0. Introduction
This article introduces the “Diffusion Policy,” a new method for generating robot behaviors that represents the robot’s visuomotor policy as a conditional denoising diffusion process. It has been benchmarked across 15 different tasks in 4 different robot manipulation benchmarks, showing consistent superiority over existing state-of-the-art robot learning methods, with an average improvement of 46.9%. The Diffusion Policy can learn the gradient of the action-distribution score function and iteratively optimize this gradient field during inference through a series of stochastic Langevin dynamics steps.
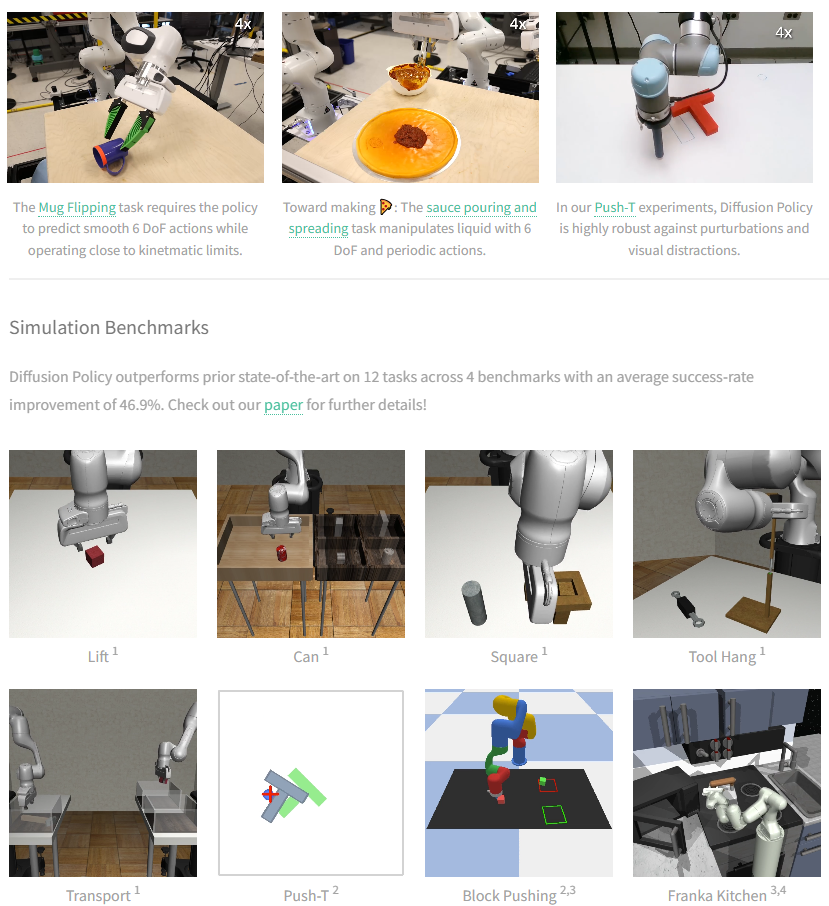
We found that the diffusion formulation has significant advantages when applied to robotic policies, including the ability to elegantly handle multimodal action distributions, suitability for high-dimensional action spaces, and impressive training stability. To fully unleash the potential of diffusion models in physical robot visuomotor policy learning, this article proposes a series of key technical contributions, including receding horizon control (MPC control), visual conditioning, and time-series diffusion transformers. The related code can be found on GitHub.
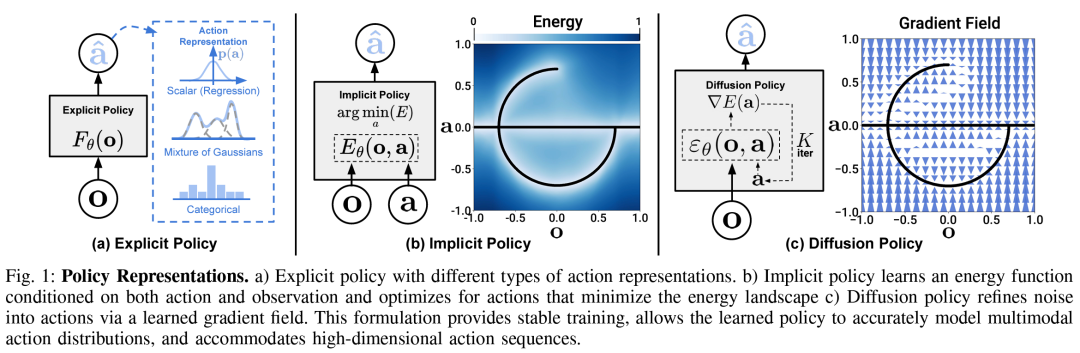
1. Log Significance
To reproduce the experiments in Tables I, II, and IV of this paper, we provide:
1. A config.yaml file containing all parameters needed to reproduce the experiments.
2. Detailed training/evaluation logs.json.txt for each training step.
3. The best epoch checkpoints for each run, marked as *-test_mean_score=*.ckpt and the latest checkpoint latest.ckpt.
The experimental logs are hosted on our website, formatted as a nested directory: https://diffusion-policy.cs.columbia.edu/data/experiments////
In each experiment directory, you can find:
.├── config.yaml├── metrics│ └── logs.json.txt├── train_0│ ├── checkpoints│ │ ├── epoch=0300-test_mean_score=1.000.ckpt│ │ └── latest.ckpt│ └── logs.json.txt├── train_1│ ├── checkpoints│ │ ├── epoch=0250-test_mean_score=1.000.ckpt│ │ └── latest.ckpt│ └── logs.json.txt└── train_2 ├── checkpoints │ ├── epoch=0250-test_mean_score=1.000.ckpt │ └── latest.ckpt └── logs.json.txtThe metrics/logs.json.txt file summarizes all evaluation metrics from the three training runs every 50 epochs. The numbers reported in the paper correspond to the max and k_min_train_loss aggregation keywords. We can find these on the web page and check the content saved within.
To download all files in the subdirectory, you can use:
wget --recursive --no-parent --no-host-directories --relative --reject="index.html*" https://diffusion-policy.cs.columbia.edu/data/experiments/low_dim/square_ph/diffusion_policy_cnnWe can clearly see through tree that it aligns with what we discussed above.
