

1. Introduction
On June 27, the authoritative technology magazine “MIT Technology Review” announced the list of the 50 smartest companies in the world for 2017. iFlytek ranked first in China and sixth globally. The companies ahead of iFlytek are: NVIDIA, SpaceX, Amazon, 23andMe, and Alphabet. “MIT Technology Review” stated that “iFlytek’s voice assistant is the Chinese version of Siri, with a portable real-time translator that is an outstanding AI application, overcoming dialects, slang, and background noise, accurately translating Chinese into over a dozen languages. iFlytek holds a 70% market share in China’s voice technology market.” More and more people believe that voice recognition will become the key technology for the next generation of interaction revolution.
Meanwhile, in our daily lives, we have become accustomed to using voice assistants like Siri or Cortana to solve small problems in specific situations, such as scheduling our week while driving or briefly replying to messages. However, in most cases, the usage rate of voice assistants is not high. According to a survey by Creative Strategies, 62% of Android users have never used a voice assistant, while the number is 70% among Apple users. Is it because the technology of voice recognition is not advanced enough, or do people not need voice assistants? The success of Amazon Echo may provide some insights.
The Amazon Echo is a home voice assistant launched by Amazon in November 2014, capable of numerous functions including shopping, controlling smart home devices, reading Kindle, booking Uber, tracking (Amazon) deliveries, ordering pizza, timing, performing arithmetic, playing music, locating phones, and mimicking rain sounds, among others. Upon its launch, it ignited market enthusiasm. According to foreign research institutions, Echo’s sales were around 1.7 million units in 2015, growing to over 6.5 million units in 2016, and as of January 2017, global sales of Amazon Echo exceeded 7 million units, with an expected breakthrough of 11 million units this year. According to a report by eMarketer, Amazon Echo holds over 70% of the smart speaker market in the United States.
Why is the situation of Echo and Siri so different? Researchers believe this is mainly due to the different usage environments of the two products. For most people, taking out a phone and talking to a robot in public lacks privacy and can be somewhat uncomfortable; however, at home, facing family and friends, this issue can be effectively avoided, and a quiet environment can greatly enhance the speed and accuracy of machine recognition. It can be said that Amazon Echo has accurately targeted the market. However, other giants are not willing to fall behind and have launched their own home smart voice assistants: Apple has launched HomePod, and Google has introduced Google Home. It seems that a voice war is brewing.
2. Basic Principles of Voice Recognition
Voice recognition refers to converting a segment of voice signal into corresponding text information. The system mainly consists of four parts: feature extraction, acoustic model, language model, and dictionary and decoding. To effectively extract features, it is often necessary to preprocess the collected sound signals through filtering and framing, extracting the signal to be analyzed from the original signal. After that, the feature extraction process converts the sound signal from the time domain to the frequency domain, providing suitable feature vectors for the acoustic model. The acoustic model then calculates the score of each feature vector based on acoustic characteristics. The language model calculates the probability of the possible sequence of words corresponding to the sound signal based on linguistic theories. Finally, decoding is performed based on the existing dictionary to obtain the final possible text representation.
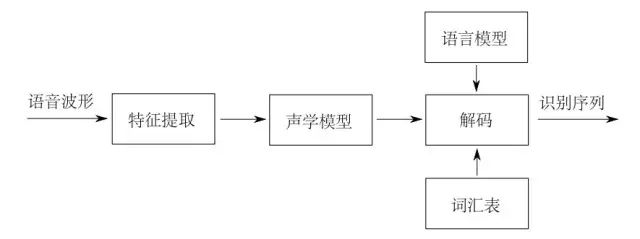
1. Acoustic Signal Preprocessing
As a prerequisite and foundation for voice recognition, the preprocessing of voice signals is crucial. During the final model matching, the feature parameters of the input voice signal are compared with the feature parameters in the template library. Therefore, only by obtaining feature parameters that can represent the essential characteristics of the voice signal during the preprocessing stage can these parameters be matched for high recognition rates.
