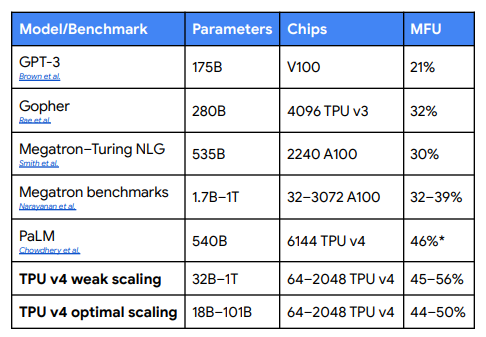
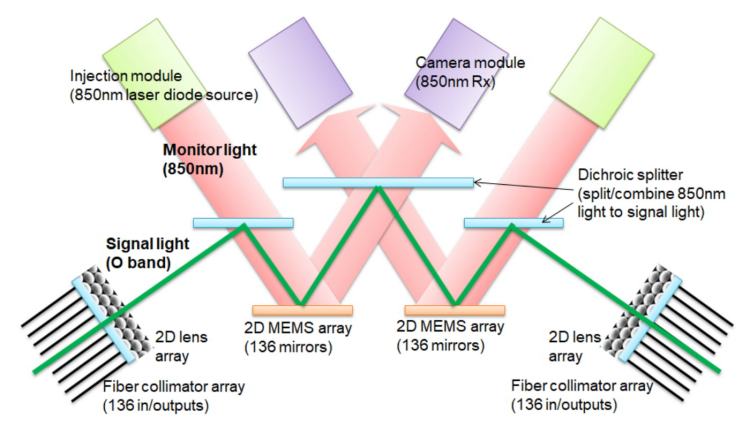
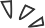This article is from the public account Silicon Star PeoplePro (ID: Si-Planet)Google’s large language model Gemini 1.0 has amazed everyone since its launch. In terms of performance, whether it is understanding text, images, and audio, or reasoning about texts in 57 fields and mathematical problems, it almost surpasses the dominant model in the natural language domain, GPT-4. Moreover, the official website of Google Gemini states, “Gemini is the first model to surpass human experts on MMLU (Massive Multitask Language Understanding).”What makes Google Gemini so powerful? The core reason comes from the two server-side inference chips used to train Google Gemini: TPU v4 and TPU v5e. Although both TPU and GPU are used for training and inference, they are fundamentally different in their “problem-solving approaches”.Google employs a technology called Optical Circuit Switch (OCS) on TPU v4. As the name suggests, this allows server clusters to transmit information using light. The upper part is the injection module, which uses an 850-nanometer laser diode to emit 850-nanometer display light. The middle part is a dichroic beam splitter used to split or combine light; the lower part is a 2D MEMS array used to reflect light; and the two ends are 2D lens arrays and optical fiber collimator arrays used to project O-band signal light.Basic Principle of OCSTraditional server clusters use copper wires for conduction, transmitting information by counting the number of electrons passing through the copper wire within a specified time. However, any medium, even gold or silver, incurs resistance, which inevitably slows down the speed of electron transmission. There are no optical-to-electrical conversion stages; everything is done by light to transport information without middlemen profiting from the transaction.Let’s compare this with the most common solution on the market, NVIDIA’s H100, which uses Infiniband technology. This technology employs a switched structure topology. All transmissions start or end at the channel adapter. Each processor contains a Host Channel Adapter (HCA), and each peripheral has a Target Channel Adapter (TCA).To put it bluntly, H100 is somewhat like a relay station. The relay station receives messages on behalf of the power center, allowing the manager to directly check their future tasks at the station. However, TPU v4 directly signals the smoke signals, which is not only faster but also bypasses all intermediate message relay facilities, achieving direct communication. According to Google, the cost of the OCS system and underlying optical components is less than 5% of the TPU v4 system cost, and its power consumption is less than 5% of the entire system, making it both cheap and effective.Speaking of this, we must mention a concept created by Google called MFU, which stands for Model FLOPs Utilization. This is a different method of measuring computational utilization that does not include any operations during backpropagation, meaning that the efficiency measured by MFU directly translates to end-to-end training speed. This means that the maximum limit of MFU must be 100%, and the higher the number, the faster the training speed.Google aims to use the concept of MFU to evaluate the load capacity and operational efficiency of TPU v4, thereby determining how much intensity can be applied to Google Gemini. In-depth benchmarking tests were conducted on a series of pure decoder transformer language models (with GPT as an example), where the model sizes (in billions of parameters) were half the number of chips.MFU of TPU v4 in Different ScenariosIn Google’s benchmarking activities, TPU v4 achieved an MFU of 44-56%. The comparison in the following figure clearly shows this, especially in the case of multiple TPU v4s connected in series. This is the magic of OCS, and Google also hopes to convey a message to the world: “Believe in light.”Comparison of MFU Across Different ChipsSince TPU v4 is so powerful, TPU v5e, as the iterative product, will only be better. In fact, the reason Google named this model Gemini is also due to these two TPUs. The meaning of Gemini is the zodiac sign Gemini, representing the twin brothers Castor and Pollux born from Zeus and Leda in Greek mythology. In a sense, TPU v4 and TPU v5e are also twins, hence the name Gemini. Of course, there is another possibility that the developers particularly like “Saint Seiya,” where the main antagonist in the Golden Twelve Palaces arc is Saga of Gemini, whose ultimate move is the Galaxy Explosion. However, I think the latter possibility is lower.Additionally, the largest cost of a server comes from operation and maintenance. However, under such a scale, it is impossible to maintain high throughput using traditional periodic weight checkpointing methods for persistent cluster storage, as it requires periodically shutting down and restarting a certain cluster. Therefore, for Gemini, Google uses redundant memory copies of the model state, allowing for quick recovery from a complete model copy in the event of any unplanned hardware failures. Compared to PaLM and PaLM-2, although a large amount of training resources were used, this greatly sped up recovery time. As a result, the overall output of the largest training tasks increased from 85% to 97%.Google Gemini’s server cluster is also the first supercomputer to support embedded hardware. Embedding is an algorithm closely related to Google’s business. Embedding itself is a relatively low-dimensional space where the model can convert high-dimensional vectors into this low-dimensional space. With embedding, it becomes easier to perform machine learning on large data inputs such as sparse vectors representing words. Ideally, embedding positions semantically