


This is a work from Big Data Digest. For reprint requirements, please see the end of the article.
Translation Team | Han Yang, Fan Yuecan, Mao Li, Cao Xiang
We are now in a world where machines think, learn, and create. Furthermore, their capabilities to do these things will rapidly increase, until in a foreseeable future, the range of problems they can handle will expand alongside the range of applications of human thought.
—— Herbert Simon, 1957
On January 14, 2017, at the Texas Data Day conference, Jonathan Mugan, co-founder and CEO of Deep Grammar, an AI and machine learning expert, delivered a speech titled “Deep Learning for Natural Language Processing”.
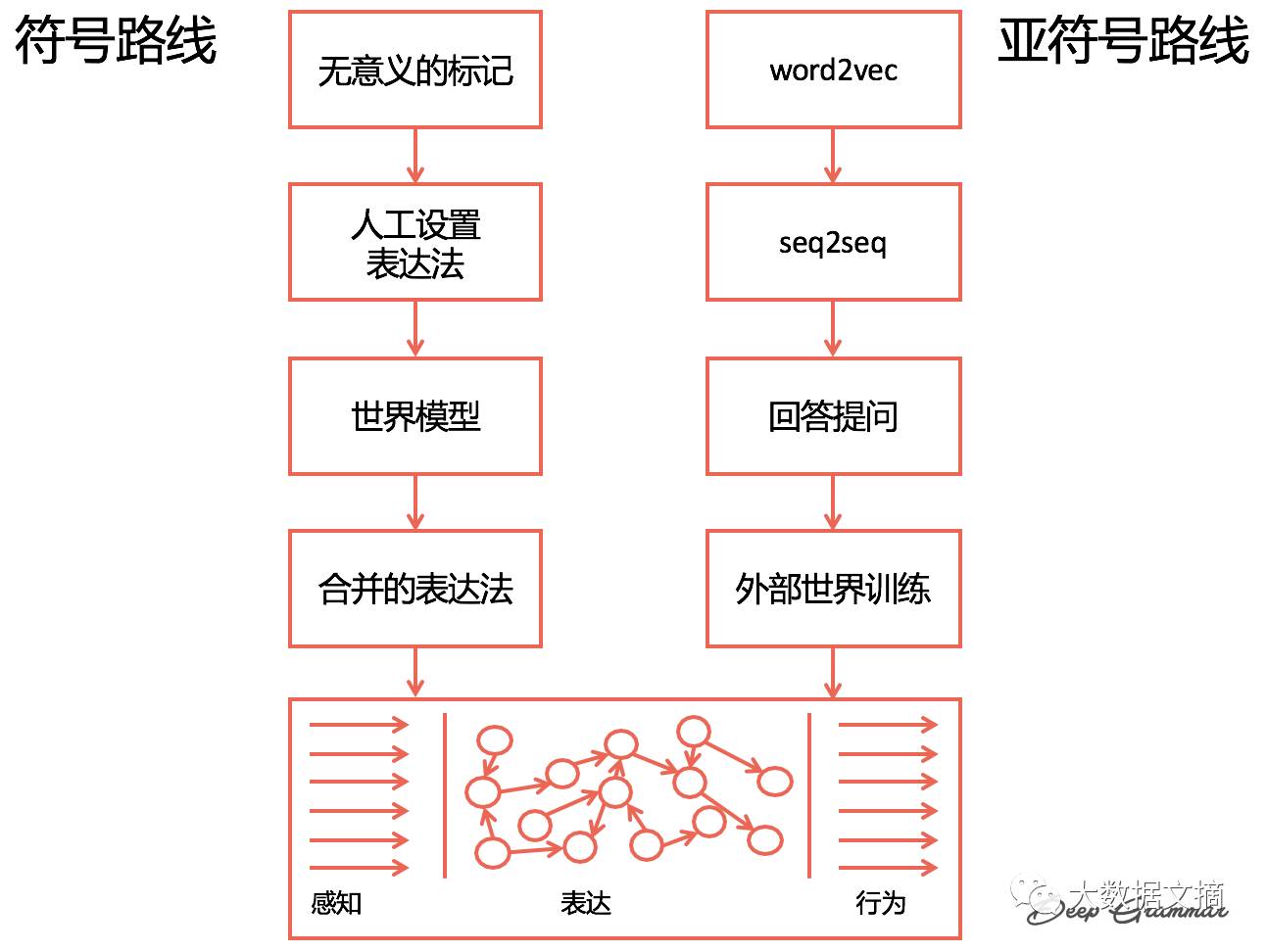
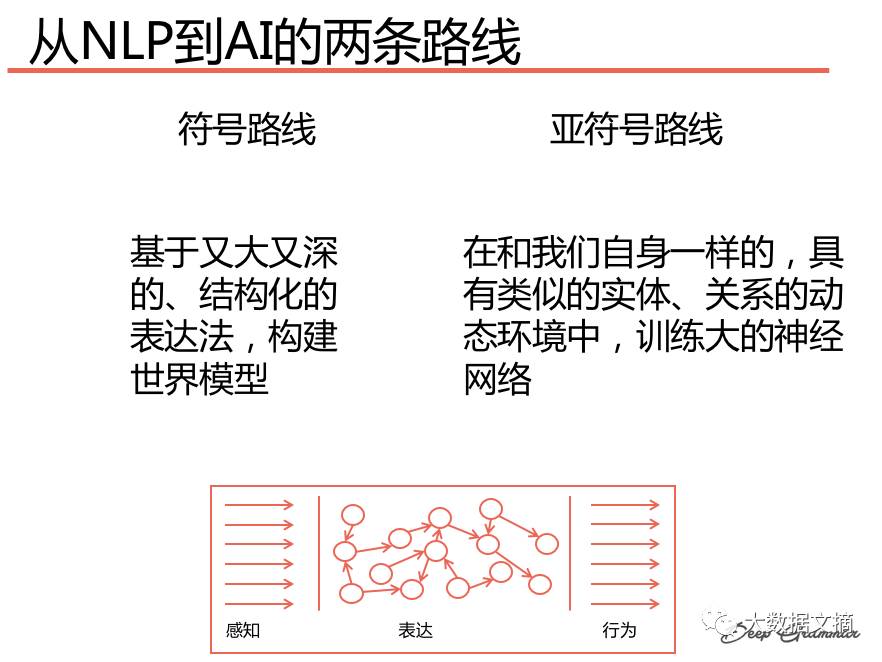
Jonathan Mugan focuses on the intersection of AI, machine learning, and natural language processing.In this presentation, he emphasized how to transition from natural language processing to AI, detailing two specific paths: the symbolic route and the sub-symbolic route.
