

Source: New Intelligence
This article has 7372 words, recommended reading 10 minutes.
This article organizes the speech content of Professor Tao Dacheng at the AI WORLD 2018 World Artificial Intelligence Summit on September 20.
[ Introduction ] Professor Tao Dacheng from the University of Sydney, an academician of the Australian Academy of Science and chief scientist of UBTECH, pointed out that humans possess intelligence in four aspects: perception, reasoning, learning, and behavior. The ultimate goal of AI is to enable machines to have intelligence similar to that of humans. At the AI WORLD 2018 World Artificial Intelligence Summit on September 20, Dr. Tao introduced the significant progress his team has made in these four areas.
Professor Tao Dacheng from the University of Sydney, an academician of the Australian Academy of Science and chief scientist of UBTECH, delivered a keynote speech titled “AI Dawn: Opportunities and Challenges” at the AI WORLD 2018 World Artificial Intelligence Summit on September 20.
Dr. Tao stated that the goal of artificial intelligence is to achieve human-like intelligence in machines. Humans have four aspects of intelligence: Perceiving, Learning, Reasoning, and Behaving. His speech focused on these four aspects.

Perceiving includes many aspects: object detection, target tracking, scene segmentation, keypoint detection, facial image analysis, etc. However, high-performance perceiving also relies on high-quality data input. If the input images or videos are affected by noise, turbulence, blur, fog, low resolution, etc., data quality needs to be improved.
In terms of learning, Dr. Tao introduced multi-view learning, multi-label learning, adversarial domain generalization, tag disentangled GAN, etc. In particular, the evolutionary adversarial network (Evolutionary GAN) effectively addresses two major pain points in traditional GAN network learning:
-
Training instability.
-
Model collapse. This work was also selected as a hot paper by MIT Technology Review (The Best of the Physics arXiv).
Additionally, inspired by the data processing inequality in information theory, Dr. Tao and his students theoretically explained two highly concerning issues in deep learning:
-
Why do deep neural networks with very high model complexity not overfit?
-
Is a deeper deep neural network better?
Finally, Dr. Tao introduced some progress made by the UBTECH Sydney University Artificial Intelligence Research Institute in reasoning and behaving. His team recently achieved very good results in international competitions on visual question answering (VQA) and visual dialog.
Currently, Dr. Tao’s team is working hard to achieve imitation learning on humanoid robots, hoping that in the near future, robots will understand human behavior through cameras, imitate human actions, and ultimately interact effectively with people.
Below is the organized content of Professor Tao Dacheng’s speech:
Thank you very much to New Intelligence for inviting me to share some of the work we have done in the field of artificial intelligence over the past two years.

First, please take a look at this photo. I want to ask everyone a question: how many people are in this photo? It’s not difficult to answer this question, but it will take a lot of time. If we count individually, it would take about an hour to know that there are approximately 900 people here.

If we use our face detection technology on a desktop with a GPU, it can get a similar result in just three seconds. This seems like a simple task, but it is not always smooth sailing for computers. In 2017, our algorithm could detect more than 700 faces, then over 800, and now over 900, approaching human effectiveness. Additionally, we found that the faces detected by the computer actually help people to discover faces that were not initially seen. This illustrates that artificial intelligence can expand human intelligence from a special perspective.
The Goal of Artificial Intelligence: Achieving Human-like Intelligence in Machines

What is artificial intelligence? Artificial intelligence is the intelligence exhibited by machines, so it can be called “machine intelligence” to distinguish it from the intelligence exhibited by humans. Humans have four aspects of intelligence: Perceiving, Learning, Reasoning, and Behaving. The goal of artificial intelligence is to enable machines to achieve and simulate human intelligence. We look forward to the day when machines can perceive the world like humans, learn, reason, and respond accordingly. Therefore, we need to give artificial intelligence the ability in these four aspects.

This video showcases some of our core technologies in the field of artificial intelligence, including target detection, (single, multiple) target tracking, object segmentation, feature point detection, human pose estimation, emotion analysis, age estimation, single-camera depth estimation, etc.

