Source | OSCHINA Community – OneFlow Deep Learning Framework
Original link: https://my.oschina.net/oneflow/blog/6087116

Translated by|Yang Ting, Xu Jiayu
Recently, AI image generation has attracted attention for its ability to create stunning images based on textual descriptions, greatly changing the way people create images.Stable Diffusion, as a high-performance model, produces higher quality images, operates faster, and consumes fewer resources and memory, marking a milestone in the field of AI image generation.
After being introduced to AI image generation, you may be curious about how these models work.
Below is an overview of how Stable Diffusion works.
Stable Diffusion has a wide range of applications and is a multifunctional model. It can generate images from text (text2img). The above image is an example of generating an image from text input. In addition, we can also use Stable Diffusion to replace or modify images (in which case we need to input both text and images).
Below is the internal structure of Stable Diffusion. Understanding the internal structure helps us better comprehend the components of Stable Diffusion, how they interact, and the meaning of various image generation options/parameters.
1Components of Stable Diffusion
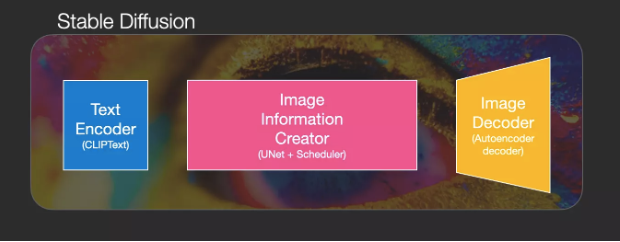
Stable Diffusion is not a single model but a system composed of multiple parts and models.
Internally, we can first see a text understanding component that converts text information into a numeric representation to capture the intent of the text.
This section provides a general introduction to ML, and more details will be explained later in the article. It can be said that this text understanding component (text encoder) is a special Transformer language model (strictly speaking, it is a text encoder of a CLIP model). Text input into the Clip text encoder yields a feature list, where each word/token in the text receives a vector feature.
Then, the text features are used as input for the image generator, which consists of several parts.
The image generator has two steps:
1-Image Information Creator
The Image Information Creator is a key part unique to Stable Diffusion and is the reason for its performance far exceeding other models.
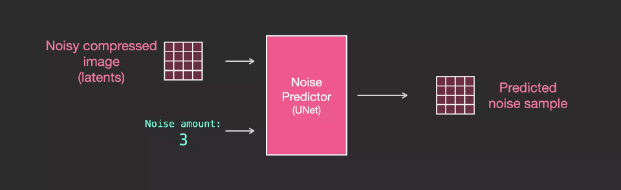
The Image Information Creator runs multiple steps to generate image information. The step parameter of Stable Diffusion interfaces and libraries is generally set to 50 or 100 by default.
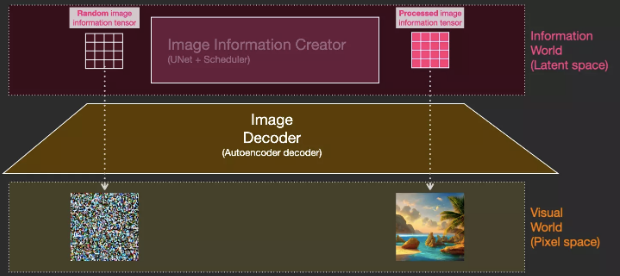
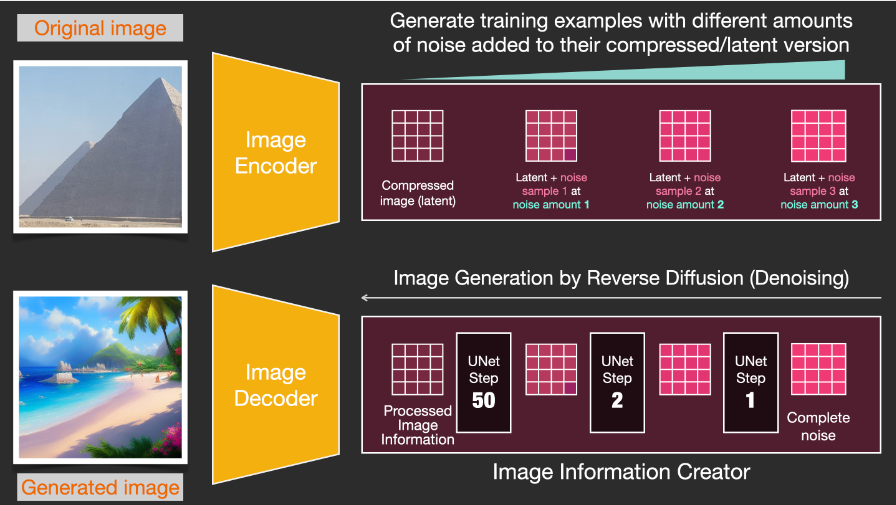
The Image Information Creator operates entirely in the image information space (also known as latent space), allowing Stable Diffusion to run faster than previous diffusion models that operated in pixel space. Technically, the Image Information Creator consists of a UNet neural network and a scheduling algorithm.
