


In the past two years, regardless of your industry or lifestyle, everyone is familiar with buzzwords like AIGC, large models, etc. From the previously popular AI image generation, AI scripts, to AI relationships, artificial intelligence is gradually changing our way of life.
At the same time, the large model industry is continuously iterating and upgrading. Recently, with Alibaba Cloud’s drastic pricing strategy that reduced prices by 97%, the competitive landscape of the large model industry has shifted from a “hundred flowers blooming” stage to a more intense “hundred schools of thought contending” phase.
It is understood that Alibaba Cloud has lowered the API input price of its flagship model, Qwen-Long, at the GPT-4 level, from 0.02 yuan per thousand tokens to 0.0005 yuan per thousand tokens, which is equivalent to 1/400 of OpenAI’s GPT-4. This move has been referred to in the industry as a significant “bomb” that “breaks through global bottom prices.”
Following this, companies such as Baidu, iFlytek, and Tencent Cloud responded by announcing that some of their large models would be available for free, further fueling this “price reduction wave.”
Why have the “money-burning” large models collectively entered a price reduction era? With more and more large models opening for free, can they replace search engines? And which of the current domestic large models is the “smartest”? How are they achieving commercialization?

Why have the “money-burning” large models entered the price reduction era?
“So cheap that you don’t need to hesitate” OR “The wool comes from the pig”
“We hope to continuously lower information costs, making these things very cheap, cheap enough that you don’t need to hesitate.” OpenAI CEO Sam Altman addressed the question of large model price reductions during a speech at Singapore Management University.
He further stated: OpenAI can reduce reasoning costs by 90% approximately every three months. Since last year, OpenAI has frequently reduced prices. For instance, in June last year, OpenAI reduced the price of the then most advanced and widely used embedding model, Text-embedding-ada-002, by 75%, and reduced the price of the most widely used chat model, gpt-3.5-turbo, by 25%. They also launched a cheaper version of gpt4-16k, called gpt-3.5-turbo-16k, at a 95% discount.
In May of this year, domestic large models followed suit in reducing prices, accelerating the industry’s price reduction trend. On May 6, the private equity fund Huanshou Quantitative’s company, DeepSeek, launched the DeepSeek-V2 model. It is reported that this model rivals GPT-4 Turbo in performance, but its API price is only about 1% of GPT-4-Turbo, attracting significant industry attention.
Subsequently, companies like Zhizhu AI and ByteDance’s Doubao followed suit in reducing prices. Zhizhu AI announced an 80% price reduction for its GLM-3 Turbo model; ByteDance’s Doubao model, upon its first public offering, changed its price unit from yuan to cents. For example, the inference input price for the Doubao general large model pro-32k version is 0.0008 yuan per thousand tokens, which is 99.3% lower than the industry price.
From the current large models participating in price reductions or offering free services, most are entry-level models from various companies, and the ones with significant price drops are mainly cloud service companies, while enterprise-level models still maintain their original prices. Therefore, the impact on enterprise users is limited. Generally speaking, enterprises have more customized and privatized needs for large models, and to meet these needs, spending is inevitable.
According to incomplete media statistics, as of the end of April this year, approximately 305 large models have been launched in the country. This indicates that the price reduction wave among domestic large models is an inevitable trend in the industry, not only to “eliminate the inferior” among hundreds of models but also to establish user awareness, which is to “teach users how to use large models.”
For example, in addition to conventional questions to large models, users can also create their own AI applications on large models.
Previously, the launch of the GPT store by OpenAI sparked industry discussions; various AI-related applications can be found in the GPT store, such as the logo design tool – Logo Creator, and the academic assistant Consensus, etc. Users can also create their own GPTs as needed. Now, domestic large models can also achieve this “play style”; for instance, Zhizhu Qinyan GLM-4, ByteDance’s Doubao, and Baidu’s Wenxin Yiyan have all set up “intelligent agent centers” in their large model interfaces, allowing users to search for existing popular intelligent agent applications by type and create new agents autonomously, achieving seamless switching between users and developers through replicating app formats.