This article is based on the 64-page PPT from this presentation. Click the top right corner to enter the Big Data Digest backend and reply with “Natural Language Processing” to get the complete presentation PPT.

Artificial intelligence has become smarter. Especially with deep learning, but computers still cannot read or converse intelligently.
To understand language, computers need to understand the world. They need to answer questions like the following:
Why can you pull a cart with a rope but not push it?
Why is it unusual for a gymnast to compete on one leg?
Why is it only raining outside?
If there is a book on the table, what happens if you push the table?
If Bob goes to the dump, will he be at the airport?
Let us understand language in a way based on sensation and action—
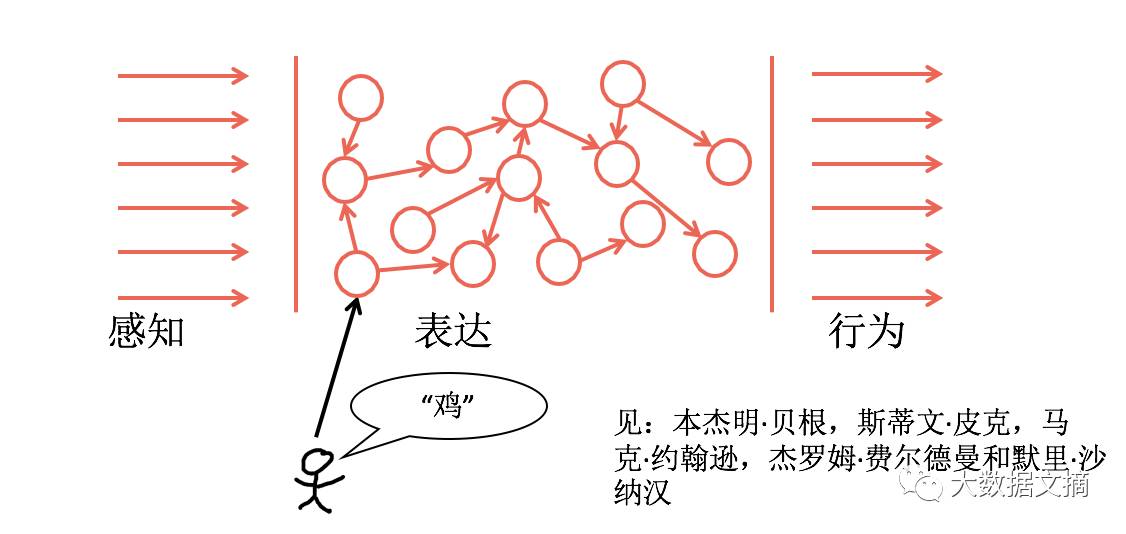
When someone says “chicken,” we directly match it with our experience of chickens; we understand each other because we have the same experiences, which is the kind of understanding computers need.