The term “diffusion” describes what happens in the Image Information Creator. As the Image Information Creator processes information step by step, the Image Decoder can subsequently produce high-quality images.
The Image Decoder draws images based on the information from the Image Information Creator. It runs only once at the end of the process to generate the final pixel image.
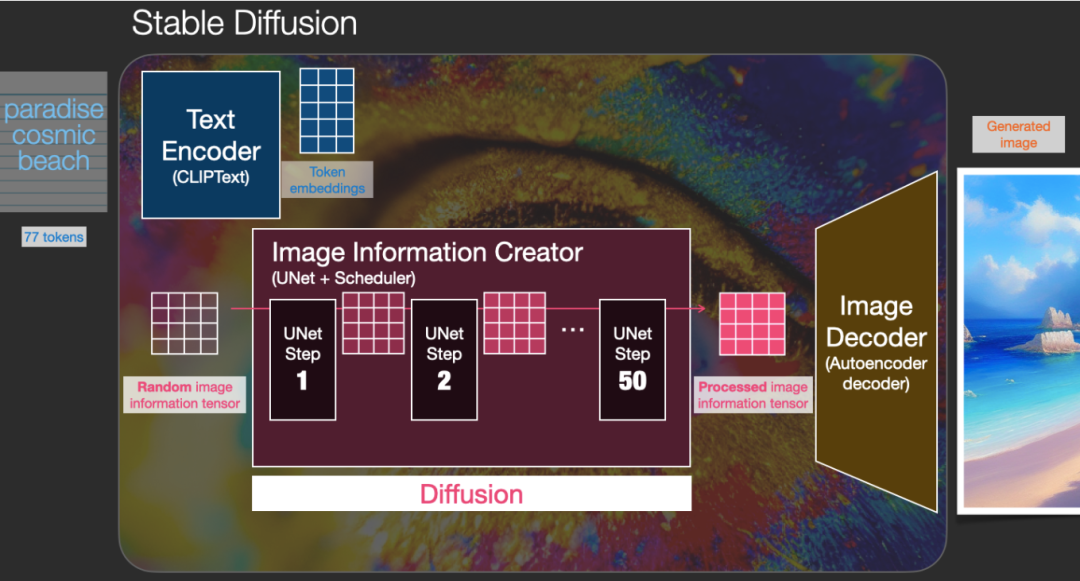
This constitutes the three main components of Stable Diffusion, each with its own neural network:
-
ClipText: Used for text encoding. Input: Text. Output: 77 token embeddings vectors, each with 768 dimensions.
-
UNet + Scheduler: Gradually processes information in the latent space. Input: Text embeddings and an initialized multidimensional array (structured list of numbers, also known as a tensor) consisting of noise. Output: Processed information array.
-
Autoencoder Decoder: Uses the processed information array to draw the final image. Input: Processed information array (dimensions: (4,64,64)) Output: Generated image (dimensions: (3,512,512), i.e., (Red/Green/Blue; Width, Height)).