Why is everyone talking about artificial intelligence today? Because we have big data and powerful computing servers, we now have the ability to effectively train ultra-large-scale models compared to a long time ago. Although multilayer neural networks emerged a long time ago, they were not able to be well promoted due to limitations in data and computational power. More importantly, we currently have a significant demand from industry, academia, and government sectors. This has truly contributed to the resurgence of artificial intelligence today. The urgent needs of the industry have also greatly driven academic investment in artificial intelligence.
Today, I will introduce our progress in perceiving, learning, reasoning, and behaving.
Basic Perception Tasks: Object Detection and Target Tracking
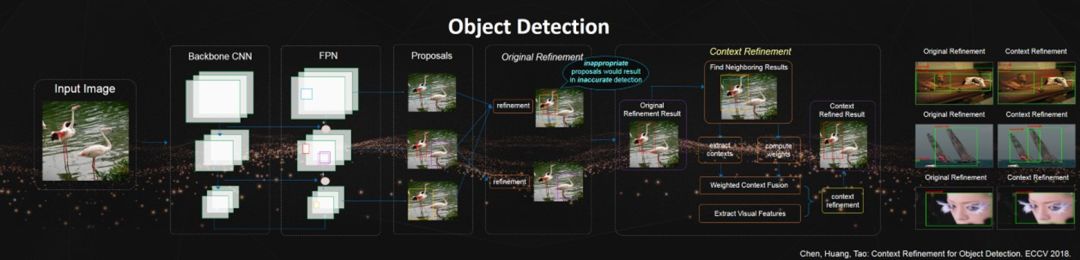
Object detection is a fundamental task in perceiving. Existing two-stage object detectors have achieved very good results. They first generate region candidate boxes and then adjust these candidate boxes. The adjustment process updates the coordinates of subsequent boxes and predicts the category of the object. However, inaccurate candidate boxes may lead to incorrect detection results.
To solve this problem, we proposed a context-based adjustment algorithm. Specifically, we found that the detection boxes surrounding a detected box often provide supplementary information about the object to be detected.
Therefore, we attempted to extract useful contextual information from surrounding detection boxes to improve the existing adjustment algorithm. In our proposed method, we will integrate the extracted contextual information based on a weighting process. Finally, by utilizing the fused contextual information and corresponding visual features, our context-based candidate box adjustment algorithm can significantly improve the existing adjustment algorithm.
For example, as shown in the figure, one candidate box for a crane is not very ideal: the blue, yellow, and red boxes each contain only part of the information about the crane. Our proposed context-based candidate box adjustment algorithm can effectively integrate the information from different parts of the candidate boxes containing the crane to form a complete candidate box.
With a complete candidate box, detection rates can be effectively improved.

Target tracking is another very fundamental task in perceiving. The difficulty of single target tracking arises from the fact that the object’s shape may undergo significant changes during movement due to geometry/photometry, camera viewpoint, and illumination variations, as well as partial occlusion. Multi-target tracking is even more challenging; in addition to the difficulties encountered in single target tracking, it also requires distinguishing the number of objects and different IDs.
Therefore, performing long sequence tracking in uncontrolled environments is very difficult. With the use of deep learning in target tracking, the performance of trackers has significantly improved. This is primarily because deep learning can effectively provide the intrinsic representation of the tracked object, thus demonstrating good robustness against various changes and occlusions. For instance, multi-player tracking in a basketball court is a good example.