2. Environment Installation
2.1 Simulation Implementation
To reproduce our simulation benchmark results, please install our conda environment on a Linux machine with an Nvidia GPU. On Ubuntu 20.04, you need to install the following apt packages to support mujoco:
sudo apt install -y libosmesa6-dev libgl1-mesa-glx libglfw3 patchelfWe use conda here:
git clone https://github.com/real-stanford/diffusion_policy.gitcd diffusion_policy/conda env create -f conda_environment.yaml2.2 Real Robot
Hardware (taking Push-T as an example):
1x UR5-CB3 or UR5e (requires RTDE interface)
2x RealSense D415
1x 3Dconnexion SpaceMouse (for remote control)
1x Millibar Robotics manual tool changer (only needed on the robot side)
1x 3D printed end effector
1x 3D printed T-block
USB-C cable and screws for RealSense
Software:
Ubuntu 22.04.3 (tested)
Mujoco dependencies: sudo apt install libosmesa6-dev libglfw3 patchelf — 20.04 requires adding libgl1-mesa-glx
RealSense SDK
SpaceMouse dependencies: sudo apt install libspnav-dev spacenavd; sudo systemctl start spacenavd
conda environment mamba env create -f conda_environment_real.yaml
3. Reproducing Simulation Benchmark Results
3.1 Download Training Data
Create a data subdirectory in the repo root directory:
cd diffusion_policymkdir data && cd dataDownload the corresponding zip file from https://diffusion-policy.cs.columbia.edu/data/training/:
wget https://diffusion-policy.cs.columbia.edu/data/training/pusht.zipExtract the training data:
unzip pusht.zip && rm -f pusht.zip && cd ..Obtain the corresponding experiment configuration file:
wget -O image_pusht_diffusion_policy_cnn.yaml https://diffusion-policy.cs.columbia.edu/data/experiments/image/pusht/diffusion_policy_cnn/config.yaml
3.2 Running a Single Seed
Activate the conda environment and log in to wandb (if not logged in yet).
conda activate robodiffwandb loginStart training with seed 42 on GPU 0.
python train.py --config-dir=. --config-name=image_pusht_diffusion_policy_cnn.yaml training.seed=42 training.device=cuda:0 hydra.run.dir='data/outputs/${now:%Y.%m.%d}/${now:%H.%M.%S}_${name}_${task_name}'
This will create a directory formatted as data/outputs/yyyy.mm.dd/hh.mm.ss__, where configurations, logs, and checkpoints will be written. The policy will be evaluated every 50 epochs, with the success rate recorded as test/mean_score in wandb, along with some videos of the rounds.
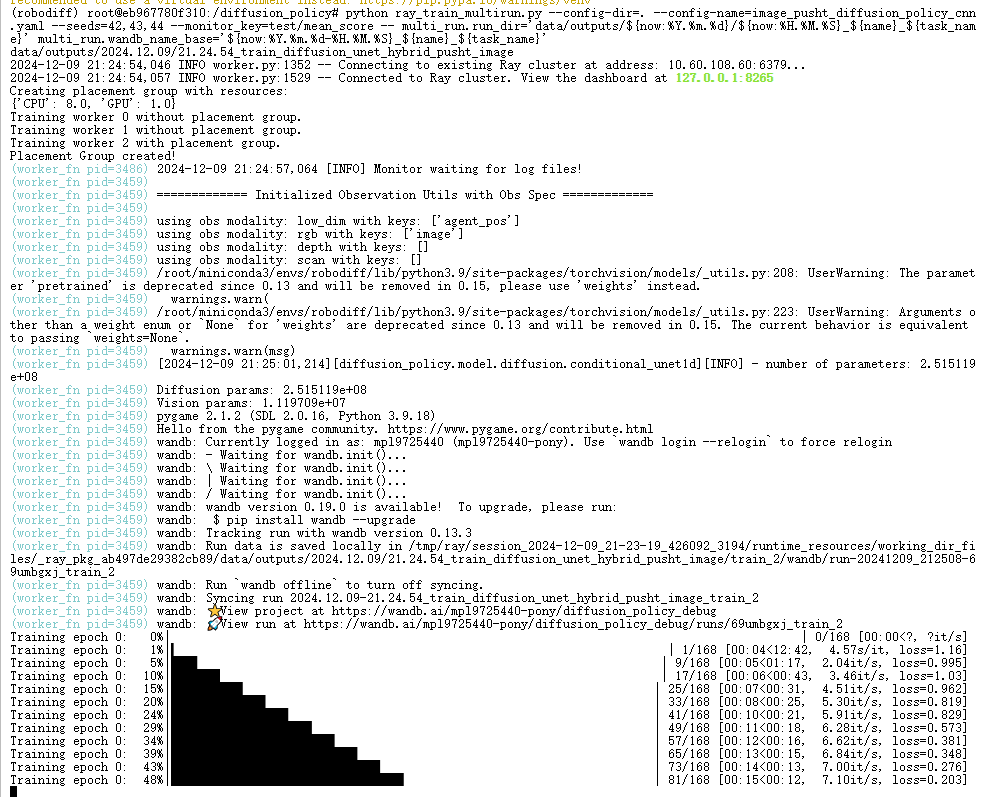
3.3 Running Multiple Seeds
Start a local ray cluster. For large-scale experiments, you might want to set up an AWS cluster that supports auto-scaling. All other commands remain unchanged.
