

This article is authored by Mr. Scofield, originally published on the author’s personal blog. Lei Feng Network has obtained authorization for reprint.
0. Introduction
Some time ago, while combining deep learning with NLP, I kept pondering some questions, one of which is the core question: how exactly does deep networks solve various NLP tasks so perfectly? What happens to my data in the NN?
Moreover, many terms like: word vectors, word embedding, distributed representation, word2vec, glove, etc., what do these terms represent, what are their specific relationships, and are they at the same level?
Due to my obsessive-compulsive disorder in pursuing a complete knowledge structure, I kept researching, thinking, and revolving…
Then I felt a bit of progress. I thought, why not share my understanding with peers, regardless of right or wrong, perhaps we can exchange more meaningful insights?
The structure of this article is organized logically in order of concepts, analyzing, comparing, and explaining layer by layer.
Additionally, I would like to mention that the content here is relatively introductory, and some points may not be described accurately due to my current level of understanding… I hope you can be lenient and correct me in the comments!
1. Core Key of DeepNLP: Language Representation
Recently, there is a new term: Deep Learning + NLP = DeepNLP. When conventional machine learning reaches a certain stage, it is gradually overshadowed by the emerging deep learning, which leads a new wave of excitement, as deep learning has advantages over machine learning! So when deep learning enters the NLP field, it naturally sweeps through a batch of ACL papers. And this is indeed the case.
First, let’s mention the data feature representation issue. Data representation is a core problem in machine learning. During the past Machine Learning phase, feature engineering emerged, designing a large number of features to solve the effective representation of data. However, in Deep Learning, don’t even think about it, it’s end-to-end, one step to success, hyper-parameters automatically help you select key feature parameters.
So, how can Deep Learning exert its real power in NLP? Obviously, without discussing how to design a strong network structure or how to introduce NN-based solutions for advanced tasks like sentiment analysis, entity recognition, machine translation, and text generation, we first need to overcome the language representation barrier—how to make language representation a data type that NN can process.
Let’s see how images and speech represent data:

In speech, audio spectrum sequence vectors form a matrix as input fed to the NN for processing, good; in images, pixel matrices flattened into vectors are fed to the NN for processing, good; but in natural language processing? Oh, you might know or not know, each word is represented by a vector! The idea is simple, yes, in fact, it is that simple, but is it really that simple? Maybe not so simple.
Some mention that images and speech belong to relatively naturally low-level data representation forms. In the fields of image and speech, the most basic data is signal data, and we can determine the similarity of signals through some distance metrics. In judging whether two images are similar, we can simply observe the images themselves. However, language, as a tool for expressing high-level abstract thought information developed by humans over millions of years, has highly abstract characteristics. Text is symbolic data, and even synonyms like “microphone” and “话筒” (microphone in Chinese) are difficult to characterize their relationship based on their literal differences (semantic gap phenomenon). It may not be as simple as one plus one to represent them, and more background knowledge is required to determine whether two words are similar.
So can we confidently draw a conclusion: how to effectively represent language sentences is the key premise for NN to exert its powerful fitting computational ability!
2. Types of NLP Word Representation Methods
Next, I will introduce various word representation methods based on the above ideas. According to current developments, word representation is divided into one-hot representation and distributed representation.
1. One-hot Representation
The most intuitive and, so far, the most commonly used word representation method in NLP is One-hot Representation, which represents each word as a long vector. The dimension of this vector is the size of the vocabulary, where most elements are 0, and only one dimension’s value is 1, representing the current word. There is a lot of information about one-hot encoding, and here’s a simple example:
“话筒” is represented as [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] “麦克” is represented as [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
Each word is a 1 in a sea of 0s. This One-hot Representation, if stored sparsely, will be very concise: that is, assigning each word a number ID. For example, in the previous example, “话筒” is recorded as 3, and “麦克” is recorded as 8 (assuming starting from 0). If programming, you can use a hash table to assign a number to each word. This concise representation method, combined with algorithms like maximum entropy, SVM, CRF, etc., has already completed various mainstream tasks in the NLP field well.