Diffusion is the process that occurs in the pink area of the Image Information Creator component. This part has a token embeddings representation of the input text and a randomly initialized image information array, which are also known as latents. During this process, an information array is produced, which the Image Decoder uses to generate the final image.
Diffusion occurs gradually step by step, with more relevant information added at each step. To better understand this process, we can examine the random latents array to see if it transforms into visual noise. In this case, visual inspection is performed through the Image Decoder.
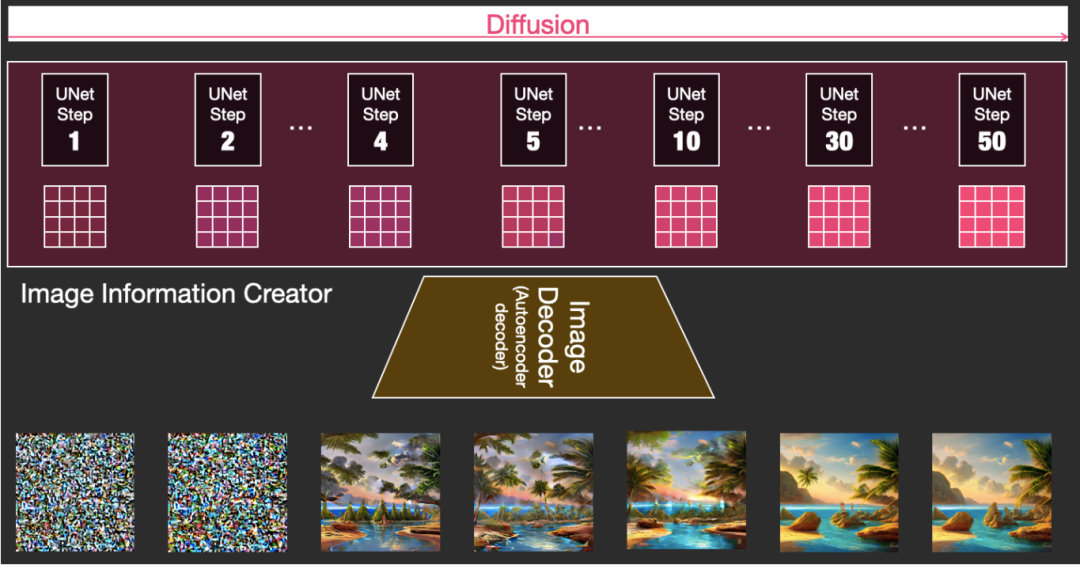
Diffusion is divided into multiple steps, with each step running on the input latents array and producing another latents array that is more similar to the input text and all visual information obtained during model training.
We can visualize a set of such latents arrays to see what information is added at each step. This process is breathtaking.
In this case, something particularly interesting happens between steps 2 and 4, as if the outlines emerge from the noise.
The core of diffusion model image generation is a powerful computer vision model. Based on a sufficiently large dataset, these models can learn many complex operations. The diffusion model constructs the problem for image generation as follows:
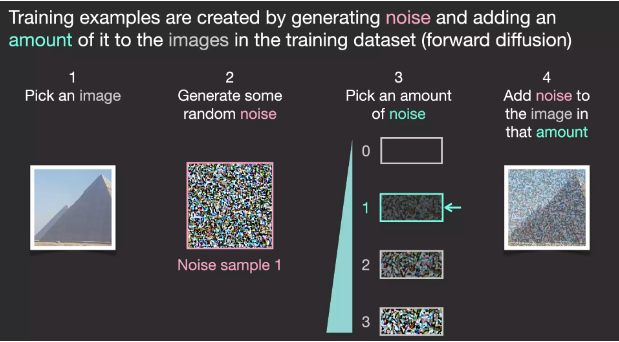
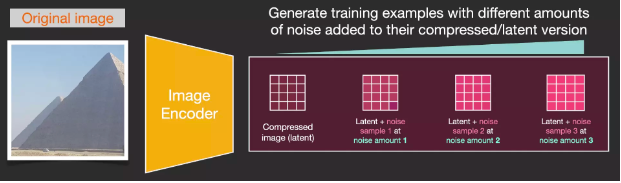
Assume we have an image; we first generate some noise and then add this noise to the image.