export CUDA_VISIBLE_DEVICES=0,1,2 # Choose GPUs managed by ray clusterray start --head --num-gpus=3Start the ray client, which will start 3 training workers (3 seeds) and 1 metric monitoring worker. (Of course, you can also choose to set up 1 GPU; for more details, refer to the installation and usage of the distributed framework Ray in Python (https://www.cnblogs.com/dechinphy/p/18384118/ray))
python ray_train_multirun.py --config-dir=. --config-name=image_pusht_diffusion_policy_cnn.yaml --seeds=42,43,44 --monitor_key=test/mean_score -- multi_run.run_dir='data/outputs/${now:%Y.%m.%d}/${now:%H.%M.%S}_${name}_${task_name}' multi_run.wandb_name_base='${now:%Y.%m.%d-%H.%M.%S}_${name}_${task_name}'
In addition to the wandb logs recorded by each training worker, the metric monitoring worker will also log to the wandb project diffusion_policy_metrics, recording the aggregated metrics from all 3 training runs. Local configurations, logs, and checkpoints will be written to data/outputs/yyyy.mm.dd/hh.mm.ss__, with the directory structure identical to our training logs. We can check the situation in wandb.ai:
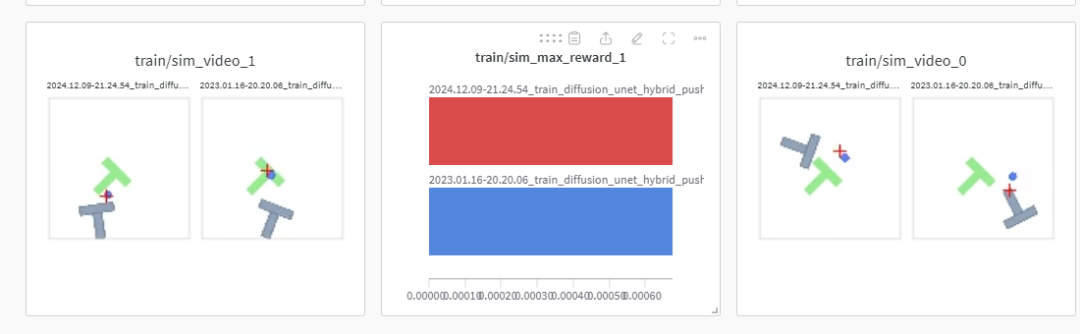
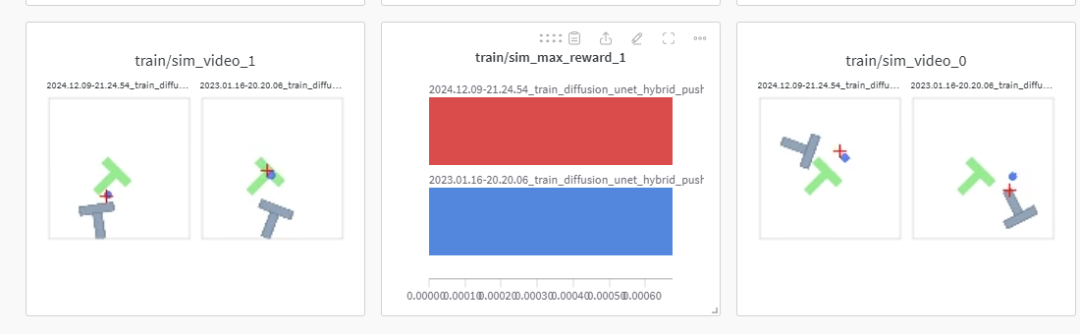
3.4 Evaluating Pre-trained Checkpoints
If needed, students can download a checkpoint from the published training log folder, for example https://diffusion-policy.cs.columbia.edu/data/experiments/low_dim/pusht/diffusion_policy_cnn/train_0/checkpoints/epoch=0550-test_mean_score=0.969.ckpt.
Run the evaluation script:
python eval.py --checkpoint data/0550-test_mean_score=0.969.ckpt --output_dir data/pusht_eval_output --device cuda:0eval_log.json contains the metrics recorded in wandb during training:
cat data/pusht_eval_output/eval_log.json{ "test/mean_score": 0.9150393806777066, "test/sim_max_reward_4300000": 1.0, "test/sim_max_reward_4300001": 0.9872969750774386,... "train/sim_video_1": "data/pusht_eval_output//media/2fo4btlf.mp4"}We will not elaborate here; generally, readers can evaluate the ckpt after training is completed.
4. Key Functions and Feature Descriptions
4.1 Base Workspace
4.1.1 Base Class BaseWorkspace
Purpose:
Manage configurations during the training process.
Save and load checkpoints and snapshots.
Member variables:
include_keys = tuple()exclude_keys = tuple()Explanation: Defines two class variables to specify the property keys to be included or excluded when saving checkpoints.
Methods:
__init__ method
def __init__(self, cfg: OmegaConf, output_dir: Optional[str]=None): self.cfg = cfg self._output_dir = output_dir self._saving_thread = NonePurpose: Defines the initialization method, receiving an OmegaConf type cfg parameter and an optional output_dir to save as a member variable.
output_dir property
@propertydef output_dir(self): output_dir = self._output_dir if output_dir is None: output_dir = HydraConfig.get().runtime.output_dir return output_dirUsing @property to turn the output_dir method into a read-only property, allowing access via instance.output_dir.
Purpose: Users can obtain the output directory of this instance.
run method
def run(self): passTo be overridden in subclasses for specific implementation.
save_checkpoint method
def save_checkpoint(self, path=None, tag='latest', exclude_keys=None, include_keys=None, use_thread=True): if path is None: path = pathlib.Path(self.output_dir).joinpath('checkpoints', f'{tag}.ckpt') else: path = pathlib.Path(path) if exclude_keys is None: exclude_keys = tuple(self.exclude_keys) if include_keys is None: include_keys = tuple(self.include_keys) + ('_output_dir',) path.parent.mkdir(parents=False, exist_ok=True) payload = { 'cfg': self.cfg, 'state_dicts': dict(), 'pickles': dict() } for key, value in self.__dict__.items(): if hasattr(value, 'state_dict') and hasattr(value, 'load_state_dict'): # modules, optimizers and samplers etc if key not in exclude_keys: if use_thread: payload['state_dicts'][key] = _copy_to_cpu(value.state_dict()) else: payload['state_dicts'][key] = value.state_dict() elif key in include_keys: payload['pickles'][key] = dill.dumps(value) if use_thread: self._saving_thread = threading.Thread( target=lambda : torch.save(payload, path.open('wb'), pickle_module=dill)) self._saving_thread.start() else: torch.save(payload, path.open('wb'), pickle_module=dill) return str(path.absolute())Parameters:
path: string, optional, specifies the save path.
tag: label for identifying the checkpoint, default is latest.
exclude_keys: list of keys, optional, specifies the properties to be excluded during saving.
include_keys: list of keys, optional, specifies additional properties to be included during saving.
use_thread: indicates whether to use a thread for the save operation, default is True.
Path handling:
if path is None: path = pathlib.Path(self.output_dir).joinpath('checkpoints', f'{tag}.ckpt')else: path = pathlib.Path(path)If no path is specified, the default save path is constructed, located at output_dir/checkpoints/{tag}.ckpt, which saves a checkpoint file (.ckpt) at that path.
In machine learning and deep learning, checkpoint files are used to save the model state during training. This allows for resuming training from the most recent checkpoint if interrupted, rather than starting from scratch. Checkpoint files are also commonly used to save the trained model for subsequent evaluation, testing, or deployment.
Handling exclude_keys and include_keys
if exclude_keys is None: exclude_keys = tuple(self.exclude_keys)if include_keys is None: include_keys = tuple(self.include_keys) + ('_output_dir',)If these two variables are not specified, the class variables are used, and include_keys should also contain the _output_dir attribute.
Creating checkpoint directory
path.parent.mkdir(parents=False, exist_ok=True)Initializing payload
payload = { 'cfg': self.cfg, 'state_dicts': dict(), 'pickles': dict()}Creating a dictionary to save configurations, state dictionaries, and serialized objects.
Iterate through instance properties and collect the data to be saved:
for key, value in self.__dict__.items(): if hasattr(value, 'state_dict') and hasattr(value, 'load_state_dict'): # modules, optimizers and samplers etc if key not in exclude_keys: if use_thread: payload['state_dicts'][key] = _copy_to_cpu(value.state_dict()) else: payload['state_dicts'][key] = value.state_dict() elif key in include_keys: payload['pickles'][key] = dill.dumps(value)If the attribute has a state dictionary state_dict and a load state dictionary method load_state_dict (usually for models or optimizers), and is not in exclude_keys, save it (to CPU).