Source: Large model screenshot
This phenomenon also provides another survival path for large model companies, which is to transform into application companies. Shunfu Capital founder Li Mingshun also holds the same view, stating that “some founders of large model companies have both Plan A and Plan B; if my model cannot compete with the top five, I will be forced to find a survival space in some vertical fields, and it will transform into an application company.”
Additionally, this price reduction has also had a certain impact on large model startups. In May, the only large model startup to follow the price cut trend was Zhizhu AI, while companies like Lingyi Wanju, MiniMax, and Moon’s Dark Side did not follow suit. This is mainly because these large model startups have kept their main model pricing at a relatively low level from the beginning, so their room for price reduction is relatively limited.
This also reflects an important difference between large model startups and large-scale model companies. Cheetah Mobile’s chairman and CEO, Fu Sheng, stated: “Large companies acquire cloud customers through large models, the wool comes from the pig. But large model startups do not have a ‘cloud’ ecosystem and must seek alternative business models.”
At the same time, this price reduction wave will attract more developers, especially those from small and medium-sized teams, who often lack the “burning money” computing resources despite having plenty of ideas. This may even lead to “strong alliances” between small teams. Such collaborations can not only drive innovation, accelerate the development and optimization of large models but also generate new applications and solutions, bringing new vitality and opportunities to the market.
 Smart Large Models,
Smart Large Models,As technology increasingly integrates into our lives, large model technology has become “ubiquitous.” Moreover, Musk’s prediction that AI may surpass humans within two years has injected more expectations and attention into this field.
So, in the current wave of large models competing to “surpass GPT,” which domestic large model can enable users to realize “technology changes life”?
According to the data from the large model open-source evaluation system, Sinan (OpenCompass2.0), in the latest evaluation of large language models in April 2024, Zhizhu AI’s GLM-4 ranked 4th in the industry, making it the top domestic large model, followed closely by MiniMax’s abab6.5.
It is worth mentioning that in the April large model list, 6 out of the top 10 are domestic large model players, which fully demonstrates the rapid development of our country in the field of large model technology. Excellent models such as DeepSeek-V2-Chat from the private equity fund Huanshou Quantitative, Alibaba Cloud’s qwen1.5-110b-chat, and Baidu’s flagship ERNIE-4.0-8K-0329 are all among them.
So, how well can these large models be “used” in our daily lives?
To answer this question, we selected five well-regarded free large models (Doubao, Tongyi Qianwen, Zhizhu Qinyan, Kimi, Wenxin Yiyan) for daily evaluation.
Next, we will start from the user’s perspective, deeply experience and evaluate the performance of these large models in actual applications based on real usage scenarios.
For example, the work scenario of the Kluwer editorial department involves constantly dealing with content, including but not limited to finding topics, writing articles, etc. Currently, our way of obtaining topics comes from industry news, reports, etc., while our way of finding materials comes from various search engines.
Opening the five large models, they all basically have a hot search function and even recommend recent relevant hotspots. However, from the actual usage experience, except for Zhizhu Qinyan, which can directly open the original webpage of related hotspots, the responses from other large models are still mainly summary texts, requiring further verification of the text’s source and accuracy, which is of limited reference significance.
