New Intelligence Report
New Intelligence Report
[New Intelligence Guide] A new paradigm combining large language models and AutoGPT has arrived!
This paper presents a comprehensive benchmark study of Auto-GPT agents in real-world decision-making tasks, exploring the application of large language models (LLMs) in decision-making tasks.

Paper link:https://arxiv.org/pdf/2306.02224.pdf
The authors compared the performance of several popular LLMs (including GPT-4, GPT-3.5, Claude, and Vicuna) in Auto-GPT decision tasks and introduced a new algorithm called “extra opinions,” which incorporates small expert models into the Auto-GPT framework to improve task performance.
Authors’ Perspectives
Authors’ Perspectives
The most interesting finding in this study is that large language models, especially GPT-4, have developed human-like abilities to extract useful information from different opinions, think critically, and improve their results.
So the question arises, how does GPT benefit from diverse opinions?
Psychological research has explored how humans benefit from diverse opinions and identified patterns, such as giving more weight to authoritative opinions, tending to ignore a few individual opinions, and overvaluing their own opinions; usually three to six opinions are sufficient, etc.
This direction is worth much follow-up research; for instance, we currently use a small expert model to provide different opinions; what if we let large models debate each other?
Main Contributions
Main Contributions
1. For the first time, it demonstrates that Auto-GPT can easily adapt to online decision tasks closely resembling real-world scenarios.
2. Provides a comprehensive benchmark comparison among popular LLMs (including GPT-4, GPT-3.5, Claude, and Vicuna). We present findings regarding the applicability of these models for autonomous agents.
3. It proves that obtaining second opinions from small expert models can significantly enhance task performance. This could become a new approach to introducing supervisory signals into Auto-GPT without model fine-tuning.
Experimental Setup
Experimental Setup
Prompt Design
Without large-scale tuning, we directly set the task requirements or questions as the objectives for Auto-GPT, adapting Auto-GPT for various tasks.
For example, inputting a sentence like “I want to purchase a folding storage box that is easy to install, made of faux leather, and has dimensions of 60x40x40cm.”
To help Auto-GPT understand the available actions, we represent each action as a tool.
Notably, the effectiveness of using only tool instructions without examples is poor. However, performance significantly improves with a few examples. Therefore, we include one to three few-shot examples in the tool demonstrations to leverage the LLM’s contextual learning capabilities.
Considering Extra Opinions
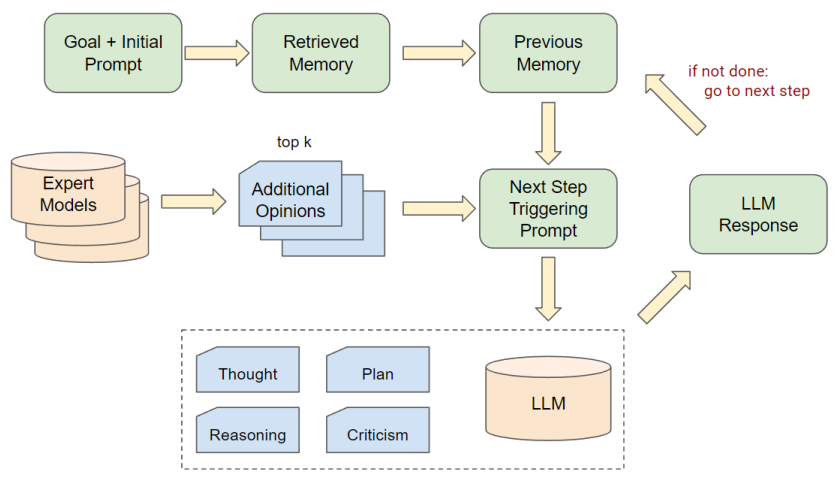
We further improved Auto-GPT’s workflow to consider extra opinions from external expert models.
Specifically, in the decision-making phase of Auto-GPT, we sample the top k opinions from expert models and include these opinions in the context of the prompt for the large language model to reference.
In this work, we simply utilized pre-prepared IL models as external experts for each task.
The prompt providing extra opinions to the LLM follows this template: ‘Here’s one(a few) suggestion(s) for the command: Please use this suggestion as a reference and make your own judgement.’
Webshop Experimental Setup:
Webshop is a simulated online shopping environment that scrapes over 1.18 million products from http://Amazon.com.