If the attribute is in include_keys, use dill to serialize and save it to payload[‘pickles’].
Save the checkpoint:
if use_thread: self._saving_thread = threading.Thread( target=lambda : torch.save(payload, path.open('wb'), pickle_module=dill)) self._saving_thread.start()else: torch.save(payload, path.open('wb'), pickle_module=dill)Based on the status of use_thread, decide whether to enable a new thread for saving the checkpoint.
Return the absolute path of the save:
return str(path.absolute())Function of save_checkpoint method: Save the current workspace’s checkpoint.
get_checkpoint_path method
def get_checkpoint_path(self, tag='latest'): return pathlib.Path(self.output_dir).joinpath('checkpoints', f'{tag}.ckpt')tag: label for specifying the saved checkpoint, default is ‘latest’.
Parameters:
Purpose: Return a path pointing to the checkpoint constructed using the pathlib module.
load_payload method
def load_payload(self, payload, exclude_keys=None, include_keys=None, **kwargs): if exclude_keys is None: exclude_keys = tuple() if include_keys is None: include_keys = payload['pickles'].keys() for key, value in payload['state_dicts'].items(): if key not in exclude_keys: self.__dict__[key].load_state_dict(value, **kwargs) for key in include_keys: if key in payload['pickles']: self.__dict__[key] = dill.loads(payload['pickles'][key])Parameters:
payload: dictionary containing saved data.
exclude_keys: properties to exclude during loading (optional).
include_keys: additional properties to include during loading (optional).
**kwargs: other keyword arguments passed to load_state_dict method.
Handling exclude_keys and include_keys
if exclude_keys is None: exclude_keys = tuple()if include_keys is None: include_keys = payload['pickles'].keys()If not specified, exclude_keys defaults to empty, and include_keys defaults to the keys of serialized elements in the data dictionary.
Loading state dictionaries
for key, value in payload['state_dicts'].items(): if key not in exclude_keys: self.__dict__[key].load_state_dict(value, **kwargs)If the key in payload[‘state_dicts’] is not excluded, call the corresponding object’s load_state_dict method to load the state dictionary.
load_state_dict method is a method in deep learning frameworks (like PyTorch) for models or modules, used to load serialized state dictionaries into models or modules.
Loading serialized objects
for key in include_keys: if key in payload['pickles']: self.__dict__[key] = dill.loads(payload['pickles'][key])Use dill to deserialize and assign to the corresponding instance property.
Purpose: Load a serialized payload dictionary back into the current instance’s properties.
load_checkpoint method
def load_checkpoint(self, path=None, tag='latest', exclude_keys=None, include_keys=None, **kwargs): if path is None: path = self.get_checkpoint_path(tag=tag) else: path = pathlib.Path(path) payload = torch.load(path.open('rb'), pickle_module=dill, **kwargs) self.load_payload(payload, exclude_keys=exclude_keys, include_keys=include_keys) return payloadParameters:
path: checkpoint path.
tag: checkpoint label, default is ‘latest’.
exclude_keys: properties to exclude during loading (optional).
include_keys: additional properties to include during loading (optional).
**kwargs: other keyword arguments passed to torch.load and load_payload methods.
Path handling
if path is None: path = self.get_checkpoint_path(tag=tag)else: path = pathlib.Path(path)Loading checkpoint data
payload = torch.load(path.open('rb'), pickle_module=dill, **kwargs)Use torch.load to load the checkpoint file, with dill as the serialization module, and ‘rb’ parameter indicating binary reading.
Loading payload data:
self.load_payload(payload, exclude_keys=exclude_keys, include_keys=include_keys)Call the previous load_payload method to apply the loaded data to the current instance.
Return payload
return payloadPurpose: Load checkpoint data.
create_from_checkpoint class method
@classmethoddef create_from_checkpoint(cls, path, exclude_keys=None, include_keys=None, **kwargs): payload = torch.load(open(path, 'rb'), pickle_module=dill) instance = cls(payload['cfg']) instance.load_payload( payload=payload, exclude_keys=exclude_keys, include_keys=include_keys, **kwargs) return instance@classmethod
Defines a class method using the @classmethod decorator, which can be called through the class itself without instantiation. For more details, see the tutorial on @classmethod decorator(https://www.runoob.com/python/python-func-classmethod.html).
Parameters:
cls: the class itself.
path: checkpoint path.
tag: checkpoint label, default is ‘latest’.
exclude_keys: properties to exclude during loading (optional).
include_keys: additional properties to include during loading (optional).
**kwargs: other keyword arguments passed to load_payload method.
Loading checkpoint data
payload = torch.load(open(path, 'rb'), pickle_module=dill)Create an instance and load data
instance = cls(payload['cfg'])instance.load_payload( payload=payload, exclude_keys=exclude_keys, include_keys=include_keys, **kwargs)Using the loaded configuration payload to create a new instance and apply the loaded data to the new instance.
Return instance
return instancePurpose: Create a new instance from a checkpoint.
save_snapshot method
def save_snapshot(self, tag='latest'): path = pathlib.Path(self.output_dir).joinpath('snapshots', f'{tag}.pkl') path.parent.mkdir(parents=False, exist_ok=True) torch.save(self, path.open('wb'), pickle_module=dill) return str(path.absolute())tag: snapshot label, default is ‘latest’.
Parameters
Purpose: Serialize and save the entire BaseWorkSpace instance to the specified path.
create_from_snapshot class method
@classmethoddef create_from_snapshot(cls, path): return torch.load(open(path, 'rb'), pickle_module=dill)Parameters
cls: the class itself.
path: specifies the snapshot file path.
Purpose: Load the snapshot file from the specified path.
4.1.2 Helper Function _copy_to_cpu
def _copy_to_cpu(x): if isinstance(x, torch.Tensor): return x.detach().to('cpu') elif isinstance(x, dict): result = dict() for k, v in x.items(): result[k] = _copy_to_cpu(v) return result elif isinstance(x, list): return [_copy_to_cpu(k) for k in x] else: return copy.deepcopy(x)Parameters
x: input data, which can be a tensor, dictionary, list, etc.
Handling torch.Tensor
if isinstance(x, torch.Tensor): return x.detach().to('cpu')If the input data is a tensor, create a new tensor that shares memory with the current tensor but does not require gradient computation, move it to CPU and return it.
Handling dict
elif isinstance(x, dict): result = dict() for k, v in x.items(): result[k] = _copy_to_cpu(v) return resultIf the input data is a dictionary, recursively pass each value to _copy_to_cpu for processing, then return the new dictionary.
