

Introduction
AI art generation has started to enter the public eye. In the past year, a large number of text-to-image models have emerged, especially with the advent of Stable Diffusion and Midjourney, sparking a wave of AI art creation. Many artists have also begun to experiment with AI to assist in their artistic endeavors. This article will systematically review the text-to-image algorithms that have appeared in recent years, helping readers gain a deeper understanding of the principles behind them.
To explore the intersection of complex science and humanistic art, the Collective Intelligence Club is hosting the “Complex Science and Art” seminar series, gathering actors and thinkers from various fields—including scientists, artists, scholars, and related practitioners—to engage in interdisciplinary discussions and collaborative outputs. The seminar series began in July 2022 and will run monthly for a total of twelve sessions. AI-generated art is one of the themes of the seminar. Friends interested in this topic are welcome to sign up. Details and registration links can be found at the end of this article.

Hu Pengbo | Author
Zhu Sijia | Typesetting
Shisanwei | Proofreading
Table of Contents
Table of Contents
-
Based on VQ-VAE
-
AE
-
VAE
-
VQ-VAE
-
DALL-E
Based on GAN
-
VQGAN
-
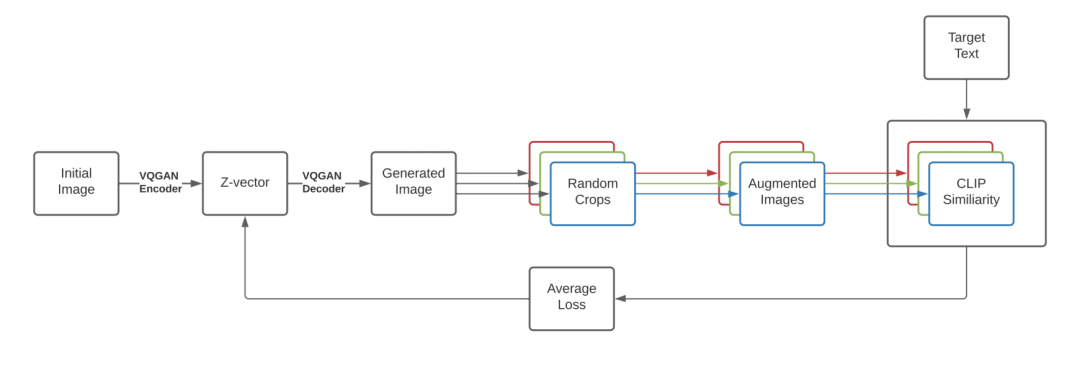
VQGAN-CLIP
-
DALL-E Mini
-
Parti
-
NUWA-Infinity
Based on Diffusion Model
-
Diffusion Model
-
GLIDE
-
DALL-E2
-
Imagen
-
Stable Diffusion
Model Trials
Summary
Based on VQ-VAE
Based on VQ-VAE
AE
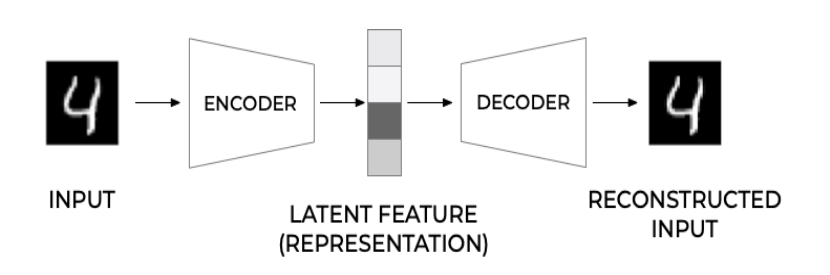
Autoencoders consist of an encoder and a decoder (as shown in the figure below)[1]. They first compress the image and then reconstruct the compressed representation. In practical applications, autoencoders are often used for dimensionality reduction, denoising, anomaly detection, or neural style transfer.
