

Authorized Reprint by Author
Author: Li Wenzhe
Excerpt from: Inclusive Big Data Center
Introduction
The Knowledge Graph is currently a hot research topic. Since Google launched its first version of the Knowledge Graph in 2012, it has sparked a wave of interest in both academia and industry. Major internet companies quickly launched their own Knowledge Graph products in response. For instance, in China, internet giants Baidu and Sogou launched “Zhixin” and “Zhilifang” respectively to improve their search quality. So, compared to these traditional internet companies, what applications can Knowledge Graphs have in the rapidly evolving industry of Internet Finance?
Table of Contents
1. What is a Knowledge Graph?
2. Representation of Knowledge Graphs
3. Storage of Knowledge Graphs
4. Applications
5. Challenges
6. Conclusion
1. What is a Knowledge Graph?
A Knowledge Graph is essentially a semantic network, a data structure based on graphs, composed of nodes (Point) and edges (Edge). In a Knowledge Graph, each node represents an “entity” that exists in the real world, and each edge represents the “relationship” between entities. Knowledge Graphs are the most effective way to represent relationships. In simpler terms, the Knowledge Graph connects all different types of information (Heterogeneous Information) into a relational network. It provides the ability to analyze problems from the perspective of relationships.
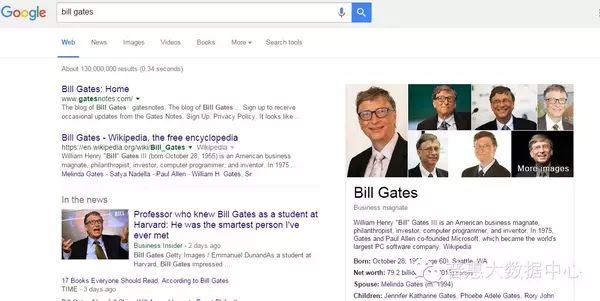
The concept of Knowledge Graph was first proposed by Google, mainly to optimize existing search engines. Unlike traditional keyword-based search engines, Knowledge Graphs can better query complex relational information, understanding user intent at the semantic level and improving search quality. For example, when you enter ‘Bill Gates’ in Google’s search box, the right side of the search results page displays related information such as birth date, family background, etc.
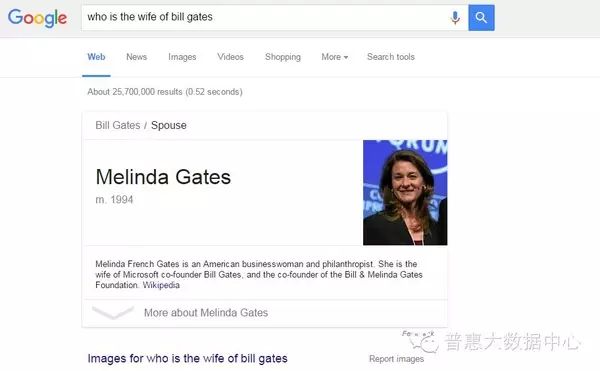
Additionally, for slightly more complex search queries like “Who is the wife of Bill Gates?”, Google can accurately return his wife, Melinda Gates. This indicates that the search engine truly understands user intent through the Knowledge Graph.
The Knowledge Graphs mentioned above belong to a broad category, addressing issues like search engine optimization and question-answering systems in general domains. Next, we will look at the representation and applications of domain-specific Knowledge Graphs, which are also of great interest in the industry.