Handling list
elif isinstance(x, list): return [_copy_to_cpu(k) for k in x]If the input data is a list, recursively process it using list comprehension and return it.
Handling other types
else: return copy.deepcopy(x)If the data is of another type, create an independent copy and return it.
4.1.3 Features
1. Use Hydra and OmegaConf to manage and access configuration parameters.
2. Save and load checkpoints.
Supports saving checkpoints of the current state, including configurations, model state dictionaries, and other serialized objects.
Supports managing different checkpoint versions through labels.
Provides a threaded saving option to avoid blocking the main thread.
3. Save and load snapshots, supporting saving and loading the complete state of the workspace for quick recovery, assuming code remains unchanged, suitable for rapid experimentation in research.
4. The _copy_to_cpu helper function moves tensors from GPU to CPU within complex data structures for serialization and saving.
5. Allows customization of saved and loaded content through exclude_keys and include_keys, adapting to different needs and scenarios.
4.2 Train Diffusion Unet Hybrid Workspace
OmegaConf.register_new_resolver("eval", eval, replace=True)By using OmegaConf.register_new_resolver method, register a new resolver to dynamically resolve eval() function in configuration files.
4.2.1 TrainDiffusionUnetHybridWorkspace(BaseWorkSpace)
Derived class from BaseWorkSpace for managing training (hybrid input) Unet networks.
Member variables:
include_keys = ['global_step', 'epoch']Methods:
__init__ method:
The constructor initializes the class, setting a random seed to ensure reproducibility of results.
def __init__(self, cfg: OmegaConf, output_dir=None): super().__init__(cfg, output_dir=output_dir) # set seed seed = cfg.training.seed torch.manual_seed(seed) np.random.seed(seed) random.seed(seed)torch.manual_seed, np.random.seed, random.seed set the seed for torch, NumPy, and Python’s built-in random number generator respectively.
Model and EMA initialization
self.model: DiffusionUnetHybridImagePolicy = hydra.utils.instantiate(cfg.policy)self.ema_model: DiffusionUnetHybridImagePolicy = Noneif cfg.training.use_ema: self.ema_model = copy.deepcopy(self.model)Call the hydra library’s instantiate function to instantiate DiffusionUnetHybridImagePolicy based on cfg.policy.
EMA (Exponential Moving Average), a weighted moving average method to improve model robustness, defaults to None.
If the configuration specifies using EMA, deep copy the model to self.ema_model to ensure self.model and self.ema_model are independent.
Optimizer initialization
self.optimizer = hydra.utils.instantiate( cfg.optimizer, params=self.model.parameters())Call the hydra library’s instantiate function to instantiate the optimizer based on cfg.policy and pass the model’s parameters to the optimizer.
Initialize training state
# configure training stateself.global_step = 0self.epoch = 0run method:
Start the training loop. If the configuration enables the resume option, resume training from the most recent checkpoint.
def run(self): cfg = copy.deepcopy(self.cfg) # resume training if cfg.training.resume: lastest_ckpt_path = self.get_checkpoint_path() if lastest_ckpt_path.is_file(): print(f"Resuming from checkpoint {lastest_ckpt_path}") self.load_checkpoint(path=lastest_ckpt_path)Several methods in BaseWorkSpace are reflected here.
Configure dataset
dataset: BaseImageDatasetdataset = hydra.utils.instantiate(cfg.task.dataset)assert isinstance(dataset, BaseImageDataset)train_dataloader = DataLoader(dataset, **cfg.dataloader)normalizer = dataset.get_normalizer()Use hydra to configure the dataset.
Load training data using DataLoader.
**cfg.dataloader unpacks the key-value pairs in cfg.dataloader as keyword arguments.
Get the data normalizer.
Configure the validation dataset
val_dataset = dataset.get_validation_dataset()val_dataloader = DataLoader(val_dataset, **cfg.val_dataloader)Configure the validation dataset.
Load the validation dataset using DataLoader.
Normalize the model and ema_model
self.model.set_normalizer(normalizer)if cfg.training.use_ema: self.ema_model.set_normalizer(normalizer)Ensure consistency in input data processing.
Configure the learning rate scheduler
lr_scheduler = get_scheduler( cfg.training.lr_scheduler, optimizer=self.optimizer, num_warmup_steps=cfg.training.lr_warmup_steps, num_training_steps=( len(train_dataloader) * cfg.training.num_epochs) \\ // cfg.training.gradient_accumulate_every, last_epoch=self.global_step-1)Control the learning rate variation based on parameters in the configuration file.
ema_model configuration
ema: EMAModel = Noneif cfg.training.use_ema: ema = hydra.utils.instantiate( cfg.ema, model=self.ema_model)Configure the environment runner
env_runner: BaseImageRunnerenv_runner = hydra.utils.instantiate( cfg.task.env_runner, output_dir=self.output_dir)assert isinstance(env_runner, BaseImageRunner)Responsible for executing tasks in the simulation environment.
Configure experiment logging
wandb_run = wandb.init( dir=str(self.output_dir), config=OmegaConf.to_container(cfg, resolve=True), **cfg.logging)wandb.config.update( { "output_dir": self.output_dir, })Use wandb to configure experiment logging, visualizing various states and parameters during training.
Checkpoint management configuration
topk_manager = TopKCheckpointManager( save_dir=os.path.join(self.output_dir, 'checkpoints'), **cfg.checkpoint.topk)Configure the checkpoint manager to save the best checkpoints during training.
Transfer device and optimizer to GPU
device = torch.device(cfg.training.device) self.model.to(device) if self.ema_model is not None: self.ema_model.to(device) optimizer_to(self.optimizer, device)Debug configuration
if cfg.training.debug:cfg.training.num_epochs = 2cfg.training.max_train_steps = 3cfg.training.max_val_steps = 3cfg.training.rollout_every = 1cfg.training.checkpoint_every = 1cfg.training.val_every = 1cfg.training.sample_every = 1Training process
log_path = os.path.join(self.output_dir, 'logs.json.txt')with JsonLogger(log_path) as json_logger: for local_epoch_idx in range(cfg.training.num_epochs): step_log = dict() # ========= train for this epoch ========== train_losses = list() with tqdm.tqdm(train_dataloader, desc=f"Training epoch {self.epoch}", leave=False, mininterval=cfg.training.tqdm_interval_sec) as tepoch: for batch_idx, batch in enumerate(tepoch): # device transfer batch = dict_apply(batch, lambda x: x.to(device, non_blocking=True)) if train_sampling_batch is None: train_sampling_batch = batch # compute loss raw_loss = self.model.compute_loss(batch) loss = raw_loss / cfg.training.gradient_accumulate_every loss.backward() # step optimizer if self.global_step % cfg.training.gradient_accumulate_every == 0: self.optimizer.step() self.optimizer.zero_grad() lr_scheduler.step() # update ema if cfg.training.use_ema: ema.step(self.model)For each loop batch
Move each batch data to GPU.