Advanced Perception Tasks: Solving the Pathological Problem of Monocular Depth Estimation
Monocular depth estimation is a pathological problem, thus highly challenging. This task aims to restore pixel-level depth values from a single scene image and plays a crucial role in understanding 3D scene geometry. Why is this a pathological problem? For example, suppose there is a line in three-dimensional space, and we can project it onto a plane. On the projected plane, we can see a straight line, but we cannot confirm whether this line in the original three-dimensional space is straight or curved. However, in practice, we can estimate depth information based on the image information.
For instance, in this image, a person’s height in the original image is about three centimeters, but you would never think that this person’s height in three-dimensional actual space is three centimeters. Based on common sense, we all know that an adult male’s height is around 175 to 180 centimeters.
Based on simple geometric transformations, we can estimate the distance of this person from the camera. There is a lot of information in the image that can help us estimate pixel depth information, such as shadows, color variations, layout, ground, etc. The key question is how to design features and use reasonable statistical models to estimate the depth of each pixel.
A long time ago, researchers used handcrafted features combined with MRF (Markov Random Field) to complete this task. Although the predictive performance of traditional MRF models is not satisfactory, the existing results indicate that this problem is not entirely unsolvable.
Recent methods have made significant progress by exploring the multi-level contextual semantic information of deep convolutional neural networks (DCNN) on this issue. However, the depth values predicted by these methods are still very inaccurate.
Some possible reasons are:
-
Due to the extreme complexity of depth distribution, learning the depth distribution under standard regression paradigms is very difficult.
-
Previous works have ignored the ordinal relationship between depth values in modeling.
-
Image-level and multi-scale information have not been fully exploited yet.
Inspired by these phenomena, we first transformed the depth estimation problem into a discrete paradigm and then introduced an ordinal regression constraint to incorporate an ordering mechanism for depth prediction. Finally, we designed an effective multi-scale depth network to achieve better contextual semantic information learning. Our model (DORN) not only outperforms peers on four very challenging datasets (KITTI, ScanNet, Make3D, and NYU Depth v2) but also won first place in the Robust Vision Challenge 2018 depth estimation project.
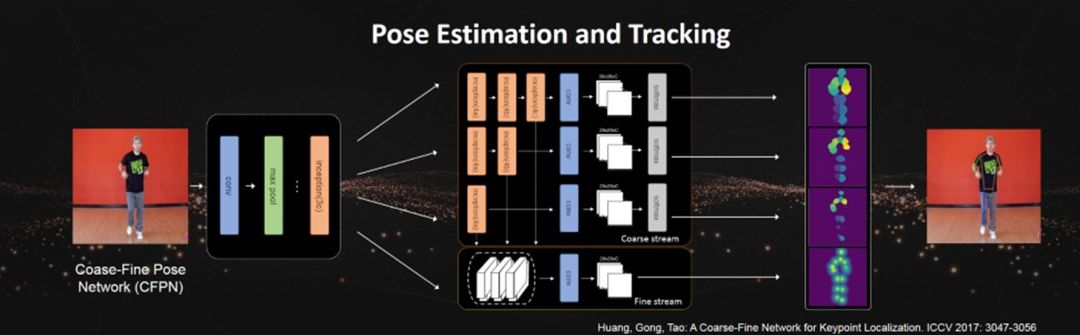
Object Pose Estimation and Prediction
Predicting a set of semantic keypoints, such as human body joints or bird parts, is an important technology in the field of image understanding. The keypoints of objects help align them and reveal subtle differences between them, while also being a key technology for computers to comprehend human posture. Despite significant progress in this technology in recent years, keypoint prediction remains a significant challenge due to large differences in object appearance, posture variations, and occlusions.
Currently, CNN-based keypoint localization methods use confidence maps to supervise keypoint detectors, but due to the varying difficulty of detecting keypoints in different images, using uniformly confident maps may hinder the learning of the keypoint detector.
To address the robustness issue of keypoint localization, we proposed a coarse-fine supervised network (CFN) deep convolutional network method. This method uses a fully convolutional network, leveraging several different depth branches to obtain hierarchical feature representations. Based on their receptive fields, it uses supervision information of varying granularity. Finally, all hierarchical feature information is combined to achieve precise localization of target keypoints. We demonstrated the effectiveness and universality of this method through experiments on bird part localization and human pose estimation tasks.