First, the sound signal needs to be filtered and sampled. This process is mainly to exclude signals outside the human voice frequency and interference from the 50Hz electrical current frequency. This is generally done using a bandpass filter, setting upper and lower cutoff frequencies for filtering, and then quantifying the original discrete signal; next, it is necessary to smooth the transition segments of high and low-frequency parts of the signal to facilitate solving the spectrum under the same signal-to-noise ratio conditions; framing and windowing operations are performed to give the original time-varying frequency domain signal short-term stationary characteristics, i.e., dividing the continuous signal into independent, frequency-domain stable parts of different lengths for analysis, mainly using pre-emphasis techniques; finally, endpoint detection is required to correctly determine the start and end points of the input voice signal, mainly through short-term energy (the amplitude change of the signal within the same frame) and short-term average zero-crossing rate (the number of times the sampled signal crosses zero within the same frame) for roughly judging, specific details can refer to the end of the article【References】.
2. Acoustic Feature Extraction
After completing the preprocessing of the signal, the next step is the extremely critical feature extraction operation in the entire process. Simply recognizing the original waveform does not yield good recognition results; the feature parameters extracted after frequency domain transformation are used for recognition, and the feature parameters that can be used for voice recognition must meet the following criteria:
-
The feature parameters can describe the fundamental features of the voice as much as possible;
-
Minimize coupling between parameter components, compressing the data;
-
The process of calculating feature parameters should be simplified, making the algorithm more efficient. Pitch period, resonance peak values, etc., can serve as characteristic parameters representing voice features.
Currently, the most commonly used feature parameters by mainstream research institutions include Linear Predictive Cepstral Coefficients (LPCC) and Mel Frequency Cepstral Coefficients (MFCC). Both feature parameters operate on voice signals in the cepstral domain, with the former starting from the vocal model and using LPC technology to obtain cepstral coefficients. The latter simulates the auditory model, using the output from the filter bank model as acoustic features, followed by discrete Fourier transform (DFT) for transformation.
The so-called pitch period refers to the vibration period of the vocal cords’ frequency (fundamental frequency), as it effectively characterizes the features of voice signals; the so-called resonance peak refers to the areas where energy is concentrated in the voice signal, as it characterizes the physical features of the vocal tract and is a major determinant of speech quality, making it an essential feature parameter as well. The detailed extraction methods for these two parameters and the currently mainstream feature parameters LPCC, MFCC, etc., will not be elaborated here; please refer to the end of the article【References】. Additionally, many researchers are beginning to apply some methods from deep learning in feature extraction, achieving rapid progress, which will be introduced in more detail in Chapter 3.
3. Acoustic Model
The acoustic model is a very important component of the voice recognition system, and its ability to differentiate between different basic units directly affects the quality of recognition results. Voice recognition is essentially a pattern recognition process, and the core of pattern recognition is the issue of classifiers and classification decisions.
Typically, in isolated words or small vocabulary recognition, using Dynamic Time Warping (DTW) classifiers yields good recognition results, with fast recognition speeds and low system overhead, making it a successful matching algorithm in voice recognition. However, in large vocabulary or non-specific speaker voice recognition, the recognition effect of DTW declines sharply; at this point, using Hidden Markov Models (HMM) for training significantly improves recognition effects. Traditionally, Gaussian Mixture Models (GMM) are used to characterize state output density functions in conventional voice recognition, hence it is also known as the GMM-HMM framework.
Simultaneously, with the development of deep learning, using Deep Neural Networks (DNN) for acoustic modeling has formed the so-called DNN-HMM framework to replace the traditional GMM-HMM framework, achieving good results in voice recognition, which will be introduced in Chapter 3. This chapter will first introduce the basic theory of the Gaussian Mixture Model – Hidden Markov Model (GMM-HMM).
3.1 Gaussian Mixture Model
For a random vector x, if its joint probability density function satisfies formula 2-9, it is said to follow a Gaussian distribution, denoted as x ∼ N(µ, Σ).
