

This article is submitted by the authors of the paper

Introduction
Photonic Neural Networks (PNNs) aim to break through the bottleneck of classical von Neumann computer architecture. By using photons as the computational medium to build low-latency, high-energy efficiency, and high-bandwidth optoelectronic integrated computing processors, they are expected to support the computational power demands of large AI models in the post-Moore era.
However, limited by the dynamic system error accumulation present in analog computing systems, directly deploying the photonic neural network model parameters obtained from offline training to processors results in a sharp decline in task inference performance as the network scale increases. Existing online training methods face challenges such as the inability to accurately calculate network gradients, low layer-wise training efficiency, and the need for additional backpropagation hardware, making it difficult to apply to the training of large-scale photonic neural networks.
Recently, the research team of Assistant Professor Xing Lin from the Department of Electronics at Tsinghua University and the research team of Professor Hongkai Xiong from the Department of Electronics at Shanghai Jiao Tong University proposed a Dual Adaptive Training method for large-scale photonic neural networks (DAT), which enables the network to adapt to a large amount of dynamic system error accumulation through precise modeling of the network and dual backpropagation. They trained a photonic neural network architecture containing 280,000 neurons on simulation and experimental platforms for spatial optical computing and on-chip integrated optical computing, achieving significantly better training performance on classification tasks compared to current training methods.
This result was published in Nature Machine Intelligence, titled “Dual Adaptive Training of Photonic Neural Networks“. PhD students Ziyang Zheng and Zhengyang Duan are the co-first authors of the paper, with Assistant Professor Xing Lin and Professor Hongkai Xiong serving as co-corresponding authors. Other authors involved in the research include Postdoctoral Fellow Hang Chen, PhD student Sheng Gao, Engineer Haiou Zhang from Tsinghua University, and PhD student Rui Yang from Shanghai Jiao Tong University.
Video: Overview of the Dual Adaptive Training method for Photonic Neural Networks
Dual Adaptive Training Method
As shown in Figure 1, to overcome the problem of inaccurate network gradient calculation caused by system errors, researchers introduced a miniature system error prediction network module in the network modeling, connected to the PNN physical model through residual interconnections. For the input training samples, the training process performs end-to-end dual backpropagation, accurately calculating the network gradient from input to output while iteratively updating the PNN physical model parameters and the system error prediction network parameters. The training process includes the following four steps:
(1) System state measurement: The system inputs training samples and measures the output of the PNN physical system, with optional measurement of intermediate states in the system to assist in improving training performance.