We can consider this as a training example. Afterward, we use the same formula to create more training examples and train the central component of the image generation model with these examples.
Although this example demonstrates some noise values from the image (total 0, no noise) to total noise (total 4, total noise), we can easily control the noise added to the image, allowing us to create dozens of training examples for each image in the dataset.
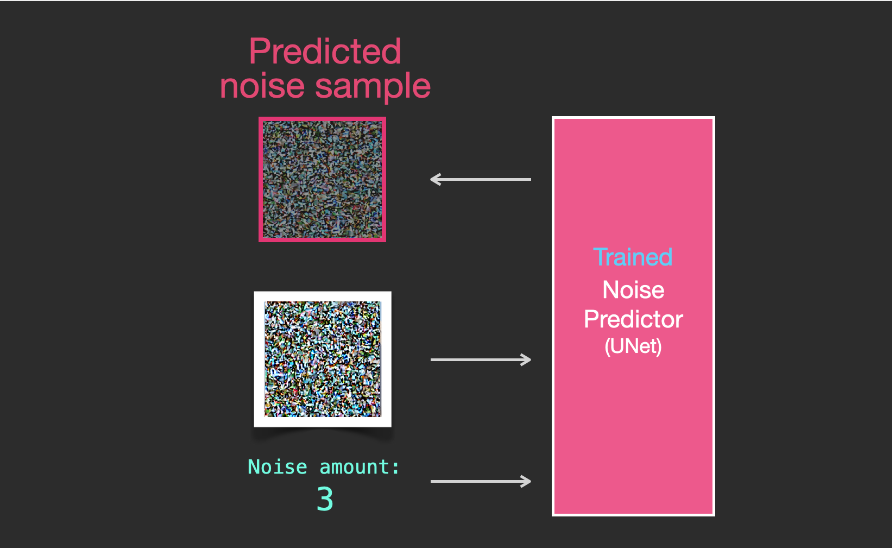
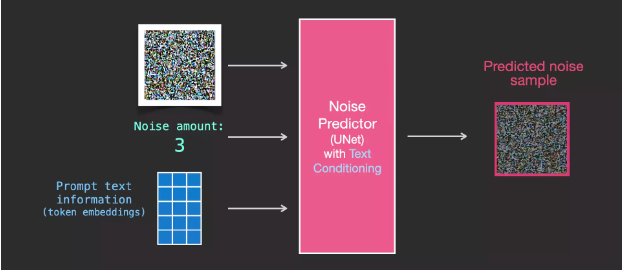
With this dataset, we can train a noise predictor and ultimately obtain a predictor that can create images when run under specific configurations. Those familiar with ML will find the training steps very familiar:
Next, let’s see how Stable Diffusion generates images.
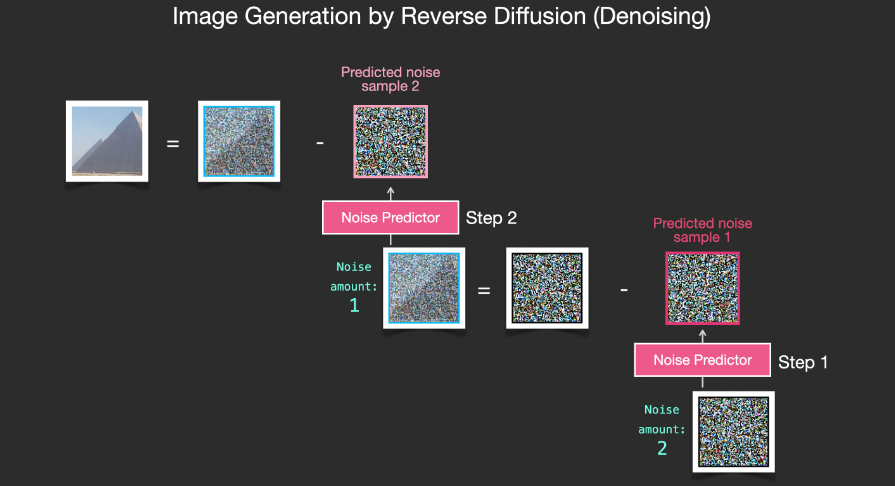
4Image Generation Through Denoising
The trained noise predictor can denoise noisy images and predict noise.