Two Paths of Understanding Meaning:
Bags-of-Words Representation:
View words as arbitrary symbols and look at their frequency. “Dog bites man” and “man bites dog” are completely identical. Consider a vocabulary with 50,000 words:
The position of “aardvark” is 0
The position of “ate” is 2
The position of “zoo” is 49,999
A bag of words can be a vector with 50,000 dimensions.
“The aardvark ate the zoo.” = [1,0,1,…,0,1]
We can do a bit better by counting the frequency of these words.
tf: term frequency, the frequency of a word appearing.
“The aardvark ate the aardvark by the zoo.” = [2,0,1,…,0,1]
Boosting Rare Vocabulary:
Consider that rare vocabulary can better represent the text than common vocabulary, and we can achieve better results. Multiply each entry by a measure representing how common it is in the corpus.
idf: inverse document frequency
idf(term, document) = log(number of documents / number of documents containing the term)
10 documents, only one has “aardvark”, 5 have “zoo”, and 5 have “ate”
tf-idf: tf * idf
“The aardvark ate the aardvark by the zoo.” = [4.6,0,0.7,…,0,0.7]
This is called the vector space model. You can feed these vectors into any classifier or find similar documents based on similar vectors.
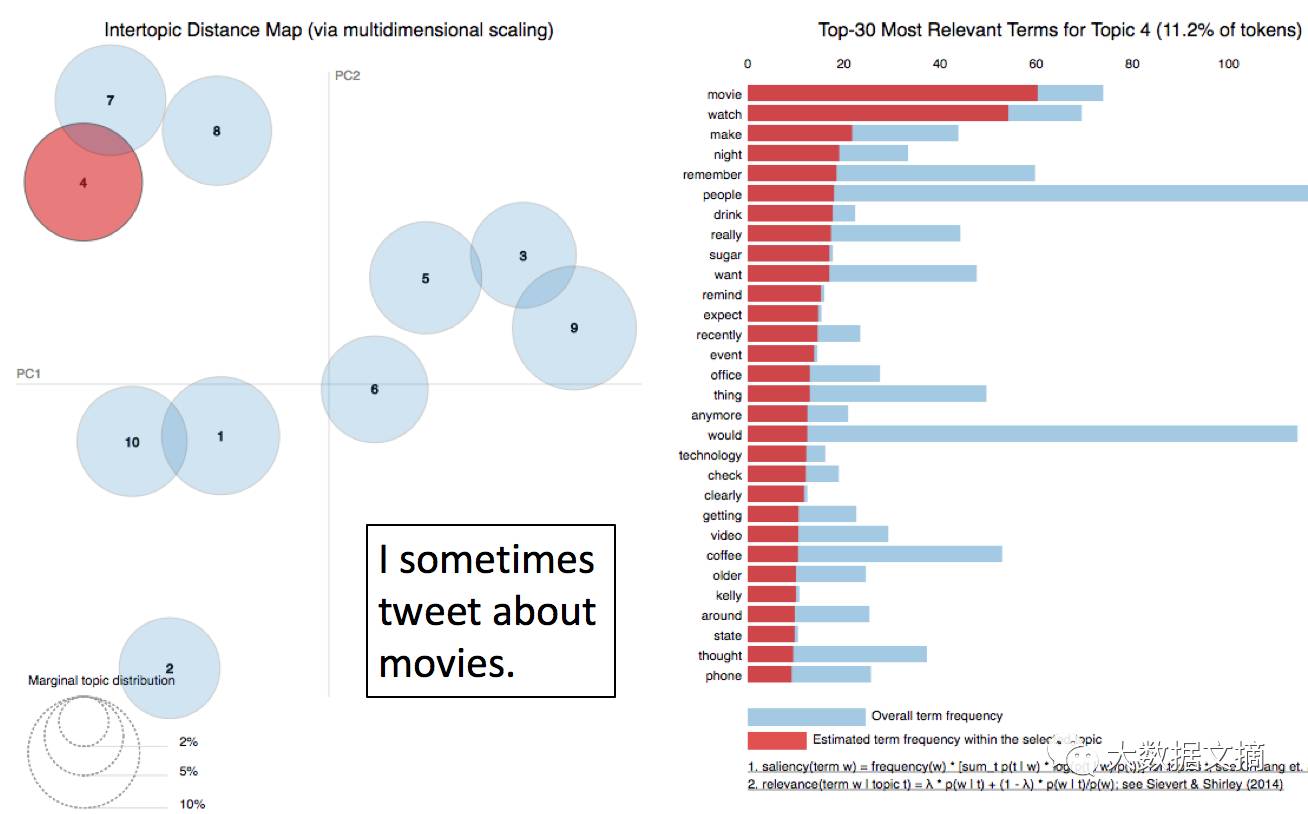
Topic Model (LDA):
Latent Dirichlet Allocation
You choose the number of topics, each topic is a distribution over words, and each document is a distribution over topics. This is easily operated in the Python topic model gensim (https://radimrehurek.com/gensim/models/ldamodel.html)
Applying LDA on Twitter through pyLDAvis:
Sentiment Analysis: — What the author feels about the text:

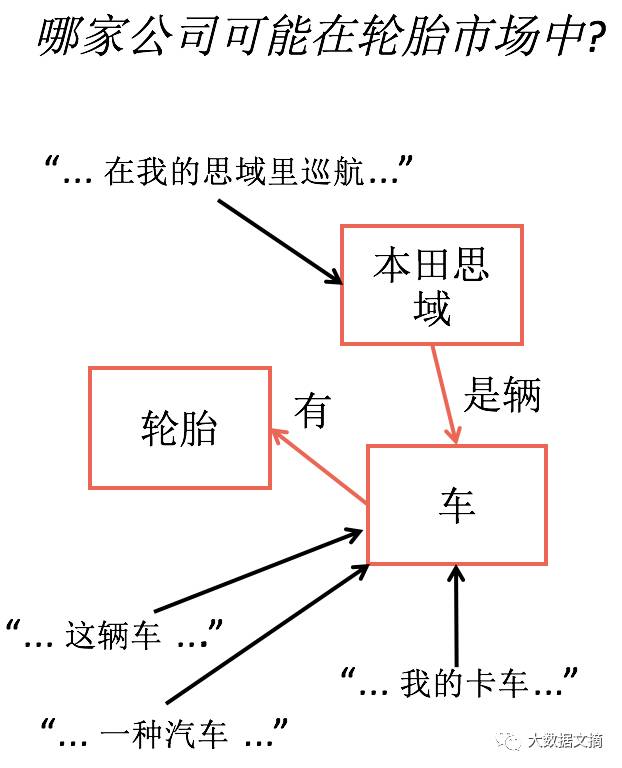
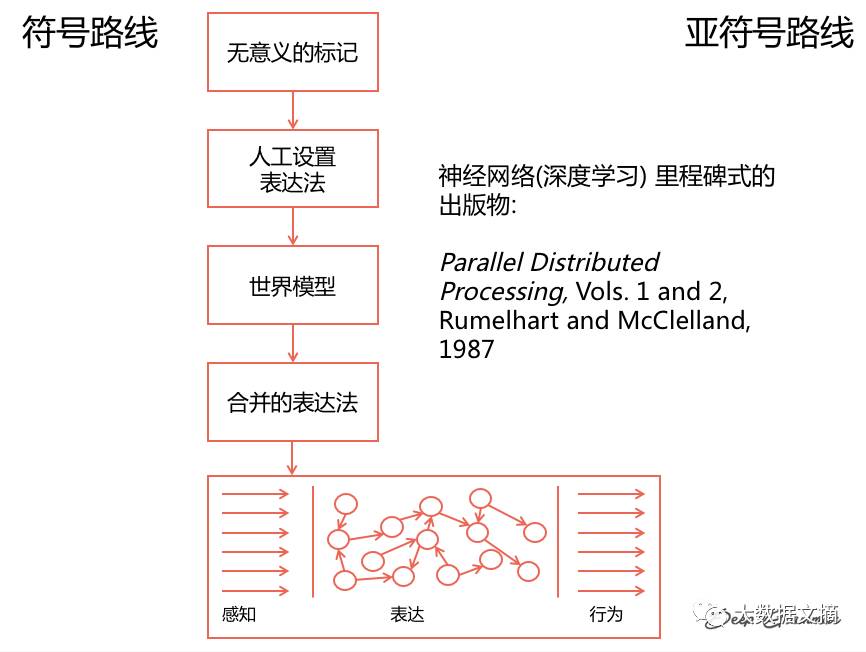
We tell computers what things mean by manually specifying the relationships between symbols.
1. Use predetermined relationships to store meaning
2. Illustrate multiple ways to write something that means the same
By using a relatively small number of expressions, we can encode what machines should do.
