In fact, artificial intelligence has been a part of our lives for a long time. However, for many people, AI still seems like a rather “profound” technology. Yet, no matter how profound the technology is, it starts from basic principles. There are 10 major algorithms in the field of artificial intelligence that are based on simple principles, discovered and applied long ago, and even learned in high school, making them extremely common in everyday life.
1. Linear Regression
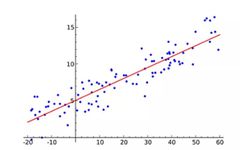
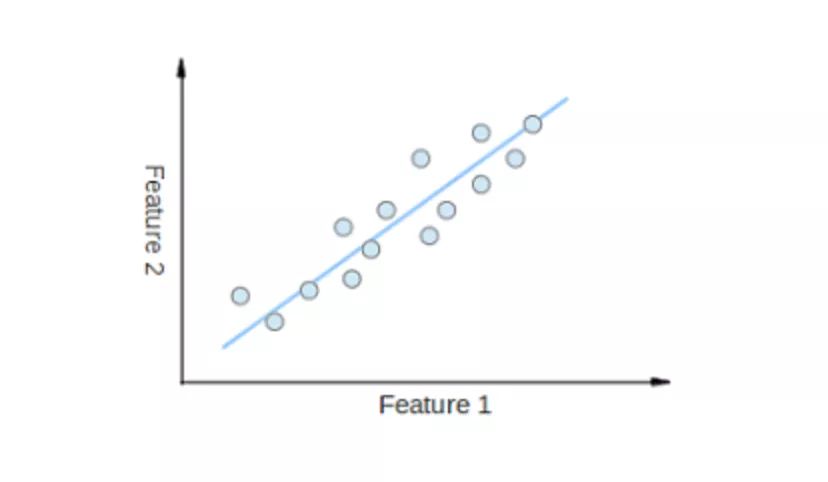
Linear Regression is possibly the most popular machine learning algorithm. Linear regression aims to find a straight line that fits the data points in a scatter plot as closely as possible. It attempts to represent the relationship between the independent variable (x values) and the numerical outcome (y values) by fitting the line equation to the data. This line can then be used to predict future values!
The most commonly used technique for this algorithm is the Least Squares Method. This method calculates the best fitting line to minimize the vertical distances from each data point to the line. The total distance is the sum of the squares of all the vertical distances (green line). The idea is to fit the model by minimizing this squared error or distance.
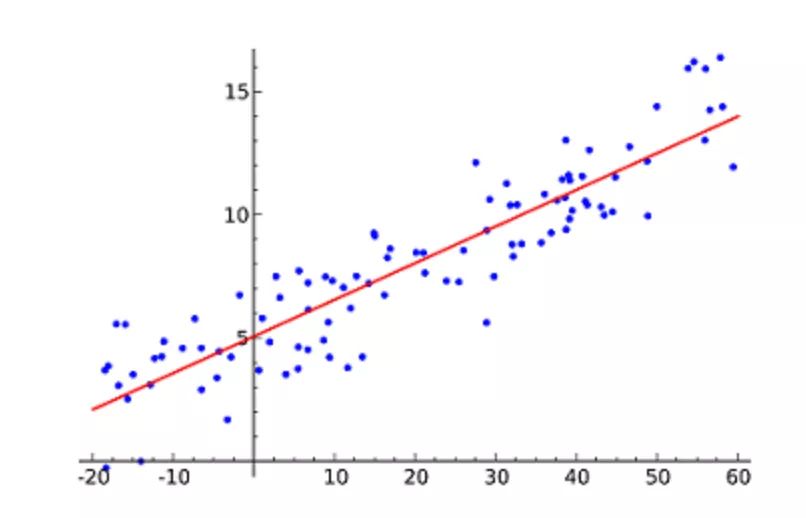
For example, simple linear regression has one independent variable (x-axis) and one dependent variable (y-axis).