2. Representation of Knowledge Graphs
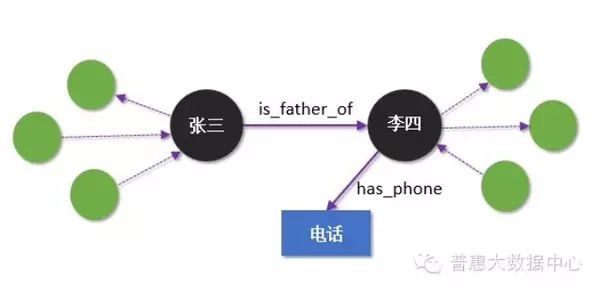
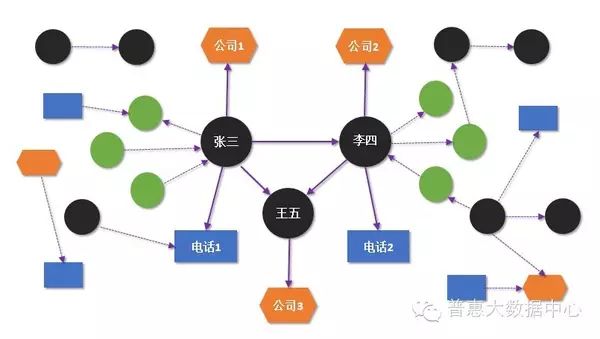
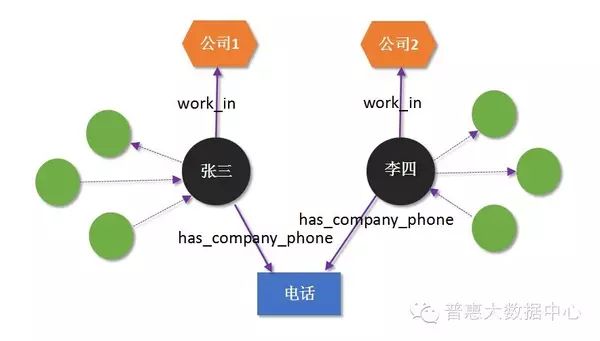
Suppose we use a Knowledge Graph to describe a fact – “Zhang San is Li Si’s father”. Here, the entities are Zhang San and Li Si, and the relationship is “father” (is_father_of). Of course, Zhang San and Li Si may have other types of relationships with other people (not considered for now). When we also add phone numbers as nodes to the Knowledge Graph (phone numbers are also entities), we can define a relationship called has_phone, indicating that a phone number belongs to a person. The following diagram illustrates these two different relationships.
Furthermore, we can add time as a property (Property) to the has_phone relationship to indicate when the phone number was activated. Such properties can be added to both relationships and entities, resulting in a graph called a property graph. Both property graphs and traditional RDF formats can be used as representations and storage methods for Knowledge Graphs, but there are differences, which will be briefly explained in later chapters.
3. Storage of Knowledge Graphs
Knowledge Graphs are based on graph data structures, and their storage methods mainly come in two forms: RDF storage format and graph databases (Graph Database). For differences, please refer to [1]. The following curve shows the development of various data storage types in recent years. Here, we can clearly see the rapid growth of graph-based storage methods in the entire database storage field. This curve is sourced from Graph DBMS increased their popularity by 500% within the last 2 years.
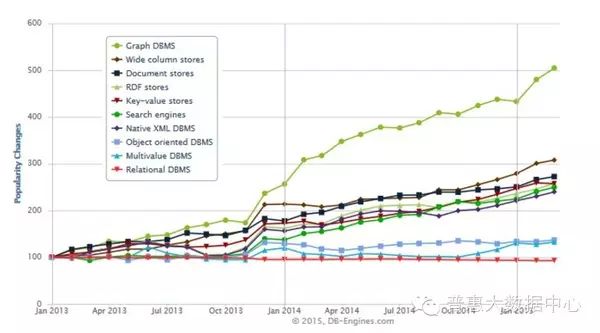
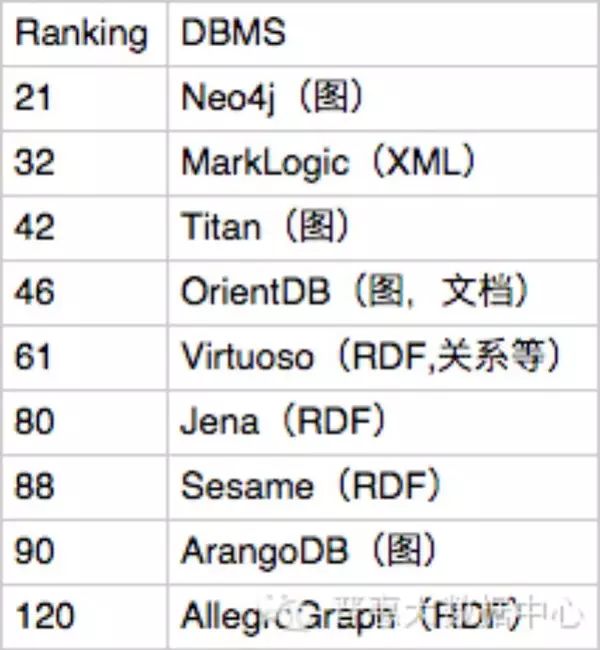
The following list shows the current popular rankings of graph-based storage databases. From this ranking, it can be seen that neo4j occupies the NO.1 position in the entire graph storage field, and Jena remains the most popular storage framework in the RDF field so far. This data is sourced from DB-Engines Ranking.