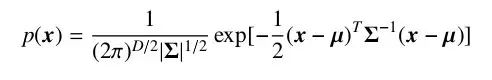
Where µ is the expected value of the distribution, and Σ is the covariance matrix of the distribution. Gaussian distribution has a strong ability to approximate real-world data and is easy to compute, thus it is widely used in various disciplines. However, there are still many types of data that cannot be well described by a single Gaussian distribution. In such cases, we can use a mixture of multiple Gaussian distributions to describe this data, with multiple components responsible for different potential data sources. At this point, the random variable conforms to the density function.
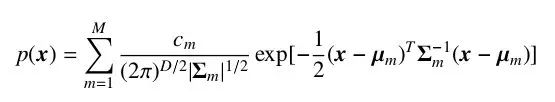
Where M is the number of components, usually determined by the problem scale.
We refer to the model used to describe data following a mixture of Gaussian distributions as a Gaussian Mixture Model. Gaussian Mixture Models are widely used in the acoustic models of many voice recognition systems. Considering that the dimensionality of vectors in voice recognition is relatively high, we usually assume that the covariance matrix Σm in the mixture Gaussian distribution is a diagonal matrix. This not only significantly reduces the number of parameters but also improves computational efficiency.
Using Gaussian Mixture Models to model short-term feature vectors has the following advantages: first, Gaussian Mixture Models have strong modeling capabilities; as long as the total number of components is sufficient, Gaussian Mixture Models can approximate a probability distribution function with arbitrary precision; additionally, using the EM algorithm can easily lead to convergence of the model on training data. For issues such as computational speed and overfitting, researchers have also developed parameter-tying GMM and subspace Gaussian mixture models (subspace GMM) to address these. Besides using the EM algorithm for maximum likelihood estimation, we can also use a discriminative error function directly related to word or phoneme error rates to train Gaussian Mixture Models, greatly improving system performance. Therefore, until the emergence of deep neural network technology in acoustic models, Gaussian Mixture Models have always been the best choice for modeling short-term feature vectors.
However, Gaussian Mixture Models also have a serious drawback: they have very poor modeling capabilities for data near a non-linear manifold in vector space. For instance, suppose some data is distributed on both sides of a sphere and is very close to the sphere. If we use a suitable classification model, we may only need a few parameters to distinguish the data on both sides of the sphere. However, if we use a Gaussian Mixture Model to depict their actual distribution, we would need a very large number of Gaussian distribution components to accurately characterize them. This drives us to seek a model that can more effectively utilize voice information for classification.
3.2 Hidden Markov Model
Now, we consider a discrete random sequence; if the transition probabilities satisfy the Markov property, meaning that future states are independent of past states, it is called a Markov chain. If the transition probabilities are time-invariant, it is called a homogeneous Markov chain. The output of a Markov chain corresponds one-to-one with predefined states; for any given state, the output is observable and has no randomness. If we extend the output so that each state of the Markov chain outputs a probability distribution function, then the states of the Markov chain cannot be directly observed but can only be inferred through other variables that conform to probability distributions affected by state changes. We refer to the model that uses this hidden Markov sequence assumption to model data as a Hidden Markov Model.
In the context of voice recognition systems, we use Hidden Markov Models to characterize the sub-state changes within a phoneme to solve the correspondence between feature sequences and multiple basic units of speech.
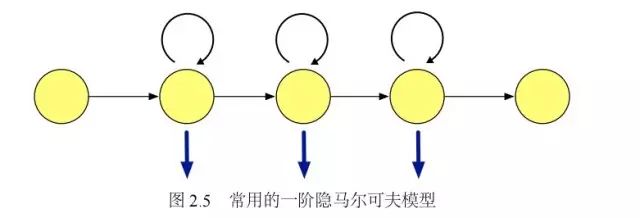
Using Hidden Markov Models in voice recognition tasks requires calculating the model’s likelihood on a segment of speech. During training, we need to use the Baum-Welch algorithm to learn the parameters of the Hidden Markov Model and perform maximum likelihood estimation (MLE). The Baum-Welch algorithm is a special case of the EM (Expectation-Maximization) algorithm, which iteratively computes the conditional expectations in the E-step and maximizes the conditional expectations in the M-step using prior and posterior probabilities.