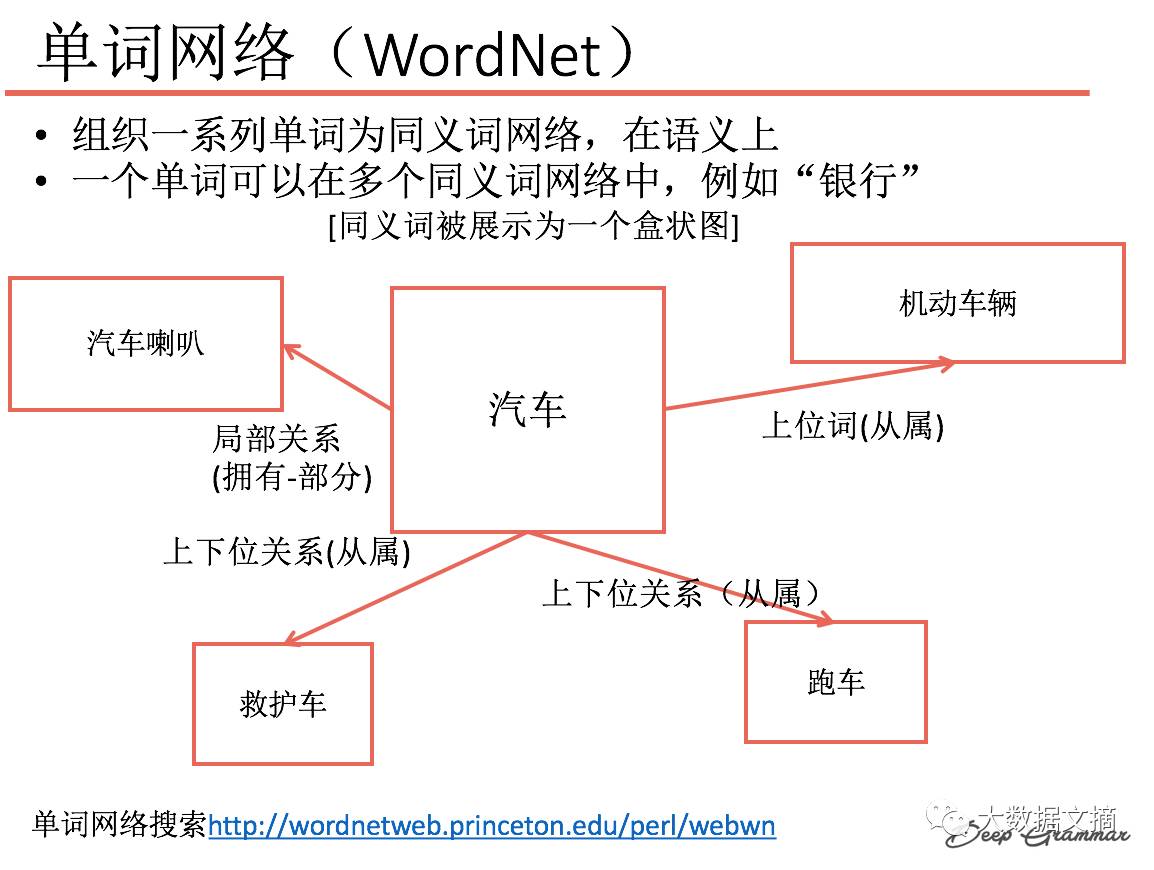
WordNet:

FrameNet:

ConceptNet:

Another Knowledge Ontology:
Merge Ontology on Suggestions:

Image Schemas:
Image schemas are representations of human experiences across common cultural experiences
—— Feldman, 2006
Humans use image schemas to understand spatial arrangements and movements
—— Mandler, 2004
Examples of image schemas include paths, prophets, blockage, and attraction
—— Johnson, 1987
Abstract concepts such as romantic relationships and arguments are represented as metaphors of these experiences
—— Lakoff and Johnson, 1980
Semantic Web – Linked Data:
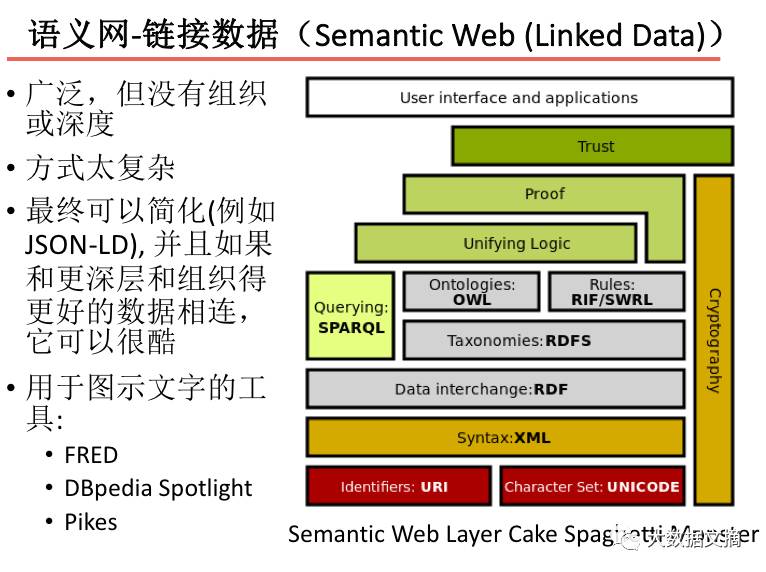
Computers need causal models about how the world works and how to interact with it. People do not say everything to convey a message; they only say what is not covered by our shared concepts. The most effective way to encode our shared concepts is to borrow models. Models express how the world changes based on events. For example, recalling a business purchase framework, later one person has more money and another has less, and conclusions can be drawn from the model.