Of course, if the Knowledge Graph to be designed is very simple, and queries do not involve more than one degree of association, we can also choose to use relational data storage formats to save the Knowledge Graph. However, for slightly more complex relational networks (real-life entities and relationships are generally complex), the advantages of Knowledge Graphs become very clear. Firstly, the efficiency of associative queries will be significantly improved compared to traditional storage methods. When we involve 2nd or 3rd degree associative queries, the query efficiency based on Knowledge Graphs can be thousands or even millions of times higher. Secondly, graph-based storage is designed to be very flexible, typically requiring only local changes. For example, if we have a new data source, we can simply insert it into the existing graph. In contrast, relational storage methods are less flexible, as all schemas are predefined, and any subsequent changes can be very costly. Finally, storing entities and relationships in a graph data structure is the best way to align with the overall narrative logic.
4. Applications
In this article, we mainly discuss the applications of Knowledge Graphs in the Internet Finance industry. Of course, many application scenarios and ideas can be extended to other industries. The application scenarios mentioned here are just the tip of the iceberg; Knowledge Graphs can still unleash their potential value in many other applications, which we will continue to discuss in future articles.
Fraud Prevention
Fraud prevention is a crucial aspect of risk control. The challenge of big data-based fraud prevention lies in how to integrate data from different sources (structured and unstructured) and build a fraud prevention engine to effectively identify fraud cases (such as identity fraud, group fraud, agency packaging, etc.). Moreover, many fraud cases involve complex relational networks, presenting new challenges for fraud review. Knowledge Graphs, as a direct representation of relationships, can effectively address these two issues. Firstly, Knowledge Graphs provide a very convenient way to add new data sources, as mentioned earlier. Secondly, Knowledge Graphs are inherently designed to represent relationships, and this intuitive representation can help us analyze specific potential risks present in complex relationships more effectively.
The core of fraud prevention is people; we first need to connect all data sources related to the borrower and build a Knowledge Graph that encompasses multiple data sources, integrating into a structured knowledge that a machine can understand. Here, we can integrate not only the borrower’s basic information (such as the information filled out at the time of application) but also the borrower’s consumption records, behavior records, and online browsing records into the entire Knowledge Graph for analysis and prediction. One challenge here is that much of the data is unstructured data obtained from the internet, requiring the use of machine learning and natural language processing techniques to convert this data into structured data.
Inconsistency Verification
Inconsistency verification can be used to assess a borrower’s fraud risk, which is similar to cross-validation. For example, if borrower Zhang San and borrower Li Si provide the same company phone number but list completely different companies, this becomes a risk point that needs extra attention from the review staff.
Similarly, if a borrower claims to be friends with Zhang San and father-son with Li Si, when we try to add the borrower’s information to the Knowledge Graph, the “inconsistency verification” engine will trigger. The engine first reads the relationship between Zhang San and Li Si to verify whether this “triangular relationship” is correct. Clearly, friends of friends are not father-son relationships, indicating a significant inconsistency.
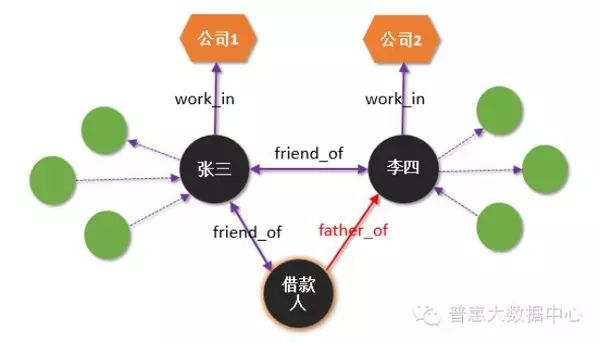
Inconsistency verification involves knowledge reasoning. In simple terms, knowledge reasoning can be understood as “link prediction”, which derives new relationships or links from existing relationship graphs. For instance, in the above example, if Zhang San and Li Si are friends, and Zhang San is also a friend of the borrower, we can infer that the borrower is also a friend of Li Si.