Now let’s analyze its shortcomings. 1. The dimension of the vector increases as the number of types of words in a sentence increases; 2. Any two words are isolated, which cannot represent the semantic relationship between words, and this is fatal.
2. Distributed Representation
Traditional one-hot representation only symbolizes words without containing any semantic information. How to incorporate semantics into word representation? The distributional hypothesis proposed by Harris in 1954 provides a theoretical basis for this idea: words with similar contexts have similar semantics. Firth further elaborated and clarified the distributional hypothesis in 1957: the meaning of a word is determined by its context (a word is characterized by the company it keeps).
So far, based on the distributional hypothesis, word representation methods can be divided into three categories according to different modeling: matrix-based distributional representation, clustering-based distributional representation, and neural network-based distributional representation. Although these different distributional representation methods use different techniques to obtain word representations, since they are all based on the distributional hypothesis, their core ideas consist of two parts: 1. Choosing a way to describe the context; 2. Choosing a model to characterize a certain word (referred to as the “target word”) and its relationship with its context.
3. NLP Language Models
Before detailing the distributed representation of words, we need to clarify a key concept in NLP: language models. Language models include grammatical language models and statistical language models. Generally, we refer to statistical language models. The reason for placing language models before word representation methods is that the latter will soon use this concept.
Statistical language models treat language (the sequence of words) as a random event and assign corresponding probabilities to describe its likelihood of belonging to a certain language set. Given a vocabulary set V, for a sequence S = ⟨w1, · · · , wT ⟩ ∈ Vn composed of words from V, the statistical language model assigns a probability P(S) to this sequence to measure the confidence that S conforms to the grammatical and semantic rules of natural language.
In simple terms, a language model calculates the probability of a sentence. What is the significance? The higher the scoring probability of a sentence, the more it indicates that it is a more natural sentence spoken by people.
It’s that simple. Common statistical language models include N-gram models, with the most common being unigram, bigram, trigram, etc. Formally, the role of a statistical language model is to determine a probability distribution P(w1; w2; :::; wm) for a string of length m, indicating its likelihood of existence, where w1 to wm represent the various words in this text. In practical solving processes, the probability value is usually calculated using the following formula:
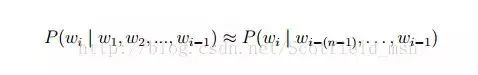
Through these methods, we can also retain some word order information, thus capturing the context information of a word.
Specific details of language models are common knowledge, please search for them yourself.
4. Distributed Representation of Words
1. Matrix-based Distributional Representation
Matrix-based distributional representation is often referred to as distributional semantic models. In this representation, a row in the matrix becomes the representation of the corresponding word, which describes the distribution of that word’s context. Since the distributional hypothesis states that words with similar contexts have similar semantics, in this representation, the semantic similarity between two words can be directly transformed into the spatial distance of two vectors.
A common model is the Global Vector model (GloVe), which is a method of obtaining word representations by decomposing a “word-word” matrix, belonging to matrix-based distributional representation.
2. Neural Network-based Distributional Representation, Word Embedding
Neural network-based distributional representation is generally called word vectors, word embedding, or distributed representation. This is the protagonist of today’s discussion.
The neural network word vector representation technique models the context and the relationship between the context and the target word through neural network technology. Due to the flexibility of neural networks, the greatest advantage of this method is that it can represent complex contexts. In the previous matrix-based distributional representation method, the most commonly used context is words. If n-grams containing word order information are used as context, as n increases, the total number of n-grams will grow exponentially, leading to the curse of dimensionality. However, when representing n-grams, neural networks can combine n words in various ways, causing the number of parameters to increase only linearly. With this advantage, neural network models can model more complex contexts, incorporating richer semantic information into word vectors.
