Big Data Digest Production
Compiled by: Digest Bacteria
In recent years, the development of computer vision (CV) has surged, penetrating all aspects of our lives. To the public, this may seem like an exciting technological innovation; however, that is not entirely true.
In fact, computer vision has decades of development history, laying a solid foundation for many algorithms used today as early as the 1970s. Then, about ten years ago, a new technology that was still in the theoretical development stage emerged: deep learning, a form of AI that utilizes neural networks to solve highly complex problems, driven by sufficient data and computational power.
With the continuous advancement of deep learning, we began to realize its outstanding performance in solving certain computer vision problems. For challenging issues such as object detection and classification, the application of deep learning has shown particularly ideal effects. From this point on, a clear distinction began to emerge between “classical” computer vision and deep learning-based computer vision.
What Holds Classical CV Back?
However, the rise of deep learning has not devalued classical computer vision as an outdated technology; both are still developing in parallel, helping us clarify which problems are more suitable for solving with big data and which should continue to use mathematical and geometric algorithms.
Although deep learning can revolutionize computer vision, this magical change only manifests when suitable training data is available, or when the network can learn independently under clear logical or geometric constraints.
In the past, classical computer vision was used for object detection, recognizing features (such as edges, corners, and textures), and even labeling every pixel in an image (semantic segmentation). However, these processes are very complex and time-consuming.
To detect objects, one must master techniques such as sliding window, pattern matching, and exhaustive search. Extracting and classifying features requires engineers to develop custom methods. Distinguishing different categories of objects at the pixel level requires extensive work to delineate different regions, and even the most experienced computer vision engineers cannot always correctly differentiate each pixel in an image.
Deep Learning Transforms Object Detection
In contrast, deep learning, especially convolutional neural networks (CNNs) and region-based CNNs (R-CNNs), has made object detection relatively simple, especially when combined with large image databases from companies like Google and Amazon. With a well-trained network, algorithms can detect objects in various situations without explicit manual rules, and are not limited by viewing angles.
In terms of feature extraction, deep learning requires only an effective algorithm and a rich and diverse training data set to prevent model overfitting and ensure high accuracy when facing new data in production. In this task, CNNs perform exceptionally well. Additionally, when deep learning is applied to semantic segmentation, the U-net architecture performs very well, eliminating the need for complex manual processing.
A Look Back at “Classical Algorithms”
While deep learning has undoubtedly transformed the field of computer vision, for specific challenges such as Simultaneous Localization and Mapping (SLAM) and Structure from Motion (SFM), classical computer vision solutions still outperform newer methods. These problems involve using images to understand and depict the dimensions of physical space.
SLAM primarily focuses on building and updating a map of a certain area while tracking the position of an agent (usually some type of robot) within the map. This technology has made automated driving and robotic vacuum cleaners possible.
SFM also relies on advanced mathematical and geometric knowledge, but its goal is to create a 3D reconstruction of an object using multiple perspectives obtained from an unordered set of images. It is suitable for situations that do not require real-time, immediate responses.
Initially, it was thought that correctly executing SLAM required substantial computational power. However, by using approximate methods, pioneers in computer vision have been able to make computational demands more manageable.
In contrast, SFM is simpler: unlike SLAM, which usually involves sensor fusion, this method only utilizes the inherent properties of the camera and the features of the images. Compared to many laser scans that cannot be performed due to range and resolution limitations, this is a cost-effective method. The result is a reliable and accurate representation of objects.
The Road Ahead
Deep learning still cannot solve certain problems as effectively as classical computer vision. Engineers should continue to use traditional techniques to address these issues. When problems involve complex mathematics and direct observation, and suitable training data sets are hard to obtain, the power and bulkiness of deep learning may not yield elegant solutions. This situation can be likened to a “bull in a china shop”: just as ChatGPT is not the most efficient (or accurate) tool for basic arithmetic, classical computer vision will continue to dominate certain challenges.
The partial transition from classical computer vision to deep learning-based computer vision has brought us two key insights.
First, we must recognize that completely replacing old technologies, while simpler, is a mistake. When a field is disrupted by new technology, we must carefully pay attention to details and determine on a case-by-case basis which problems will benefit from new technology and which are still better suited to old methods.
The second insight is that while the transition brings scalability, it also brings a bittersweet sentiment. Traditional methods indeed involve more manual operations, but this also means they are a blend of art and science. The creativity and innovation required to extract features, objects, edges, and key elements from images do not come from deep learning but from thoughtful consideration.
As we gradually move away from classical computer vision techniques, engineers sometimes become more like integrators of computer vision tools. While this is a “good thing” for the industry, it regrettably abandons those more artistic and creative elements. A future challenge will be to find ways to reintegrate this artistry.
Understanding the Replacements
In the next decade, it is predicted that “understanding” will ultimately replace “learning” as the primary focus of network development. The emphasis will no longer be on how much knowledge a network can learn, but rather on the extent to which it can deeply understand information and how we can facilitate this understanding without providing excessive data. Our goal should be to enable the network to draw deeper conclusions with minimal intervention.
In the field of computer vision, the next decade will undoubtedly bring some surprises. Perhaps classical computer vision will eventually become obsolete. Perhaps deep learning will also be replaced by a technology we have not yet heard of. However, at least for now, these tools are the best choice for handling specific tasks and form the foundation for the development of computer vision in the next decade. In any case, it will be a very meaningful journey.
References:
https://venturebeat.com/ai/ten-years-in-deep-learning-changed-computer-vision-but-the-classical-elements-still-stand/

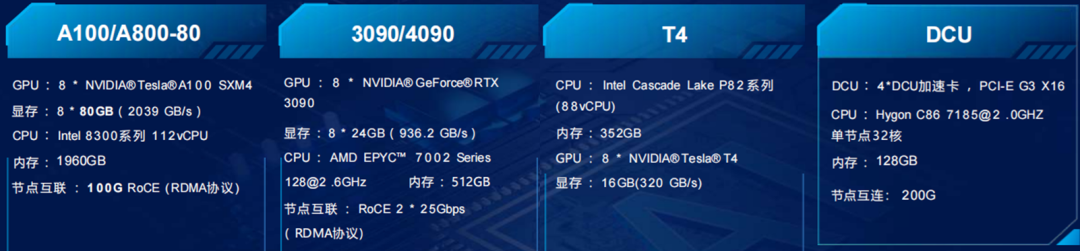
Rent! GPU Cloud Resources
A new batch of A100/A800 online
Operator machine room, service guaranteed

People who click “See” have all become good-looking!