It can be used to predict next year’s housing price increase, next quarter’s sales of a new product, etc. It sounds straightforward, but the challenge of the linear regression algorithm is not in obtaining the predicted values, but in how to achieve greater accuracy. For that possibly very subtle number, how many engineers have exhausted their youth and hair.
2. Logistic Regression
Logistic Regression is similar to linear regression, but the results of logistic regression can only have two values. While linear regression predicts an open numerical value, logistic regression is more like a yes or no question.
The range of Y values in the logistic function is from 0 to 1, representing a probability value. The logistic function typically has an S-shape, dividing the chart into two regions, making it suitable for classification tasks.
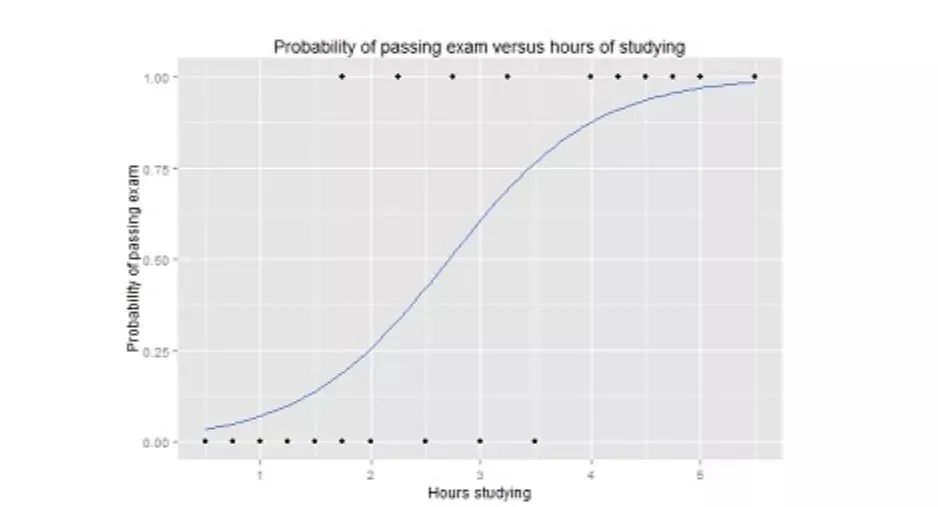
For instance, the logistic regression curve shown above illustrates the probability of passing an exam in relation to study time, which can be used to predict whether one can pass the exam.
Logistic regression is often used by e-commerce or food delivery platforms to predict user preferences for product categories.
3. Decision Trees
If linear and logistic regression complete tasks in one round, then Decision Trees are a multi-step process. They are also used for regression and classification tasks, but the scenarios are usually more complex and specific.
For example, a teacher faces a class of students and needs to determine who are good students. If the criterion is simply scoring 90 points, it seems too crude and does not account for other factors. For students scoring less than 90 points, we can discuss aspects like homework, attendance, and participation separately.
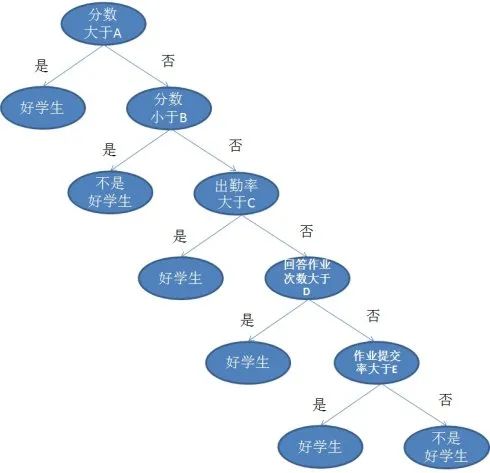
This is an example of a decision tree, where each branching circle is called a node.At each node, we ask questions about the data based on available features.The left and right branches represent possible answers.The final nodes (leaf nodes) correspond to a prediction value.
