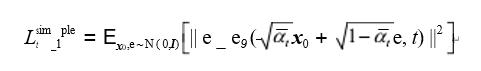In 2022, the rapid development of AIGC in the field of large language models made general artificial intelligence seem less distant. When the number of parameters exceeds a certain threshold, AIGC systems based on large language models can understand commands issued by humans in natural language and correspondingly generate real, high-quality text, images, audio, video, and other multimodal data. The diffusion model is one of the notable pioneers in this area.
The diffusion model (Diffusion Model) is a type of advanced deep learning generative model based on diffusion principles. Besides diffusion models, other generative models include the earlier VAE (Variational Auto-Encoder) and GAN (Generative Adversarial Network).
Today, I will guide you through understanding diffusion models using the book “From Principles to Practice of Diffusion Models”. You can learn to generate beautiful images with related code based on the content introduced in this book.
In 2022, the rapid development of AIGC in the field of large language models made general artificial intelligence seem less distant. When the number of parameters exceeds a certain threshold, AIGC systems based on large language models can understand commands issued by humans in natural language and correspondingly generate real, high-quality text, images, audio, video, and other multimodal data. The diffusion model is one of the notable pioneers in this area.
The diffusion model (Diffusion Model) is a type of advanced deep learning generative model based on diffusion principles. Besides diffusion models, other generative models include the earlier VAE (Variational Auto-Encoder) and GAN (Generative Adversarial Network).
Today, I will guide you through understanding diffusion models using the book “From Principles to Practice of Diffusion Models”. You can learn to generate beautiful images with related code based on the content introduced in this book.

Click the cover to purchase the book at half price, limited to 50 people.
The knowledge points covered in this book are as follows:
● The principles of diffusion models, aiming to explain how diffusion models “diffuse”.
● The development of diffusion models, aiming to describe the technical iterations and ecological development process of diffusion models in image generation.
● The applications of diffusion models, aiming to introduce other applications of diffusion models beyond the field of image generation.
The Principles of Diffusion Models
Diffusion models are a type of generative model, which utilize the diffusion concept from physical thermodynamics, primarily involving the forward diffusion and backward diffusion processes.
In deep learning, the goal of generative models is to generate new samples based on given samples (training data).
First, given a batch of training data X, assume it follows a certain complex true distribution p(x). The given training data can be viewed as observed samples x drawn from that distribution. If we can estimate the true distribution of the training data from these observed samples, wouldn’t it be possible to continuously sample new samples from that distribution? Generative models do exactly that; their purpose is to estimate the true distribution of the training data and assume it as q(x). In deep learning, this process is called fitting a network.
So, the question arises, how can we know the difference between the estimated distribution q(x) and the true distribution p(x)?
A simple idea is to maximize the probability that all training data samples are drawn from q(x). This idea actually originates from the maximum likelihood estimation in statistics, which is also one of the fundamental concepts of generative models. Therefore, the learning objective of generative models is to model the distribution of the training data.
The idea of maximum likelihood estimation has already been applied to some models (like VAE) with good results. The diffusion model can be seen as a deeper version of VAE. The expressive power of diffusion models is richer, and their core lies in the diffusion process.
The idea of diffusion comes from the branch of non-equilibrium thermodynamics in physics.Non-equilibrium thermodynamics specifically studies certain physical systems that are not in thermodynamic equilibrium. One of the most typical research cases is the process of a drop of ink diffusing in water. Before diffusion begins, the drop of ink forms a large spot at some location in the water, which we can consider as the initial state of this drop of ink. However, describing the probability distribution of this initial state is quite difficult because this probability distribution is very complex.
As the diffusion process progresses, the drop of ink gradually spreads into the water over time, and the color of the water also gradually turns into the color of the ink, as shown in Figure 1-1. At this point, the probability distribution of the ink molecules becomes simpler and more uniform, allowing us to easily describe the probability distribution with mathematical formulas.
In this case, non-equilibrium thermodynamics comes into play, as it can describe the probability distribution of each “time step” state during the diffusion process of the ink over time (aiming to discretize the continuous time process). If we can find a way to reverse this process, we can gradually infer the complex distribution from a simple distribution.
