,…,xn,cn,xn+1), predict cn+1.
McCarthy described this as the problem of “betting on the next character,” which is the core mechanism of large language models like GPT: next token prediction. A Turing machine summarizing known data is a large model. For the same dataset, the expectation is to minimize the parameters of the large model covering the dataset, i.e., to find the most economical Turing machine. Learning can be seen as compression, and the relationship between the number of parameters and the number of tokens can be studied accordingly. Solomonoff’s Induction may be non-terminating, thus using approximate algorithms relaxes the constraints on the “minimality” of Turing machines and the accuracy of predictions. He derived the prior probability distribution of sequences using Bayes’ theorem. Neural networks, as universal approximators, are good candidates for implementing Solomonoff’s Induction, which is also the approach taken by today’s large models. Solomonoff was interested in the problem of generating sentence syntax and was inspired by Chomsky to generalize grammar into probabilistic grammar. His “Inductive Inference Machine” can learn grammar from input text, which is known as “grammar discovery.” Chomsky’s innate grammar is similar to Solomonoff’s prior probability distribution, but their positions differ. According to the Church-Turing thesis, the distinction between the two is merely rhetorical. In Solomonoff’s prior probability distribution, the confidence of the program decreases exponentially with length, adhering to Occam’s razor principle. This is a wonderful formula:
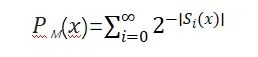
His life was not affluent; he spent most of his time doing government research at his consulting firm Oxbridge, which he ran alone. His academic autobiography, “The Discovery of Algorithmic Probability Theory,” was published in 1997 and has been revised multiple times. The latest edition is included in the collection “Randomness Through Computation: Some Answers, More Questions.”

Soviet mathematician Kolmogorov made profound contributions to traditional mathematics and significantly influenced computer science and information theory. In the 1950s, he keenly recognized the importance of information theory while being skeptical of cybernetics. Kolmogorov conducted in-depth research in probability theory, founded the quarterly journal “Problems of Information Transmission,” proposed a quantitative definition of information, and categorized it into frequency, combinatorial, and algorithmic foundations. He argued that information theory logically precedes probability theory, with algorithms being the most solid foundation. Kolmogorov’s complexity theory is defined as the length of the shortest program that generates a given object, and his articles are concise yet profound. Although some of his theories require further refinement by later scholars, his work remains of great significance. Kolmogorov complexity is considered more reliable than Shannon entropy because the Kolmogorov complexity of a graph is invariant, while structural entropy varies with different representations of the graph. Kolmogorov referenced Solomonoff’s work, enhancing the latter’s reputation in the Soviet Union beyond that in the West. Kolmogorov complexity is also known as Solomonoff complexity or Solomonoff-Kolmogorov-Chaitin complexity; to avoid ambiguity, this article uses the term “Kolmogorov complexity.” Influenced by Kolmogorov, this discipline is also referred to as algorithmic probability theory or algorithmic information theory. At Royal Holloway, University of London, Soviet scholars established a machine learning research center and created the Kolmogorov Medal, with Solomonoff as the first recipient, and the most recent recipient being Vladimir Vapnik. Solomonoff also served as a part-time professor at the college.


