
MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, with an audience that includes NLP graduate students, university professors, and corporate researchers.The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners. Reprinted from | NewBeeNLP Author | Wang Ning
Recently, I came across some exciting work in the multimodal field, introducing two papers, both from DeepMind.
Typical tasks in the image-text multimodal field include img-text retrieval, VQA, captioning, grounding, etc. The current academic settings are manageable. However, once the knowledge scope expands to open-ended scenarios, the task difficulty increases dramatically. Nevertheless, DeepMind’s Flamingo model has achieved this using the same model in these challenging scenarios. I was quite surprised by the examples in the paper!

It can be seen that the Flamingo model can perform open-ended captioning, VQA, and even counting and arithmetic. Many additional knowledge points, such as the origin of flamingos, are not difficult for unimodal language models like GPT-3, T5, Chinchilla, etc.
However, for traditional multimodal models, it is difficult to learn such a wide range of external knowledge through traditional img-text pairs, as much of this knowledge is contained in text-based unimodal sources (like Wikipedia). Therefore, DeepMind’s focus in the multimodal field is to stand on the shoulders of giant language models, freezing the parameters of large-scale trained language models, and designing multimodal models to align with NLP large models.
1
『Frozen』
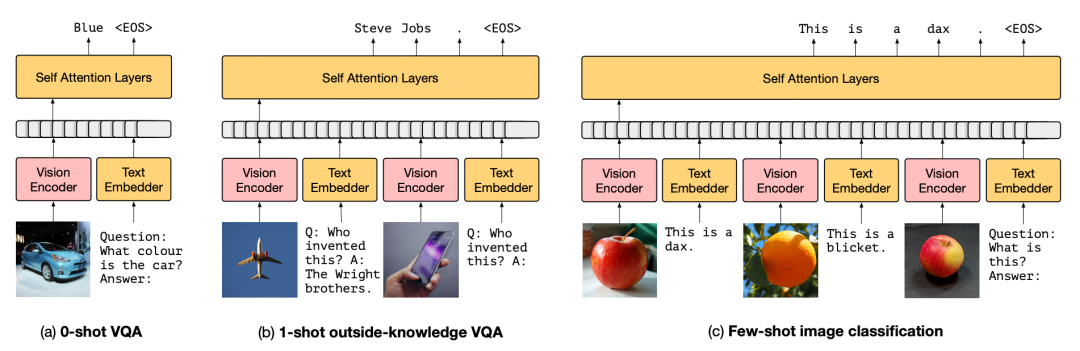
To introduce the Flamingo model, I must first discuss DeepMind’s previous work, Frozen, presented at NeurIPS 2021. The Frozen model is quite simple; the authors used a pre-trained language model and completely froze its parameters, only training the visual encoder.
Model structure: The LM model is a transformer structure with 7B parameters trained on C4 data, and the visual encoder is NF-ResNet50. Training data: Only the CC3M dataset was used for training, which includes 3 million img-text pairs, so the pre-training data volume is not large. The Frozen framework is as follows. The visual features can be seen as prompts for the LM model, which responds based on the “hint” of the visual features.

Structure of the Frozen model
It can be seen that through some constraints of img-text pairs, the unfrozen visual encoder aligns and approaches the frozen LM. The algorithm only used the captioning corpus CC3M during pre-training, and the richness of knowledge is also limited. So, what can the Frozen model do?
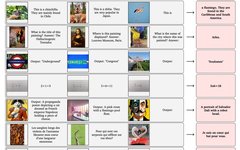
Applications of the Frozen model in downstream scenarios
Although trained with caption data (CC3M), it surprisingly performs VQA and even knowledge-based VQA. For example, in the image above, if you tell it that the airplane was invented by the Wright brothers, it can relate it to the fact that the iPhone was created by Steve Jobs. Clearly, this external knowledge is not something that the limited img-text pairs in CC3M can provide; it comes from the frozen LM model that was never involved in training. The authors then conducted a series of experiments, showing that the Frozen model is still far from SOTA models.