The importance of each feature is determined by a top-down approach. The higher the node, the more important its attribute. For instance, in the above example, the teacher considers attendance more important than homework, so the attendance node is higher, and naturally, the score node is higher.
4. Naive Bayes

The Naive Bayes classifier is a popular statistical technique, with classic applications in spam filtering.
Of course, I bet that 80% of people do not understand the above paragraph. (The 80% figure is just a guess, but experiential intuition is a kind of Bayesian calculation.)
To explain Bayes’ theorem in non-technical terms, it involves calculating the probability of A given B, to determine the probability of B given A. For example, if a kitten likes you, there is an a% chance it will roll over in front of you; what is the probability that the kitten rolling over in front of you means it likes you?
Of course, solving such problems is like shooting in the dark, so we need to introduce other data. For instance, if the kitten likes you, there is a b% chance it will cuddle with you and a c% chance it will purr. So how do we know how likely the kitten likes us? We can calculate it using Bayes’ theorem from the probabilities of rolling over, cuddling, and purring.
5. Support Vector Machine
The distance between the hyperplane and the nearest class point is called the margin. The optimal hyperplane has the largest margin, allowing for classification of points while maximizing the distance between the nearest data points and the two classes.
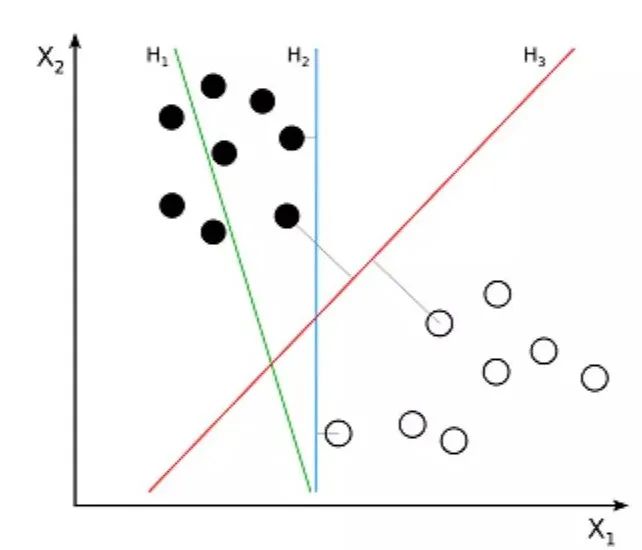
Thus, the problem SVM aims to solve is how to separate a set of data. Its main applications include character recognition, face recognition, text classification, and various other recognitions.
6. K-Nearest Neighbors (KNN)
The choice of K is critical: a smaller value may yield a lot of noise and inaccurate results, while a larger value is impractical. It is most commonly used for classification but can also be applied to regression problems.
The distance used to assess similarity between instances can be Euclidean distance, Manhattan distance, or Minkowski distance. Euclidean distance is the ordinary straight-line distance between two points. It is the square root of the sum of the squared differences of the point coordinates.
