
Author: Zhang Jianzhong
Source: http://blog.csdn.net/zouxy09/article/details/8775518
Deep learning is a new field in the study of machine learning, motivated by the establishment and simulation of neural networks that analyze and learn like the human brain. It mimics the mechanisms of the human brain to interpret data such as images, sounds, and text. Deep learning is a form of unsupervised learning.
The concept of deep learning originates from the study of artificial neural networks. A multilayer perceptron with multiple hidden layers is a structure of deep learning. Deep learning combines low-level features to form more abstract high-level representations of attribute categories or features, aiming to discover distributed feature representations of the data.
Deep learning itself is considered a branch of machine learning, which can be simply understood as the evolution of neural networks. About two to three decades ago, neural networks were a particularly hot direction in the field of machine learning, but they gradually faded away for several reasons:
1) They are prone to overfitting, and the parameters are difficult to tune, requiring many tricks;
2) Training speed is relatively slow, and the performance is not superior to other methods when the number of layers is small (less than or equal to 3);
Thus, for about 20 years, neural networks received little attention, and this period was primarily dominated by SVMs and boosting algorithms. However, a dedicated individual, Hinton, persevered and eventually (along with others like Bengio and Yann LeCun) proposed a practically feasible deep learning framework.
Deep learning shares similarities with traditional neural networks but also has many differences.
The similarity lies in the fact that deep learning adopts a similar hierarchical structure to neural networks, consisting of a multi-layer network with an input layer, multiple hidden layers, and an output layer. Only adjacent layers are connected, while nodes within the same layer and across layers are not connected. Each layer can be viewed as a logistic regression model; this hierarchical structure is quite close to the structure of the human brain.
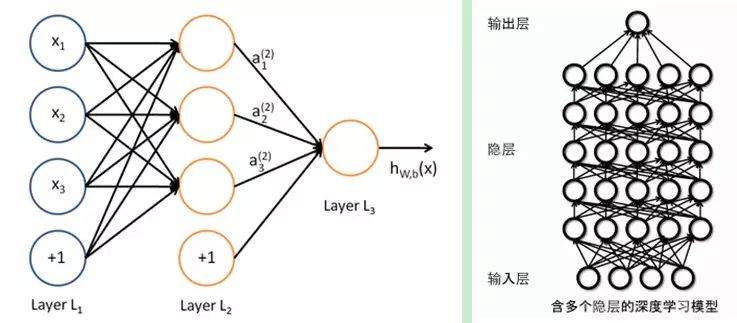
To overcome the challenges in training neural networks, deep learning employs a training mechanism that is quite different from traditional neural networks. Traditional neural networks use backpropagation for training, which can be simply described as an iterative algorithm that trains the entire network. It randomly sets initial values, calculates the current network output, and then adjusts the parameters of the previous layers based on the difference between the current output and the label until convergence (the overall process is a gradient descent method). In contrast, deep learning utilizes a layer-wise training mechanism. The reason for this approach is that if backpropagation is used for a deep network (more than 7 layers), the residuals propagated to the earlier layers become too small, leading to a phenomenon known as gradient diffusion.
Deep Learning Training Process
1. Why traditional neural network training methods cannot be used for deep neural networks
The backpropagation (BP) algorithm, as a typical training method for multilayer networks, is already quite ineffective for networks with only a few layers. The local minima commonly found in non-convex cost functions of deep structures (involving multiple layers of nonlinear processing units) are a major source of training difficulties.
Problems with the BP algorithm:
(1) Gradients become increasingly sparse: as we move down from the top layer, the error correction signals become smaller;
(2) Convergence to local minima: especially when starting far from the optimal region (random initialization can lead to this situation);
(3) Generally, we can only train with labeled data: but most data is unlabeled, while the brain can learn from unlabeled data;
2. The deep learning training process
If we train all layers simultaneously, the time complexity becomes too high; if we train one layer at a time, the bias will propagate layer by layer. This faces the opposite issue to supervised learning, resulting in severe underfitting (because deep networks have too many neurons and parameters).
In 2006, Hinton proposed an effective method for building multilayer neural networks on unlabeled data. Simply put, it involves two steps: first, training one layer of the network at a time; second, fine-tuning to ensure that the high-level representation generated from the original representation x and the high-level representation r can closely match the generated x’. The method is as follows:
1) First, build single-layer neurons layer by layer, training one single-layer network at a time.
2) After all layers are trained, Hinton uses the wake-sleep algorithm for fine-tuning.
He transforms the weights between all layers except the top layer into bidirectional connections, so that the top layer remains a single-layer neural network while the other layers become graphical models. The upward weights are used for “cognition,” and the downward weights are used for “generation.” Then, he uses the Wake-Sleep algorithm to adjust all weights. This ensures that cognition and generation align, meaning that the generated top-level representation can accurately reconstruct the underlying nodes as much as possible. For instance, if a node at the top level represents a face, then all images of faces should activate this node, and the resulting downward-generated image should represent a rough face image. The Wake-Sleep algorithm consists of two parts: waking and sleeping.
1) Wake phase: the cognitive process generates abstract representations (node states) for each layer through external features and upward weights (cognitive weights), and modifies the downward weights (generative weights) between layers using gradient descent. In other words, “If reality differs from my imagination, adjust my weights so that my imagination corresponds to reality.”
2) Sleep phase: the generative process generates the states of the lower layers using the top-level representation (concept learned during wake) and downward weights, while modifying the upward weights between layers. In other words, “If the scene in my dreams does not match the corresponding concept in my mind, adjust my cognitive weights so that this scene appears to me as that concept.”
The specific deep learning training process is as follows:
1) Use bottom-up unsupervised learning (training from the bottom layer up to the top):
Utilizing unlabeled data (labeled data may also be used) to train the parameters of each layer step by step. This step can be seen as an unsupervised training process, which is the most significant difference from traditional neural networks (this process can be seen as a feature learning process):
Specifically, first train the first layer using unlabeled data, learning the parameters of the first layer (this layer can be viewed as obtaining a hidden layer of a three-layer neural network that minimizes the difference between output and input). Due to model capacity limitations and sparsity constraints, the resulting model can learn the structure of the data itself, thereby obtaining features with greater representational ability than the input; after learning the n-1 layer, use the output of the n-1 layer as the input for the n layer to train the n layer, thereby obtaining the parameters for each layer;
2) Top-down supervised learning (training with labeled data, propagating errors from the top down to fine-tune the network):
Based on the parameters obtained in the first step, further fine-tune the parameters of the entire multilayer model, which is a supervised training process; the first step is similar to the random initialization process of neural networks. However, since the first step of deep learning is not random initialization but is derived from learning the structure of the input data, this initial value is closer to the global optimum, thus achieving better results. Therefore, the effectiveness of deep learning is largely attributed to the feature learning process in the first step.
If you feel the charm of mathematics from this, please support the author!
Feel free to share or appreciate!

Recommended classic articles:
-
Understanding the Real Significance Behind Matrices
-
Want to Pursue Her? First Calculate How Long You Have to Wait
-
The Geometric Meaning of Matrix Rank and Determinants
-
Application of Algorithms in Pursuing Girls
-
MIT Experts Explain Mathematical Systems
-
Speculation on the Principles Behind WeChat Red Envelopes
-
Advantages and Disadvantages of Various Programming Languages
-
How to Pair Socks Using the Fastest and Most Efficient Algorithm?
-
Implementing Snake AI
-
What Are the Recommendation Algorithms?