Hello everyone, my name is Wang Ziyou, a friend of Hugo. My master’s degree at Stanford and my current entrepreneurial direction in China are both related to artificial intelligence.
Recently, AI large models represented by ChatGPT have sparked a lot of discussions in China, and the venture capital sector has shown a vibrant scene, which is regarded by NVIDIA’s founder Jensen Huang as another “iPhone moment”. Bill Gates has stated, “It feels like seeing a graphical user interface for the first time.”
But why is such a groundbreaking invention not from giants like Google, Baidu, or Facebook, who have been deeply involved in AI for many years, but rather from a small startup team at OpenAI?
Below, I will share my observations.
The Speed of Technological Development Exceeds Everyone’s Expectations
I have recently conducted a lot of research on ChatGPT and am amazed at how fast technology is developing.
Back in 2019, when I was involved in NLP (Natural Language Processing) research, the general consensus among my friends was that “compared to the CV (Computer Vision) field, NLP would take another 10 years to apply”. Now, it seems that this view was quite shortsighted.
Now, four years later, the problems that language models can handle have far exceeded our understanding. After falling behind for four years, I recently revisited the research and found that the so-called “miracles through brute force” (stacking parameters and training amounts) cannot fully encapsulate the vision and persistence of the OpenAI team in their choice of technological paths.
If everyone can carefully examine the technological development path in the NLP field over the past few years, they might be more impressed by how precious the efforts of this team are.
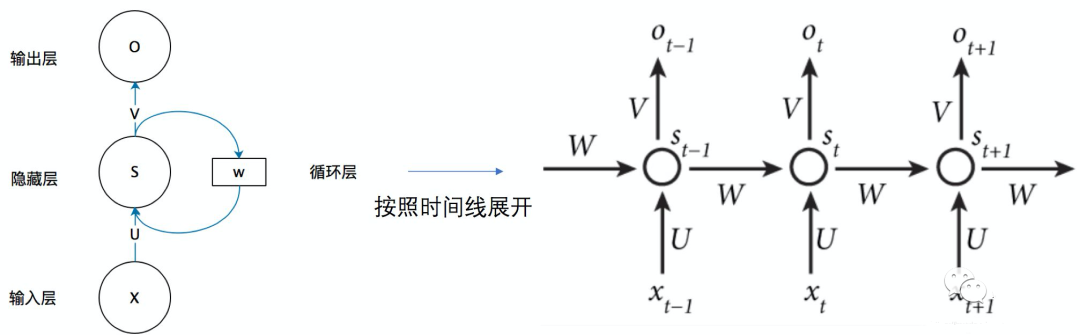
Starting with Recurrent Neural Networks (RNN)
Let’s take a step back to the earliest language models. At that time, the most effective model was probably the RNN (Recurrent Neural Network). We won’t delve into the intricate details of the principles, but rather explain the characteristics of this type of model from a physical intuition perspective.
This type of model primarily utilizes the sequential relationships in language to make predictions. For example, in the phrase “He seems like a dog”, the prediction of the word “dog” relies on the preceding words. Therefore, in terms of the model architecture, it is a “cyclic structure”, where the next variable depends on the previous variable.
This type of model performs well on sequential data, which includes not only language but also datasets like stock prices. This aligns well with human intuition, but there are also several issues:
First, as the number of layers in the model increases, the earliest data can get drowned out, making it difficult to effectively consider the relationships between words.
Second, it cannot perform parallel computation, and the amount of data the model can handle is limited. Due to the sequential relationships in the model, it cannot be parallelized like images using GPUs, which limits the model size.
Third, it can only be used for specific learning tasks. For example, a model designed for translation cannot be used for text generation.
The Beginning: Attention and Transformer
The inception of GPT and many subsequent technologies actually began at Google. In 2017, Google researchers published a profoundly influential paper titled “Attention is All You Need”, which proposed the Transformer model, the foundational architecture for most language models today.