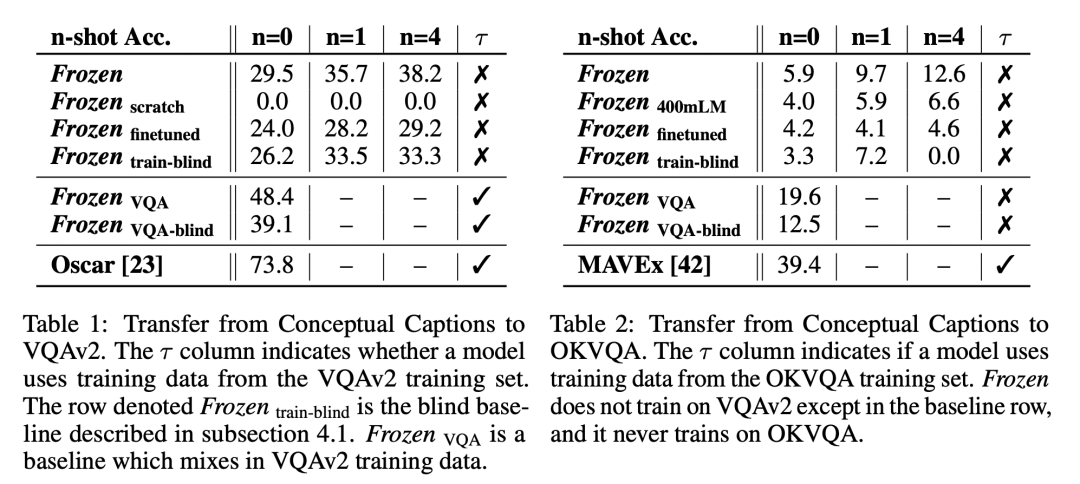
Results of the Frozen experiments
It can be seen that the Frozen model has a significant gap from SOTA algorithms on the VQA and OKVQA datasets.
Several interesting phenomena:
-
If the model cannot see the image (blind model), relying only on the LM model, the performance is decent but significantly lower than the model that can see the image. This indicates that Frozen effectively aligns the img-text modalities and learns how to reference image information to respond;
-
It can achieve decent performance even in few-shot or zero-shot scenarios;
-
End-to-end fine-tuning of the LM model decreases performance, indicating that parameters of the LM model trained on a large amount of unimodal data can easily be damaged by a small amount of img-text data. This proves the article’s viewpoint that the LM model needs to be Frozen to retain the knowledge learned from text information!
2
『Flamingo』
After introducing Frozen, it is only natural that the DeepMind team followed up with the impressive Flamingo model. Compared to Frozen, the Flamingo model has several improvements:
-
A stronger LM model: 70B parameter language model Chinchilla;
-
More trainable parameters: the visual encoder is also frozen this time, but the image feature sampling model can be trained. More importantly, learnable parameters are also embedded in various layers of the LM model, with a total of up to 10B trainable parameters;
-