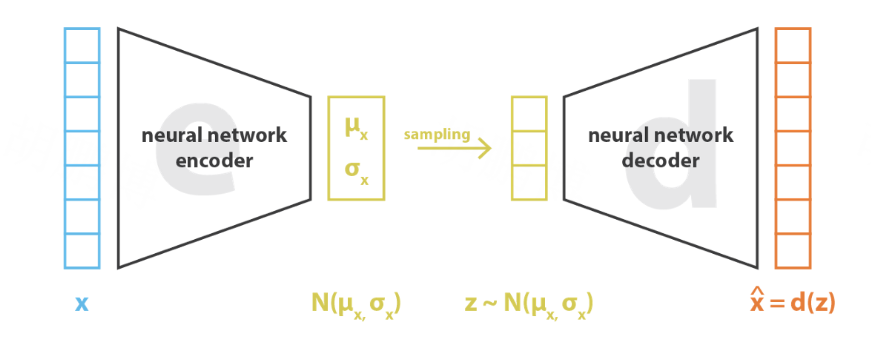
-
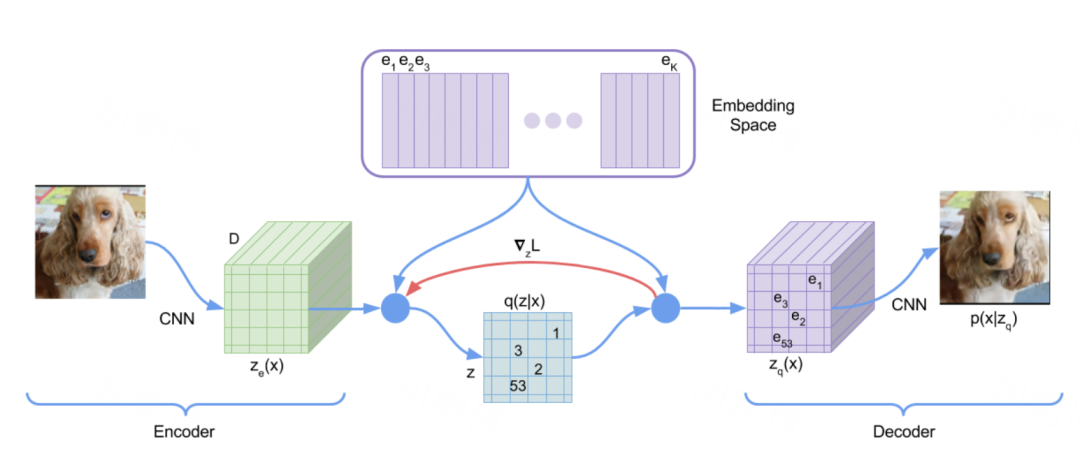
First, set K vectors as a queryable Codebook. -
The input image is passed through the encoder CNN to obtain N intermediate representations, and then, using the nearest neighbor algorithm, query the vectors in the Codebook that are most similar to these N intermediate representations. -
Place the queried similar vectors from the Codebook in the corresponding positions to obtain . -
The decoder reconstructs the image using the obtained intermediate representations .


-
Train a dVAE (referred to as dVAE in the article, which is actually a VQ-VAE, and will not be discussed further here), where the number of Codebook entries is 8192. -
Train an autoregressive model, here using a Transformer, to predict the intermediate representation from the input text.
Based on GAN
Based on GAN
-
Initialize a generator and a discriminator . -
Fix the parameters of the generator and only update the parameters of the discriminator . The specific process involves selecting a portion of real samples and generating some samples from the generator, feeding them into the discriminator , which must determine which samples are real and which are generated, optimizing the discriminator based on the error with the real results. -
Fix the parameters of the discriminator , only updating the parameters of the generator . The specific process involves using the generator to produce a portion of samples, feeding the generated samples into the discriminator , which will judge them, optimizing the generator’s parameters so that the discriminator leans towards judging them as real samples.