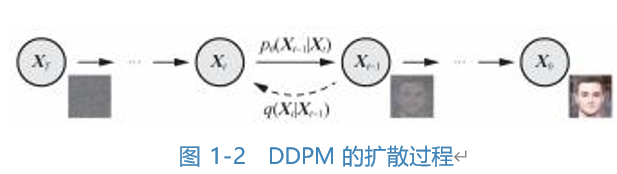
The earliest recognized diffusion model, DDPM (Denoising Diffusion Probabilistic Model), originates from this diffusion principle. However, even with the above conditions, it is still challenging to derive complex distributions from simple distributions. DDPM also makes some assumptions, such as assuming that the diffusion process is a Markov process (i.e., the probability distribution of each time step state is derived only from the probability distribution of the previous time step state plus Gaussian noise at the current time step) and that the inverse process of the diffusion process follows a Gaussian distribution, etc.
The diffusion process of DDPM is shown in Figure 1-2, specifically divided into forward and backward processes.
1 ) Forward Process
The forward process is the process of adding noise to the data. Assuming a batch of training data is given, the data distribution is x0 ~ q(x0), where 0 indicates the initial state, meaning that diffusion has not yet started.
As mentioned earlier, the forward noise-adding process is divided into discrete time steps T. At each time step t, Gaussian noise is added to the data xt−1 from the previous time step, generating noisy data (referred to as “noisy”) xt, which is then sent to the next time step t+1 for further noise addition.
The variance of the noise is determined by a fixed value βt located in the interval (0, 1), while the mean is determined by the fixed value βt and the current “noisy” data distribution. After repeatedly iterating and adding noise (i.e., adding noise) T times, as long as T is large enough, according to the properties of Markov chains, we can ultimately obtain data with a pure random noise distribution, similar to the state of a stable ink system.
2) Optimization Objective
The diffusion model predicts the noise residual, which requires minimizing the “distance” between the noise distribution predicted in the backward process and the noise distribution applied in the forward process.
Let’s look at the diffusion model from another perspective. If we consider the intermediate generated variables as latent variables, then the diffusion model can actually be seen as a model with T latent variables, thus it can be considered a deeper VAE. The loss function of VAE can be obtained using variational inference to derive the variational lower bound.
The final optimization objective of the diffusion model can be expressed mathematically as follows:
It can be seen that when training DDPM, simply using a simple MSE (Mean Squared Error) loss to minimize the noise distribution applied in the forward process and the noise distribution predicted in the backward process can achieve the final optimization objective.
The Development of Diffusion Models
Diffusion models have gradually evolved from simple image generation models to replacing existing image generation models, leading to the current era of AI painting, with a remarkable speed of development. Since this book mainly introduces the 2D image generation tasks of diffusion models, this section will only discuss the development history of diffusion models related to 2D image generation as follows.
● Beginning Diffusion: The proposal and improvement of basic diffusion models.
● Accelerating Generation: Samplers.
● Breaking Records: Diffusion models guided by explicit classifiers.
● Exploding on the Internet: Multimodal image generation based on CLIP (Contrastive Language-Image Pretraining).
● Once Again “Out of the Circle”: The “relearning” methods of large models—DreamBooth, LoRA, and ControlNet.
● Opening the AI Painting Era: Numerous commercial companies propose mature image generation solutions.
Beginning Diffusion: The Proposal and Improvement of Basic Diffusion Models
The earliest diffusion model in the field of image generation is DDPM (proposed in 2020). DDPM first applied the “denoising” diffusion probabilistic model to image generation tasks, laying the foundation for the application of diffusion models in the field of image generation, including the definition of the diffusion process, noise distribution assumptions, Markov chain calculations, stochastic differential equation solving, and loss function representation, etc. Many subsequent diffusion models are various improvements based on this foundation.
Accelerating Generation: Samplers
Although diffusion models have achieved certain results in the field of image generation, their generation speed is very slow during the image generation phase due to the need for multiple iterations (the generation speed of the initial version of diffusion models even took several minutes), which has been a point of criticism for diffusion models. In diffusion models, the speed and quality of the image generation phase are controlled by the samplers, so how to accelerate sampling while ensuring generation quality is a crucial issue for diffusion models.