Dimensions of Models: Probability: comparing determinism and randomness. For example, comparing logic and probabilistic programming. Factor States: comparing overall states and using variables. For example, comparing finite automata and dynamic Bayesian networks. Correlation: comparing propositional logic and first-order logic. For example, comparing Bayesian networks and Markov logic networks. Concurrent: comparing a model of one thing with multiple things. For example, comparing finite automata with Petri nets. Temporal: comparing static and dynamic. For example, comparing Bayesian networks with dynamic Bayesian networks.
Expressing through Model Combination:
Word2vec model learns a vector for each word in the vocabulary. Each word vector has the same dimension, generally around 300. Unlike tf-idf vectors, word vectors are dense, with most values not being zero.
1. Initialize each word as a random vector
2. For each word w1 in the document set:
3. For each word w2 around w1:
4. Move the vector so that w1 and w2 are closer while other words are further from w1.
5. If the stopping condition is not met, return to step 2
—— Skip-gram Model (Mikolov et al., 2013)
Note: In reality, each word corresponds to two vectors because you do not want a word to be near itself. (See Goldberg and Levy https://arxiv.org/pdf/1402.3722v1.pdf), this double for-loop explanation comes from Christopher Moody.
The Meaning of word2vec:
We often see such famous saying:
“You can understand a word by the other words near it”
—— J. R. Firth 1957
In a sense, this seems to be a fact.
“Vectors have internal structure.”
—— Mikolov et al., 2013
Italy – Rome = France – Paris
King – Queen = Man – Woman
But… words are not based on experience; they just rely on the other words around them.
(Also can be done on ConceptNet, see https://arxiv.org/pdf/1612.03975v1.pdf)
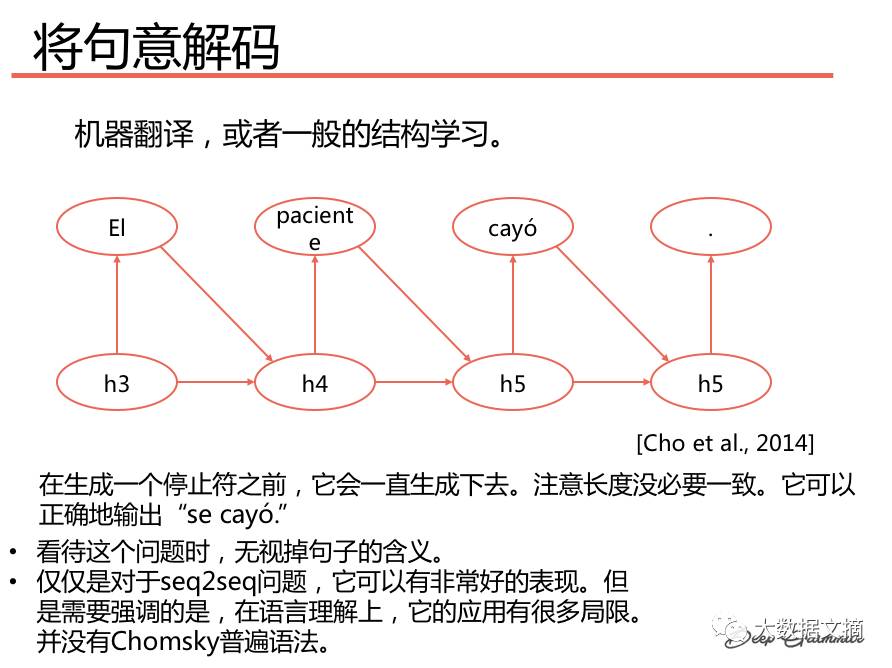
Seq2seq (sequence-to-sequence) model can encode a sequence of symbols, such as a sentence, into a vector. Subsequently, the model can decode the vector into another sequence of symbols. Both encoding and decoding can be done through Recurrent Neural Networks (RNNs). An obvious application is machine translation. For instance, the source language is English, and the target language is Spanish.