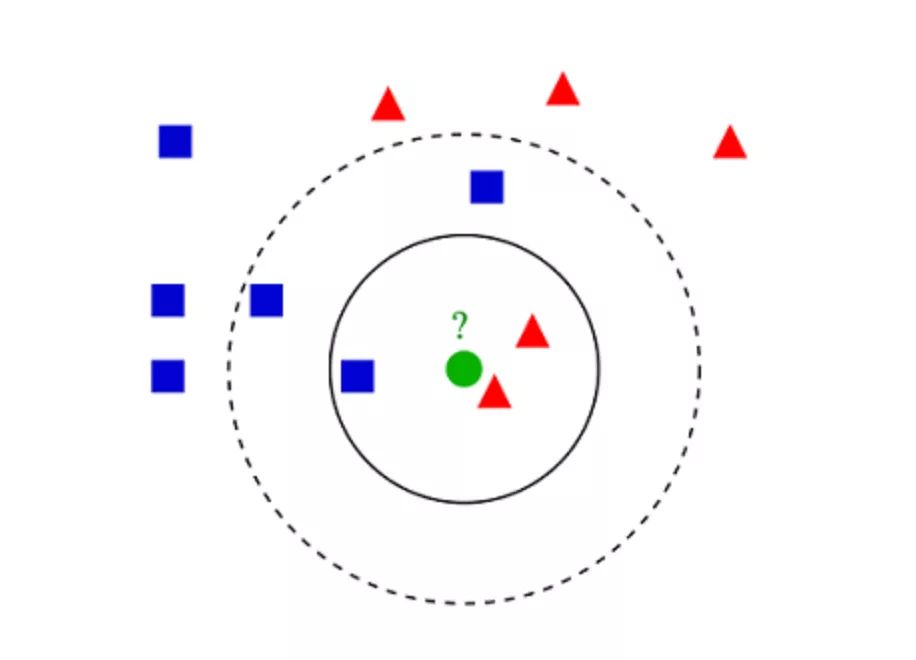
KNN classification example
KNN is theoretically simple, easy to implement, and can be used for text classification, pattern recognition, clustering analysis, etc.
7. K-Means
The algorithm iteratively assigns each data point to one of the K groups based on the features of each data point. It selects K points as K-cluster centroids. New data points are added to the cluster with the closest centroid based on similarity. This process continues until the centroids stop changing.

In real life, K-Means plays an important role in fraud detection and is widely used in the automotive, health insurance, and insurance fraud detection sectors.
8. Random Forest
Random Forest is a very popular ensemble machine learning algorithm.The basic idea of this algorithm is that the opinions of many people are more accurate than those of individuals.In Random Forest, we use an ensemble of decision trees (see Decision Trees).
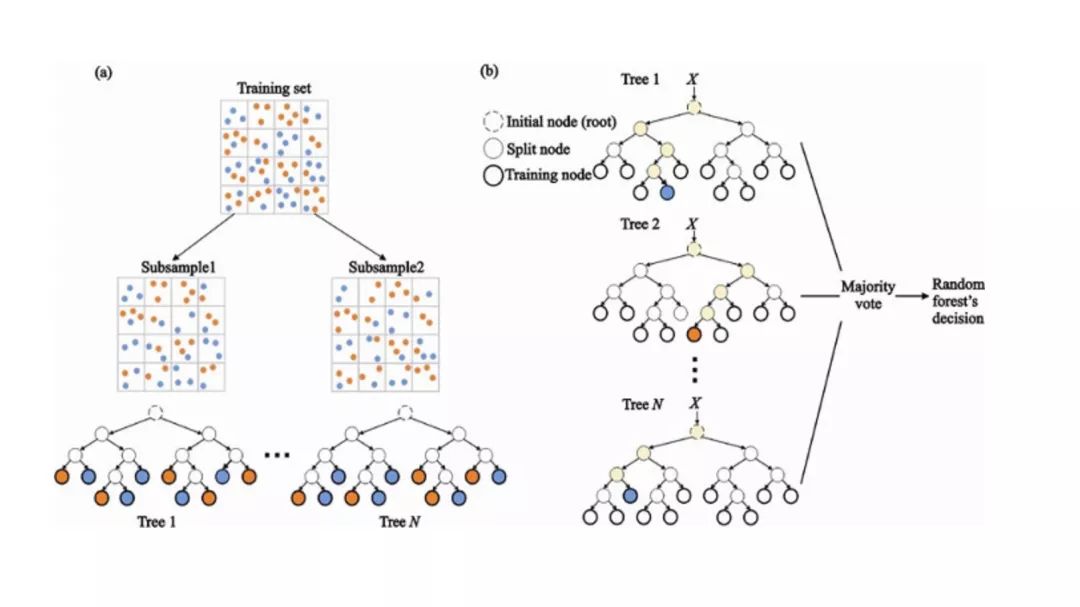
(b) During classification, decisions for input instances are made based on majority voting.