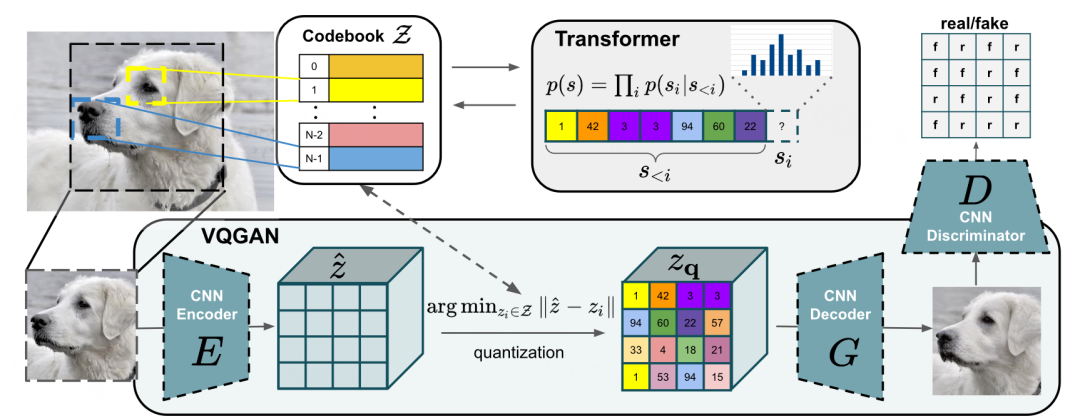
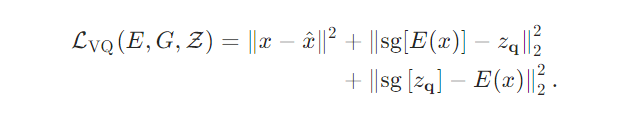
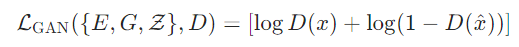
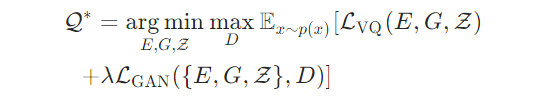

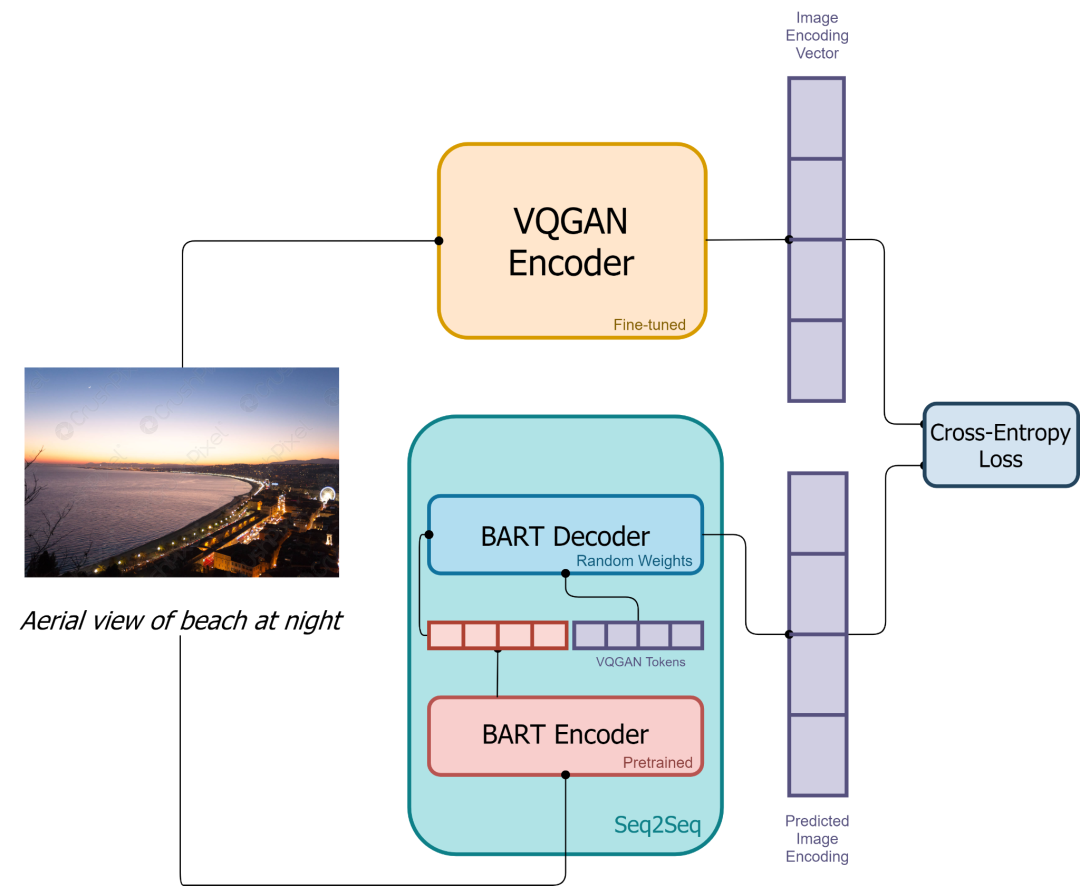
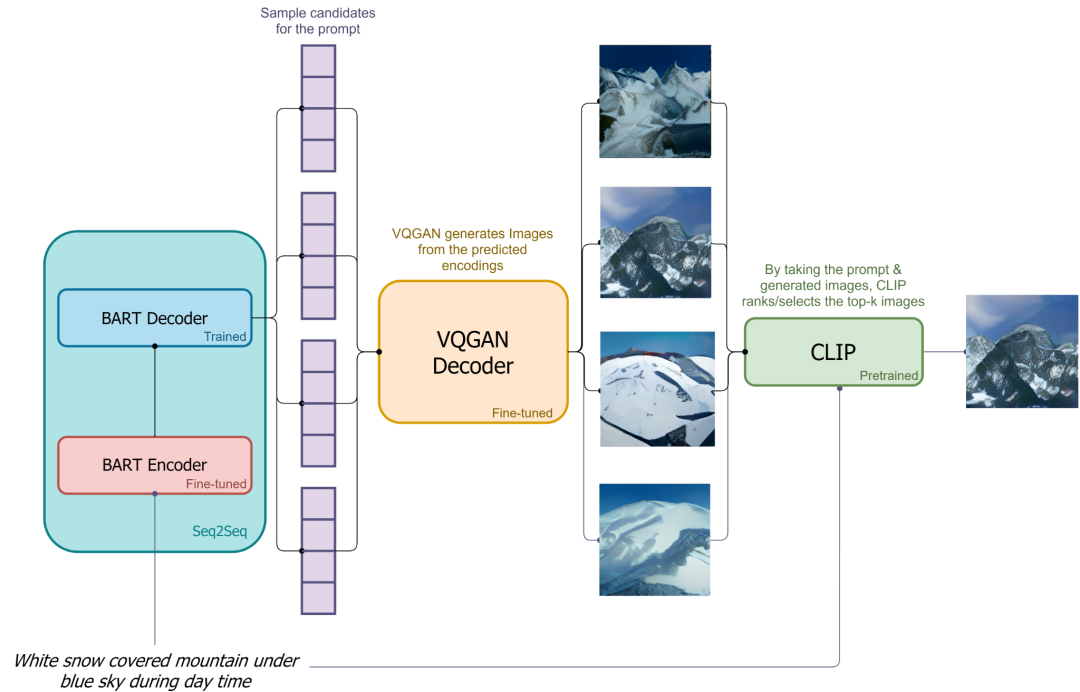

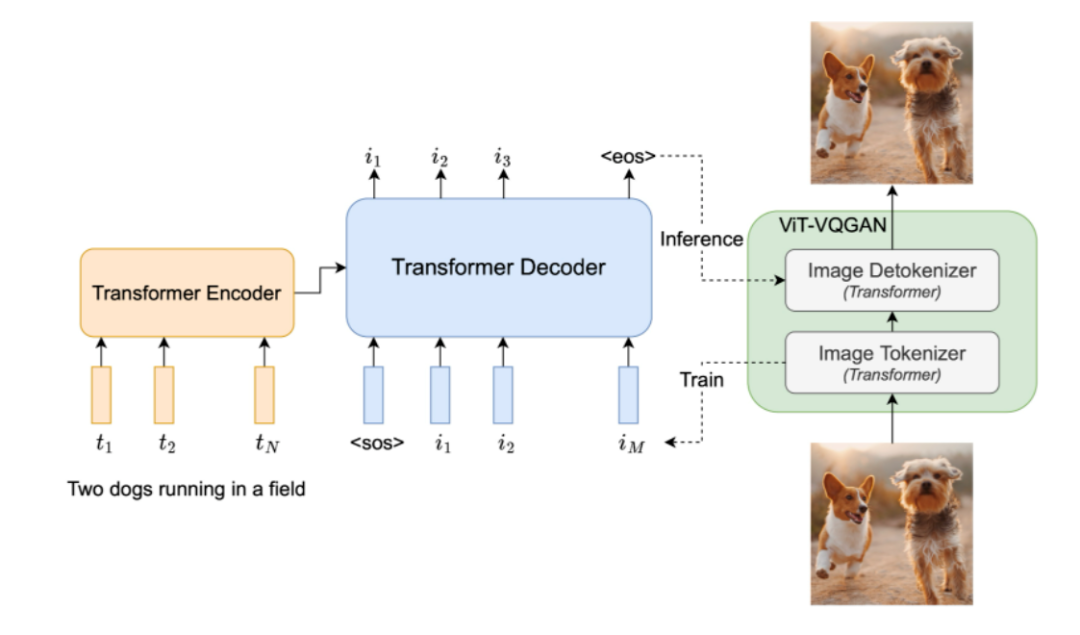