Encoding Sentence Meaning into a Vector:
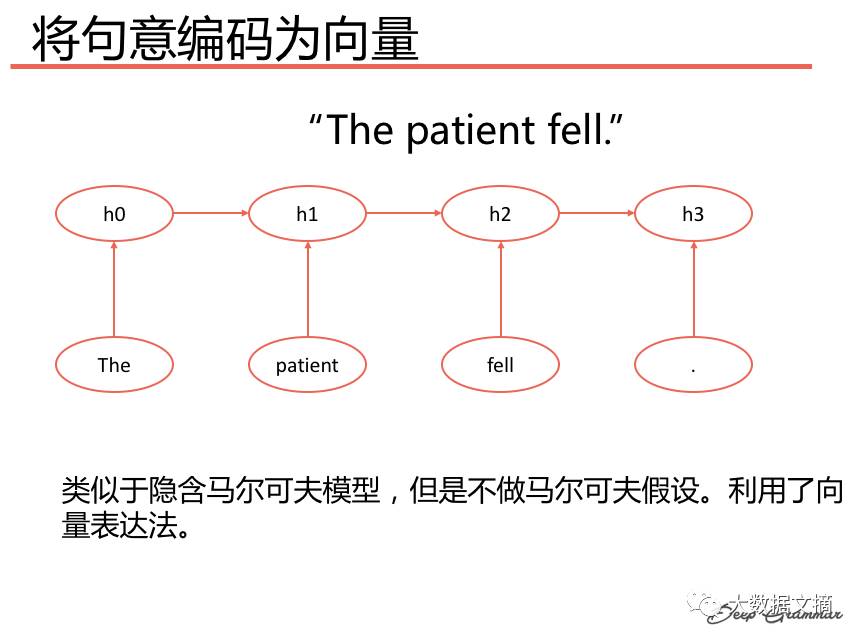
Decoding Sentence Meaning:
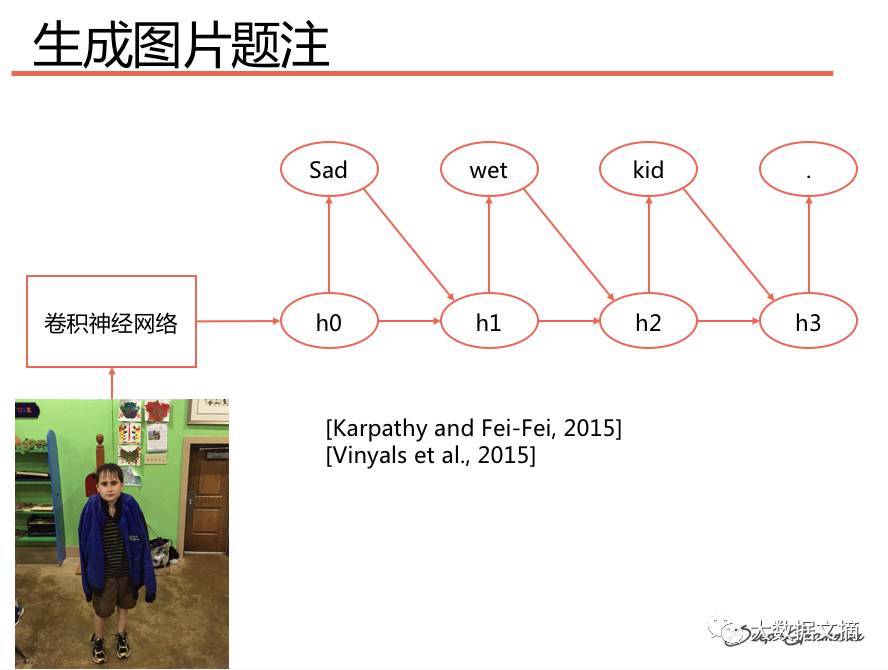
Generating Image Captions:
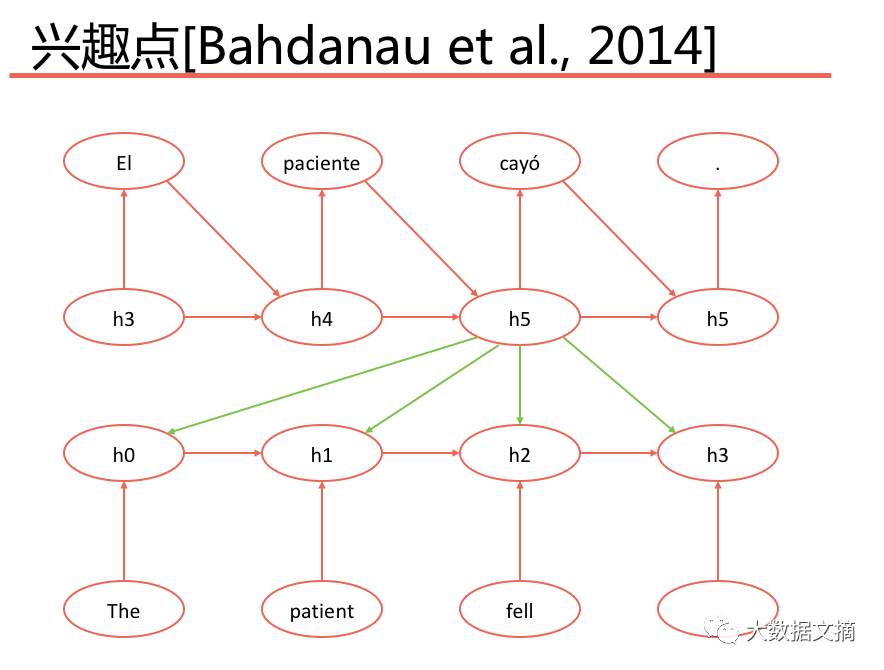
Points of Interest:
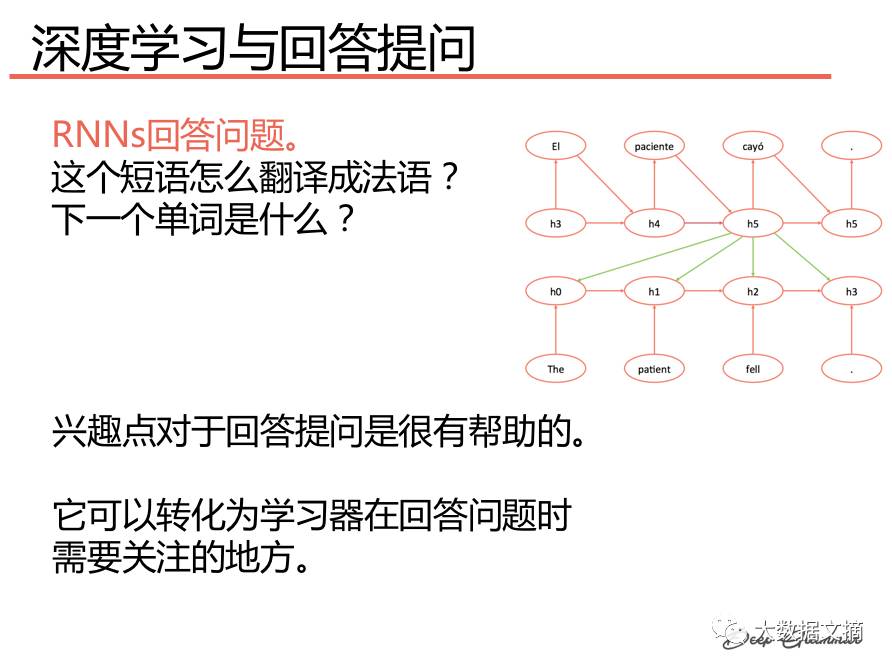
Deep Learning and Answering Questions:

Neural networks have learned the connections between various sequences of symbols, but this description is insufficient to cover the rich connections of the real world.
If we want to communicate with machines, we need to train them in environments as similar to ourselves as possible. It cannot just be conversations! (Harnad[1990] http://users.ecs.soton.ac.uk/harnad/Papers/Harnad/harnad90.sgproblem.html) To understand “chicken,” we need machines to gain as much experience about “chicken” as possible. When we say “chicken,” we are not only referring to that type of bird but also to everything we can do with it and all its meanings in our culture.
This direction has seen a lot of work:
First, in the industry —
1. OpenAI
World: Training on the screen of VNC (Remote Desktop)
Now through Grand Theft Auto (GTA)!
(https://openai.com/blog/GTA-V-plus-Universe/)
2. Google
Mikolov et al., A Roadmap towards Machine Intelligence.
They defined an artificial environment. (https://arxiv.org/pdf/1511.08130v2.pdf)
3. Facebook
Weston, Memory Networks for Dialogue https://arxiv.org/pdf/1604.06045v7.pdf
Kiela et al., Virtual Embodiment: A Scalable Long-Term Strategy for Artificial Intelligence Research. Advocating “purposefully” using video games https://arxiv.org/pdf/1610.07432v1.pdf