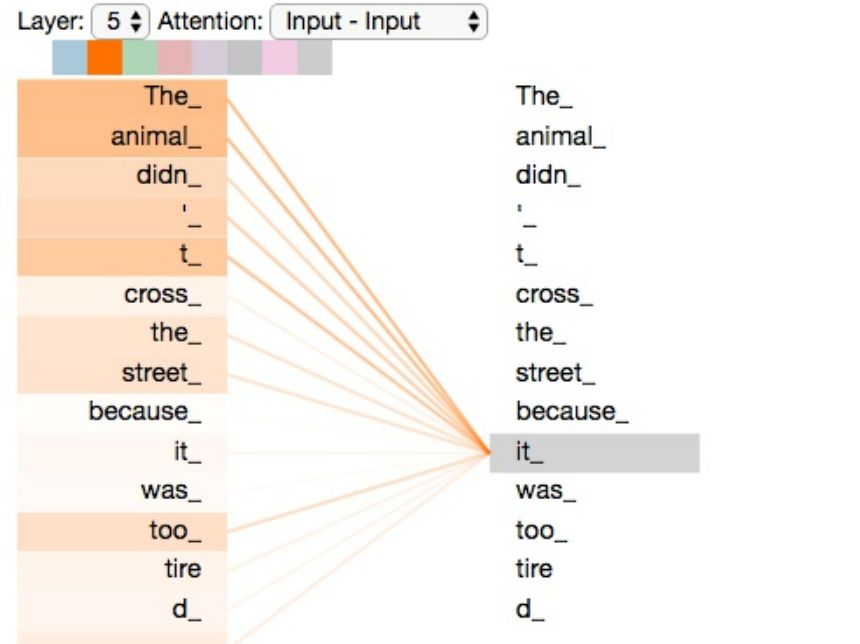
Intuitively, this is quite simple to understand. They believed that when humans speak, every word is related to other words, similar to human attention. We can better understand this with the following illustration, where the relationship strength of the output “it” with the left side can be seen through the color intensity. This mechanism can be assigned weights and applied in neural networks.
Through this attention mechanism, language models can depart from the RNN structure, effectively discarding the models that everyone previously relied on. The algorithm performs well, and the design is very elegant.
I want to mention an interesting phenomenon that I personally experienced. At that time, many researchers attempted to combine Transformer with RNN, which indeed improved performance. However, looking back now, this direction turned out to be a dead end, so reflecting on this period brings different realizations.
BERT and GPT-1: Losing at the Starting Line
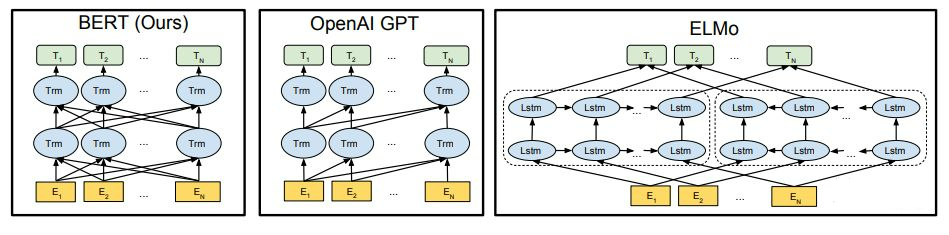
Around 2018, OpenAI began to make strides, releasing the first GPT model. At the same time, Google released the BERT model.
Here are the three most popular models at the time. Unfortunately, BERT outperformed GPT-1 on many issues. This is why Google did not invent ChatGPT, and the capital market was so disappointed.
First, let’s discuss how BERT and GPT-1 improved upon previous models. I believe this is when the OpenAI team understood the right technological path.
First, we need to understand that traditional machine learning requires well-annotated data. For example, if I want to train an algorithm to judge human emotions, I need to provide data to the machine, such as “input: I am unhappy, output: negative emotion”. This model has a huge problem: well-annotated data is very scarce and highly dependent on human effort. However, most data in language models, such as the majority of corpus on Zhihu, is unannotated, with only input provided. If relying solely on manual annotation, large datasets cannot be completed.
This is where BERT and GPT-1 proposed a new approach: learning from the text itself without requiring additional annotations.
BERT captures a sentence like “He seems like a dog”, randomly masking some words, such as “He [mask] like a dog”, and the model predicts the masked word. GPT-1, on the other hand, masks the next word and only provides the preceding context for the machine to predict. In summary, this allows them to utilize the vast majority of data available online to train the model. This step is their pre-training process.
