Since its launch on December 2nd, 2022, ChatGPT, developed by the startup OpenAI in Silicon Valley, has garnered over a million users and sparked intense discussions. It can perform a variety of common text output tasks, including writing code, debugging (code correction), translating documents, writing novels, creating business copy, generating recipes, completing assignments, and evaluating assignments. Additionally, it can remember the context of conversations with users, responding in a remarkably realistic manner.
Despite industry experts pointing out that ChatGPT still faces issues such as outdated training data, questions linger about the future of human-created artificial intelligence and the evolving relationship between humans and thinking machines. These are questions we cannot stop pondering.
Written by | Sun Ruichen
Reviewed by | Zhang Zheng
Edited by | Chen Xiaoxue
 Promotional poster for the movie Dune (Image source: IMDB.com)
Promotional poster for the movie Dune (Image source: IMDB.com)
The movie Dune, released at the end of last year, is a science fiction story set in the year 10191 (8169 years from now). While watching, I had a question: the lives of people in this story seem more primitive than today, and there are not many traces of artificial intelligence (AI) in the narrative. Later, I read the original novel of Dune and understood that this was a deliberate choice by the author: at some point before 10191, there was a war against thinking machines created by humans. In the end, humanity had to fight fiercely to defeat these sentient robots, leading to a decision to permanently ban their existence, resulting in the primitive world of Dune in 10191.
Last Friday, OpenAI launched a new AI conversational model, ChatGPT. Many, including myself, tried out this new chatbot over the past week. After experiencing the chatbot, you might have guessed it—my mind wandered back to the world of Dune.
The past decade seems like an “Cambrian explosion” in the field of artificial intelligence technology, with a plethora of new terms emerging rapidly and gaining popularity. Many of these new terms and their abbreviations lack standardized Chinese translations, leading industry insiders to communicate primarily using English abbreviations. This creates a cognitive barrier for outsiders trying to fully grasp these technologies.
To understand the ChatGPT chatbot, one must first understand its predecessors: InstructGPT, GPT-3, GPT-2, GPT, Transformer, and the commonly used RNN models in natural language processing prior to these.
1. The Predecessor of ChatGPT
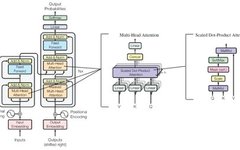
In 2017, the Google Brain team published a paper titled “Attention is all you need” at the NeurIPS conference, a top academic conference in machine learning and artificial intelligence. In this paper, the authors introduced the transformer model based on self-attention mechanisms, which was used for understanding human language, i.e., natural language processing.
Before this paper emerged, the mainstream model in natural language processing was the recurrent neural network (RNN). The advantage of RNNs is their ability to handle sequential data better, such as language. However, this also leads to instability or early stopping issues when processing longer sequences, such as long articles or books, due to gradient vanishing or explosion phenomena during training. Additionally, RNNs require longer training times since they must process data sequentially, preventing parallel training.
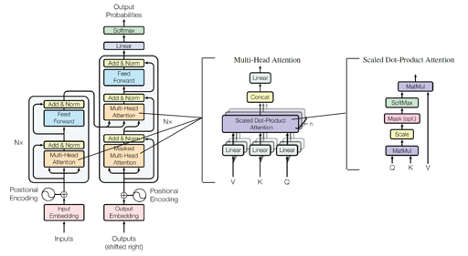
Initial architecture of the Transformer model (Image source: Reference [1])
The Transformer model proposed in 2017 could perform data computation and model training in parallel, requiring less training time and yielding interpretable models, meaning the models have explainability.
This initial Transformer model had 65 million adjustable parameters. The Google Brain team used various publicly available language datasets to train this initial Transformer model, including the 2014 English-German translation workshop dataset (4.5 million pairs of corresponding English-German sentences), the 2014 English-French translation workshop dataset (36 million English-French pairs), and selected sentences from the Pennsylvania Treebank language dataset (40,000 sentences from the Wall Street Journal and another 17 million sentences from the corpus). Moreover, the Google Brain team provided the model architecture in the paper, enabling anyone to build similar models and train them with their own data.
After training, this initial Transformer model achieved top scores in various metrics, including translation accuracy and English syntactic analysis, becoming the most advanced large language model (LLM) at the time.