Solomonoff (left) with Chaitin, 2003
Greg Chaitin (1947-), a Jewish-American theoretical computer scientist born in Argentina, showed exceptional talent in high school, publishing articles on automata clock synchronization. He returned to Argentina with his parents before graduating from college and found a programming job at an IBM subsidiary, researching Gödel’s incompleteness theorem. At the age of 19, he independently reinvented the ideas of Solomonoff’s Induction and Kolmogorov information content, publishing them in the journal of the American Mathematical Society.
Chaitin’s research was based on Berry’s paradox, and he used the LISP functional programming language to avoid confusion. He proved that Kolmogorov complexity is non-computable, calling it “incompleteness.” In 1974, Chaitin returned to the United States and worked at IBM’s TJ Watson Research Center, where he presented a version of the incompleteness theorem derived from Berry’s paradox to Gödel. Although Gödel did not care much about it, Chaitin still believed his proof provided a new information-theoretic perspective on incompleteness. Chaitin sent his article in IEEE Transactions on Information Theory to Gödel and arranged a meeting, but due to Gödel’s poor health and fear of snow, the meeting was canceled, which Chaitin deeply regretted. In 1991, he was invited to speak at the University of Vienna and was praised as “more Gödel than Gödel.” In his later years, Chaitin developed a strong interest in biology, publishing popular science works like “Proving Darwin,” expressing dissatisfaction with the lack of theoretical foundations in biology and proposing to explain evolution using algorithmic information theory, termed “meta-biology,” with ideas traceable to genetic algorithms and programming.

Soviet mathematician Leonid Levin independently proposed NP-completeness in 1972 and proved several equivalent problems, with his article published in the journal founded by Kolmogorov. Although he did not receive a doctoral degree due to political issues, he later obtained a PhD from MIT and taught at Boston University until retirement. His contributions are widely recognized, and the Cook theorem in computational theory textbooks has been renamed the Cook-Levin theorem. In 2012, he received the Gödel Prize for considering the impact on the entire discipline.
Levin’s articles are usually very brief, and his algorithmic average complexity analysis he initiated in 1986 is only two pages long. Although Levin tends to believe that P=NP, this is a minority view in academia.
In a 1973 article, Levin presented two theorems, with Theorem 1 concerning NP-completeness and Theorem 2 being overlooked at the time. Theorem 1 was not detailed, and Theorem 2 was not even stated. Levin proposed a universal search process related to McCarthy’s problem, on which Solomonoff had already conducted 20 years of research.
Upon learning of Levin’s situation in the Soviet Union, Solomonoff reached out to American schools and scholars to assist Levin. He wrote a report on his academic discussions with Levin, completing the proof of Theorem 2 for Levin-1973 and referred to Levin’s universal search process as L-search.
Levin’s L-search adds a time constraint based on Kolmogorov complexity, defined as follows:
Kt(x) = min{ℓ(p) + log(time(p)): U(p) = x}
Thus, Levin’s complexity is computable, meaning that if the inverse function exists, it can always be found through Levin’s universal search process. This aligns with Solomonoff’s earlier convergence theorem.

The second page of Levin’s 1973 article. Acknowledgments precede the references, and the statement of Theorem 2 comes right after the acknowledgments.

Physicist Charles Bennett (1943-) is famous for quantum computing and is the first B in the quantum key distribution protocol BB84. He has made outstanding contributions to algorithmic information theory, introducing the concept of logical depth in 1988 (see Bennett-1988), defined as follows:
LD(x) = min{T(p): ℓ(p) =p*+s ∧U(p) = x}
which is the time required for the near-shortest program to output x. Here, p* is Kolmogorov complexity, and ℓ(p) is the length of the near-shortest program. It can be seen that logical depth further relaxes the requirement for the shortest length of programs in Kolmogorov complexity.
If we consider induction as compression, logical depth concerns the time of decompression. Logical depth allows us to consider the relationship between time and space. Intuitively, we might think that time is more “expensive” than space, but currently, in computational theory, we do not know whether the class P of polynomial time equals the class PSPACE of polynomial space; of course, NP is a subset of PSPACE, but it is unknown whether it is a proper subset. If P≠PSPACE, there must exist strings computable in PSPACE with logical depth greater than polynomial. Compression primarily considers space costs, while decompression incurs time costs.
The compression time of large models is the training time, Kolmogorov complexity represents the number of parameters, and logical depth corresponds to the shortest “inference” time. The term “inference” is more appropriate here, as it is statistical in nature, differing from the logical sense of “reasoning.” Large models also have logical “reasoning” aspects, such as CoT, but textbooks on machine theorem proving often do not distinguish between inference and reasoning. If the logical and statistical factions of artificial intelligence spoke Chinese, they might not argue.