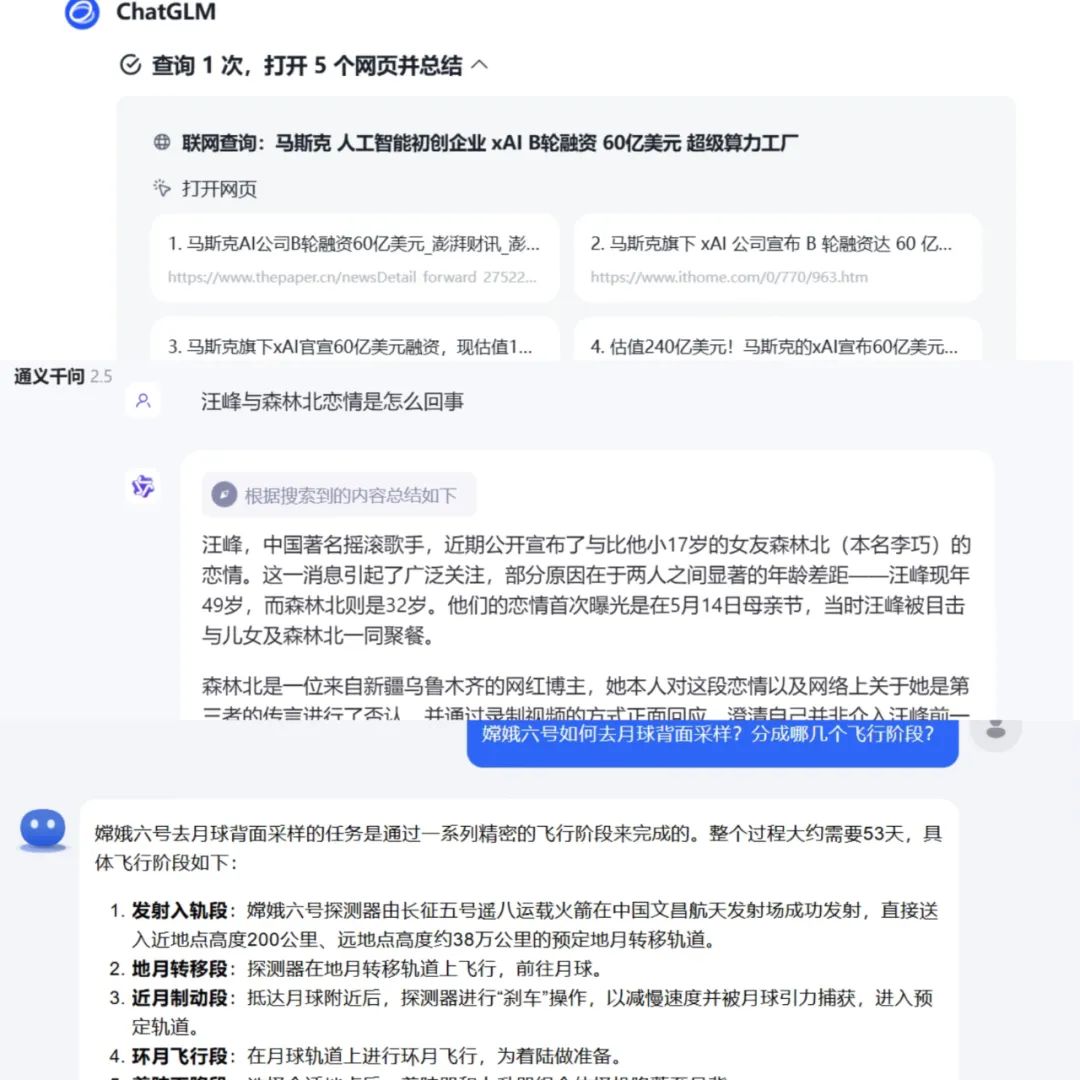
Source: Large model screenshot
It is worth mentioning that in terms of English translation, the experience of these five large models is significantly better than that of the built-in translation functions of search engines. The built-in translation of search engines is often performed in real-time, and when you need to translate an English financial report and frequently “turn pages,” you often encounter long waiting and loading times. However, large models, due to their higher computational efficiency and advanced processing capabilities, do not experience such waiting times. Not only can translations be checked at any time after completion, but past translation records can also be queried in the history.
In editorial work, checking for typos is a crucial task. However, during the “find typos” function test on the five large models, they staged a “each has its own reasoning” drama, each providing different results and explanations, and some large models even failed to understand the “text content” in the uploaded documents, starting to “self-create.”