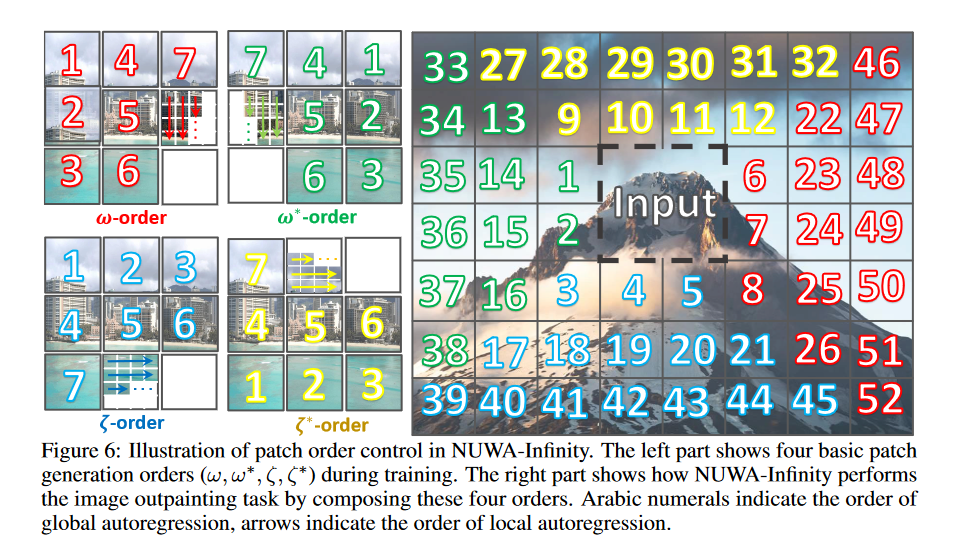

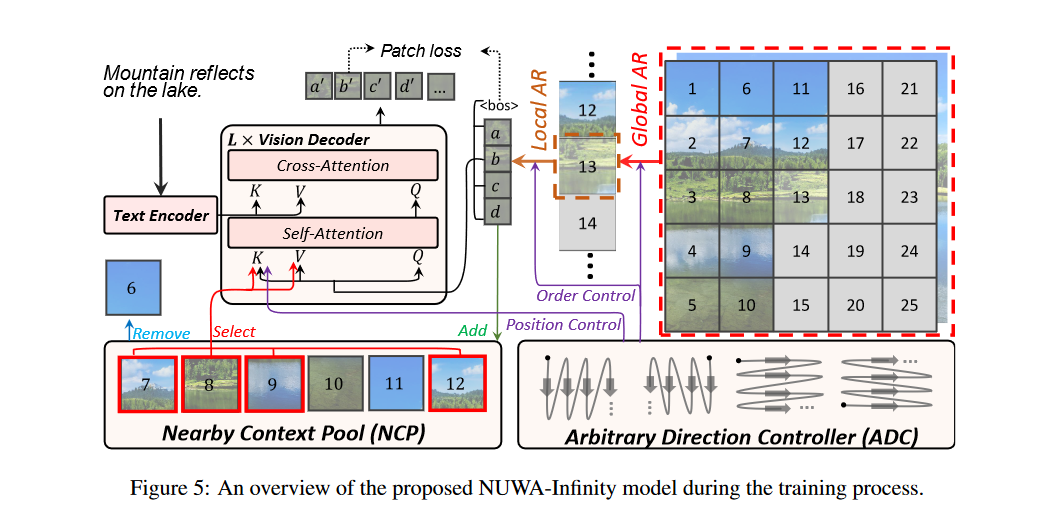
Based on Diffusion Model
Based on Diffusion Model
Unlike VQ-VAE and VQ-GAN, diffusion models are currently the core method in the field of text-to-image generation. The most well-known and popular text-to-image models, such as Stable Diffusion, Disco-Diffusion, Mid-Journey, and DALL-E2, are all based on diffusion models. This section will provide a detailed introduction to the principles of diffusion models and the algorithms based on them.