4. Language Model
The language model primarily describes the habitual ways of human language expression, focusing on the inherent relationships between words in terms of their arrangement structure. In the decoding process of voice recognition, the language model is referenced for inter-word transitions, while the word internal transitions reference the pronunciation dictionary. A good language model not only improves decoding efficiency but also enhances recognition rates to some extent. Language models can be classified into rule-based models and statistical models, with statistical language models characterizing the inherent statistical laws of language units using probabilistic methods, which are simple and practical in design and have achieved excellent results, widely used in voice recognition, machine translation, sentiment recognition, and other fields.
The simplest and most commonly used language model is the N-gram language model (N-gram LM). The N-gram language model assumes that the probability of the current word, given the previous context, only depends on the preceding N-1 words. Therefore, the probability of a word sequence w1, . . . , wm can be approximated as
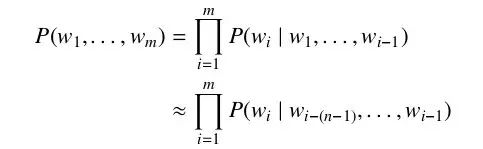
To obtain the probability of each word in the formula given the previous context, we need a sufficient amount of text in that language to estimate. We can directly calculate this probability using the proportion of the word pairs containing the previous context among all word pairs.
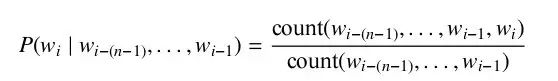
For word pairs that have not appeared in the text, we need to use smoothing methods for approximation, such as Good-Turing estimation or Kneser-Ney smoothing, etc.
5. Decoding and Dictionary
The decoder is the core component of the recognition phase, decoding the speech using the trained model to obtain the most probable word sequence or generating a recognition lattice based on intermediate results for subsequent components to process. The core algorithm of the decoder is the dynamic programming algorithm Viterbi. Due to the enormous decoding space, we typically use token passing methods with limited search width in practical applications.
Traditional decoders dynamically generate decoding graphs, such as the well-known voice recognition tools HTK (HMM Tool Kit) with HVite and HDecode, etc. This implementation consumes less memory, but considering the complexity of various components, the overall system flow is cumbersome, making it inconvenient and inefficient to combine language models and acoustic models and more challenging to scale. Current mainstream decoder implementations will use pre-generated finite state transducers (FST) as preloaded static decoding graphs to some extent. Here, we can construct the language model (G), vocabulary (L), context information (C), and Hidden Markov Model (H) as standard finite state transducers and combine them through standard finite state transducer operations to build a transducer from context-related phoneme sub-states to words. This implementation method uses some additional memory space but makes the instruction sequences of the decoder more organized, facilitating the construction of an efficient decoder. Moreover, we can pre-optimize the pre-constructed finite state transducers, merging and trimming unnecessary parts to make the search space more reasonable.
Summary:
In the past, the most popular voice recognition systems typically used Mel Frequency Cepstral Coefficients (MFCC) or Perceptual Linear Prediction (PLP) as feature vectors and Gaussian Mixture Model – Hidden Markov Model (GMM-HMM) as acoustic models, trained using maximum likelihood criteria (ML) and Expectation-Maximization algorithms.
3. Frontiers in Speech Recognition
As early as the 1980s, researchers began using neural networks as classifiers in language recognition. However, due to the limitations of computing power at the time, the scarcity of speech data, and choices in modeling basic units of speech, neural network classifiers did not become mainstream in subsequent voice recognition systems and performed worse than Gaussian Mixture Models. However, with the new century, people have reevaluated neural networks, and the wave of deep learning has swept through the field of voice recognition, leading to a surge of research into the applications of deep neural networks in voice recognition. The deep neural network model is a discriminative model, which requires relatively fewer parameters than generative models like Gaussian Mixture Models, which need to describe the complete distribution, making it easier to achieve good results for the task of distinguishing different basic units.