This environment provides a real action space for actions such as searching, clicking, navigating, and purchasing.
The evaluation process mainly looks at whether the described product was successfully purchased, requiring a match of product, attributes, options, and price.
The baseline model is one that employs imitation learning (IL) methods, with its action strategy component fine-tuned. This baseline model will be compared with the large language model operating in the Auto-GPT manner.
ALFWorld Experimental Setup
ALFWorld is a research environment that combines complex task orientation with language understanding.It contains over 25,000 unique, program-generated tasks covering real environments such as kitchens, living rooms, and bedrooms.
These tasks require complex problem-solving abilities and deep understanding of language and environment. Initial evaluations use imitation learning (IL) DAgger agents, and then comparisons are made with generative language models operating in an Auto-GPT style.
Experimental Results
Experimental Results
Direct Comparison Results
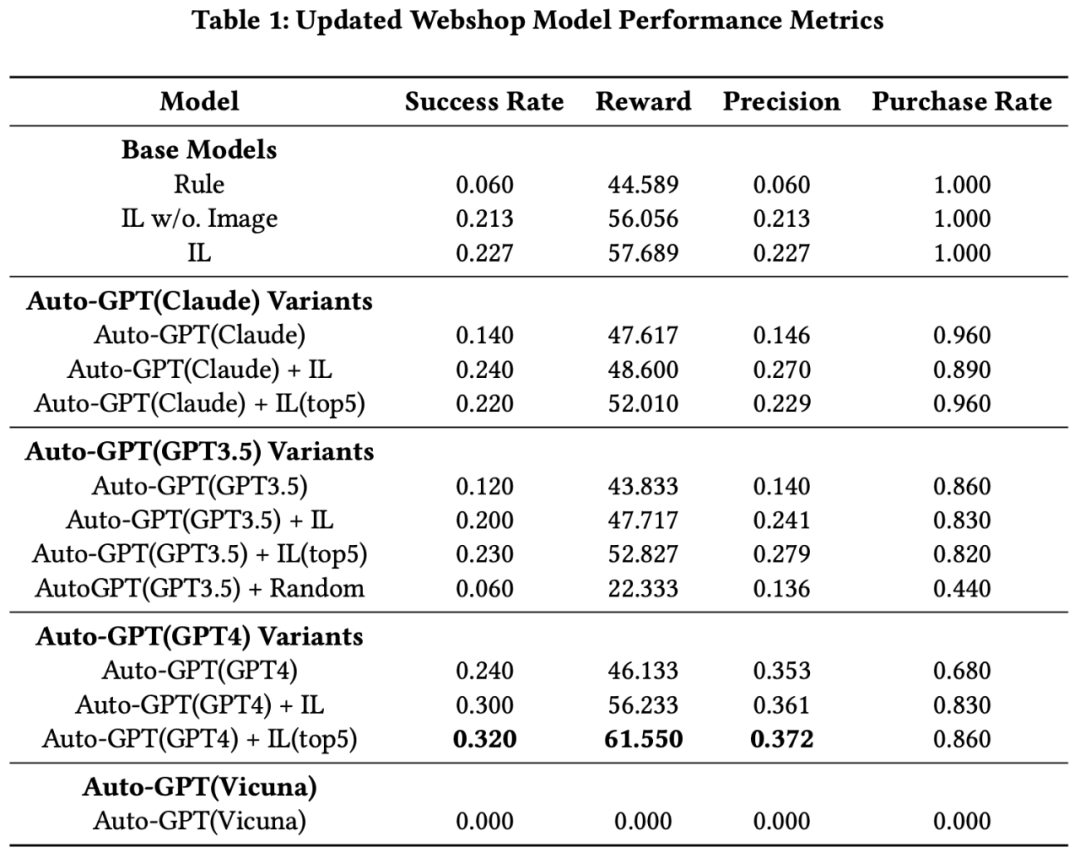
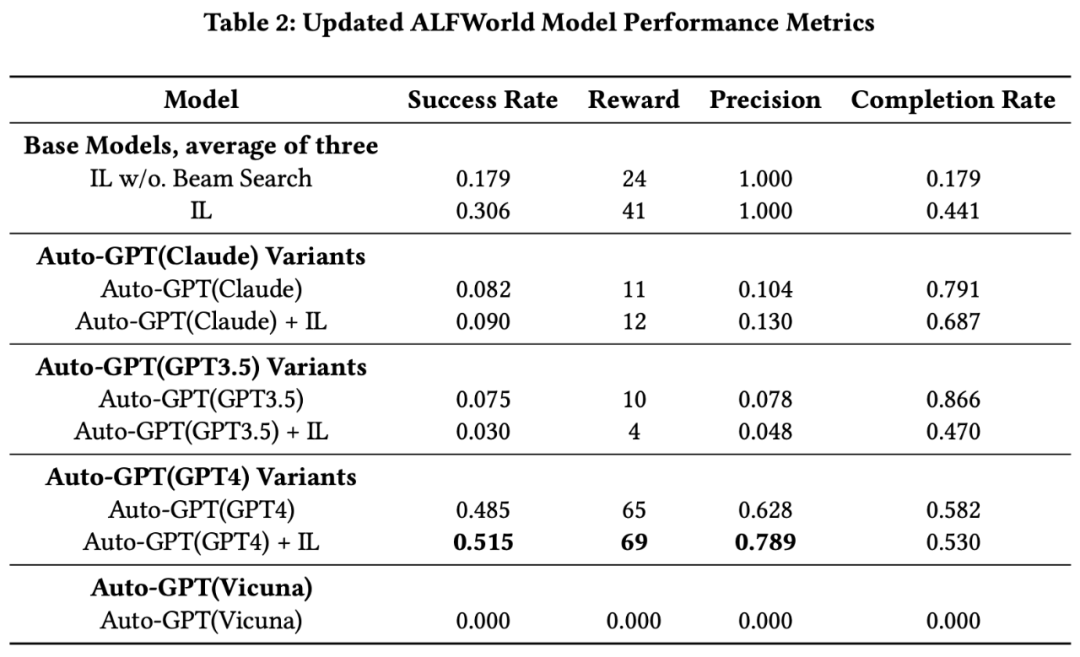
This study mainly compares the performance of different large language models (LLMs) and imitation learning (IL) models in AutoGPT configurations through the execution of two experiments: Webshop and ALFWorld.
First, in the Webshop experiment, GPT-4 performed excellently, surpassing other IL models. Although the original IL model without image input achieved only moderate success, the IL model with image input performed better.
However, Auto-GPT agents using only GPT-3.5 or Claude did not perform as well as the original IL model; nonetheless, the performance of GPT-4 itself exceeded all IL models.
Second, in the ALFWorld experiment, the combination of the IL model and Beam Search significantly outperformed the version without Beam Search. In contrast, the performance of Claude and GPT-3.5 running in the AutoGPT setup did not exceed that of the IL model, but GPT-4 clearly outperformed the IL model’s performance, regardless of whether Beam Search was used.
Moreover, we propose a new research model that combines large language models (LLMs) with expert models.
We first sample the top k additional viewpoints from expert models and present these viewpoints to LLMs, allowing them to consider these viewpoints and make final decisions. This method performed particularly well on GPT-4, indicating that GPT-4 can enhance its performance by considering opinions from multiple weak learning models.
Overall, GPT-4 demonstrated the best performance among all models and was able to effectively utilize the recommendations from expert models to enhance its decision-making capabilities.