Group Fraud
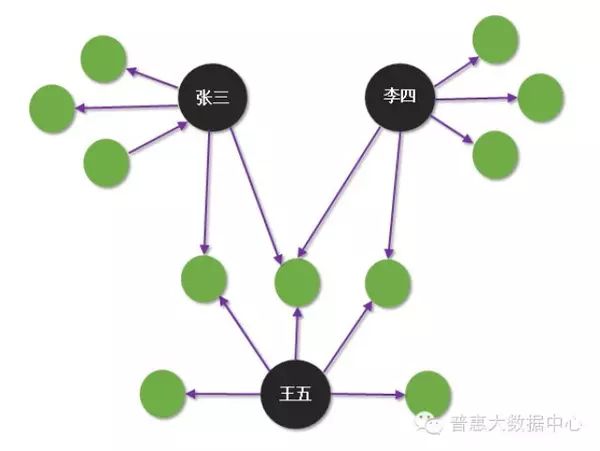
Compared to identifying false identities, uncovering group fraud is more challenging. Such organizations hide within very complex relational networks and are not easily detected. Only by clarifying the implicit relational networks can we analyze and discover the potential risks within. Knowledge Graphs, as a natural tool for analyzing relational networks, can help us more easily identify these potential risks. For example, some members of group fraud may apply for loans using false identities, but some information is shared. The diagram below roughly illustrates this situation. From the diagram, it can be seen that Zhang San, Li Si, and Wang Wu have no direct relationships, but through the relational network, we can easily see that these three share certain information, which immediately raises concerns about fraud risk. Although group fraud can take many forms, one thing is certain: Knowledge Graphs will provide better analytical tools than any other tools.
Anomaly Detection
Anomaly detection is a significant topic in the field of data mining research. We can simply understand it as finding “anomalies” from given data. In our application, these “anomalies” may be associated with fraud. Since Knowledge Graphs can be viewed as a graph, anomaly detection in Knowledge Graphs is largely based on the structure of the graph. Due to the different types of entities and relationships in Knowledge Graphs, anomaly detection must also consider this additional information. Most graph-based anomaly detection computations are relatively intensive and can be performed offline. In our application framework, anomaly detection can be divided into two main categories: static analysis and dynamic analysis, which will be discussed one by one.
– Static Analysis
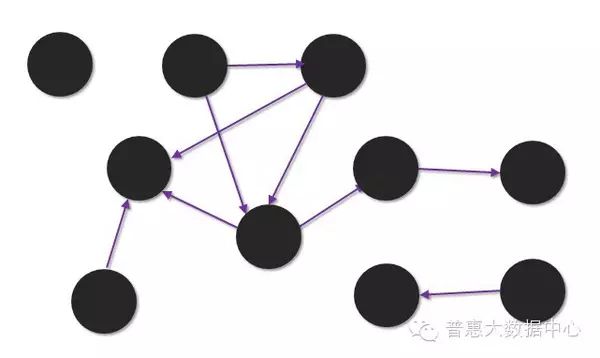
Static analysis refers to discovering some anomalies (such as anomalous subgraphs) given a graph structure and a certain point in time. In the diagram below, we can clearly see that the mutual density of five points is very high, indicating a possible fraud organization. Therefore, further analysis can be conducted on these anomalous structures.
– Dynamic Analysis
Dynamic analysis refers to analyzing the trend of structural changes over time. Our assumption is that in a short period, the structure of the Knowledge Graph will not change significantly; if it changes a lot, it indicates possible anomalies that require further attention. Analyzing structural changes over time will involve time series analysis techniques and graph similarity computation techniques. Interested readers can refer to materials on this topic [2].
Lost Customer Management
In addition to pre-loan risk control, Knowledge Graphs can also play a powerful role in post-loan management. For instance, in managing lost customers after a loan, Knowledge Graphs can help us uncover more potential new contacts, thereby increasing the success rate of collections.
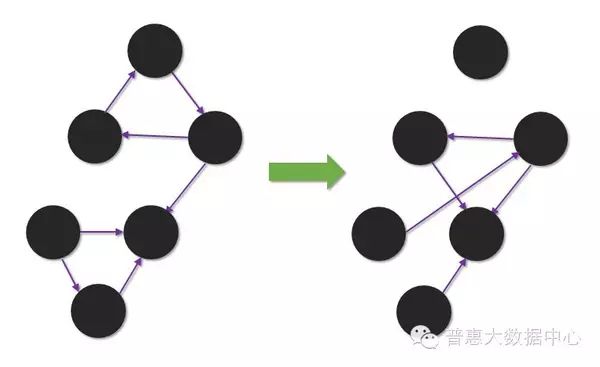
In reality, many borrowers stop repaying after successfully borrowing and play “hide and seek,” making it difficult to contact them. Even attempts to reach out to other contacts the borrower provided previously may fail. This leads to a so-called “lost contact” state, leaving collectors at a loss. The next question is, in the case of lost contact, can we uncover new contacts related to the borrower? Moreover, this group of people does not appear as associated contacts in our Knowledge Graph. If we can uncover more potential new contacts, it will significantly improve the success rate of collections. For example, in the relationship graph below, the borrower has a direct relationship with Li Si, but we cannot contact Li Si. Is it possible to predict and determine which of Li Si’s contacts might know the borrower through second-degree relationship analysis? This involves analyzing the structure of the graph.