With the popularity of deep learning, important concepts such as Artificial Neural Networks (ANN), Convolutional Neural Networks (CNN), and Backpropagation (BP) have become widely known and will not be elaborated here.
1. Deep Learning and Acoustic Feature Extraction
One of the simplest methods to apply neural networks in traditional HMM-GMM systems is to use neural networks for feature learning. This approach does not require modifying the existing voice recognition framework and can enhance system performance without significant changes to the system.
Using traditional speech feature extraction algorithms (such as MFCC or PLP) only applies to single-frame signals, which cannot adequately encompass effective speech information and are susceptible to noise pollution. For feature learning and speech recognition, this goal can be summarized as the use of original spectral features or waveform features. Over the past 30 years, although transformations of speech spectra have lost some information from the original speech data, various “handcrafted” features have greatly improved the recognition rates of GMM-HMM systems. The most successful among these is the non-adaptive cosine transform, which facilitated the generation of MFCC features. The cosine transform approximately removes correlations between feature components, which is crucial for GMMs using diagonal covariance matrices. However, as deep learning models replace GMM models, the removal of correlations between features becomes less relevant.
In using DNN for feature extraction, there are two common approaches: the first is bottleneck (BN) features. We need to construct a bottleneck-shaped neural network, where one hidden layer’s dimension is much smaller than that of other hidden layers. Next, we can either use an autoencoder for unsupervised training of the network or set the network’s output target as the posterior probabilities of states, training it using the BP algorithm. Upon completion of training, the network structure behind the bottleneck is deleted, and the output at that time is taken as the feature. The BN features obtained in this way can be regarded as a nonlinear feature transformation and dimensionality reduction technique. In constructing HMM-GMM acoustic models, we typically concatenate BN features with traditional short-term features like MFCC as input for learning in the HMM-GMM model. In practice, using pre-trained deep neural networks instead of the shallow networks commonly used in traditional BN features, combined with discriminative training methods, has significantly improved system performance. Another feature learning method is to use tandem features. In practice, tandem features first use a neural network classifier to estimate the posterior probabilities of phonemes, and then the output vector from the network is orthogonalized using PCA as input features for the HMM-GMM system. This tandem approach performs better than directly using neural network mixture models and standard GMM models. Additionally, Sivadas and others used a hierarchical structure in tandem features, replacing the original single neural network with multiple neural networks, each trained to have different functions and organized hierarchically. This method reduces the parameter scale compared to the original single neural network, shortens training time, and achieves better performance.
2. Deep Learning and Acoustic Modeling
As the role of deep neural networks in voice recognition is further explored, directly adopting HMM-DNN hybrid models has become a better choice. In HMM-DNN hybrid models, we replace multiple GMM models used for different states with a deep neural network. We need to train a deep neural network, with the training goal being to estimate the posterior probabilities of input speech frames for each HMM state, i.e., P(qt = s|xt). To correctly estimate the posterior probabilities in different states, we typically need to generate training corpus alignment information (force alignment) as training targets through existing HMM-GMM models and annotations. The quality of the force alignment information significantly affects the performance of the trained HMM-DNN hybrid model system. In a recent study, researchers further improved system performance by iteratively using the newly trained HMM-DNN hybrid model to generate alignment information for retraining the HMM-DNN hybrid model. Additionally, we usually use features composed of adjacent multiple frames as input for the neural network, enhancing the network’s ability to utilize adjacent information.
3. Future Research Directions
Currently, speech recognition systems that combine deep learning with Hidden Markov Models have achieved good recognition results, such as Baidu’s Deep Speech 2, which has reduced the word error rate for phrase recognition to 3.7%, and Microsoft’s English speech recognition with a word error rate of 5.9%, and have already been pushed into commercial applications. However, there is still considerable room for improvement in current intelligent speech recognition.