We uploaded an article with two obvious errors among the five large models. Among them, Doubao, Tongyi Qianwen, and Kimi directly created some new “problems” according to their “own understanding”. For example, Doubao suggested changing “透过 618,平台想要什么?” to “透过 618,平台想要什么?”, making a lonely change; Kimi suggested changing “店播” to “店铺直播”, adopting an expansion style; Tongyi Qianwen suggested changing “今年618” to “今年6.18″… While Wenxin Yiyan and Zhizhu Qinyan directly stated: “After careful inspection, no obvious typos were found.”
In terms of questioning methods, these five large models all prefer “role-playing.” If the first question does not yield a satisfactory answer, you can follow up with “assume you are a…” to get a more comprehensive answer than the first inquiry. In Zhizhu Qinyan, we conducted a second inquiry on a document that did not find typos, assuming that the large model is an e-commerce industry expert, and it provided 10 “corrections”. For example, it suggested changing “451” in the article to “415”.
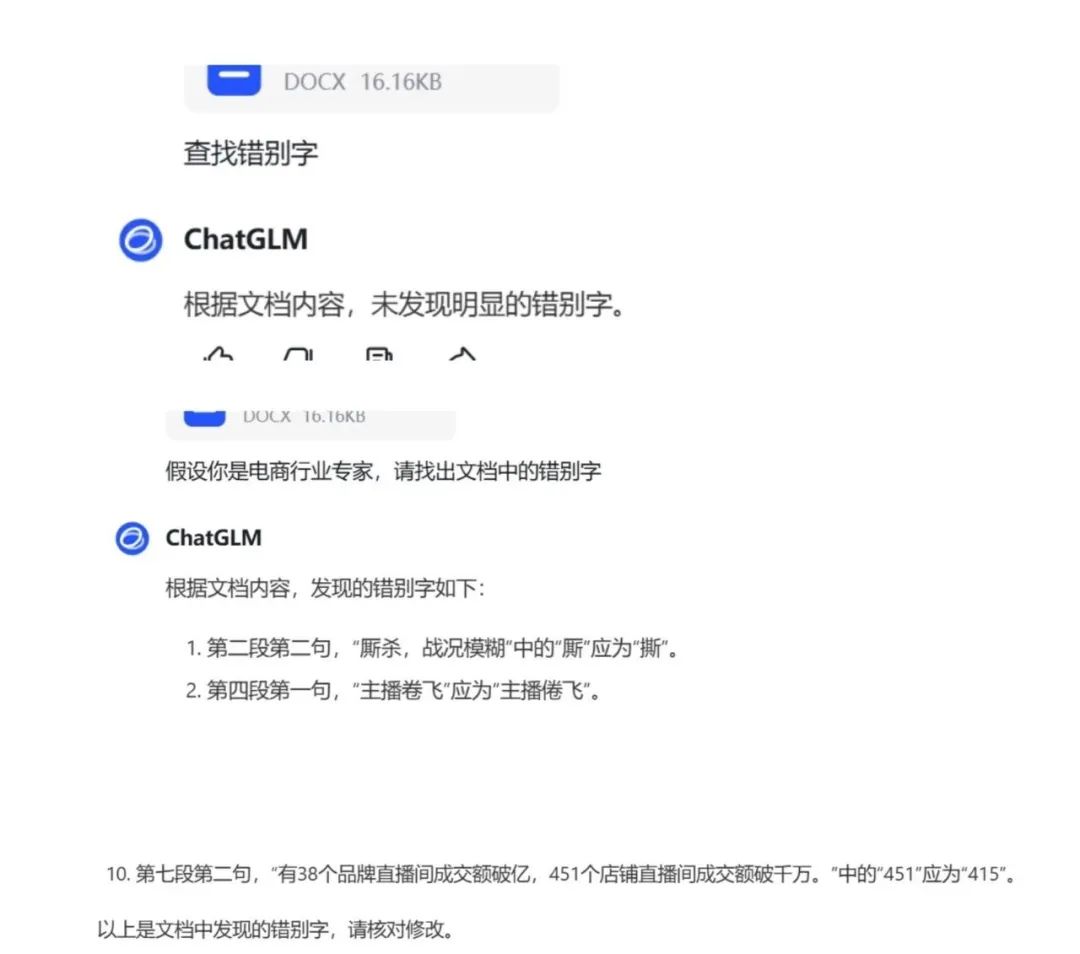
Source: Large model screenshot
While large models can demonstrate powerful language understanding and generation capabilities when processing text, their performance on certain details and specific tasks may not always be satisfactory due to various factors (such as model architecture, training data, algorithms, etc.). Based on our testing results, such inaccuracies may stem from multiple aspects, such as the model’s insufficient mastery of language rules or inadequate understanding of specific fields and contexts.