Compute loss, and backpropagate gradients.
When the gradient accumulation step is met, update the optimizer weights and reset gradients.
If EMA is enabled, update the EMA model.
Log and accumulate losses
raw_loss_cpu = raw_loss.item()tepoch.set_postfix(loss=raw_loss_cpu, refresh=False)train_losses.append(raw_loss_cpu)step_log = { 'train_loss': raw_loss_cpu, 'global_step': self.global_step, 'epoch': self.epoch, 'lr': lr_scheduler.get_last_lr()[0]}is_last_batch = (batch_idx == (len(train_dataloader)-1))if not is_last_batch: # log of last step is combined with validation and rollout wandb_run.log(step_log, step=self.global_step) json_logger.log(step_log) self.global_step += 1if (cfg.training.max_train_steps is not None) \\ and batch_idx >= (cfg.training.max_train_steps-1): breakRecord losses and learning rates, logging them to wandb and json_logger.
tepoch.set_postfix sets the suffix of the progress bar.
If the set loop step count is reached, exit the loop.
At the end of each training iteration: validation, rollout
train_loss = np.mean(train_losses)step_log['train_loss'] = train_loss# ========= eval for this epoch ==========policy = self.modelif cfg.training.use_ema: policy = self.ema_modelpolicy.eval()# run rolloutif (self.epoch % cfg.training.rollout_every) == 0: runner_log = env_runner.run(policy) # log all step_log.update(runner_log)# run validationif (self.epoch % cfg.training.val_every) == 0: with torch.no_grad(): val_losses = list() with tqdm.tqdm(val_dataloader, desc=f"Validation epoch {self.epoch}", leave=False, mininterval=cfg.training.tqdm_interval_sec) as tepoch: for batch_idx, batch in enumerate(tepoch): batch = dict_apply(batch, lambda x: x.to(device, non_blocking=True)) loss = self.model.compute_loss(batch) val_losses.append(loss) if (cfg.training.max_val_steps is not None) \\ and batch_idx >= (cfg.training.max_val_steps-1): break if len(val_losses) > 0: val_loss = torch.mean(torch.tensor(val_losses)).item() # log epoch average validation loss step_log['val_loss'] = val_lossCalculate average training loss.
Use the policy variable to point to the model, set it to evaluation mode.
Run rollout and log.
Run validation, logging the average loss of validation.
To be done: Interpret the self.model.compute_loss (compute loss) method (defined in diffusion_unet_hybrid_image_policy file).
Sampling and action error evaluation
# run diffusion sampling on a training batchif (self.epoch % cfg.training.sample_every) == 0: with torch.no_grad(): # sample trajectory from training set, and evaluate difference batch = dict_apply(train_sampling_batch, lambda x: x.to(device, non_blocking=True)) obs_dict = batch['obs'] gt_action = batch['action'] result = policy.predict_action(obs_dict) pred_action = result['action_pred'] mse = torch.nn.functional.mse_loss(pred_action, gt_action) step_log['train_action_mse_error'] = mse.item() del batch del obs_dict del gt_action del result del pred_action del msePerform diffusion sampling on a training batch and calculate the mean squared error (MSE) between predicted actions and true actions.
To be done: Interpret the policy.predict_action (predict action) method (defined in diffusion_unet_hybrid_image_policy file).
Save checkpoint
if (self.epoch % cfg.training.checkpoint_every) == 0: if cfg.checkpoint.save_last_ckpt: self.save_checkpoint() if cfg.checkpoint.save_last_snapshot: self.save_snapshot() # sanitize metric names metric_dict = dict() for key, value in step_log.items(): new_key = key.replace('/', '_') metric_dict[new_key] = value # We can't copy the last checkpoint here # since save_checkpoint uses threads. # therefore at this point the file might have been empty! topk_ckpt_path = topk_manager.get_ckpt_path(metric_dict) if topk_ckpt_path is not None: self.save_checkpoint(path=topk_ckpt_path)Call the parent class’s save checkpoint and snapshot methods.
Note that save_point uses multithreading, which may cause the save checkpoint operation to not yet complete while the code continues to execute. As a result, the checkpoint file (model state, training state, etc.) may not have been fully written to disk yet. If you attempt to immediately copy or use the latest checkpoint file at this point, the file may be incomplete or blank.
End the current cycle and update logs, states
policy.train()wandb_run.log(step_log, step=self.global_step)json_logger.log(step_log)self.global_step += 1self.epoch += 14.2.2 @hydra.main Decorator
@hydra.main(version_base=None,config_path=str(pathlib.Path(__file__).parent.parent.joinpath("config")), config_name=pathlib.Path(__file__).stem)@hydra.main is a decorator provided by Hydra to convert the main function into a Hydra application. For more details, refer to: https://www.cnblogs.com/CircleWang/p/15616703.html
version_base=None indicates that no specific version control is used.
config_path specifies the location of the configuration file, using pathlib to dynamically construct the path, pointing to the config folder in the parent directory of the current script.
config_name is set to the name of the current script (without extension), determining which configuration file to load based on the script’s name.
4.2.3 Main Function Definition
def main(cfg): workspace = TrainDiffusionUnetHybridWorkspace(cfg) workspace.run()Parameters:
cfg: configuration object loaded by Hydra.
Inside the function, create an instance of TrainDiffusionUnetHybridWorkspace, passing the loaded configuration cfg.
The most important part of this section is the line during initialization: self.model: DiffusionUnetHybridImagePolicy = hydra.utils.instantiate(cfg.policy), which determines the nature of the model. Therefore, the next step will study the DiffusionUnetHybridImagePolicy class, as the inheritance relationship is DiffusionUnetHybridImagePolicy → BaseImagePolicy → ModuleAttrMixin → torch.nn.Module. The following will start from ModuleAttrMixin.
4.3 Module Attr Mixin
4.3.1 ModuleAttrMixin Class
Derived from torch.nn, this class is designed to facilitate the retrieval of the parameter’s device type and data type in the model, allowing for quicker access to this information during model development and debugging.
Initialization method
def __init__(self): super().__init__() self._dummy_variable = nn.Parameter()Creates an empty nn.Parameter variable _dummy_variable to ensure that this module has at least one parameter, which will be used in the implementation of device and dtype attributes later.
Why is self._dummy_variable needed? In some models or custom modules, there may not be actual nn.Parameters. If there are no parameters, self.parameters() will return an empty iterator. In this case, accessing device and dtype attributes using next(iter(self.parameters())) will raise a StopIteration exception. Therefore, a dummy parameter is defined to avoid this issue.