similar inputs close to each other in the embedding space to capture some semantics of the input.Embedding is a key component of deep learning recommendation models (DLRM) used in advertising, search ranking, YouTube, and Google Play. Each TPU v4 contains third-generation sparse core data flow processors that can accelerate models that rely on embedding by 5 to 7 times, while using only 5% of the chip area and power consumption.Embedding processing requires a large amount of end-to-end communication because embeddings are distributed across TPU chips working collaboratively on the model. This pattern emphasizes the bandwidth of shared memory interconnects. This is why TPU v4 uses a 3D toroidal interconnect (compared to the 2D toroidal interconnect used in TPU v2 and v3). The 3D toroidal interconnect of TPU v4 provides higher bisection bandwidth, which helps support a larger number of chips and better demonstrate sparse core performance.TPU v4There is no doubt that Google is a software company, and Google Gemini is a software product, but Google excels in hardware. Google emphasizes that Gemini is a powerful multimodal model. Multimodal refers to combining various sensory input forms to make more informed decisions, meaning the model can solve problems using complex, diverse, and unstructured data.A short video (from 360p to 1080p) has a data volume of about tens of MB to hundreds of MB, a voice data volume of about several hundred KB, and a line of text data volume of about several bytes. For traditional large language models, if only processing text information, the load requirements on the server will not be high, as the data volume is small. However, once video, images, etc., are processed together, the server load will increase exponentially. In fact, it is not that other models cannot handle multimodal data; it is that other servers cannot withstand such large data volumes, with hardware dragging down software. Google dares to tackle this challenge primarily because TPU v4 and TPU v5e can handle high loads and high MFU in large-scale interconnected scenarios, which is undoubtedly Google’s trump card.However, Google cannot celebrate too early. First of all, NVIDIA’s tensor computing GPU H200 will be released in a few days. Major clients like Open AI are likely to get their hands on it first. At that time, whether for inference or training, GPT may reach an extremely exaggerated level.Secondly, Microsoft has also taken action. In 2019, Microsoft launched a project called Athena. It involves designing and developing custom AI chips to meet the unique needs of training large language models and driving AI applications. Like TPU, Athena is also an internal project that can reduce reliance on third-party hardware providers like NVIDIA. Athena is an extremely secretive project; its performance and appearance are completely unknown to the outside world. The only information available is that some lucky Open AI employees have already begun testing Athena.Although it is unclear what changes H200 and Athena can bring to Open AI, it is certain that both Google and Google Gemini are under significant pressure.
What Does TPU Mean for Google?
Speaking of Google’s TPU, there is a small story. TPU stands for Tensor Processing Unit, which is a dedicated integrated circuit (ASIC) developed by Google to accelerate machine learning. Although Google publicly announced the use of TPU at the I/O conference in May 2016, the TPU had already been developed in 2015.Neural machine translation technology was proposed in September 2014, and Baidu launched the first internet NMT system (neural machine translation system) in May 2015. NMT technology overcomes the shortcomings of traditional methods that segment sentences into different fragments for translation, fully utilizing contextual information to encode and decode sentences as a whole, thus producing smoother translations.However, at that time, the technology for neural translation placed a heavy load on servers, mainly because the hardware was not powerful enough, and products like H100 and A100 did not exist. From published papers and Google’s blogs, it can be seen that Google actually had such technology at that time, but the core reason for not using it was that the hardware could not withstand it. After about six months of testing, TPU was perfectly adapted to servers and used as an algorithm accelerator. When it came to the I/O conference day, Google bit the bullet and said, “We also have NMT now!”Google’s TPU was initially not open to the public, and it wasn’t until 2018 that cloud TPU services began to emerge. Users can purchase TPU on the cloud to quickly solve tensor computation business needs. In 2022, Google updated the TPU v4 business on the cloud, which means users can also purchase and use the various technologies mentioned above to enjoy higher inference and training capabilities.The biggest difference between Google and Open AI is that the former has strong business requirements; Google Gemini will not be a money-making tool. For most people, it is more like a new high-tech toy. However, cloud TPU v4 is different; as of the quarter ending March 31, Google’s cloud business revenue was $7.4 billion, with an operating profit of $191 million and a profit margin of 2.5%. Google Cloud business achieved its first profitability, but the profit margin is still too low, especially compared to Amazon Cloud’s 28% profit margin. Therefore, cloud TPU has become a significant growth point for Google’s business. If Google Gemini performs well, it will undoubtedly be a game-changer for promoting Google Cloud TPU business.Cool Play Lab Authorized ReprintFor reprints, please contact the original authorWhat Is Behind Google Gemini
 Basic Principle of OCS
Basic Principle of OCS MFU of TPU v4 in Different Scenarios
MFU of TPU v4 in Different Scenarios