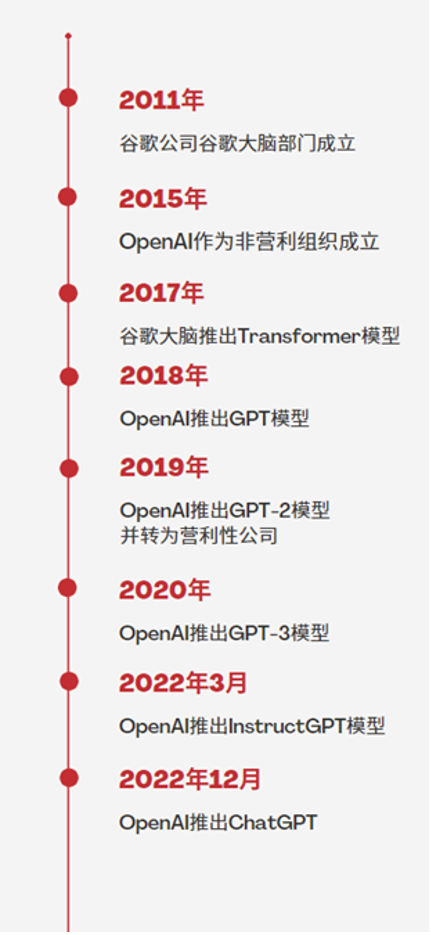 Major milestones of large language models (LLM)
Major milestones of large language models (LLM)
From the moment the Transformer model was born, it profoundly influenced the trajectory of artificial intelligence development in the following years. In just a few years, its impact has spread across various fields of AI—from diverse natural language models to the AlphaFold2 model predicting protein structures, all have utilized it.
2. Continuous Iteration: Searching for the Limits of Language Models
Among the many teams following and researching the Transformer model, OpenAI is one of the few that has consistently focused on finding its limits.
Founded in December 2015 in San Francisco, OpenAI was co-founded by Elon Musk, who provided early funding (he later withdrew from the company but retained his funding status). In its early days, OpenAI was a non-profit organization with a mission to develop AI technologies that are beneficial and friendly to human society. In 2019, OpenAI changed its nature and announced it would become a for-profit entity, a change closely related to the Transformer model.
In 2018, less than a year after the Transformer model’s birth, OpenAI published a paper titled “Improving Language Understanding by Generative Pre-training” and launched the GPT-1 (Generative Pre-training Transformers) model, which has 117 million parameters. This model was trained on a large dataset of classic book texts (BookCorpus), containing over 7,000 unpublished books across various genres, including adventure, fantasy, and romance. After pre-training, the authors further trained the model using different specific datasets for four different language scenarios (also known as fine-tuning). The final trained model outperformed the base Transformer model in question answering, text similarity assessment, semantic entailment judgment, and text classification, becoming the new industry leader.
In 2019, the company announced a model with 1.5 billion parameters: GPT-2. The architecture of this model is similar to GPT-1, with the main difference being that GPT-2 is ten times larger. They also published a paper introducing this model titled “Language Models are Unsupervised Multitask Learners.” In this work, they used a new dataset primarily composed of web text information they collected. Unsurprisingly, the GPT-2 model set new records in multiple language scenarios for large language models. The paper provided results of the GPT-2 model answering new questions (questions and answers not present in the training data).
 Results of GPT-2 model answering new questions (Image source: [3])
Results of GPT-2 model answering new questions (Image source: [3])
In 2020, this startup team surpassed themselves again, publishing the paper “Language Models are Few-Shot Learners” and launching the latest GPT-3 model, which has 175 billion parameters. The architecture of GPT-3 is not fundamentally different from GPT-2, except that it is two orders of magnitude larger. The training dataset for GPT-3 is also significantly larger than its predecessors: a filtered web crawling dataset (429 billion tokens), Wikipedia articles (3 billion tokens), and two different book datasets (670 million tokens in total).
Due to the massive number of parameters and the scale of the training dataset, training a GPT-3 model conservatively costs between five million to twenty million dollars—using more GPUs for training increases costs but reduces time, and vice versa. It can be said that such a large language model is no longer an affordable research project for ordinary scholars or individuals. With such a massive GPT-3 model, users can provide only small sample prompts or even no prompts at all to receive high-quality answers that meet their needs. Small sample prompts refer to users providing a few examples to the model before posing their language tasks (translation, text creation, answering questions, etc.).
 GPT-3 can better answer questions based on user-provided prompts (Image source: [4])
GPT-3 can better answer questions based on user-provided prompts (Image source: [4])
When GPT-3 was released, it did not provide a broad user interaction interface and required users to submit applications to register after approval, so the number of people who directly experienced GPT-3 was limited. Based on the experiences shared online by those who tried it, we know that GPT-3 can automatically generate complete, coherent long articles based on simple prompts, making it almost unbelievable that these works are produced by machines. GPT-3 can also write code, create recipes, and perform almost all text creation tasks. After the initial testing, OpenAI commercialized the GPT-3 model: paying users can connect to GPT-3 through an API to utilize the model for their language tasks. In September 2020, Microsoft obtained exclusive licensing for the GPT-3 model, meaning it could access the source code exclusively. This exclusive license does not affect paying users’ continued use of the GPT-3 model via the API.