Get device attribute
@propertydef device(self): return next(iter(self.parameters())).deviceThe @property decorator defines device as a read-only property, allowing direct access through model.device.
next(iter(self.parameters())).device means retrieving the first parameter from the model’s parameters iterator self.parameters() and accessing its device attribute.
Get data type attribute
@propertydef dtype(self): return next(iter(self.parameters())).dtypeThe @property decorator defines dtype as a read-only property, allowing direct access through model.dtype.
next(iter(self.parameters())).dtype means retrieving the first parameter from the model’s parameters iterator self.parameters() and accessing its dtype attribute.
4.4 Base Image Policy
4.4.1 BaseImagePolicy
Abstract base class derived from ModuleAttrMixin, typically used to define a series of methods and interfaces for concrete policy models to implement (e.g., convolutional networks, variational autoencoders, etc.).
predict_action method
def predict_action(self, obs_dict: Dict[str, torch.Tensor]) -> Dict[str, torch.Tensor]: """ obs_dict: str: B,To,* return: B,Ta,Da """ raise NotImplementedError()This method is designed to provide a standard definition for the policy inference interface of the model.
Parameter explanation:
Shape conventions: The comments indicate that the shape of each tensor is formatted as (B, To, *).
B: Batch size.
To: Observation time dimension.
*: Remaining dimensions of arbitrary shape.
obs_dict: Input dictionary Dict[str, torch.Tensor], where each key str represents an observation (image, state), and each value torch.tensor is a tensor representing input data.
Return value:
Returns a dictionary representing the predicted actions.
Shape conventions:
B: Batch size.
Ta: Action execution time dimension.
Da: Action dimension.
NotImplementedError exception: This method is currently not implemented, and subclasses (such as actual image policy models) must implement this interface to define their specific action prediction logic.
reset method
def reset(self): passreset() method is used to reset the internal state of the policy model.
In some reinforcement learning or sequence models, the policy model may be stateful, meaning it retains internal state between different time steps (e.g., RNN, LSTM). In this case, the reset() method needs to be called when starting a new round of inference (e.g., a new game round or a new set of sequential data) to clear the previous state. The current implementation is an empty function (pass), indicating that by default, the policy model is stateless. Subclasses can override this method as needed to reset the model’s internal state (such as hidden layer state, attention weights, etc.).
set_normalizer method
def set_normalizer(self, normalizer: LinearNormalizer): raise NotImplementedError()This method is designed as an interface for setting the model’s input/output normalizer.
Parameter:
normalizer: of type LinearNormalizer, representing a linear normalization object.
The purpose of LinearNormalizer is typically to normalize or denormalize input observation values, such as standardizing input image data to the range [0, 1], or adjusting action values based on mean and variance.
NotImplementedError exception: This method is currently not implemented, and subclasses must implement this interface to define how to apply the normalizer to the model. Typically, models need a normalizer to maintain standard consistency in input data, thereby improving the stability of model training and the accuracy of inference.
BaseImagePolicy is designed to provide a unified interface and infrastructure for all image-based policy models. In practical applications, different types of image policy models (such as convolutional neural networks, attention-based models, etc.) may have different architectures, but they should all possess the following capabilities:
Action prediction predict_action: The ability to predict the corresponding action from a given observation.
State reset reset: The ability to reset its internal state (if any) when needed.
Normalization set_normalizer: The ability to process input and output data using a normalizer.
4.5 Diffusion Unet Hybrid Image Policy
4.5.1 DiffusionUnetHybridImagePolicy
This class uses diffusion models to process conditional image inputs and combines behavior cloning and image feature encoders to predict the actions of robots in multi-step operation sequences. This model framework integrates the image processing module of the robomimic framework and the diffusers diffusion model, designed to solve the action reasoning task in multi-step sequences.
Class initialization and construction
Constructor parameters:
def __init__(self, shape_meta: dict, noise_scheduler: DDPMScheduler, horizon, n_action_steps, n_obs_steps, num_inference_steps=None, obs_as_global_cond=True, crop_shape=(76, 76), diffusion_step_embed_dim=256, down_dims=(256,512,1024), kernel_size=5, n_groups=8, cond_predict_scale=True, obs_encoder_group_norm=False, eval_fixed_crop=False, **kwargs):shape_meta: Represents the shape metadata of input data (observations and actions), used to specify the dimensional structure of actions and observations.
noise_scheduler: A diffusion noise scheduler object DDPMScheduler used to simulate the diffusion process over time steps.
horizon: Represents the maximum length of the action sequence that the model can predict.
n_action_steps: Indicates the number of action steps to predict in a single inference.
n_obs_steps: Indicates the number of observation steps contained in each input inference.
num_inference_steps: Used to control the number of time steps in the inference process of the diffusion model.
obs_as_global_cond: A boolean parameter that determines whether to use observation features as global conditional inputs, default is True.
crop_shape: A tuple defining the cropping size when processing images.
diffusion_step_embed_dim: Specifies the dimension of the diffusion step embedding.
down_dims: Defines the dimensions for each downsampling layer in the network.
kernel_size: Defines the size of the convolution kernel.
n_groups: Defines the number of groups for group convolutions.
cond_predict_scale: Indicates whether to scale conditional predictions.
obs_encoder_group_norm: Indicates whether to use group normalization in the observation encoder.
eval_fixed_crop: Indicates whether to use fixed cropping during evaluation.
**kwargs: A dictionary containing any additional keyword parameters for providing extra configuration options.
Initialize the observation processor
# parse shape_metaaction_shape = shape_meta['action']['shape']obs_shape_meta = shape_meta['obs']obs_config = {'low_dim': [], 'rgb': [], 'depth': [], 'scan': []}# process obs shape meta to update obs_configfor key, attr in obs_shape_meta.items(): shape = attr['shape'] type = attr.get('type', 'low_dim') obs_key_shapes[key] = list(shape) if type == 'rgb': obs_config['rgb'].append(key) elif type == 'low_dim': obs_config['low_dim'].append(key)Parse the action and observation data metadata provided in shape_meta, and classify the observation data based on types (low_dim, rgb, etc.).
Initialize obs_config to specify the observation modes in robomimic to match the format of input data.
dict.get() is a method in Python that retrieves the value corresponding to a key in a dictionary, returning the second argument as a substitute value if the key does not exist.