To successfully complete the aforementioned perceiving tasks, we need to assume that the images we obtain are all of high quality. However, in practical problems, the images we acquire may be affected by various factors, resulting in poor data quality. Therefore, we need to address image quality assessment and, based on the results of image quality assessment, we also need effective models to enhance image quality, such as denoising, deblurring, removing the effects of medium turbulence, enhancing the resolution of low-resolution images, defogging, etc.
Recently, many people have a feeling that deep learning dominates everything. To solve practical problems, it seems that we just need to stack different network layers, deepen the network, and then tune parameters. In fact, it is not that simple. To effectively solve practical problems, we need to understand deep learning, know how to effectively tune parameters, be familiar with traditional statistical machine learning and classical computer vision, and have a deep understanding of the problem to know how to build effective learning models, which are, of course, deep learning models.
In the learning direction, we have also done a lot of work: rapid matrix decomposition, multi-view learning, multi-task learning, multi-label learning, transfer learning, learning with labeled noise, generative adversarial networks, deep learning theory, etc. Due to time constraints, I will briefly introduce some of our recent work in multi-view learning, generative adversarial networks, and deep learning theory.
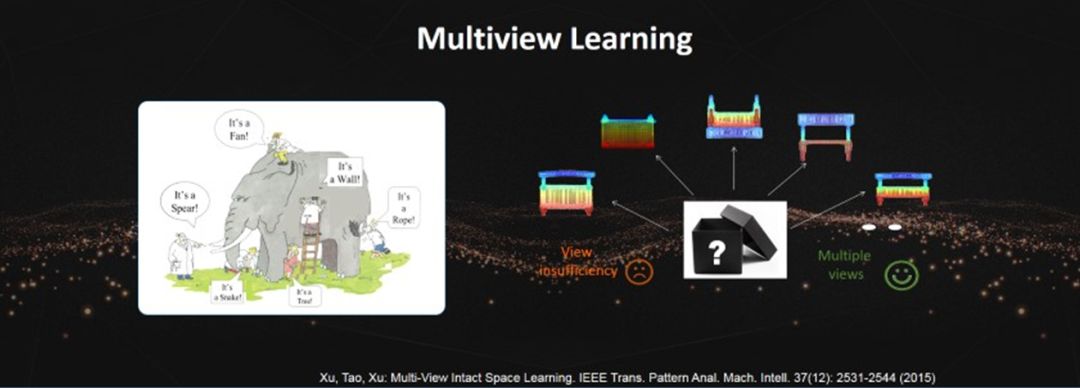
Multi-view Learning: A “Blind Man Touching an Elephant” Approach to Decision Strategies
Everyone knows the story of the blind man touching an elephant; in reality, when we make decisions, we are similar to the blind man because the information we obtain is also incomplete. Therefore, when we make decisions, we are making the optimal strategy based on the information at hand. Thus, for the same situation, each person may make a different decision.
Multi-view learning is very important for today’s intelligent systems, as these systems are equipped with a large number of sensors. For instance, modern autonomous vehicles are equipped with LiDAR, millimeter-wave radar, cameras, IMU, etc. Each sensor can only perceive part of the information in the environment, so we need to fuse the information from different sensors to help us make the final decision.
Suppose there exists an oracle space; each sensor can be modeled as a linear or nonlinear projection of the oracle space. If we have a large number of sensors, we can obtain a large amount of projection information. We can prove that if we have enough different projection information, we can reconstruct this oracle space with very high probability. With this oracle space, we can make effective decisions.

Take a look at the image on the far left. What do you see at first glance? Most people would say a ship. Then you might also notice that there are people on the ship, right? This phenomenon suggests that such sequential information is very helpful for multi-label learning. Through reinforcement learning, we can effectively learn this sequence to enhance the efficiency of reinforcement learning.
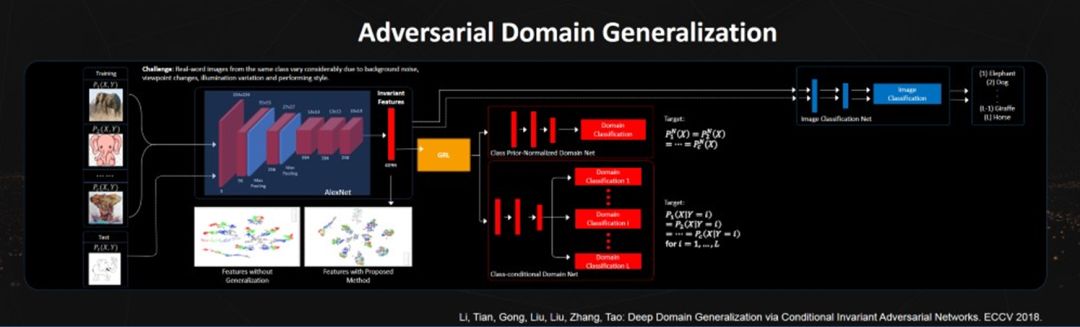
The learning problems we face today may be such a situation: the training data and testing data come from different sensors or information domains. This is the problem that domain generalization aims to solve. Because the training data and testing data come from different domains, we need to find some features: these features are effective for completing our specified tasks both on the training data and the testing data.
Humans can easily do this: when my son was three years old, I showed him a cartoon picture of a giraffe. When I took him to the zoo, he could easily recognize a real giraffe. However, before this, he had never seen a real giraffe in a real-world scenario. We certainly hope that computers can possess similar abilities. Here we utilize GANs (Generative Adversarial Networks) to effectively learn such invariant features.
We proposed an end-to-end conditional adversarial domain adaptation deep learning model to learn domain-invariant features, which simultaneously measures the invariance of distribution P(Y) and conditional probability distribution P(X|Y). The network framework consists of four parts. The first part, AlexNet, is used to learn domain-invariant features. The second part is an image classification network to ensure that the learned features have good class discriminability.
The domain-invariant property of features is ensured by the category prior normalization domain classification network and the category conditional domain classification network. The category prior normalization domain classification network is used to match the category prior normalized distribution of different domains, and its main purpose is to eliminate variations between different domains. Secondly, the category conditional domain classification network is used to ensure the distribution matching for each category. This guarantees that the joint probability distribution of different domains is matched. Experimental results obtained on different standard datasets demonstrate the effectiveness of our method and show significant improvements over existing methods.
TD-GAN New Framework: Solving the Explainability Problem in Deep Learning