5. Word Embedding
1. Concept
Neural network-based distributional representation is also known as word vectors or word embedding. The neural network word vector model, like other distributional representation methods, is based on the distributional hypothesis, with the core still being the representation of context and the modeling of the relationship between context and the target word.
As mentioned earlier, to choose a model that characterizes a certain word (referred to as the “target word”) and its relationship with its context, we need to capture the context information of a word in word vectors. At the same time, we happen to mention that statistical language models have the capability to capture context information. Therefore, the most natural approach to building the relationship between context and the target word is to use language models. Historically, early word vectors were merely by-products of neural network language models.
In 2001, Bengio et al. formally proposed the Neural Network Language Model (NNLM), which learned word vectors while learning the language model. So please note: word vectors can be considered as by-products of training language models using neural networks.
2. Understanding
As mentioned, the one-hot representation has the disadvantage of excessive dimensionality, so now we make some improvements to the vector: 1. Change each element of the vector from integer to floating-point, resulting in a representation across the entire real number range; 2. Compress the originally sparse, huge dimensions into a smaller dimensional space, as illustrated:
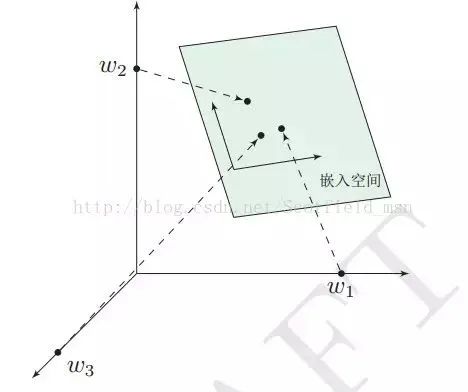
This is also the reason why word vectors are also called word embeddings.
6. Neural Network Language Models and Word2Vec
Now, we have a rational understanding of the hierarchical relationship of distributed representation and word embedding, so how does this relate to word2vec?
1. Neural Network Language Models
As mentioned, training language models through neural networks can yield word vectors. So, what types of neural network language models are there? To my knowledge, there are roughly the following:
● Neural Network Language Model, NNLM ● Log-Bilinear Language Model, LBL ● Recurrent Neural Network based Language Model, RNNLM ● The C&W model proposed by Collobert and Weston in 2008 ● The CBOW (Continuous Bag of Words) and Skip-gram models proposed by Mikolov et al.
At this point, some may see two familiar terms: CBOW and Skip-gram. Those who have seen word2vec should be familiar with this. Let’s continue.
2. Word2Vec and CBOW, Skip-gram
Now we formally introduce the hottest term: word2vec.
The five neural network language models mentioned above are only logical concepts, and we need to implement them through design, and the tools to implement the CBOW (Continuous Bag of Words) and Skip-gram language models are the well-known word2vec! Additionally, the C&W model is implemented using SENNA.
By the way, let’s talk about these two language models. A statistical language model calculates the probability of a certain word occurring based on several preceding words. CBOW, as the name suggests, calculates the probability of a certain word based on the C preceding words or the C continuous words before and after it. The Skip-Gram Model, on the other hand, calculates the probabilities of the words that appear before and after based on a certain word.
For example, in the sentence “I love Beijing Tiananmen,” if we focus on the word “love” and C=2, its context would be “I” and “Beijing Tiananmen.” The CBOW model takes the one-hot representation of “I” and “Beijing Tiananmen” as input, which are C number of 1xV vectors, and multiplies them with the same VxN coefficient matrix W1 to obtain C number of 1xN hidden layers, then averages these C layers to compute a single hidden layer. This process is also referred to as a linear activation function (is this an activation function? It’s clearly not activated). Then, we multiply this hidden layer with another NxV coefficient matrix W2 to obtain a 1xV output layer, where each element represents the posterior probability of each word in the vocabulary. The output layer needs to be compared with the ground truth, which is the one-hot form of “love,” to calculate the loss. It’s important to note that V is usually a large number, like millions, making it quite time-consuming to compute. Besides, only the element corresponding to “love” must be included in the loss calculation. Word2vec uses Huffman coding-based hierarchical softmax to filter out some impossible words, and then negative sampling further eliminates some negative sample words, reducing the time complexity from O(V) to O(logV). The training process for Skip-gram is similar, except the input and output are reversed.