The paper “Score-Based Generative Modeling through Stochastic Differential Equations” proved that the sampling process of DDPM is a more general stochastic differential equation, so as long as we can solve this stochastic differential equation more discretely, we can reduce the 1000-step sampling process to 50 steps, 20 steps, or even fewer steps, greatly improving the speed of image generation by diffusion models, as shown in Figure 1-3. Many excellent solvers have emerged to address the issue of faster sampling, such as Euler, SDE, DPM-Solver++, and Karras, and these accelerated sampling methods are also crucial driving forces for the global popularity of diffusion models.
Breaking Records: Diffusion Models Guided by Explicit Classifiers
Before May 2021, although diffusion models had been applied in the field of image generation, they had not really “exploded” in popularity in this field, as early diffusion models did not perform as well as classic generative models like GAN (Generative Adversarial Network) in terms of image quality and stability. The paper “Diffusion Models Beat GANs on Image Synthesis” was pivotal in making diffusion models “explode” in the research field. OpenAI’s paper made significant contributions, especially in deriving how to use explicit classifiers to guide the diffusion process.
More importantly, this paper defeated GANs, which had dominated the image generation field for years, showcasing the powerful potential of diffusion models, making them the hottest model in image generation, as shown in Figure 1-4.
Exploding on the Internet: Multimodal Image Generation Based on CLIP
Exploding on the Internet: Multimodal image generation based on CLIP is a model that connects text and images, aiming to convert words and images with the same semantics into the same latent space, such as the word “an apple” and the image “an apple”.
It is precisely due to this technology combined with diffusion models that led to a complete explosion of text-guided image generation diffusion models in the field of image generation, such as OpenAI’s GLIDE, DALL-E, DALL-E 2 (images generated based on DALL-E 2 are shown in Figure 1-5), Google’s Imagen, and open-source Stable Diffusion (the homepage of the Stable Diffusion v2 diffusion model is shown in Figure 1-6), with excellent text generation image diffusion models emerging one after another, bringing us endless surprises.

Figure 1-5: A cat holding cheese generated by DALL-E 2.
Once Again “Out of the Circle”: The “Relearning” Methods of Large Models
— DreamBooth, LoRA, and ControlNet
Since diffusion models have embarked on the path of large models, retraining an image generation diffusion model has become very expensive. Faced with the high costs of data and computational resources, it has become very difficult for individual researchers to enter the field of diffusion model research.
However, diffusion models like the open-source Stable Diffusion have excellently learned a lot of knowledge about image generation, so there is no need to retrain similar diffusion models. Thus, many techniques for “relearning” based on existing diffusion models have naturally emerged, making it possible for individuals to train their diffusion models on consumer-grade graphics cards. DreamBooth, LoRA, and ControlNet are different methods for achieving the “relearning” of large models, each proposed for different tasks.
DreamBooth can learn to bind a specific subject image to a unique text identifier through a small amount of training, allowing users to control their subject to generate different images by inputting text prompts, as shown in Figure 1-7.
LoRA can learn the style or character of a specified dataset using an existing model and integrate it into the current image generation. Hugging Face provides a UI interface for training LoRA, as shown in Figure 1-8.
ControlNet can learn more modal information and use segmentation maps, edge maps, and other functions to control image generation more precisely. Chapter 7 will provide a more detailed explanation of ControlNet.
Opening the AI Painting Era:
Numerous Commercial Companies Propose Mature Image Generation Solutions
After the “explosion” of image generation diffusion models, due to the maturity of technology, increased attention, and ease of use, diffusion models are flourishing on the internet, with more and more people starting to use diffusion models to generate images.
Many companies providing mature image generation solutions have emerged. For example, the image generation service provider Midjourney allows users to generate images by entering prompts on Midjourney’s Discord channel homepage (as shown in Figure 1-9), and also share and discuss image generation details with users worldwide.
Additionally, through the image generation toolbox DreamStudio developed by Stability AI (as shown in Figure 1-10), users can edit images using prompts or embed its SDK into their applications or use it as a Photoshop plugin. Of course, Photoshop also has its own image editing tool library based on diffusion models, Adobe Firefly (as shown in Figure 1-11), allowing users to generate images more efficiently based on Photoshop’s traditional selection and fine control functions.