At the first Global Machine Intelligence Summit (GMIS 2017) hosted by Machine Heart, Yu Dong, deputy director of Tencent AI Lab and head of the Seattle AI Research Office, delivered a speech titled “Frontier Research in Speech Recognition” discussing four frontier issues in the field of speech recognition:
Research Direction 1: More Effective Sequence-to-Sequence Direct Conversion Models
Speech recognition essentially transforms a sequence of speech signals into a sequence of text or words, so many people believe that to solve this problem, finding an effective sequence-to-sequence conversion model would suffice.
Most previous research was done by making assumptions about the problem and then constructing several components for the transformation from speech signal sequences to word sequences based on these assumptions. Many of these assumptions, such as the short-term stationarity assumption and conditional independence assumption, are reasonable in certain specific cases but problematic in many real-world scenarios. The idea behind sequence-to-sequence direct conversion models is that if we eliminate these components designed based on problematic assumptions and replace them with conversion models learned from training data, we may find better methods to make the sequence conversion more accurate. Another benefit of this approach is that the overall training process can also be simplified.
Research Direction 2: The Cocktail Party Problem
Speech recognition systems in quiet environments have approached human levels. Many practical applications exist, but current speech recognition systems struggle to meet practical requirements in strong noise interference situations. The human auditory system has a “cocktail party effect” that allows us to focus on one person’s conversation amidst background noise, a function that is currently difficult for speech recognition systems to replicate. This problem is particularly evident with far-field microphones. One possible method is to use microphone arrays to capture sound signals from multiple positions and angles to enhance recognition effects, but this may not be the optimal solution. Future research on the brain may provide us with insights.
Research Direction 3: Continuous Prediction and Adaptive Models
In the field of speech recognition, can we build a system that continuously makes predictions? This could continuously improve the next recognition based on existing recognition results, while current speech recognition generally only involves simple matching of speech with text, and the utilization of specific information connections within the language is still very insufficient. Therefore, if we could build a better model that can continuously recognize, what characteristics would it need? One is that it can perform rapid adaptation, allowing us to compress similar information in the model for faster recognition the next time.
Research Direction 4: Joint Optimization of Front-End and Back-End
Traditionally, front-end signal processing techniques typically only use the current state of the speech signal information. In contrast, machine learning methods utilize much of the information learned from training but rarely use current frame information and do not model the data. Therefore, is there a way to better integrate these two methods? This is currently a direction that many research organizations are focusing on. Additionally, can we better optimize the front-end signal processing with the back-end speech recognition engine? Since front-end signal processing may lose information that cannot be recovered in the back-end, can we create an automated system that allocates the signaling information processing effectively, minimizing information loss in the front-end, allowing better utilization of this information in the back-end?
4. Recommended Resources
Resource Site
http://www.52nlp.cn/%e4%b9%a6%e7%b1%8d
I love voice recognition, containing various books, courses, and other resources, as well as a discussion forum.
Books
-
Dr. Huang Xuedong’s Spoken Language Processing
-
Co-authored by Professor L. Rabiner and Professor Zhuang Binghuang, a member of the US National Academy of Engineering, Fundamentals of Speech Recognition
-
HTK Toolkit Manual by Professor Steve Young, former Vice-Chancellor of Cambridge University and Fellow of the Royal Academy of Engineering.