Since the sampled noise is predicted, if we remove this sample from the image, the resulting image will be closer to the images the model was trained on. (This image is not the exact image itself but rather the image distribution, meaning the arrangement of pixels where the sky is usually blue, above the ground, a person has two eyes, a cat has pointed ears and is always lazy).
If the images in the training dataset are aesthetically pleasing, such as those trained on LAION Aesthetics, then the generated images will also be more visually appealing. If we train on logo images, we will ultimately obtain a logo generation model.
This summarizes the process by which diffusion models handle image generation, mainly as described in the paper Denoising Diffusion Probabilistic Models. I believe you have gained some understanding of the meaning of diffusion and the main components of Stable Diffusion, Dall-E 2, and Google Imagen.
It is worth noting that up to this point, the diffusion process we have described does not use any text data; it can generate beautiful images just by running the model. However, we cannot control the content of the image; it could be a pyramid or a cat. Next, we will discuss how to incorporate textual information into the diffusion process to control the type of images.
5Speed Improvement: Diffusion in Compressed (Latent) Data
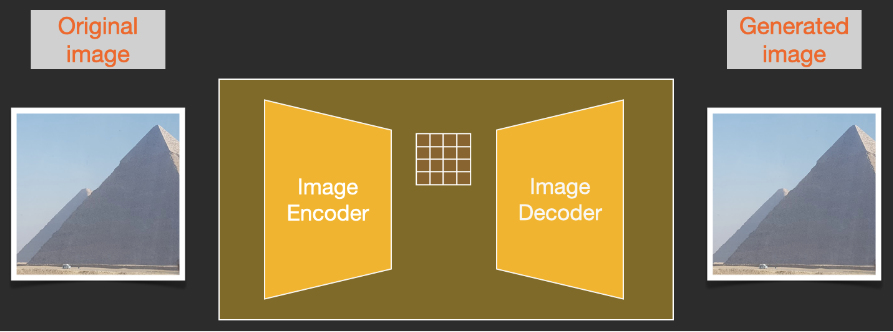
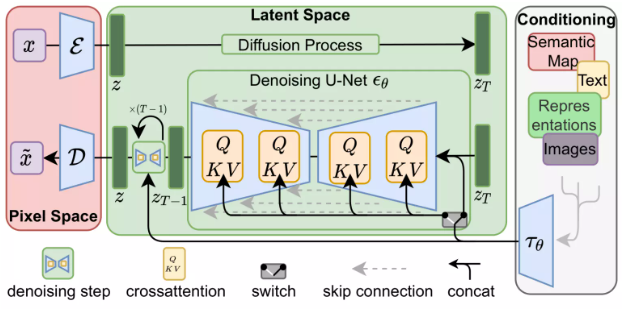
To speed up the image generation process, the Stable Diffusion paper does not operate on pixel images but runs on a compressed version of the images. This is referred to as Departure to Latent Space.
The compression (followed by decompression/drawing) is accomplished by the encoder. The autoencoder uses the Image Encoder to compress the image into latent space and then uses the Image Decoder to reconstruct the compressed information.
Forward diffusion is completed in the latent space. Noise information is applied to the latent space instead of the pixel images. Therefore, training the noise predictor is essentially to predict noise on the compressed representation, which is also referred to as latent space.
Forward diffusion is performed using the Image Encoder to generate image data to train the noise predictor. Once training is complete, backward diffusion can be executed using the Image Decoder to generate images.
Figure 3 in the LDM/Stable Diffusion paper mentions these two processes:
The above image also shows the “conditioning” component, which in this case is the text prompts describing the model-generated images. Next, we continue to explore the text component.