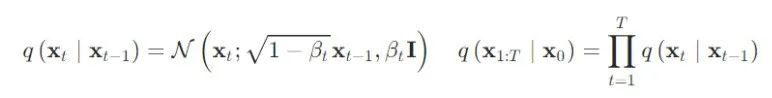
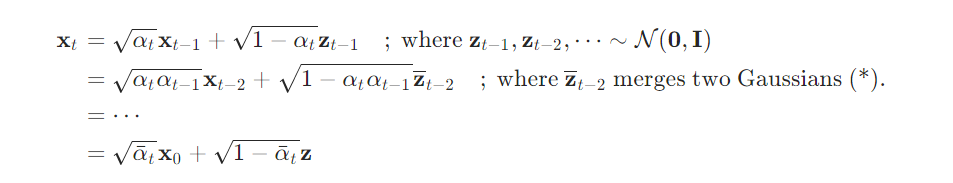
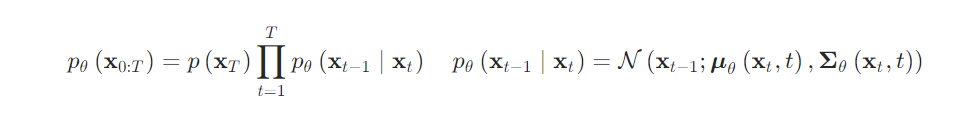
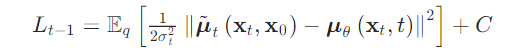

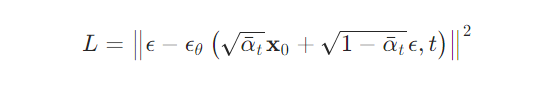






-
CLIP model, aligning image and text representations -
Prior model, receiving text information and converting it into CLIP image representations -
Diffusion model, receiving image representations to generate complete images
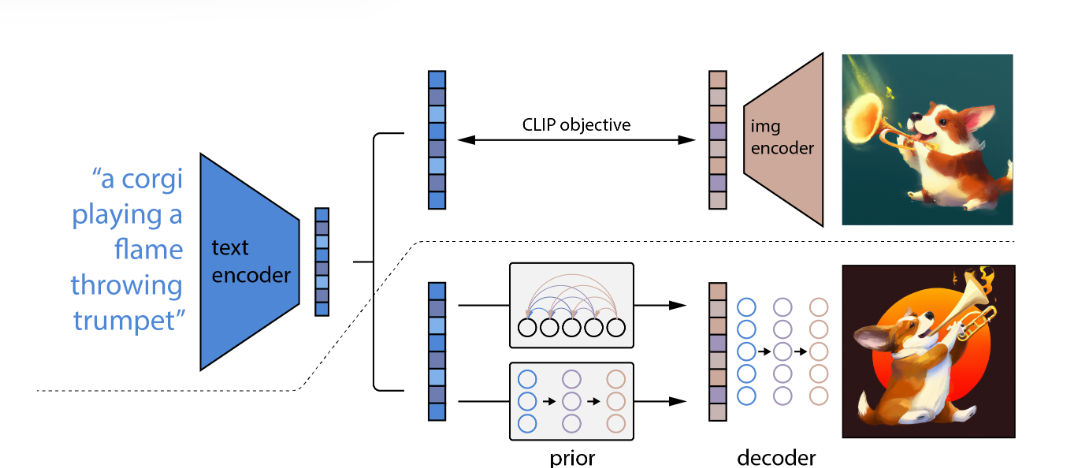
-
Train a CLIP model to align text and image features. -
Train a prior model, either an autoregressive model or a diffusion prior model (experiments have shown that the diffusion prior model performs better), which functions to map text representations to image representations. -
Train a diffusion decoder model, which aims to restore the original image based on image representations.