Toolkits
-
HTK
HTK ( http://htk.eng.cam.ac.uk ) is a classic speech recognition toolkit developed by Cambridge University, with around 100,000 professional users worldwide. HTK is written in C, and its earliest code dates back over 20 years. One story about HTK is that the Cambridge Entropy company associated with it was once acquired by Microsoft. After acquiring Entropy’s speech team, Microsoft returned the copyright of HTK to Cambridge University, which later became a free open-source tool. The greatest advantage of HTK is that its code and functions are very stable, and it integrates the most mainstream speech recognition technologies; many of HTK’s extensions are also classic, such as the most important statistical speech synthesis toolkit HTS. Another major advantage of HTK is that it has relatively comprehensive documentation, known as HTK Book. One of HTK’s drawbacks is that updates are relatively slow, and some code may need updating due to its age. HTK had its 3.5 beta version updated at the end of 2015, which includes neural network technologies. Another drawback of HTK is that it currently lacks an easy-to-use scripting system; the examples of the resource management (RM) datasets that HTK comes with cover GMM-HMM, adaptation, discriminative training, DNN, and other major technologies, but some scripts are written in tcsh, making them inconvenient to use.
-
Kaldi
Kaldi ( Kaldi · GitHub ) is a comprehensive object-oriented toolkit written in C++. Kaldi is named after the coffee god who is said to have discovered coffee, implying that the toolkit should be as easy, convenient, and popular as coffee. One way to achieve this is by releasing a large number of scripts and examples that are suitable for beginners to run directly, which is why many speech companies in China use Kaldi or learn technology from its source code. Kaldi was jointly developed by Dr. Dan Povey, a former Microsoft Research Institute researcher, and BUT University in the Czech Republic. It is worth mentioning that Dr. Dan Povey is also one of the authors of HTK, so Kaldi and HTK share similar technical ideas. However, after several years of development, Kaldi integrates more technologies than HTK. This is partly due to the different development protocols of HTK: since Kaldi’s user agreement is more open, many new technologies can be integrated quickly. However, advantages and disadvantages often coexist; one drawback of Kaldi is that due to the large number of contributors, there are many branches of code, and sometimes there are unstable or problematic code updates. Therefore, if using the latest code, one may frequently encounter issues, and sometimes there may be compatibility problems between different versions. Thus, when using newer features in Kaldi, it is recommended to compare several branches.
Additionally, Kaldi currently lacks comprehensive manuals, so for beginners, it may be helpful to discuss and consult with experienced users.
-
CNTK
Another very recommended new toolkit is CNTK (Computational Network Toolkit), developed by Microsoft under the leadership of Dr. Yu Dong, which has very powerful neural network functionalities, reportedly superior to many commonly used neural network branches in Kaldi. A major highlight of CNTK is its positioning for combinations of various problems, such as machine translation + speech recognition, etc. However, this also means that CNTK is not a completely specialized speech recognition tool and needs to be used in conjunction with tools like Kaldi. Reports suggest that Microsoft is optimizing and updating CNTK, and the future optimized version is expected to show significant improvements in source code quality and operational efficiency. Furthermore, CNTK is undoubtedly the best supported on Windows platforms among the toolkits mentioned above, aligning more with domestic usage habits.
Courses
http://cs224d.stanford.edu/
Stanford University launched a course on “Deep Learning and Natural Language Processing” in March: CS224d: Deep Learning for Natural Language Processing, taught by the young talent Richard Socher, who is German. He was involved in natural language processing during his undergraduate years and specialized in computer vision during his master’s studies in Germany. He later pursued a PhD at Stanford, studying under renowned figures in NLP and Deep Learning, Chris Manning and Andrew Ng. His doctoral thesis is titled “Recursive Deep Learning for Natural Language Processing and Computer Vision,” marking a perfect culmination of his years of study. After graduation, he co-founded MetaMind as CTO, a rising star startup in the AI field that initially raised $8 million in venture capital and is worth watching.
Speeches
https://v.qq.com/x/page/b0389gr6qsy.html
References:
Wang Yimeng. Research on Key Technologies of Speech Recognition [D]. University of Electronic Science and Technology of China, 2015.
Liu Chao. Deep Learning Methods in Speech Recognition [D]. Tsinghua University, 2016.
Zhang Jianhua. Research on Applications of Deep Learning in Speech Recognition [D]. Beijing University of Posts and Telecommunications, 2015.