(2) Model state extraction: The PNN model inputs the same training samples to extract the network output and intermediate states corresponding to the system’s positions.
(3) Optimize network modeling: Define a similarity loss function to compare the system state and model state, calculate the gradient of the system error prediction network, and update the network parameters.
(4) Optimize task inference: Define a task loss function, use the measured system state to replace the corresponding model state, calculate the gradient of the PNN physical model, update the network parameters, and deploy them to the system.
Optimizing network modeling can improve the modeling accuracy of the system, achieving more precise gradient calculations. Optimizing task inference allows the PNN physical model to adapt to dynamic system errors, achieving higher task execution performance. The two are interdependent and mutually reinforcing. The above steps iterate over the training dataset until convergence.
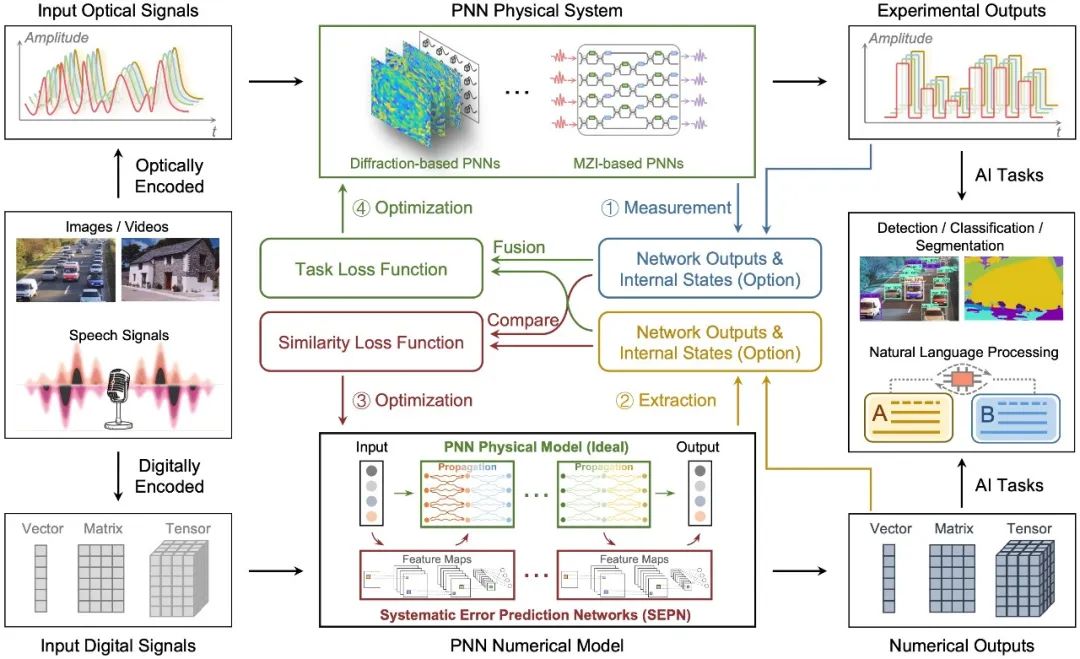
Figure 1: Dual Adaptive Training method for Photonic Neural Networks
Training Spatial Optical Computing Systems
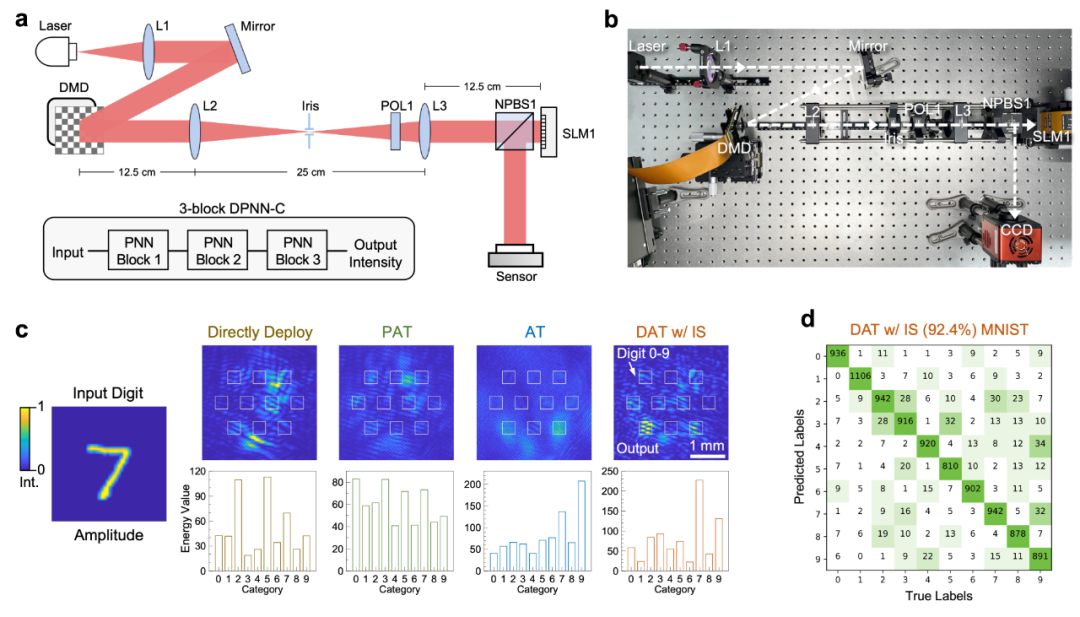
Researchers constructed a three-layer diffraction photonic neural network containing 120,000 neurons on the experimental platform to perform digit classification tasks on the MNIST dataset and product classification tasks on the Fashion-MNIST dataset. After modeling the ideal network model on a computer and completing training, the accuracy rates for digit and product classification were 93.7% and 85.6%, respectively. However, when the model parameters were directly deployed to the experimental platform, the accuracy dropped sharply to 28.3% and 11.1%, indicating significant system error accumulation on the experimental platform, severely affecting the task inference process. In addition to common geometric and manufacturing errors, researchers also observed dynamic readout errors and time-varying offset errors on the sensors of the experimental platform. After deploying the model parameters obtained from dual adaptive training to the experimental platform, the accuracy significantly improved to 92.4% and 77.3%, an increase of 64.1% and 66.2% compared to direct deployment.
Researchers also compared other state-of-the-art training methods, including Physics-Aware Training published in Nature in 2022 and Adaptive Training published in Nature Photonics in 2021. Experimental results showed that Physics-Aware Training and Adaptive Training could only improve the accuracy of digit classification to 39.6% and 53.1%, respectively, while being almost ineffective for product classification tasks, with accuracy hovering around 10%. In contrast, dual adaptive training improved the accuracy of digit classification tasks by 52.8% and 39.3%, and nearly 67% for product classification tasks. Figure 2c displays the output classification of the digit “7” in models obtained from different training methods, with only the dual adaptive training method achieving correct classification. Figure 2d shows the confusion matrix of the model obtained from dual adaptive training in the digit classification task, achieving an accuracy of 92.4%.