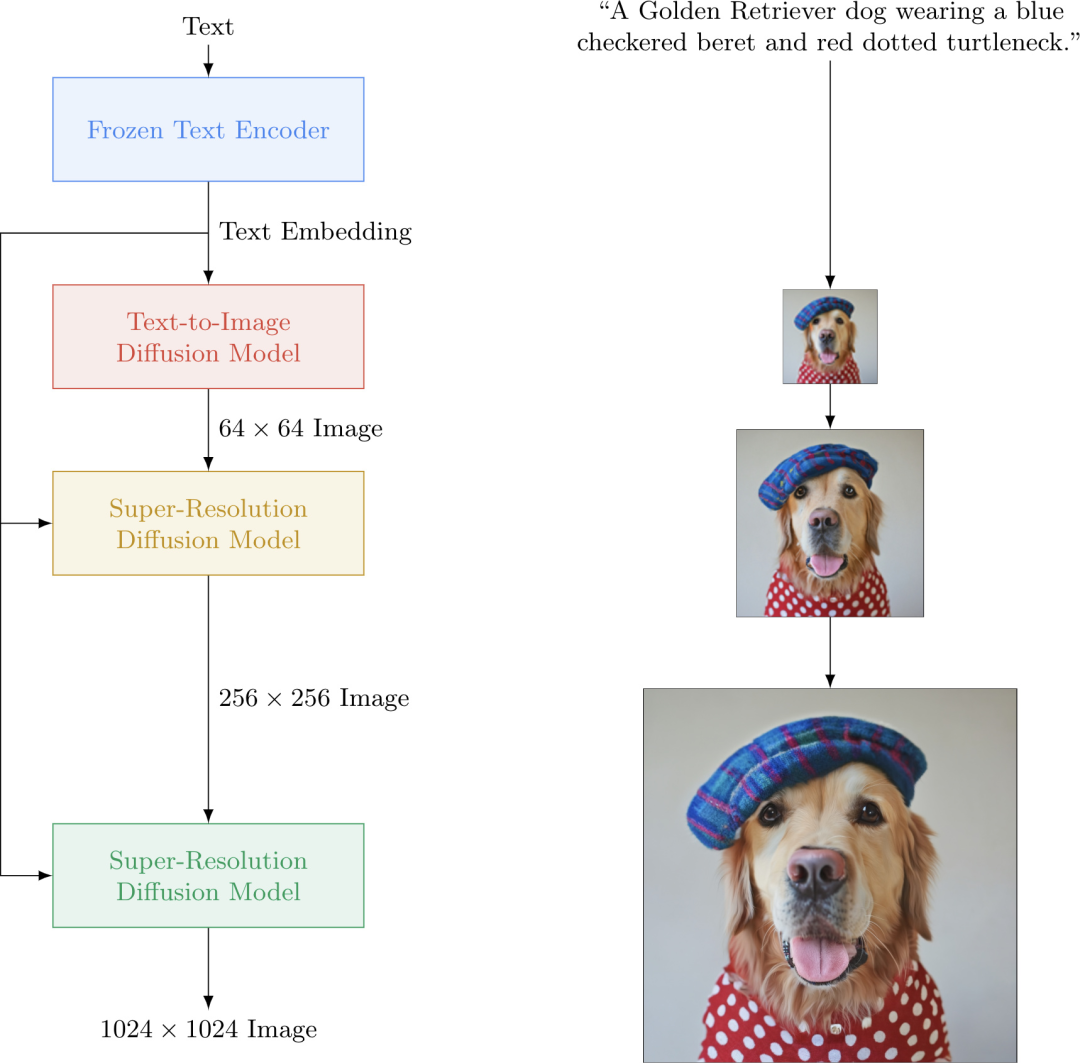

Its role is to convert images into low-dimensional representations, allowing the diffusion process to occur in this low-dimensional representation. After diffusion is complete, the VAE decoder is used to decode it back into an image.