Baidu has launched the Wenxin Yige AI creation platform (as shown in Figure 1-12), and Alibaba’s DAMO Academy has also proposed its own unified text-to-image large model.
In addition to leading companies, some startups have also begun to emerge, such as the Tiamat image generation tool launched by Backspace Network, which has received multiple rounds of investment, and the beautiful conceptual scene images generated by this tool have appeared on Shanghai subway billboards. The 6pen Art image generation app developed by Beijing Maoxianqiu Technology Co., Ltd. (as shown in Figure 1-13) brings image generation to mobile devices, allowing users to experience AI painting on their phones.
Numerous service providers are dedicated to enabling the public to generate desired images through text or images in the most mature and simplest way, truly opening the AI painting era.
The Applications of Diffusion Models
Diffusion is merely a concept, and diffusion models are not a fixed deep network structure. Besides, if the idea of diffusion is integrated into other fields, diffusion models can also play an important role.
In practical applications, the most common and mature application of diffusion models is completing image generation tasks, and this book also focuses on this. However, even so, the applications of diffusion models in other fields should not be overlooked, as they may flourish and make a significant impact in the near future, just like in the field of image generation.
This section will introduce the applications of diffusion models in other fields, specifically as follows.
● Computer Vision.
● Time Series Data Prediction.
● Natural Language.
● Text-based Multimodal.
● AI for Basic Science.
Computer vision includes both 2D and 3D vision; here, we will only introduce the applications of diffusion models in the 2D image field.
Image-related applications are very widespread and closely related to people’s daily lives. Before the emergence of diffusion models, there had already been many studies related to image processing, and diffusion models can perform well in many image processing tasks, specifically as follows.
1) Image Segmentation and Object Detection
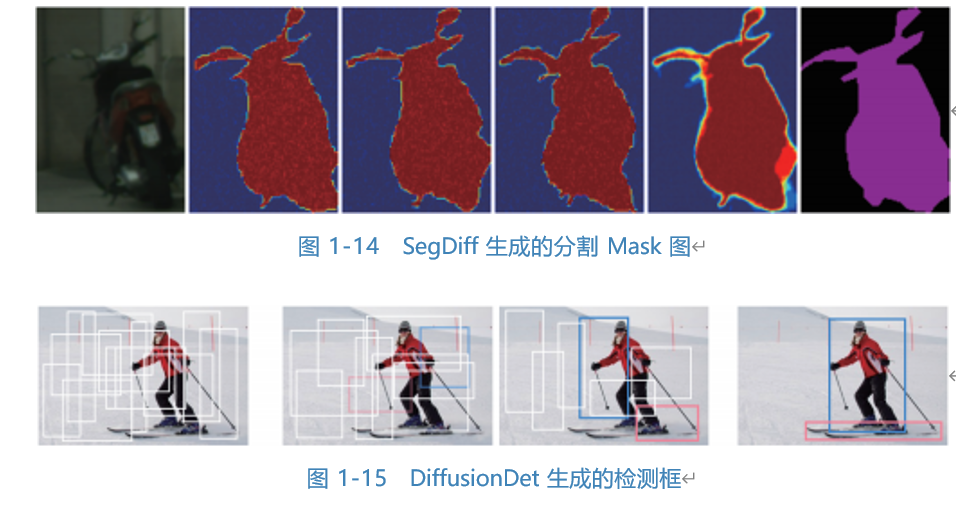
Image segmentation and object detection are classic tasks in the field of computer vision, attracting much attention in areas like intelligent driving and quality monitoring. After incorporating diffusion methods, more accurate segmentation and detection results can be obtained. For example, Meta AI’s SegDiff segmentation diffusion model can generate segmentation mask images (as shown in Figure 1-14), and the detection diffusion model DiffusionDet can also generate detection boxes step by step from random rectangular boxes (as shown in Figure 1-15). However, the diffusion model still faces the issue of slow generation speed, which requires further optimization in scenarios that need real-time detection.
2) Image Super Resolution
Image super-resolution is a technology that can reconstruct low-resolution images into high-resolution images while ensuring the coherence of the image layout. CDM (Cascaded Diffusion Model) achieves image super-resolution by progressively increasing resolution through a series of diffusion models, as shown in Figure 1-16.