Of course, there is also academia —
1. Ray Mooney
Mapping Text to Situations
http://videolectures.net/aaai2013_mooney_language_learning/
2. Luc Steels
Robots with Vocabulary and Simple Grammar
3. Narasimhan et al.
Training neural networks to play text-based adventure games
https://arxiv.org/pdf/1506.08941v2.pdf
However, we need more training for the real world:
Perhaps after Amazon Alexa has a camera and a head that can turn? How far can we go without the benefit of teachers?
Can we take gaze as a source of information?
—— Yu and Ballard, [2010]
Open Questions:
From a business perspective, what are the simplest tasks that require common sense and logical reasoning?

For Reprint
If reprinting, please prominently indicate the author and source at the beginning (Reprinted from: Big Data Digest | bigdatadigest), and place a prominent QR code for Big Data Digest at the end of the article. For articles without original markings, please edit according to reprint requirements, and you can directly reprint. After reprinting, please send the reprint link to us; for articles with original markings, please send [Article Title - Name and ID of the Public Account Pending Authorization] to us to apply for whitelist authorization. Unauthorized reprints and adaptations will be pursued for legal responsibility. Contact email: [email protected].
Reply “Volunteer” to learn how to join us




Click the image to read the article
AI Dominates Human Games: Wu Enda Claims Its Significance is Comparable to AlphaGo (With Video)