Random Forest has broad application prospects, from marketing to health insurance, and can be used for market simulation modeling, statistics on customer acquisition, retention, and churn, as well as predicting disease risks and patient susceptibility.
9. Dimensionality Reduction
Dimensionality Reduction attempts to solve this problem by combining specific features into higher-level features without losing the most important information. Principal Component Analysis (PCA) is the most popular dimensionality reduction technique.
PCA reduces the dimensionality of the data set by compressing it into low-dimensional lines or hyperplanes/subspaces, preserving the significant features of the original data as much as possible.
An example of dimensionality reduction can be achieved by approximating all data points to a straight line.
10. Artificial Neural Networks (ANN)
The working principle of artificial neural networks is similar to the structure of the brain. A group of neurons is assigned random weights to determine how neurons process input data. By training the neural network on input data, it learns the relationship between inputs and outputs. During the training phase, the system can access the correct answers.
If the network cannot accurately recognize the input, the system adjusts the weights. After sufficient training, it will consistently recognize the correct patterns.
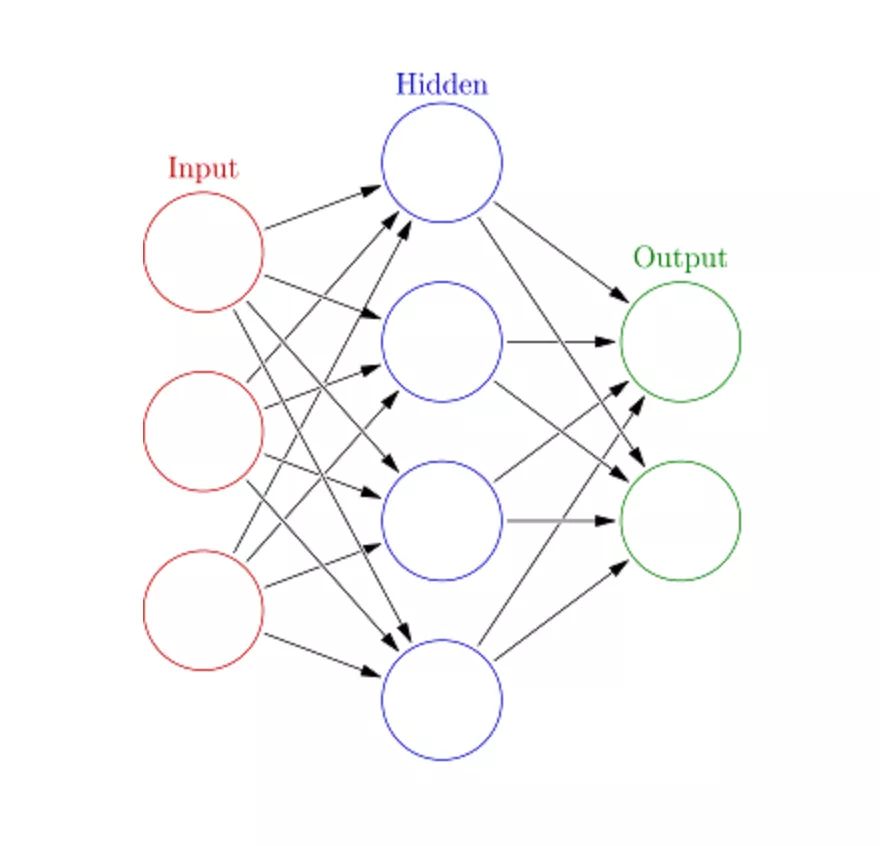
Each circular node represents an artificial neuron, and the arrows represent the connections from the output of one artificial neuron to the input of another.
Image recognition is a famous application within neural networks.
Now, you have gained a basic introduction to the most popular artificial intelligence algorithms and have some understanding of their practical applications.
Source: Robot Network