3) Image Restoration, Image Translation, and Image Editing.
Image restoration, image translation, and image editing involve operations performed on part or all of an image, including filling in missing parts, style transfer, content replacement, etc. Palette is a diffusion model that integrates functions for image restoration, image translation, and image editing, which can perform various image-level tasks in one model. Figure 1-17 provides an example of using Palette to restore an image.
Time Series Data Prediction
Time series data prediction aims to forecast future data based on historical observation data, such as air temperature prediction, stock price forecasting, sales and production capacity forecasting, etc. Time series data prediction can also be viewed as a generative task, where future data is generated based on historical data as the basic condition, thus diffusion models can also play a role.
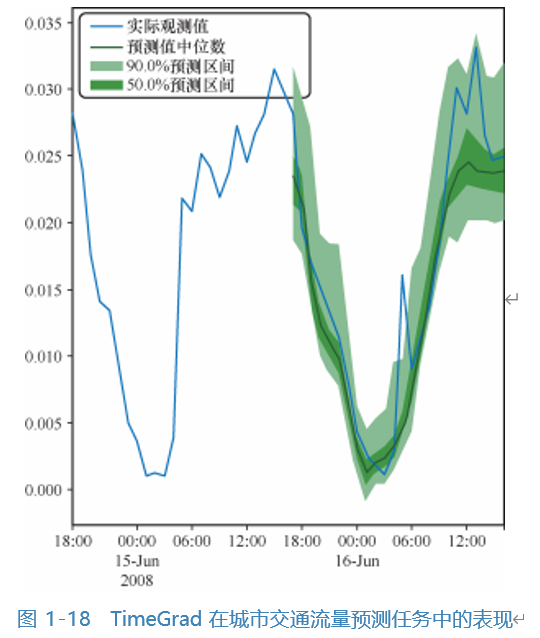
TimeGrad is the first autoregressive model to incorporate diffusion ideas into multivariate probabilistic time series data prediction tasks. To add the diffusion process to historical data, TimeGrad first processes historical data using RNN (Recurrent Neural Network) and saves it in latent space, then adds noise to historical data to achieve the diffusion process, thereby handling thousands of dimensions of multivariate data and completing prediction tasks. Figure 1-18 shows TimeGrad’s performance in urban traffic flow prediction tasks.
Time series data prediction has very broad applications in real life. Traditionally, conventional machine learning methods and deep learning’s RNN series methods have dominated the field. Now, diffusion models have shown great potential, and this is just the beginning.
The natural language field is also an important direction of development in artificial intelligence, aiming to study issues related to human language communication with computers. Recently, the “explosive” ChatGPT is a natural language generation Q&A model.
In fact, diffusion models can also complete language generation tasks. By tokenizing and converting sentences in natural language into word vectors, diffusion methods can be used to learn the generation of natural language sentences, thus completing some more complex tasks in the natural language field, such as language translation, Q&A dialogue, search completion, sentiment analysis, article continuation, etc.
Diffusion-LM is the first diffusion language model applied to the natural language field. This model aims to solve the problem of applying continuous diffusion processes to discrete, non-continuous text, thus achieving high-fidelity controllable generation in the language domain. Tests have shown that Diffusion-LM achieves excellent generation results in six controllable text generation tasks, as shown in Table 1-1.
In fact, there have been many applications based on Diffusion-LM subsequently. However, in the natural language field, the current mainstream model is still GPT (Generative Pre-trained Transformer), and we look forward to further developments of diffusion models in the natural language field in the future.
Multimodal information refers to information of various data types, including text, images, audio/video, 3D objects, etc. The interaction of multimodal information is one of the research hotspots in the field of artificial intelligence, which is of great significance for AI to understand the human world and assist humans in handling various affairs. With the emergence of image generation diffusion models like DALL-E 2 and Stable Diffusion, as well as language models like ChatGPT, multimodal has gradually evolved into interactions based on text and other modalities, such as text generating images, text generating videos, and text generating 3D objects.