Zhou Pan. Research on Acoustic Modeling of Speech Recognition Based on Deep Neural Networks [D]. University of Science and Technology of China, 2014.
Ke Dengfeng, Xu Bo. Basic Issues of Speech Recognition in the Internet Era [J]. Chinese Science: Information Science, 2013, 43(12):1578-1597.
GMIS 2017 | Yu Dong, Deputy Director of Tencent AI Lab: Four Frontier Directions in Speech Recognition Research, Machine Heart.

Baike, Volunteer of Data Pi Research Department, Tsinghua University Graduate Student.
Literature and History Bookworm, Fitness Enthusiast. Love data, love life, greatly love Data Pi~
[Understanding in One Article] Previous Reviews:
Exclusive | Understanding Deep Learning in One Article (Includes Learning Resources)
Exclusive | Understanding Transfer Learning in One Article (Includes Learning Toolkit)
Exclusive | Understanding Big Data Processing Framework in One Article
Exclusive | Understanding Feature Engineering in One Article
Exclusive | Understanding Data Visualization in One Article
Exclusive | Understanding Clustering Algorithms in One Article
Exclusive | Understanding Association Analysis in One Article
Exclusive | Understanding Big Data Computing Framework and Platform in One Article
Exclusive | Understanding Text Recognition (OCR) in One Article
Exclusive | Understanding Regression Analysis in One Article
Exclusive | Understanding Non-relational Databases (NoSQL) in One Article
Editor: Huang Jiyan
Data Pi Research Department Introduction
The Data Pi Research Department was established in early 2017, aiming to create a first-class structured knowledge sharing platform and an active community of data science enthusiasts, dedicated to spreading data thinking, enhancing data capabilities, exploring data value, and realizing the integration of industry, academia, and research!
The logic of the research department is based on structured knowledge and practical experience: organizing and building a structured foundational knowledge network; original step-by-step teaching and practical experience articles; forming professional interest communities for exchanging learning, team practice, and tracking cutting-edge developments. Interest groups are the core of the research department, with each group following the overall knowledge sharing and practical project planning while having its own characteristics: Algorithm Model Group: Actively participating in competitions like Kaggle, original step-by-step teaching series articles; Research and Analysis Group: Investigating big data applications through interviews, exploring the beauty of data products; System Platform Group: Tracking the cutting-edge technologies of big data and AI system platforms, engaging with experts; Natural Language Processing Group: Focusing on practice, actively participating in competitions and planning various text analysis projects; Manufacturing Big Data Group: Upholding the dream of a strong industrial nation, integrating industry, academia, research, and government to explore data value; Data Visualization Group: Merging information with art, exploring the beauty of data, learning to tell stories through visualization; Web Scraping Group: Scraping online information, collaborating with other groups to develop creative projects.
Click the end of the article “Read Original Text” to sign up for Data Pi Research Department Volunteers, there is always a group that suits you~
To ensure the quality of publications and establish a good reputation, Data Pi has now established a “Typo Fund” to encourage readers to actively correct errors.
If you find any errors while reading the article, please leave a message at the end of the article or provide feedback in the background. Upon confirmation by the editor, Data Pi will send an 8.8 yuan red envelope to the reporting reader.
If the same reader points out multiple errors in the same article, the bonus remains unchanged. If different readers point out the same error, only the first reader will be rewarded.
Thank you for your continued attention and support, and we hope you can supervise Data Pi in producing higher quality content.
Reprint Notice
If you need to reprint the article, please do the following: 1. Indicate at the beginning of the text: Reprinted from Data Pi THU (ID: DatapiTHU);2. Attach the Data Pi QR code at the end of the article.
To apply for reprinting, please send an email to [email protected]

The bottom menu of the official account has surprises!
For enterprises and individuals joining the organization, please check “United Federation”
For previous wonderful content, please check “Search in Account”
For joining volunteers or contacting us, please check “About Us”


Click “Read Original Text” to join the organization~