Recently, there has been growing attention on the explainability of learning. We can learn features using GAN networks to generate the data we need. But what do these features mean? We are not clear.
By mimicking the way humans understand the world, we hope that computers can learn abstract concepts from this complex world and create new things based on these concepts. Therefore, we need computers to extract decomposable features from real-world images, such as the identity of people in photos, shooting angles, lighting conditions, etc. This is called tag disentanglement. With decomposable features, we can also better explain what physical meanings our learned features have.
We proposed a new framework (TD-GAN) for extracting decomposable features from a single input image and re-rendering the image by adjusting the learned features. To some extent, TD-GAN provides a deep learning framework that can understand images in the real world.
The decomposable features learned by the network correspond to different attributes of the subject described in the image. Similar to how humans understand the world, learning decomposable features helps machines interpret and reconstruct images of the real world. Therefore, TD-GAN can synthesize high-quality output images based on user-specified information.
TD-GAN can be applied to:
-
Data augmentation, i.e., synthesizing new images for training and testing other deep learning algorithms
-
Generating images of given objects in continuous poses for 3D model reconstruction
-
Enhancing existing works through analysis and abstraction, and creating imaginative new paintings

Learning and manipulating the probability distributions of real-world data (such as images) is one of the main goals of statistics and machine learning. The deep generative adversarial networks (GAN) proposed in recent years are commonly used methods for learning complex data probability distributions.
Generative adversarial networks have achieved convincing performance in many generation-related tasks, such as image generation, image “translation,” and style transformation. However, existing algorithms still face many training difficulties. For example, most GANs require careful balancing of the capabilities between the generator and the discriminator. Unsuitable parameter settings can reduce the performance of GANs, and even make it difficult to produce any reasonable output.
For a considerable amount of time, many researchers have studied the effects of different loss functions on GANs (and it is believed that different loss functions have different advantages and disadvantages and may lead to different training issues). Therefore, many different loss functions have been introduced into GAN training, such as minimax, least squares, etc., to enhance the performance of GANs.
For different tasks and different data, different loss functions have achieved certain effects. Later, researchers from Google found through extensive experiments that although different loss functions may perform differently on various tasks or data, the overall average performance is quite similar.
This tells us that the existing loss functions of generative adversarial networks have different advantages and disadvantages, and their predefined adversarial optimization strategies may lead to instability during the training of generative adversarial networks. Inspired by natural evolution, we designed an evolutionary framework for training generative adversarial networks. During each iteration, the generator undergoes different mutations to produce multiple offspring. Then, given the currently learned discriminator, we evaluate the quality and diversity of the samples produced by the updated offspring. Finally, based on the principle of “survival of the fittest,” we eliminate poorly performing offspring and retain the remaining well-performing generators for further adversarial training.
The evolutionary model-based generative adversarial networks overcome the inherent limitations of individual adversarial training methods, significantly stabilizing the training process of generative adversarial networks and improving generation effects. Experiments have shown that the proposed E-GAN achieves convincing image generation performance and reduces the inherent training problems of existing GANs.
This work has been recognized as a hot paper by MIT Technology Review (one of “The Best of the Physics arXiv”).