1) Text-to-Image Generation
Text-to-image generation is the most popular and mature application of diffusion models. By inputting text prompts or just a few words, diffusion models can generate corresponding images based on the textual description. The well-known text-to-image generation diffusion models like DALL-E 2, Imagen, and fully open-source Stable Diffusion all belong to the multimodal diffusion models of text and images. Figure 1-19 provides several examples of using Imagen to generate images from text.
Figure 1-19: Several examples of text-to-image generation using Imagen.
2) Text-to-Video Generation
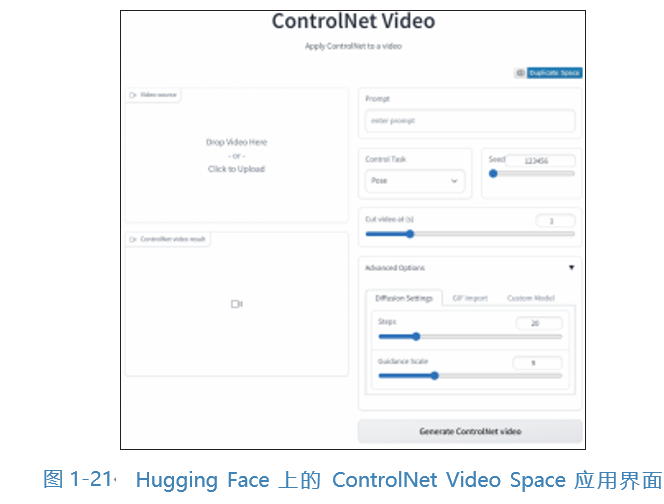
Similar to text-to-image generation, text-to-video generation diffusion models can convert input text prompts into corresponding video streams. The difference is that the previous and subsequent frames of the video need to maintain excellent coherence. Text-to-video generation also has very broad applications, such as Meta AI’s Make-A-Video (as shown in Figure 1-20) and ControlNet Video, which can finely control video generation. Figure 1-21 shows the application interface of ControlNet Video Space on Hugging Face.
Figure 1-20: Meta AI’s Make-A-Video: A dog dressed in a superhero costume soaring in the sky.
3) Text-to-3D Generation
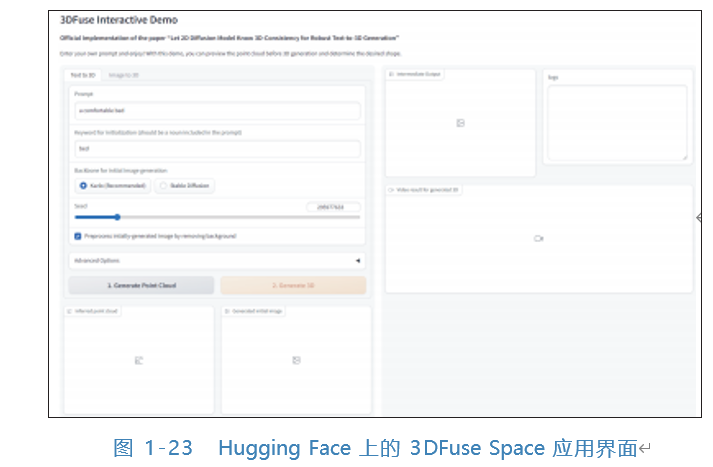
Similarly, text-to-3D generation diffusion models can convert input text into corresponding 3D objects. However, there are various ways to represent 3D objects, such as point clouds, meshes, NeRF, etc. Different applications also have slight differences in implementation. For example, DiffRF proposes a diffusion model that generates 3D radiance fields from text; 3DFuse generates corresponding 3D point clouds based on 2D images. We can experience the official demonstration provided by Hugging Face, as shown in Figures 1-22 and 1-23. Although the technology for text-to-3D generation is still in its infancy, its application prospects are very broad, including interior design, game modeling, and digital humans in the metaverse.
AI for Basic Science, also known as AI for Science, is one of the promising branches of artificial intelligence that could develop into technology beneficial to all humanity. Research results related to AI for Basic Science have repeatedly appeared in the journal Nature. For example, in 2021, DeepMind’s research on AlphaFold 2 could predict 98.5% of human proteins, and in 2022, DeepMind used reinforcement learning to control overheating plasma in nuclear fusion reactors.