Intelligent Search and Visualization
Based on Knowledge Graphs, we can also provide intelligent search and data visualization services. The function of intelligent search is similar to the application of Knowledge Graphs in Google and Baidu. That is, for each search keyword, we can return richer and more comprehensive information through the Knowledge Graph. For instance, when searching for a person’s ID number, our intelligent search engine can return all historical loan records, contact information, behavioral characteristics, and labels (such as blacklist, peers, etc.) related to that person. Additionally, the benefits of visualization are obvious; by visualizing complex information in a very intuitive way, we can clearly see the ins and outs of hidden information.
Precision Marketing
“A knowledge graph allows you to take core information about your customer—their name, where they reside, how to contact them—and relate it to who else they know, how they interact on the web, and more”– Michele Goetz, a Principal Analyst at Forrester Research
A smart company can uncover its potential customers more effectively than its competitors. In the internet age, marketing methods are diverse, but no matter how many ways there are, they all revolve around one core – analyzing and understanding users. Knowledge Graphs can combine various data sources to analyze the relationships between entities, leading to a better understanding of user behavior. For example, a company’s marketing manager can use Knowledge Graphs to analyze relationships among users to discover common preferences within an organization, thus formulating targeted marketing strategies for certain groups. Only by better and deeper (Deep understanding) understanding user needs can we improve our marketing efforts.
5. Challenges
Knowledge Graphs have not yet formed large-scale applications in the industry. Even though some companies are trying to move in this direction, many are still in the research phase. The main reason is that many companies do not understand Knowledge Graphs or do not have a deep understanding of them. However, one thing is certain: Knowledge Graphs will undoubtedly become a hot tool in the industry in the coming years, which is easily predictable from current trends. Of course, since Knowledge Graphs are a relatively new tool, there will inevitably be challenges in practical applications.
Data Noise
Firstly, there is a lot of noise in the data. Even for data that already exists in the database, we cannot guarantee 100% accuracy. Here, we will discuss from two aspects. First, the accumulated data itself has errors, so this erroneous data needs to be corrected. The simplest correction method is to perform offline inconsistency verification, as mentioned earlier. Second, there is data redundancy. For example, borrower Zhang San lists the company name as “Puhui,” borrower Li Si lists it as “Puhui Finance,” and borrower Wang Wu lists it as “Puhui Financial Information Service Co., Ltd.” Although all three belong to the same company, the different names lead the computer to think they are from different companies. The next question is how to identify these ambiguous names from massive data and merge them into one name. This involves disambiguation techniques in natural language processing.

Unstructured Data Processing Capability
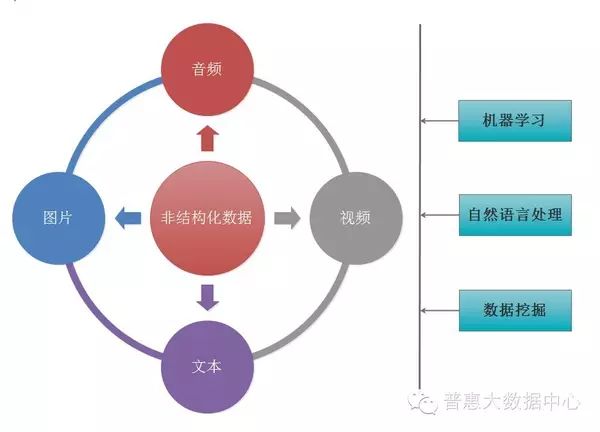
In the era of big data, much of the data is unprocessed unstructured data, such as text, images, audio, and video. Especially in the Internet Finance industry, we often face a large amount of text data. Extracting valuable information from these unstructured data is a highly challenging task, which raises the bar for machine learning, data mining, and natural language processing capabilities.