After the pre-training is completed, BERT and GPT-1 undergo further training on specific tasks to achieve better results, similar to how a person first learns phonetics before writing an essay.
Of course, there are also structural differences between BERT and GPT-1, which I won’t delve into here.
At this time, GPT-1 was definitely not as popular as BERT. I remember during our NLP course, the teacher specifically had us read BERT, while GPT-1 I didn’t study in depth. Furthermore, BERT is primarily used for natural language understanding tasks, such as question answering, text classification, and sentence relationship analysis. It can understand the semantics and relationships within the text and identify connections between statements, making these applications very clear and valuable for companies.
In contrast, the text generation scenarios where GPT excels were heavily questioned by large companies, as AI-generated text often lacks coherence. If a large company were to release a product that generates nonsensical text, it would clearly harm their reputation.
GPT-2: Upholding Research Intuition
To summarize, at this point, GPT-1 could only be used in specific scenarios, yet the model’s framework and design ideas were already top-notch. At this time, the OpenAI team proposed a very visionary research intuition: they believed that language models should handle multiple tasks rather than a single task.
For example, if a machine has read “In 2017, Google published a paper on the Attention mechanism”, then it should be able to answer the question, “In which year did Google publish the Attention mechanism?” without requiring additional training. However, GPT-1, after pre-training, still needed specialized Q&A training. They believed that machines should understand human language.
This reflects the intuition and persistence of researchers. I think this is not just about deeper models and more parameters; it is more about their fundamental thinking about the essence of language models. Many times, simply saying “brute force creates miracles” may be a psychological comfort, overlooking their foundational thinking.
Returning to our topic, the greatest contribution of GPT-2 was validating that models trained on massive amounts of data and parameters could be applied to multiple different tasks without additional training. Although for certain questions, GPT-2’s performance was even worse than random answers, it outperformed the best models at that time on seven datasets.
It is worth mentioning that the structural differences between GPT-2 and GPT-1 are not significant.
GPT-3: A Leading Technical Path
As we all know, following this, with such foundational knowledge and experience, GPT-3 was released as the most powerful language model to date.
In addition to several common NLP tasks, GPT-3 also excelled in many very challenging tasks, such as writing articles that are difficult for humans to distinguish and even writing SQL query code. The realization of these powerful capabilities relied on GPT-3’s staggering 175 billion parameters, 45TB of training data, and a training cost of up to $12 million.
This is not just about “brute force creates miracles”; this group of researchers has deeply considered the essence of language models. Otherwise, who would dare to spend so much money on training?
The model parameters, training data, and workload of GPT-3 are astonishing. The paper had as many as 31 authors, and the time and financial resources spent on all the experiments were certainly immense. Even though the model seemed to have bugs and risks of information leakage at the time, OpenAI did not retrain it.
GPT-3.5 and GPT-4: Moving Towards CloseAI
A little gossip: take a look at the GPT-4 report (they named the paper: GPT-4 Technical Report). It’s a 99-page paper that reveals no technical details, only showcasing their muscle. Look at the list of participants; this is the most direct reflection of talent and technological hegemony.
Among the friends who studied NLP with me, only one person is still conducting research in this field, which reflects the scarcity of talent.
Ultimately, many times, opportunities are not chased; they are created by people. It is only through genuine passion and belief that one can persist.
If someone had told me five years ago that they wanted to train an ultra-large model capable of handling all language problems, from translation to essay generation, I would have thought they were out of their mind. However, upon examining OpenAI’s research journey, we realize that it is not as incomprehensible as it seems.
Behind the unwavering commitment that is hard for others to understand lies an extraordinary level of cognitive ability.
Thus, the development of technology, or human innovation, has very little utilitarianism. Those who are overly utilitarian often do not fare well, such as the miniaturization of electronic tubes and the development of GPUs in historical processes. Finding what you love, persevering without seeking rewards, and running freely.
Reprinted with permission from Cool Play Lab
For reprint requests, please contact the original author
Feel free to share with friends or on social media
Persevering without seeking rewards, running freely!