Researchers also built diffraction photonic neural networks with different architectures on simulation platforms to explore the effectiveness of different training methods under various complex system error environments. Figures 3a and 3b show the architectures of single-layer (DPNN-S) and multilayer interconnected (DPNN-M) photonic diffraction neural networks. The single-layer network modules consist of three segments of diffraction processes and two phase modulation layers, while the multilayer network consists of seven such modules interconnected in a complex manner, containing 280,000 neurons. For each architecture, researchers set three complex error environments, including horizontal shifts, vertical shifts, planar rotations, and phase shifts as various error sources, assuming errors could occur at any possible position. Figure 3c shows the accuracy rates of models obtained from various training methods for digit and product classification tasks. Whether the dual adaptive training method measures (w/ IS) or does not measure (w/o IS) intermediate states in the system, its performance consistently surpasses other methods, demonstrating greater advantages under large-scale networks. These results further validate the dual adaptive training method’s precise modeling of physical systems and accurate gradient calculations for updates. Notably, the system error prediction network module employs a miniature complex U-Net architecture, with only 26,909 parameters, about 0.347% of the standard U-Net parameter count (7,765,442).
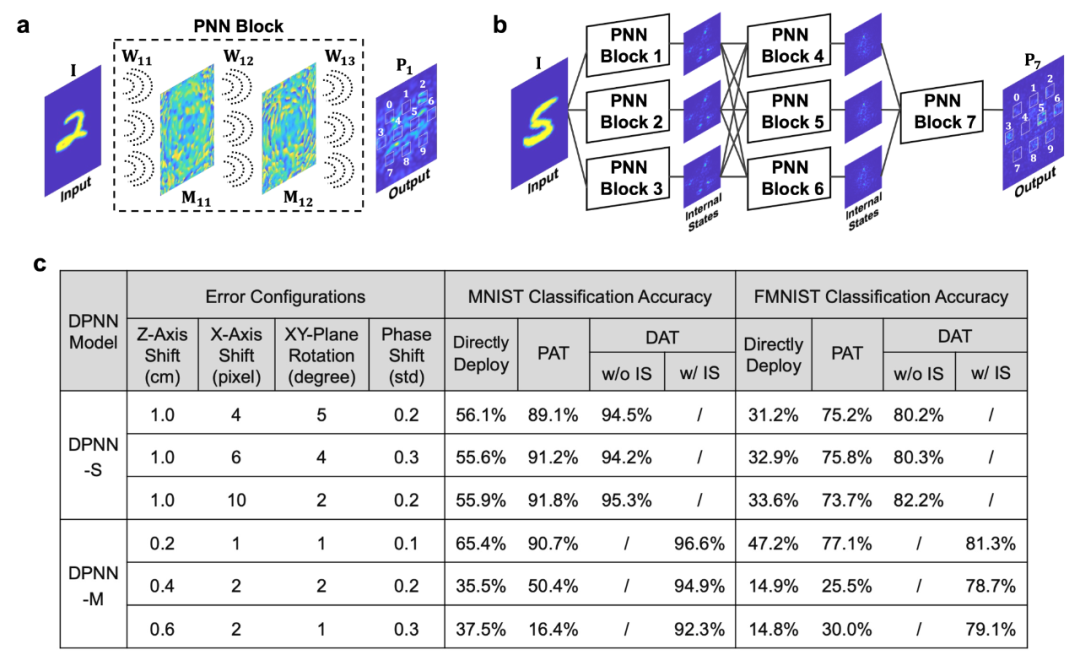
Figure 3: Training Diffraction Photonic Neural Networks with Different Architectures
Training On-Chip Integrated Optical Computing Systems
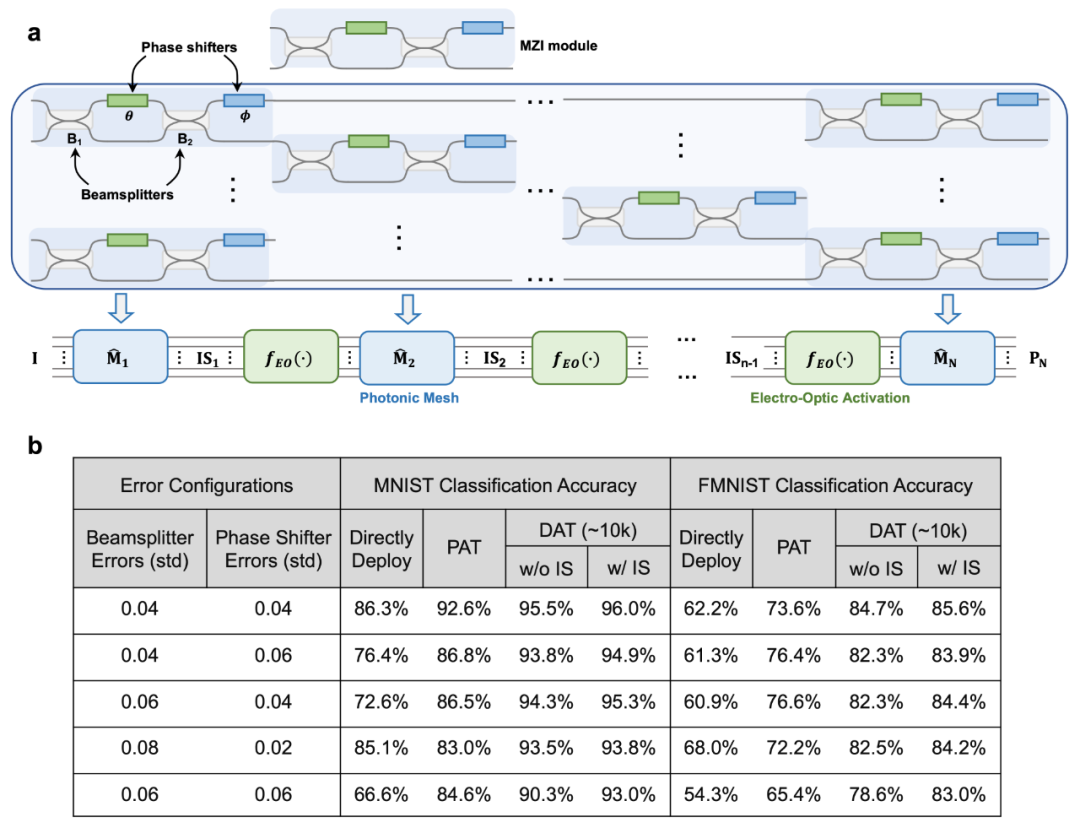
Researchers further validated the effectiveness of the dual adaptive training method on an on-chip integrated optical computing system constructed based on Mach-Zehnder Interferometers (MZI), as shown in Figure 4a. Coherent light inputs through on-chip waveguides into the MZI-integrated photonic mesh. Each MZI can achieve two-dimensional unitary transformations through phase modulation θ and ϕ, while the photonic network formed by special arrangements can achieve high-dimensional unitary transformations. The transformed optical signals propagate to the Electro-Optic Activation unit for nonlinear modulation. By repeating several rounds of the above process, a multilayer on-chip integrated optical computing system, also known as an interferometric photonic neural network, can be constructed.