Additionally, the training methods for word embeddings can be roughly divided into two categories: one category is unsupervised or weakly supervised pre-training; the other is end-to-end supervised training. Unsupervised or weakly supervised pre-training includes word2vec and auto-encoder as representatives. This category of models does not require a large number of manually labeled samples to obtain reasonably good embedding vectors. However, due to the lack of task orientation, they may still be distant from the problems we need to solve. Therefore, we often fine-tune the entire model using a small amount of manually labeled samples after obtaining the pre-trained embedding vectors.
In contrast, end-to-end supervised models have gained increasing attention in recent years. Compared to unsupervised models, end-to-end models are often more complex in structure. Additionally, due to having clear task orientation, the embedding vectors learned by end-to-end models are often more accurate. For example, a deep neural network composed of an embedding layer and several convolutional layers can be used for sentiment classification of sentences, learning more semantically rich word vector representations.
3. My Understanding of Word Embedding
Now, word vectors can reduce dimensionality while capturing the context information of the current word in the sentence (represented by the relationship of distances before and after), so we are very confident and satisfied to use them as NN inputs to represent language sentences.
One practical suggestion: when you are working on a specific NLP task that requires word vectors, I recommend: either 1. use pre-trained word vectors, but ensure they are from the same domain of content; or 2. train your own word vectors. I suggest the former because… there are too many pitfalls.
7. Conclusion
At this point, I actually didn’t intend to continue, nor did I plan to explain the mathematical principles and details of word2vec, because I found that there are already too many articles online explaining word2vec, almost all of which are the same. So I have no need to copy another one.
Therefore, to understand the details of word2vec, CBOW, and Skip-gram, please search carefully. I believe that with a solid understanding of this series of contextual knowledge, you will find it much easier to read detailed articles related to word2vec.
This also reflects a larger issue, namely the lack of critical thinking and originality in online articles.
Simply searching for “word2vec” or “word vectors” online yields a plethora of articles explaining the mathematical formulas of word2vec, CBOW, and Skip-gram, and they are all so similar… but what is most incomprehensible is that hardly anyone discusses the context of their emergence, existence, development process, and their position in the overall related technology framework, etc. This frustrates me…
In my personal methodology, a well-structured knowledge framework with complete context is often much more important than detailed knowledge points. Once you build a complete knowledge structure, all you need to do is fill in the fragmented details; however, the reverse is not true. Merely piling up knowledge will only confuse your thinking and get you nowhere.
So here I also urge fellow bloggers to fully utilize their initiative, actively create what is missing, and share unique insights, contributing to the promotion of Chinese online blogs and the CS field! I mean, even if you copy someone else’s original content, it’s best to digest it and share it with your own insights!
“How to Generate a Good Word Embedding?” Siwei Lai, Kang Liu, Liheng Xu, Jun Zhao “Research on Semantic Vector Representation Methods for Words and Documents Based on Neural Networks,” Lai Siwei “Distributed Representation Learning for Natural Language Processing,” Qiu Xipeng “Deep Learning Practical Word2Vec” http://www.cnblogs.com/iloveai/p/word2vec.html http://www.hankcs.com/nlp/word2vec.html http://licstar.NET/archives/328 https://zhuanlan.zhihu.com/p/22477976 http://blog.csdn.Net/itplus/article/details/37969519 http://www.tuicool.com/articles/fmuyamf http://licstar.net/archives/620#comment-1542 http://blog.csdn.net/ycheng_sjtu/article/details/48520293