A terrifying amount of training data: not only were 1.8 billion img-text pairs from the ALIGN algorithm added, but also millions of video-text pairs. Additionally, there is a large amount of mismatched image-text information from the MultiModal MassiveWeb (M3W) dataset, with hundreds of millions of images and about 182 GB of text. The ability to train with unpaired img-text data is also a significant highlight of the Flamingo model. Overall, its data volume is astonishing, far exceeding current multimodal algorithms like CLIP, ALIGN, SimVLM, and BLIP.
Now let’s take a look at the structure of Flamingo:
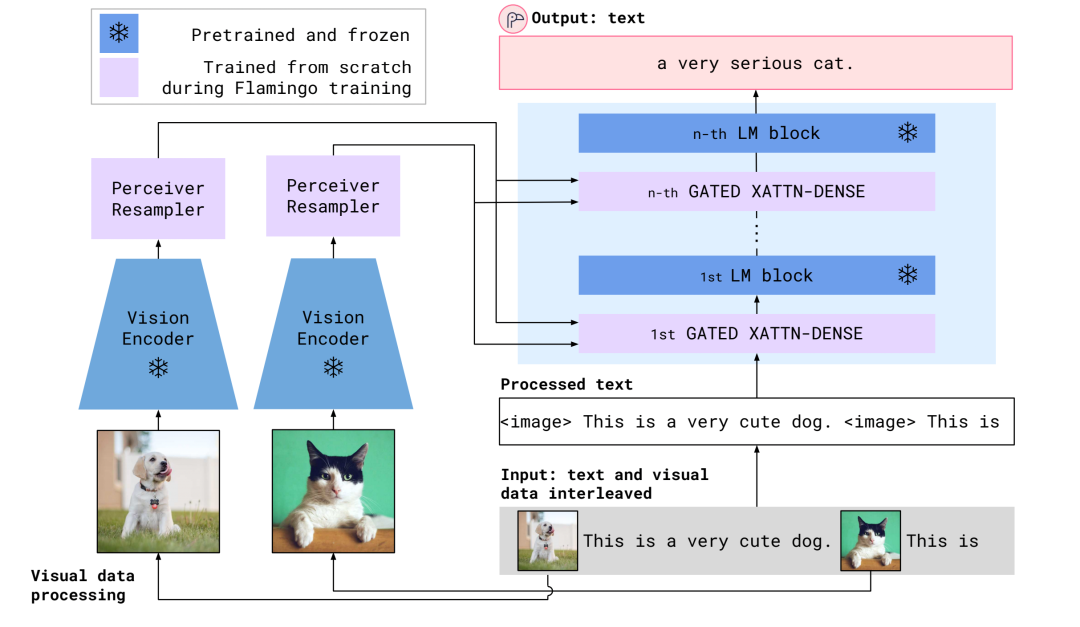
Structure of the Flamingo model
Unlike Frozen, this time the visual encoder is also frozen. The learnable parts are two: one is the Perceiver Resampler, and the other is the Gated Block embedded in the LM model. The structure of the Perceiver Resampler is as follows:
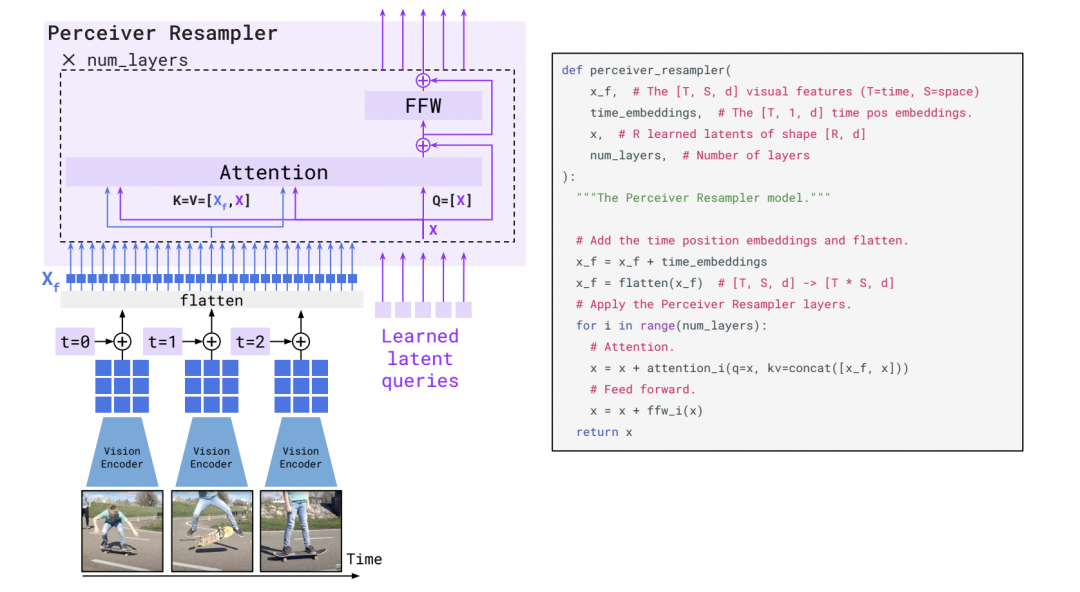
Structure of the Perceiver Resampler
The structure of the Perceiver Resampler is straightforward, with some learnable embeddings acting as queries, then image features or sequential video features attending to the queries as the final output.
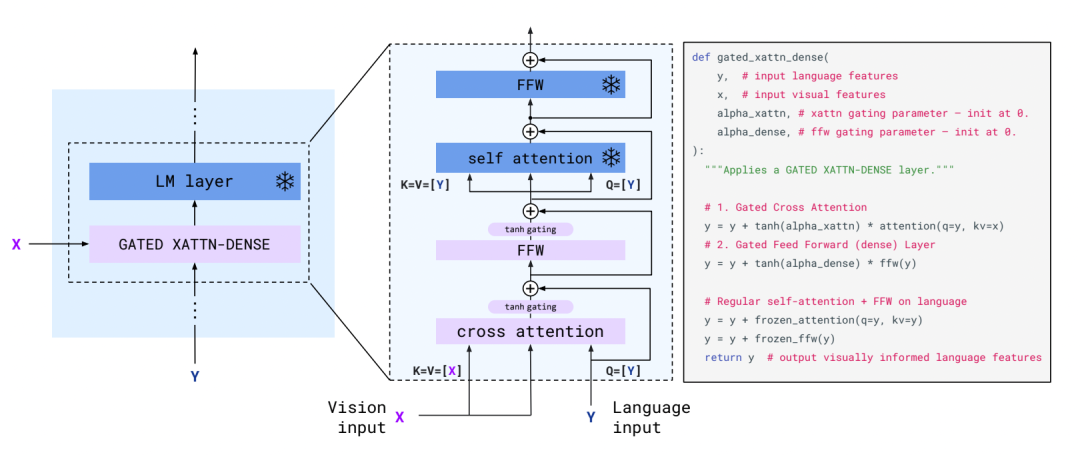
Gated xattn-dense structure
The gated xattn-dense structure embedded in the LM model is also clear, using text information as queries to aggregate visual information. Here, the text embedding acts as the query, while the visual embedding serves as the key and value. Compared to the transformer structure, the only minor difference is that an additional gate is added after the cross-attention and FFN.