We all know that deep neural networks have a characteristic: they have a large parameter space and high model complexity. Traditional statistical learning theory suggests that the larger the parameter space and the higher the model complexity, the stronger the fitting ability to the training data, but the generalization ability becomes worse.
The Universal approximation theorem has proven that a traditional multilayer perceptron with one hidden layer can fit any data. For example, such a model can fully fit data like ImageNet. If so, why do we continue to increase the depth of the network, from the initially six layers of AlexNet to the later 152 layers of ResNet, and even some using hundreds of layers? Because we know that this single hidden layer model only has a chance to achieve a small training error, but its generalization ability is very poor. That is to say, the testing effect is not good.
For a machine learning model, if its training error is much smaller than its testing error, then it has overfitted. Within the current framework of statistical learning theory, there are two unresolved questions regarding neural networks: first, why do deep neural networks with very high model complexity not overfit? Second, is a deeper deep neural network better?
Using the information processing inequality in information theory, our recent work has reached an interesting conclusion: the generalization error of deep neural networks decreases exponentially with the increase in layers. This conclusion tells us that, under the premise of ensuring that the training error is sufficiently small, in principle, the deeper the network, the better.
Reasoning and Behavior Tasks: Visual Dialog and Visual Question Answering
Regarding reasoning and behaving, we have also done some work. Here I would like to mention imitation learning, visual question answering, and visual dialog.
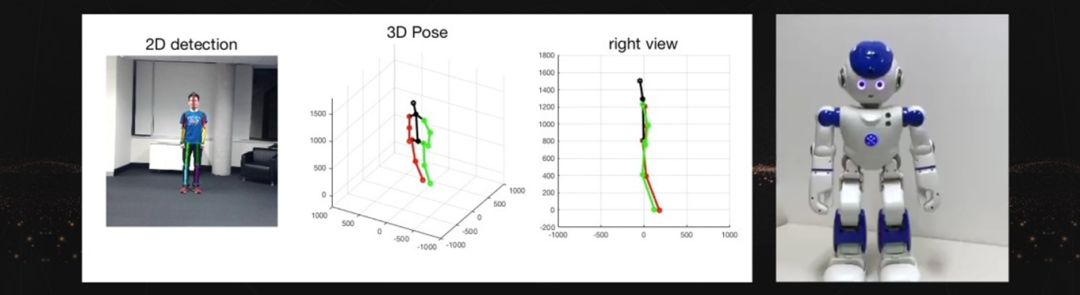
Currently, the main interaction method for any robot is through set programs and parameters. However, modern robots are equipped with cameras, so we hope that in the near future, robots can learn by observing human actions and imitating human actions.

Visual question answering aims to solve fine-grained content understanding of visual content through a question-and-answer interaction method. Given any image, users can ask questions about the image content using natural language, and the algorithm provides accurate answers in natural language. A typical visual question answering framework mainly consists of three modules: fine-grained representation of visual features, visual attention learning, and fine-grained fusion of multimodal features.
For the three key modules, we have proposed more effective methods. Such models are also very important for the interaction between robots and humans. In the real-time leaderboard of the standard dataset VQA v2 for visual question answering, our method has achieved the best level in the industry.

A related task that is more complex than visual question answering is visual dialog. Compared to visual question answering tasks, visual dialog has two challenges: first, the historical context of the dialogue, i.e., the referential relationship. Second, how to distinguish similar answers. We effectively considered these two issues in recent competitions and achieved good results.
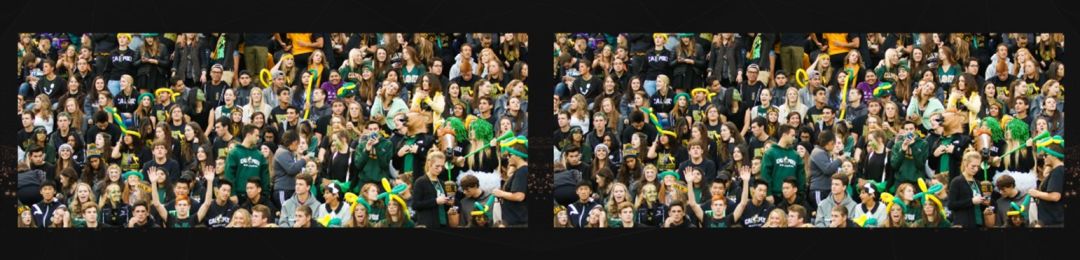
Finally, I would like you to take a look at this photo. Now, I won’t ask you how many people are here, but rather what these people are doing. I believe you can instantly tell me that these people are watching a match. The content of this photo is completely different from that of the photo at the beginning of the speech. That photo was of everyone taking a group photo. However, for computers, answering what is different between these two photos is still difficult; at least it requires a large amount of training data to answer such a very simple question.

Is this kind of intelligence what we need from artificial intelligence? Clearly not, we hope that in the future our computers can have common characteristics with humans in many aspects. Therefore, we need to enhance the reasoning and behavior capabilities of computers.
Thank you all!