In March 2022, OpenAI published another paper titled “Training language models to follow instructions with human feedback” and launched the InstructGPT model, which is fine-tuned based on the GPT-3 model. The training of InstructGPT incorporated human evaluations and feedback data, not just pre-prepared datasets.
During the public testing of GPT-3, users provided a wealth of dialogue and prompt data, while OpenAI’s internal data labeling team also generated a significant amount of manually labeled datasets. These labeled data can help the model learn human annotations (e.g., certain sentences or phrases should be used sparingly) while directly learning from the data.
OpenAI first fine-tuned GPT-3 using supervised learning with these labeled data.
Next, they collected samples of answers generated by the fine-tuned model. Generally, for each prompt, the model can provide countless answers, but users typically want to see just one answer (which aligns with human communication habits). Therefore, the data labeling team manually scored and ranked all possible answers to select the most human-like response. The results of this manual scoring can further establish a reward model—this model can automatically provide feedback to the language model, encouraging it to produce good answers and suppressing bad ones, helping the model find the optimal answer.
Finally, the team continued to optimize the fine-tuned language model using the reward model and more labeled data, iterating until the final model was named InstructGPT.
3. The Birth of ChatGPT
Our main focus today is ChatGPT and its predecessors, so it is unavoidable to discuss OpenAI’s journey. From GPT-1 to InstructGPT, if we only focus on OpenAI, we may overlook that other AI companies and teams were also making similar attempts during the same period. In the two years following the launch of GPT-3, many similar large language models emerged, but it must be said that the most well-known model remains GPT-3.

Some competitors of GPT-3 (Image source: gpt3demo.com)
Returning to the present, during this year’s NeurIPS conference, OpenAI announced their latest large language pre-trained model, ChatGPT, to the world on social media.
Similar to the InstructGPT model, ChatGPT is a chatbot developed by fine-tuning the GPT-3 model (also known as GPT-3.5). Information from OpenAI’s official website indicates that ChatGPT and InstructGPT are sister models. Given that the largest InstructGPT model has 175 billion parameters (the same as the GPT-3 model), it is reasonable to believe that ChatGPT also has a parameter count in that range. However, according to the literature, the parameter count of the InstructGPT model, which performs best on dialogue tasks, is 1.5 billion, so it is also possible that ChatGPT’s parameter count is similar.[5]
Since its launch on December 2nd, ChatGPT has already attracted over a million users. Examples of conversations shared by users on social media indicate that ChatGPT, like GPT-3, can perform a variety of common text output tasks, including writing code, debugging (code correction), translating documents, writing novels, creating business copy, generating recipes, completing assignments, and evaluating assignments. One advantage of ChatGPT over GPT-3 is that it responds more conversationally, while GPT-3 is better at producing long articles but lacks colloquial expression. Some users have utilized ChatGPT to converse with customer service to reclaim overpaid amounts (which perhaps means ChatGPT has passed the Turing test in some sense), and it might become a good companion for socially anxious individuals.
4. Warning of Issues
OpenAI’s development team warned users of some issues with the ChatGPT model upon its release, and global internet users have confirmed the existence of these problems through repeated testing.
Firstly, the training dataset for the large language model behind ChatGPT is only up to date until the end of 2021, so it cannot provide accurate answers regarding events that occurred in the past year. Secondly, when users seek accurate information from ChatGPT (e.g., writing code, checking recipes), the accuracy of its responses is inconsistent, requiring users to have the ability to discern the quality and accuracy of the answers. Due to accuracy issues, the code-sharing website StackOverflow has banned users from citing code generated by ChatGPT on its site.
In response, Zhang Zheng, director of the Amazon AWS Shanghai AI Research Institute, commented that the training method of the ChatGPT model has a fatal flaw: the scoring mechanism for various possible answers during question answering is based on ranking, meaning the second step involves rough scoring. This leads to the mixing of erroneous ideas (for example, just because sentence A ranks higher than sentence B does not mean A contains no common sense or factual errors). Question answering is not only open-ended in nature but also involves nuances that can be gray areas, requiring further subdivision. This issue is not unsolvable; there is still much foundational work to be done.