U-Net is the backbone network of the diffusion model, responsible for predicting noise to achieve the reverse denoising process.
Primarily responsible for converting text into representations that U-Net can understand, guiding U-Net during diffusion.
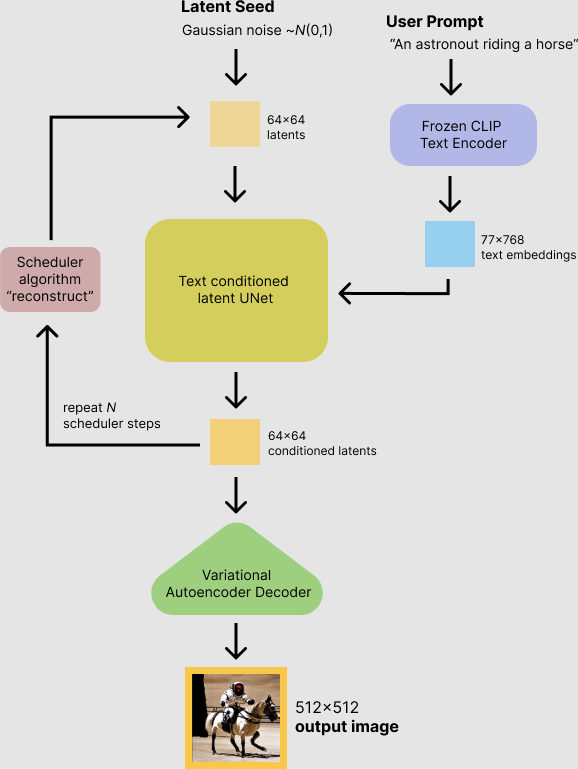
Model Trials
Model Trials
https://nightcafe.studio/
https://huggingface.co/spaces/dalle-mini/dalle-mini
https://github.com/openai/dall-e (requires waiting list)
https://beta.dreamstudio.ai/dream
https://colab.research.google.com/github/alembics/disco-diffusion/blob/main/Disco_Diffusion.ipynb
https://www.midjourney.com/home/
https://nuwa-infinity.microsoft.com/#/ (not yet open, but stay tuned)
Summary
Summary
[1] An Introduction to Autoencoders
[2] https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
[3] Neural Discrete Representation Learning
[4] https://openai.com/blog/dall-e/
[5] Zero-Shot Text-to-Image Generation
[6] Generative adversarial nets
[7] Taming Transformers for High-Resolution Image Synthesis
[8] VQGAN-CLIP: Open Domain Image Generation and Editing with Natural Language Guidance
[9] https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-mini–Vmlldzo4NjIxODA
[10] Scaling Autoregressive Models for Content-Rich Text-to-Image Generation
[11] NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
[12] Denoising Diffusion Probabilistic Models
[13] https://lilianweng.github.io/posts/2021-07-11-diffusion-models/#nice
[14] https://huggingface.co/blog/annotated-diffusion
[15] Classifier-Free Diffusion Guidance
[16] GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
[17] Hierarchical Text-Conditional Image Generation with CLIP Latents
[18] https://openai.com/dall-e-2/
[19] Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
[20] https://github.com/sd-webui/stable-diffusion-webui
[21] https://huggingface.co/blog/stable_diffusion
►►►
Registration Now Open for the Complex Science x Art Seminar Series

Seminar details and framework:
Chaos & Muses: Complex Science x Art Seminar Series
Recommended Reading
-
A Comprehensive Review of 100 Papers on Computational Aesthetics: How to Conduct Aesthetics from the Perspective of Complexity Science -
Frontiers of Computational Aesthetics: Rediscovering the History of Landscape Painting through Information Theory -
Truth and Beauty in Physics and Biology -
The Complete Online Launch of “Zhangjiang: 27 Lectures on the Frontiers of Complexity Science”! -
Become a Collective Intelligence VIP, unlock all site courses/book clubs -
Join Collective Intelligence, let’s explore complexity together!