Configure the observation data module in robomimic
config = get_robomimic_config( algo_name='bc_rnn', hdf5_type='image', task_name='square', dataset_type='ph')with config.unlocked(): # set config with shape_meta config.observation.modalities.obs = obs_config if crop_shape is None: for key, modality in config.observation.encoder.items(): if modality.obs_randomizer_class == 'CropRandomizer': modality['obs_randomizer_class'] = None else: # set random crop parameter ch, cw = crop_shape for key, modality in config.observation.encoder.items(): if modality.obs_randomizer_class == 'CropRandomizer': modality.obs_randomizer_kwargs.crop_height = ch modality.obs_randomizer_kwargs.crop_width = cwObsUtils.initialize_obs_utils_with_config(config)get_robomimic_config: Retrieves a configuration for a behavior cloning model based on robomimic (bc_rnn), which adjusts the model’s input modes based on obs_config (such as using image observations or low-dimensional observations).
Set image cropping parameters: Depending on whether crop_shape is empty, decide whether to apply the CropRandomizer module. The CropRandomizer module is used to randomly crop images during training to enhance the diversity of the data. This can help the model better handle image inputs from different perspectives.
Initialize the internal variables of ObsUtils based on the observation data module configured in robomimic to ensure that observation data can be correctly preprocessed and parsed.
Create the robomimic policy model and extract the observation encoder
policy: PolicyAlgo = algo_factory( algo_name=config.algo_name, config=config, obs_key_shapes=obs_key_shapes, ac_dim=action_dim, device='cpu', )obs_encoder = policy.nets['policy'].nets['encoder'].nets['obs']Use algo_factory to create a policy model based on the robomimic configuration, and extract the observation data encoder (obs_encoder) from it.
obs_encoder is a neural network module responsible for encoding raw observation data (images or low-dimensional state) into high-dimensional features for further policy prediction.
Replace BatchNorm layers in obs_encoder (optional)
if obs_encoder_group_norm: # replace batch norm with group norm replace_submodules( root_module=obs_encoder, predicate=lambda x: isinstance(x, nn.BatchNorm2d), func=lambda x: nn.GroupNorm( num_groups=x.num_features//16, num_channels=x.num_features) )This code decides whether to replace BatchNorm layers with GroupNorm based on the user-provided parameter obs_encoder_group_norm. This replacement is particularly useful during small batch training, as it can reduce the noise impact of BatchNorm.
Replace all CropRandomizer submodules in obs_encoder (optional)
if eval_fixed_crop: replace_submodules( root_module=obs_encoder, predicate=lambda x: isinstance(x, rmbn.CropRandomizer), func=lambda x: dmvc.CropRandomizer( input_shape=x.input_shape, crop_height=x.crop_height, crop_width=x.crop_width, num_crops=x.num_crops, pos_enc=x.pos_enc ) )When eval_fixed_crop is True, iterate through all submodules in obs_encoder, replacing all instances of type rmbn.CropRandomizer with new instances of dmvc.CropRandomizer. This replacement is usually to use different cropping logic or parameters during the evaluation phase, ensuring stability and consistency of the model during evaluation.
Initialize the diffusion model (diffusion_model)
# create diffusion modelobs_feature_dim = obs_encoder.output_shape()[0]input_dim = action_dim + obs_feature_dimglobal_cond_dim = Noneif obs_as_global_cond: input_dim = action_dim global_cond_dim = obs_feature_dim * n_obs_stepsmodel = ConditionalUnet1D( input_dim=input_dim, local_cond_dim=None, global_cond_dim=global_cond_dim, diffusion_step_embed_dim=diffusion_step_embed_dim, down_dims=down_dims, kernel_size=kernel_size, n_groups=n_groups, cond_predict_scale=cond_predict_scale)obs_feature_dim = obs_encoder.output_shape()[0], retrieves the feature dimension output from the observation encoder (obs_encoder), which is typically the number of features generated after processing the input observation data.
input_dim = action_dim + obs_feature_dim, defines the dimension of the input to the diffusion model. Here, the input dimension is the sum of the action dimension (action_dim) and the observation feature dimension (obs_feature_dim).
global_cond_dim = None, initializes global_cond_dim to None, which will be used for conditional input dimensions later.
Determines whether to use observations as global conditions for input.
If so, only the action dimension is used as the input dimension, setting input_dim to action_dim, and global_cond_dim to the product of observation feature dimension and observation steps obs_feature_dim * n_obs_steps, indicating the dimension of global conditions.
ConditionalUnet1D: A diffusion model based on a conditional UNet structure that receives observation features as conditional inputs and performs conditional diffusion and action prediction through time step embeddings (diffusion_step_embed_dim) and UNet network layers.
Model parameters:
input_dim: dimension of input features.
local_cond_dim=None: dimension of local conditions, set to None here, possibly indicating no local conditions are used.
global_cond_dim: dimension of global conditions.
diffusion_step_embed_dim: dimension of diffusion step embedding.
down_dims: list of dimensions for each downsampling layer in the network.
kernel_size: size of the convolution kernel.
n_groups: number of groups for group normalization.
cond_predict_scale: parameter for scaling conditional predictions.
Initialize other components
self.obs_encoder = obs_encoderself.model = modelself.noise_scheduler = noise_schedulerself.mask_generator = LowdimMaskGenerator( action_dim=action_dim, obs_dim=0 if obs_as_global_cond else obs_feature_dim, max_n_obs_steps=n_obs_steps, fix_obs_steps=True, action_visible=False)self.obs_encoder = obs_encoder: saves the observation encoder.
self.model = model: saves the created diffusion model.
self.noise_scheduler = noise_scheduler: saves the noise scheduler.
self.mask_generator = LowdimMaskGenerator(…): initializes a low-dimensional mask generator with parameters including action dimension, observation dimension, maximum observation steps, etc. This generator is used to produce masks that control which inputs the model should focus on during training.
The main function of the LowdimMaskGenerator class is to generate a mask based on the input parameters, controlling which features (observations or actions) are visible or hidden at a given time step in the sequential model. This class is typically applied in the training of diffusion models or other sequential generation models to limit the features the model can access at different time steps, especially in behavior modeling or time-series data processing.
Normalizer and other parameters
self.normalizer = LinearNormalizer()self.horizon = horizonself.obs_feature_dim = obs_feature_dimself.action_dim = action_dimself.n_action_steps = n_action_stepsself.n_obs_steps = n_obs_stepsself.obs_as_global_cond = obs_as_global_condself.kwargs = kwargsself.normalizer = LinearNormalizer(): initializes a linear normalizer for input normalization.
Other parameters such as horizon, obs_feature_dim, action_dim, etc., are used to save the internal state of the model.
Set inference steps
if num_inference_steps is None: num_inference_steps = noise_scheduler.config.num_train_timestepsself.num_inference_steps = num_inference_stepsThis code sets the number of steps for inference; if num_inference_steps is not provided, it defaults to the training time steps of the noise scheduler.
Reference Links
https://blog.csdn.net/zhaoliang38/article/details/139135283
https://github.com/real-stanford/diffusion_policy
https://github.com/MengMengMengH/notes-of-diffusion_policy