After introducing the structure of the Flamingo model, let’s briefly look at its astonishing performance. It can be said that achieving this level with only few-shot in downstream scenarios is surprising… In some tasks with fixed answer sets, such as traditional VQAv2, the advantage is not obvious, but in open-ended knowledge-based VQA tasks, such as OKVQA, it can refresh the current SOTA with just few-shot. In blind scenarios like VizWiz and tasks with a lot of OCR information like TextVQA, the performance is also commendable. Some video-based QA tasks like NextQA and iVQA also achieve the best performance…
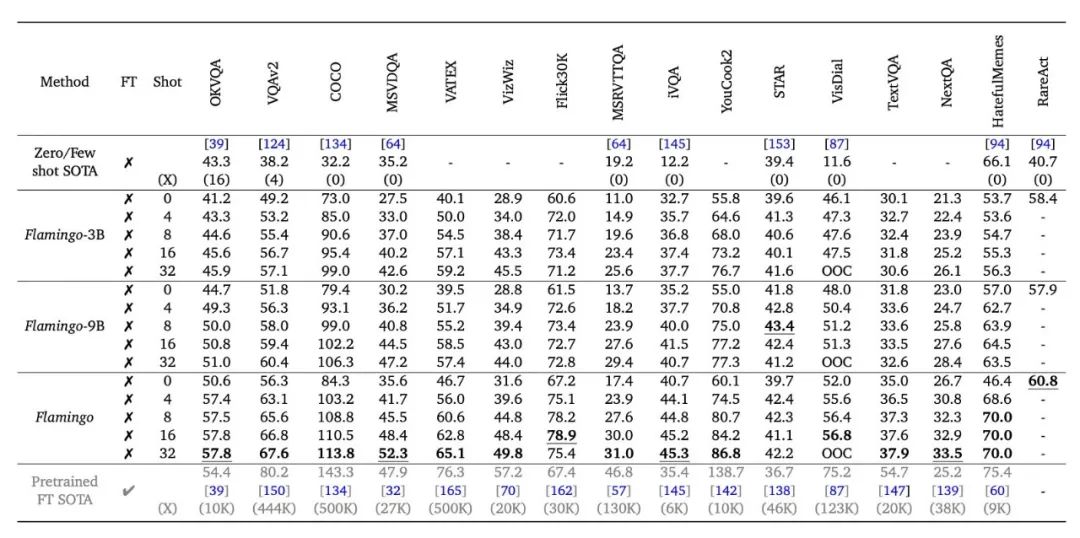
If Flamingo does not use the few-shot mode but instead uses fine-tuning mode, the paper shows that it can also refresh many industry SOTA indicators, which will not be listed here. Finally, I will list a few astonishing examples to conclude this article, preparing to study the details of the paper further.
Multimodal descriptions, multimodal Q&A, multimodal dialogues, multimodal recommendations… Many people used to think these were far away, but progress has been rapid in recent years, and the gap to practical scenarios is gradually narrowing. The future is promising!


Technical Group Invitation

△ Long press to add the assistant
Scan the QR code to add the assistant WeChat
Please note: Name – School/Company – Research Direction(e.g., Xiaozhang – Harbin Institute of Technology – Dialogue Systems) to apply to join the Natural Language Processing/PyTorch technical group.
About Us
MLNLP community is a grassroots academic community built by machine learning and natural language processing scholars from home and abroad. It has now developed into a well-known machine learning and natural language processing community, including brands such as 10,000-person top conference group, AI Selection, MLNLP Talent Exchange, and AI Academic Exchange, aimed at promoting progress between the academic and industrial sectors of machine learning and natural language processing.The community provides an open platform for communication for practitioners regarding further education, employment, and research. Everyone is welcome to pay attention and join us.