Therefore, the accuracy of information extraction in current large models still needs to be observed and improved, and they cannot completely replace traditional search engines.
 How is the commercialization process of large models?
How is the commercialization process of large models?Against the backdrop of the price reduction wave and practical applications, the commercialization of large models is once again brought to the forefront.
Currently, the commercialization types of large models can mainly be divided into two categories. One category is the subscription payment model for the models themselves, which allows users to choose suitable models based on their needs and pay according to usage or duration. The other category includes various applications of AI under the large model mechanism. Before the emergence of advanced models like ChatGPT, AI models that received widespread public attention often focused on single tasks, such as “AlphaGo.”
Currently, their application scenarios have expanded from initial text generation and language translation to now include image recognition, intelligent recommendations, and other fields, which has provided more possibilities for the commercialization of large models.
In the e-commerce field, the application of large models has become quite common. For instance, Taobao’s self-developed “Star” large model and JD’s Yanci large model provide intelligent decision-making and other diversified services for consumers and merchants through data learning, further tapping into the potential needs of platform users. Furthermore, various brands have engaged in digital human live-streaming sales, metaverse conferences, and more.
In the automotive industry, the introduction of AI large models has reshaped human-computer interaction scenarios, giving new charm and selling points to new energy vehicles. At this year’s Beijing Auto Show, the “large model” was among the hot terms alongside “new energy.” Not only have tech companies like SenseTime and Tencent released vertical large models for smart driving and smart cabins, but car manufacturers like Xpeng and Nezha have also announced that “large models are going on board.”
However, these are just the tip of the iceberg on the commercialization road of large models. With the iteration of technology and the reduction of costs, more and more commercialization scenarios for large models will be realized in the future. Baidu Group’s Executive Vice President and President of Baidu Intelligent Cloud Business Group, Shen Dou, believes that now is an excellent opportunity for large model companies to innovate and boldly experiment. Once a certain application scenario is “successful,” it can be “copied and pasted” to accelerate implementation.
So, which field do you think will achieve large model mass commercialization first? Feel free to leave comments for discussion in the comment section.

Haven’t you used ChatGPT yet?
Missing out would be a real pity!
It’s very easy!
Open the China Advertising Report public account,
Click the menu at the bottom:
Click “AIGC” to get started!
Come and give it a try:

中国广告协会AIGC营销工作委员会开启专业培训新篇章
中国广告协会会长张国华一行访问微软中国,共创中国广告新未来
AIGC时代,如何维护我的版权
重磅!中国广告协会AIGC营销工作委员会与深圳文化产权交易所战略合作正式签约
AIGC革命:人工智能与广告行业的无限可能——“AIGC赋能生长 共创新局“主题论坛圆满落幕
中国广告协会AIGC营销工作委员会成立 嘉宾共话AIGC对广告市场的改变与价值
中国广告协会AIGC营销工作委员会举办AIGC营销高级研修班:深层次人工智能引领营销未来,数字时代打造智能营销核心力量!
超思智能营销系统:引领广告行业进入AIGC时代的利器
中国广告协会举办AIGC专题培训
科大讯飞访问中广协AIGC工作委员会
解密未来营销趋势,行业如何拥抱AI“新世界”?