6Text Encoder: A Transformer Language Model
The Transformer language model serves as the language understanding component, capable of accepting text prompts and generating token embeddings. The Stable Diffusion model uses ClipText (a GPT-based model), while the paper employs BERT.
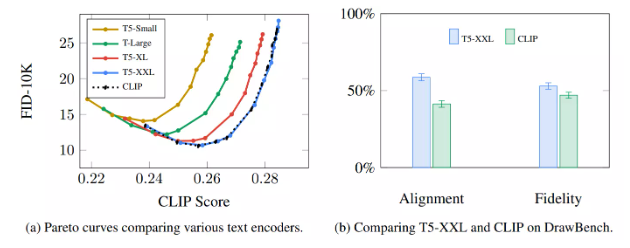
The Imagen paper indicates that the choice of language model is quite important. Compared to larger image generation components, larger language model components have a greater impact on the quality of generated images.
Larger/better language models have a huge impact on the quality of image generation models. Source: Figure A.5 in the paper by Saharia et al. on Google Imagen.
Earlier versions of the Stable Diffusion model only used the pre-trained ClipText model released by OpenAI. Future models may shift to the newly released larger CLIP variant, OpenCLIP. (Updated in November 2022, details can be found in Stable Diffusion V2 uses OpenClip. Compared to ClipText, which has only 6.3 million text model parameters, OpenCLIP has as many as 354 million text model parameters.)
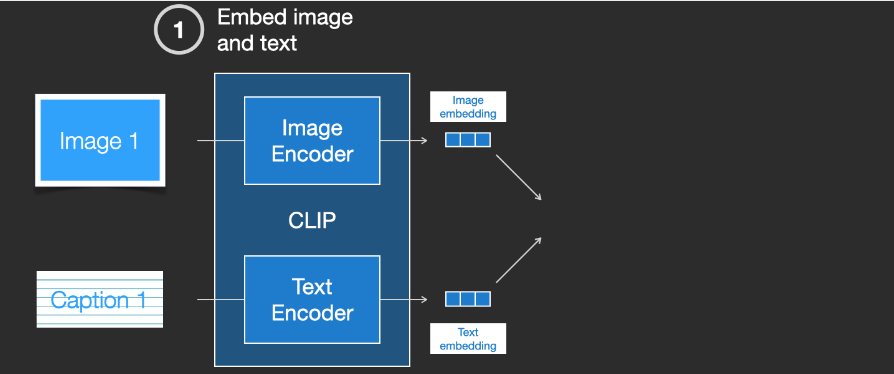
CLIP is trained on datasets of images and image descriptions. We can envision a dataset containing 400 million images and their corresponding descriptions.
Image and Image Description Dataset
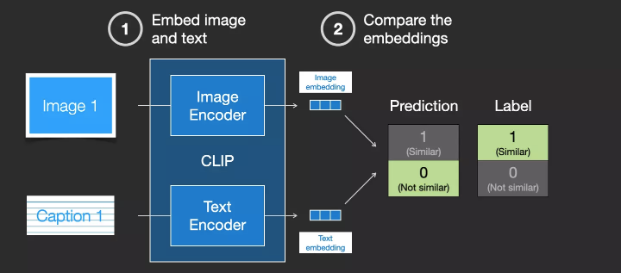
In reality, CLIP is trained on images scraped from the web with “alt” tags. CLIP combines an image encoder and a text encoder. In simple terms, training CLIP involves encoding both the images and their textual descriptions.
Then, cosine similarity is used to compare the generated embeddings. At the beginning of training, even if the text correctly describes the image, the similarity will be low.
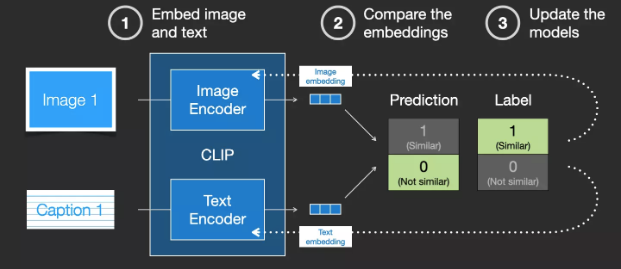
We update these two models so that the next time we embed them, we can get similar embeddings.