Finally, the way the questioner describes the problem can also affect the accuracy of ChatGPT’s responses. This issue can have unexpected consequences. Earlier this year, OpenAI launched its latest AI painting system, DALL·E 2 (alongside many similar products, such as Midjourney). Users only need to provide a language description, and DALL·E 2 can generate a painting based on that description. It is not an exaggeration to say that the quality and style of these paintings can rival works created by professional artists.
 A modern painting generated by DALL·E 2 (Image source: openai.com)
A modern painting generated by DALL·E 2 (Image source: openai.com)
Consequently, the art world was shocked, and the business of prompt engineering quietly emerged: good prompts can guide AI models to generate more satisfying and aesthetically pleasing works, while poor prompts often lead to subpar, student-level (or worse) outputs. Thus, learning how to write effective prompts and engage in high-quality dialogue with AI models has become a new entrepreneurial hotspot. The San Francisco startup PromptBase offers a service for $1.99 per prompt, primarily targeting content creation models like DALL·E 2 and GPT-3. Perhaps they will soon add ChatGPT to their business scope.
Based on the previously mentioned principles of few-shot learning and incorporating human feedback, we know that if we provide the ChatGPT model with a few examples before posing a language task or continuously provide feedback to guide ChatGPT, its responses will better align with our requirements. Therefore, writing a good prompt can lead to more surprises from ChatGPT.
5. The Evolution of Artificial Intelligence: Where Will It End?
From the 2017 Transformer to today’s ChatGPT, large language models have undergone numerous iterations, each more powerful than the last. In the future, OpenAI will continue to bring us GPT-4, GPT-5, and even GPT-100. Meanwhile, our hot, bizarre, and mind-bending chat records with ChatGPT will all become training data for the next generation of models.
When OpenAI was founded in 2016, its initial intention was to develop AI technologies beneficial to humanity. Over the past six years, there has been no indication that they have strayed from this intention—instead, ChatGPT and the large language models behind it appear to be advanced productive forces for the future. We have reason to believe that AI technologies exemplified by large language models can help us better accomplish learning and work, leading to a better life; we also have reason to believe that we should continue to support, develop, and promote AI to benefit the public. However, we can no longer ignore that the speed of AI technology evolution and iteration far exceeds that of human and biological evolution.
Elon Musk, co-founder of OpenAI, once spoke about the organization’s founding intention when he recognized the immense potential of AI: “How can we ensure that the future brought by AI is friendly? In the process of trying to develop friendly AI technologies, there will always be a risk that we may create things that concern us. However, the best barrier might be to allow as many people as possible to access and possess AI technologies. If everyone can utilize AI technologies, the risk of a small group possessing excessively powerful AI technologies leading to dangerous consequences would be minimized.”
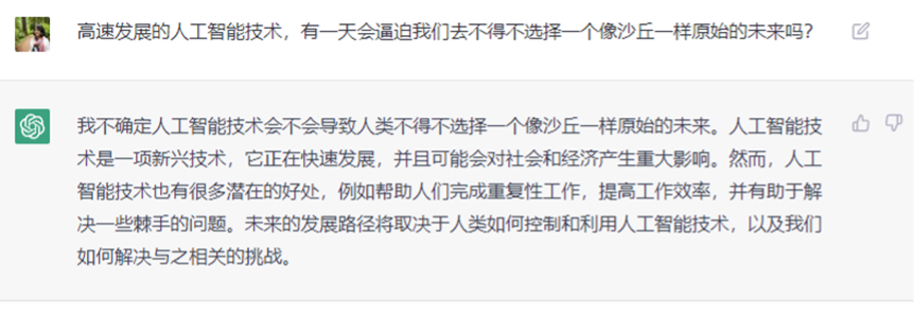
However, what Musk did not address is that even if everyone has the opportunity and ability to use AI technology, if the technology itself advances to a point beyond human control, how can we establish our own defenses? How can we avoid a world war between humans and thinking machines, as suggested in the story of Dune? The existence of ChatGPT is not yet a cause for concern, but where will the endpoint of AI evolution be?
In the process of creating AI, it is difficult for humanity to stop asking questions—will the rapidly evolving AI technology one day force us to choose a primitive future like that of Dune?
ChatGPT does not know either.
Author’s Biography:
Sun Ruichen, PhD in Neurobiology from the University of California, San Diego, currently a data scientist at a pharmaceutical company.
References:
1.https://arxiv.org/abs/1706.03762
2.https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf
3.https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
4.https://arxiv.org/abs/2005.14165v4
5.https://arxiv.org/abs/2203.02155
Edited by | Xiao Mao
This article is reproduced with authorization from the WeChat public account: Science Mr. Author: Sun Ruichen
Reproduced content only represents the author’s viewpoint
Does not represent the views of the Institute of High Energy Physics
Editor:Astronaut