Researchers built a three-layer interferometric photonic neural network with 24,576 programmable parameters on the simulation platform and explored the effectiveness of different training methods in on-chip error environments. The error sources were set as phase modulation errors occurring on the beam splitter and phase shifter within the MZI, assuming errors could occur at any possible position. Figure 4b shows the accuracy rates of models obtained from various training methods for digit and product classification tasks. The dual adaptive training method maintains stable and excellent training performance, outperforming other cutting-edge training methods, with greater advantages in severe error environments. For example, in the digit classification task under the last row of error environments, the dual adaptive training method improved classification accuracy by 28.7% when measuring intermediate states in the system, compared to ideal modeling training and direct deployment; and improved by 17.6% compared to Physics-Aware Training.
Summary and Outlook
Effective training methods are key technologies for achieving high-performance artificial intelligence systems. This study proposes the dual adaptive training method for training large-scale photonic neural networks, successfully training photonic neural networks based on spatial diffraction and on-chip interference under dynamic system error environments. The research addresses the challenge of accurately calculating network gradients, achieving end-to-end network parameter updates without requiring additional backpropagation hardware, making it applicable to training larger-scale photonic neural networks, and potentially extending to training any architecture of photonic neural networks as well as simulating neural networks, which is expected to promote the industrial application and widespread use of photonic neural networks.
Paper Information
Ziyang Zheng, Zhengyang Duan, Hang Chen, Rui Yang, Sheng Gao, Haiou Zhang, Hongkai Xiong & Xing Lin. Dual adaptive training of photonic neural networks. Nat Mach Intell (2023).
Editor: Zhao Wei
Welcome research teams to submit promotional articles, contact the editor via WeChat
WeChat: 447882024