By repeating this process on the dataset and using a large batch size, we ultimately enable the encoder to generate similar embeddings for images and text descriptions. Similar to word2vec, the training process also requires including mismatched images and text descriptions as negative samples to achieve lower similarity scores.
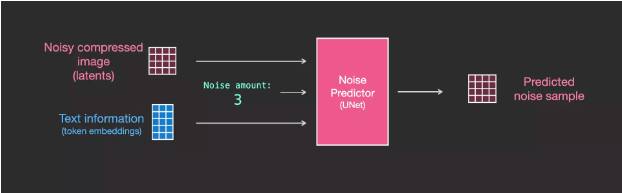
8Integrating Text Information into Image Generation Process
To integrate text into image generation, we need to adjust the noise predictor to input text.
Now, text is added to the dataset. Since we are operating in latent space, both the input images and the predicted noise are in latent space.
To better understand how text tokens are used in UNet, we will further explore the UNet model.
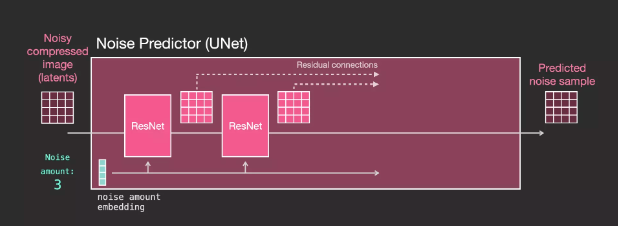
UNet Noise Predictor Layers (Without Text)
First, let’s look at the UNet without text, its input and output are as follows:
-
UNet is a series of layers used to transform latents arrays
-
Each layer operates on the output of the previous layer
-
Some of the outputs are fed (via residual connections) into the processing later in the network
-
Through residual connections, the outputs from earlier layers are sent to later layers for processing
-
The time step is transformed into an embedding vector used within the network layers
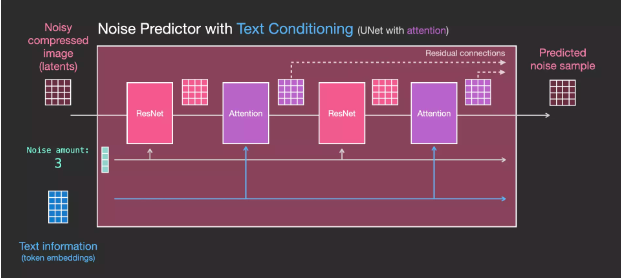
UNet Noise Predictor Layers (With Text)
Now let’s see how to change the system to increase focus on text.
To support text input, also known as text conditioning, we need to add an attention layer between the ResNet blocks of the system.
The text information is not directly processed by ResNet but is integrated into the latents through the attention layer. This way, the next ResNet can utilize the integrated text information during processing.
I hope this article helps you gain a deeper understanding of how Stable Diffusion operates. Although many other concepts are involved, once you are familiar with the above sections, these concepts will become easier to understand. Below are some resources I find very useful.
-
https://www.youtube.com/shorts/qL6mKRyjK-0
-
https://huggingface.co/blog/stable_diffusion
-
https://huggingface.co/blog/annotated-diffusion
-
-
-
-
https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
-
(This article is published by OneFlow under the CC BY-NC-SA 4.0 license. For reprinting, please contact for authorization.Original: Alammar, J (2018). The Illustrated Transformer [Blog post]. https://jalammar.github.io/illustrated-stable-diffusion/)
 Prize Q&A
Prize Q&A
Chat about Cloud Computing, Cross-Cloud Storage, and Xline
Participate in the Q&A for a chance to win a copy of the book “Rust in Action”
“Chat about Cloud Computing, Cross-Cloud Storage, and Xline”

Here you will find the latest open-source news, software updates, and technical insights
Click here ↓↓↓ Don’t forget to follow ✔ and star ⭐