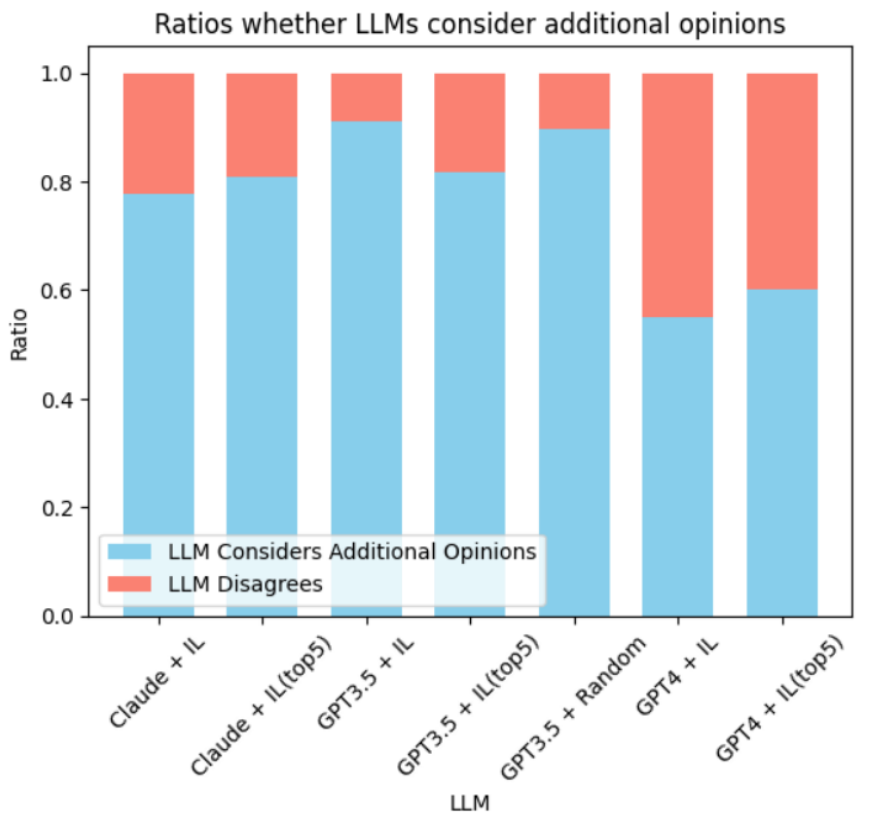
We recommend using GPT-4 because its decision-making performance significantly improves after considering the viewpoints of other models. Finally, the Ablation Study proves that these extra opinions must hold some value, as random opinions provide no help, see AutoGPT(GPT3.5) + Random.
Proportion of Extra Opinions Used
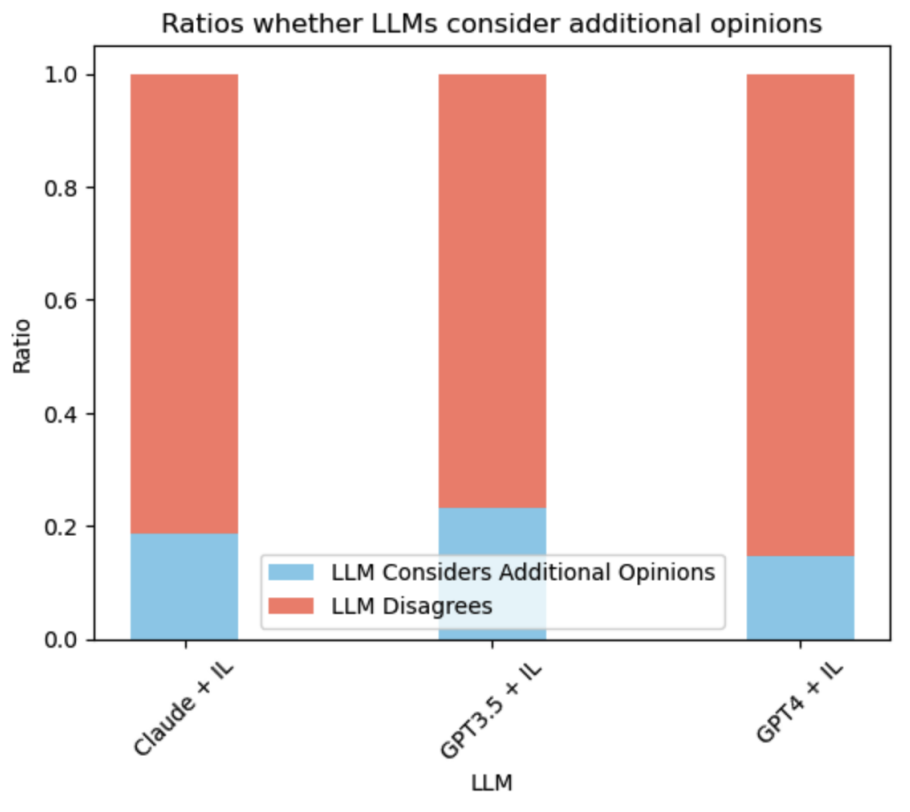
In our experiments, we found that the GPT-4 model exhibited a high level of discernment when handling extra opinions. Even amidst information noise, GPT-4 could distinguish between beneficial and irrelevant suggestions.
In contrast, the GPT-3.5 model showed a clear disadvantage when faced with potentially confusing inputs. Overall, the consistency or inconsistency of LLMs with extra opinions largely depends on the LLM’s comprehension ability and the quality of the extra opinions.