Li Ming and his wife with Solomonoff
Theoretical computer scientists Li Ming and others have made significant contributions to the study of Solomonoff-Kolmogorov-Chaitin complexity. Their co-authored book “Kolmogorov Complexity and Its Applications” is an authoritative reference in this field, now in its 4th edition. Marcus Hutter transitioned from theoretical physics to general artificial intelligence, proposing the AGI theoretical framework AIXI based on reinforcement learning, with Solomonoff’s Induction as its mathematical tool.
The success of OpenAI’s ChatGPT is often attributed to the underlying neural network architecture Transformer, but the next token prediction (Solomonoff Induction) may be the key to its success. Currently, theoretical research in large models lags behind engineering practice. The Solomonoff-Kolmogorov-Chaitin theory suggests that learning can be viewed as compression, using streamlined systems to summarize data or a process from particular instances to generalities. The Hutter Prize established by Hutter rewards the best lossless compression work, and his article “Language Modeling is Compression” indicates that large language models outperform Huffman coding-based compression algorithms in lossless compression effectiveness.
Kolmogorov and Chaitin’s starting points are information expression and information transmission, which are also compression. These perspectives have sparked enthusiastic discussions among engineers, providing a new perspective for the development of large language models.

Solomonoff Induction is described as follows:
-
Input observation data.
-
Propose a new hypothesis (Turing machine) to explain the data.
-
Input new data to test the hypothesis.
-
If the data falsifies the hypothesis, return to step 2.
-
If the data confirms the hypothesis, continue to accept the hypothesis and return to step 3.
This method is similar to Peirce’s pragmatism, emphasizing discovering the unknown from the known. Peirce believed that rationalism and empiricism are not entirely opposed; when a new hypothesis is established and begins to explain a large amount of data, the system behaves more like a rationalist; when new data falsifies old hypotheses, the system behaves more like an empiricist.
Solomonoff Induction can also explain Popper’s falsifiability theory. He argued that falsification is easier than confirmation since it is generally easier to say something is wrong than to say something is right. This is akin to Peirce’s concept of “falsifiability.” Additionally, statistician George Box stated that all models are wrong, but some are useful for prediction.
Kuhn’s theory of scientific revolutions is also a special case of Solomonoff Induction. Occam’s razor principle states that among competing hypotheses, the one with the fewest assumptions should be selected. In Solomonoff’s theory, the minimal model covering all data is the shortest program or Turing machine. A scientific revolution occurs when the differences between old and new models are significant. The new model may be more complex and deeper logically than the old model.
Finally, Solomonoff Induction can explain theories about consciousness.

Aristotle pointed out in “Metaphysics” that “the pursuit of knowledge is human nature.” He described the process of human knowledge from experience to technology and then to science. Regarding the concepts of “non-computability” or “non-termination,” perhaps they symbolize the hope left by God for humanity. Within Solomonoff’s theoretical framework, the progress of knowledge is viewed as “incremental learning.” In-depth research on Solomonoff Induction and Kolmogorov complexity is expected to provide a new theoretical foundation for machine learning. Currently, genetic algorithms, genetic programming, and reinforcement learning can all find computational theoretical support within the framework of Solomonoff Induction.
Aristotle’s perspective can also be repurposed as “compression is human nature.” Hume argued that while induction cannot be confirmed, it is crucial to human nature. Under this view, compression can be seen as the essence of humanity. Experience originates from sensation, and modeling experience data arises from economic considerations, and modeling itself is compression, a process accomplished by Turing machines. In this sense, Solomonoff Induction can serve as a first principle. The evolutionary process can also be seen as compression, with survival of the fittest interpretable as “most compressive survival.” Compression reflects the laws of the physical world manifesting in the information world. Descartes’ “I think, therefore I am” can be strictly expressed as “I compress, therefore I am.”