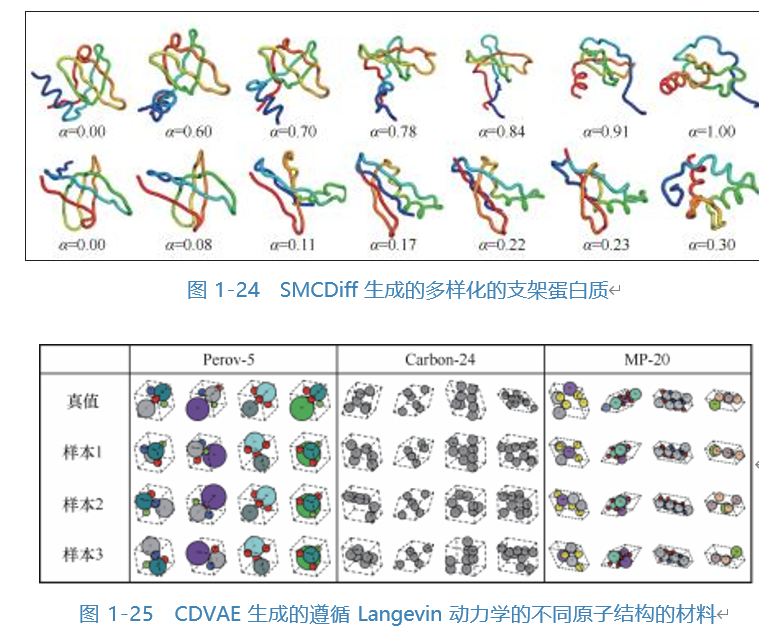
Diffusion models have consistently performed professionally in generative tasks, and they certainly play a role in the research of generative prediction in AI for Basic Science. SMCDiff created a diffusion model that can generate diverse scaffold proteins based on given motif structures, as shown in Figure 1-24. CDVAE proposed a diffusion crystal variational autoencoder model aimed at generating and optimizing materials with fixed periodic atomic structures, as shown in Figure 1-25.
The above content is from “From Principles to Practice of Diffusion Models”
Click the cover to purchase the book, limited time offer for the 8th anniversary of the Asynchronous Community.
Learn practical skills on the HuggingFace platform, with Ivy League data science master’s and algorithm engineers guiding you from theory to practice to understand and master diffusion models, quickly meeting your drawing needs at work and effectively improving efficiency.
The application fields of AIGC are increasingly broad, and in the field of image generation, diffusion models are an important application of AIGC technology. This book uses the theoretical knowledge of diffusion models as a starting point, gradually introducing related knowledge of diffusion models, and helping readers understand the details of diffusion models through a wealth of vivid and interesting practical cases. The book consists of 8 chapters, detailing the principles of diffusion models, as well as important concepts and methods such as diffusion model degradation, sampling, DDIM inversion, etc. Additionally, the appendix provides a high-quality image set generated by diffusion models and related resources from the Hugging Face community.
This book is suitable for all AI researchers, relevant researchers interested in diffusion models, and professionals with drawing needs in their work, and can also serve as a reference book for students in computer and related majors.
1. From now until August 31, premium courses are available for 9.9 yuan!
2. The book and course package products will be fully launched in 2023, making it more cost-effective to buy books and courses together, starting at 50% off!
3. From now until August 22, all physical books, e-books, and video courses (book and course packages and some courses) are 50% off! Additionally, coupons can be stacked for discounts: 10 yuan off for purchases over 100 yuan, 30 yuan off for purchases over 200 yuan, and 50 yuan off for purchases over 300 yuan, with the lowest price reaching 41% off!
4. From now until August 22, VIP members can buy 1 year and get 1 year free, along with 6 e-book versions as gifts.
Tips for saving money:
When purchasing books on the Asynchronous Community, choosing [physical book + e-book] generally keeps the price at the same level as a single physical book, which is equivalent to buying a physical book and getting an e-book for free.
Buy books and read freely now!
Share your views on the prospects of diffusion model development.
Participate in the interaction in the comment area, and click “See” and share the event to your Moments. We will select 1 reader to gift an e-book version. The deadline is August 31.