Knowledge Reasoning
Reasoning ability is an important feature of human intelligence, allowing us to discover implicit knowledge from existing knowledge. General reasoning often requires some rules of support [3]. For example, the “friend” of a “friend” can infer a “friend” relationship, and a “father’s” “father” can infer a “grandfather” relationship. For instance, if Zhang San has many friends who are also friends of Li Si, we can speculate that Zhang San and Li Si are likely to be friends. Of course, this involves probability issues. When the amount of information is particularly large, how to effectively combine this information (side information) with reasoning algorithms is crucial. Common reasoning algorithms include logic-based reasoning and distributed representation-based reasoning. As deep learning becomes increasingly important in artificial intelligence, reasoning based on distributed representations has also become a hot research topic. Interested readers can refer to the latest work in this area [4,5,6,7].
Big Data, Small Samples, and Building Effective Ecological Loops are Key
Although the amount of data available is enormous, we still face the problem of small samples, meaning there are few samples. Suppose we need to build a machine learning-based fraud detection scoring system; we first need some fraud samples. However, the number of fraud samples we can obtain is not large; even if we have millions of loan applications, the number marked as fraud may only be tens of thousands. This presents a higher challenge for modeling with machine learning. Each fraud sample comes at a high “cost” to obtain. As time goes on, we will inevitably collect more samples, but the growth potential of samples is still limited. This contrasts with traditional machine learning systems, such as image recognition, where it is not difficult to obtain hundreds of thousands or even millions of samples.
Under such small sample conditions, building an effective ecological loop is particularly important. The so-called ecological loop refers to constructing an effective self-feedback system that can provide real-time feedback to our model, enabling continuous self-optimization of the model to improve accuracy. To build such a self-learning system, we need to improve the existing data flow system and delve into various business lines to optimize the corresponding processes. This is a necessary process for the entire fraud prevention cycle; we must understand that the entire process is full of games. Therefore, we need to continuously adjust our strategies through feedback signals.
6. Conclusion
Knowledge Graphs are receiving increasing attention in both academia and industry. In addition to the applications mentioned in this article, Knowledge Graphs can also be applied in areas such as permission management and human resource management. We will discuss these applications in detail in future articles.
References
[1] De Abreu, D., Flores, A., Palma, G., Pestana, V., Pinero, J., Queipo, J., … & Vidal, M. E. (2013). Choosing Between Graph Databases and RDF Engines for Consuming and Mining Linked Data. In COLD.
[2] User Behavior Tutorial
[3] Liu Zhiyuan, Knowledge Graph – Knowledge Base in the Machine Brain, Chapter 2: Knowledge Graph – Knowledge Base in the Machine Brain
[4] Nickel, M., Murphy, K., Tresp, V., & Gabrilovich, E. A Review of Relational Machine Learning for Knowledge Graphs.
[5] Socher, R., Chen, D., Manning, C. D., & Ng, A. (2013). Reasoning with neural tensor networks for knowledge base completion. In Advances in Neural Information Processing Systems (pp. 926-934).
[6] Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., & Yakhnenko, O. (2013). Translating embeddings for modeling multi-relational data. In Advances in Neural Information Processing Systems (pp. 2787-2795).
[7] Jenatton, R., Roux, N. L., Bordes, A., & Obozinski, G. R. (2012). A latent factor model for highly multi-relational data. In Advances in Neural Information Processing Systems (pp. 3167-3175).

[Limited Time Download]

Click the image below to read “7 Major Trends in Big Data Development in 2016”
Before 2016/1/31
For the December 2015 resource package download, please click the bottom menu of Big Data Digest: Download etc.–December Download
Exciting articles from Big Data Digest:
Reply with 【Finance】 to see historical journal articles from the 【Finance and Business】 column
Reply with 【Visualization】 to experience the perfect combination of technology and art
Reply with 【Security】 for fresh cases of leaks, hackers, and offense-defense
Reply with 【Algorithm】 for interesting and informative stories
Reply with 【Google】 to see its actions in the field of big data
Reply with 【Academicians】 to see how many academicians discuss big data
Reply with 【Privacy】 to see how much privacy remains in the era of big data
Reply with 【Medical】 to view six articles in the medical field
Reply with 【Credit】 for four articles on big data credit
Reply with 【Big Country】 for the “Big Data National Archives” of the United States and 11 other countries
Reply with 【Sports】 for application cases of big data in tennis, NBA, etc.
Reply with 【Volunteers】 to learn how to join Big Data Digest
Long press the fingerprint to follow “Big Data Digest”

Focusing on big data, sharing daily