Source: DeepHub IMBA
This article is about 3500 words long and is recommended to be read in 5 minutes.
In this article, several methods for extracting keywords from statistical, graph-based, and embedding approaches are introduced.
Keyword extraction methods can find relevant keywords in documents. In this article, I summarize the most commonly used keyword extraction methods.
What is Keyword Extraction?
Keyword extraction is the process of retrieving keywords or key phrases from a text document. These keywords are selected from phrases in the text document and represent the main topic of the document. In this article, I summarize the most commonly used methods for automatic keyword extraction.
The methods for automatically extracting keywords from documents are heuristic methods that select the most frequent and significant words or phrases from the text document. I categorize keyword extraction methods under the field of Natural Language Processing, which is an important area in machine learning and artificial intelligence.
A keyword extractor is used to extract words (keywords) or create phrases (key phrases) consisting of two or more words. In this article, I use the term keyword extraction, which includes both keyword and key phrase extraction.
Why Do We Need Keyword Extraction Methods?
Time-saving — Based on keywords, one can determine whether the subject of the text (e.g., an article) is of interest and whether to read it. Keywords provide users with a summary of the main content of the article or document.
Finding Related Documents — The emergence of a vast number of articles makes it impossible to read all of them. Keyword extraction algorithms can help us find related articles. Keyword extraction algorithms can also automatically construct books, publications, or indexes.
Keyword extraction as support for machine learning — Keyword extraction algorithms find the most relevant words that describe the text. They can later be used for visualization or automatic categorization of the text.
Keyword Extraction Methods
In this article, I will outline some of the most commonly used keyword extraction methods. I will consider unsupervised (no training required) and domain-independent methods. I categorize the methods into three groups: statistical methods, graph-based methods, and vector embedding-based methods.
Statistical Methods
Statistical methods are the simplest. They calculate statistics for keywords and use these statistics to score them. Some of the simplest statistical methods are term frequency, collocation, and co-occurrence. There are also some more complex ones, such as TF-IDF and YAKE!.
TF-IDF, or term frequency–inverse document frequency, calculates the importance of a word in a document relative to the entire corpus (a larger set of documents). It calculates the frequency of each word in the document and weights it by the inverse frequency of the word across the entire corpus. Finally, the highest-scoring words are selected as keywords.
The formula for TF-IDF is as follows:
Where t is the observed term. This equation applies to each term (word or phrase) in the document. The blue part of the equation is term frequency (TF), and the orange part is inverse document frequency (IDF).
The idea behind TF-IDF is that words that appear more frequently in a document are not necessarily the most relevant. This algorithm favors terms that frequently appear in a text document but are less common in other documents.
The advantage of TF-IDF is its speed, while the disadvantage is that it requires at least dozens of documents in the corpus, and TF-IDF is language-independent.
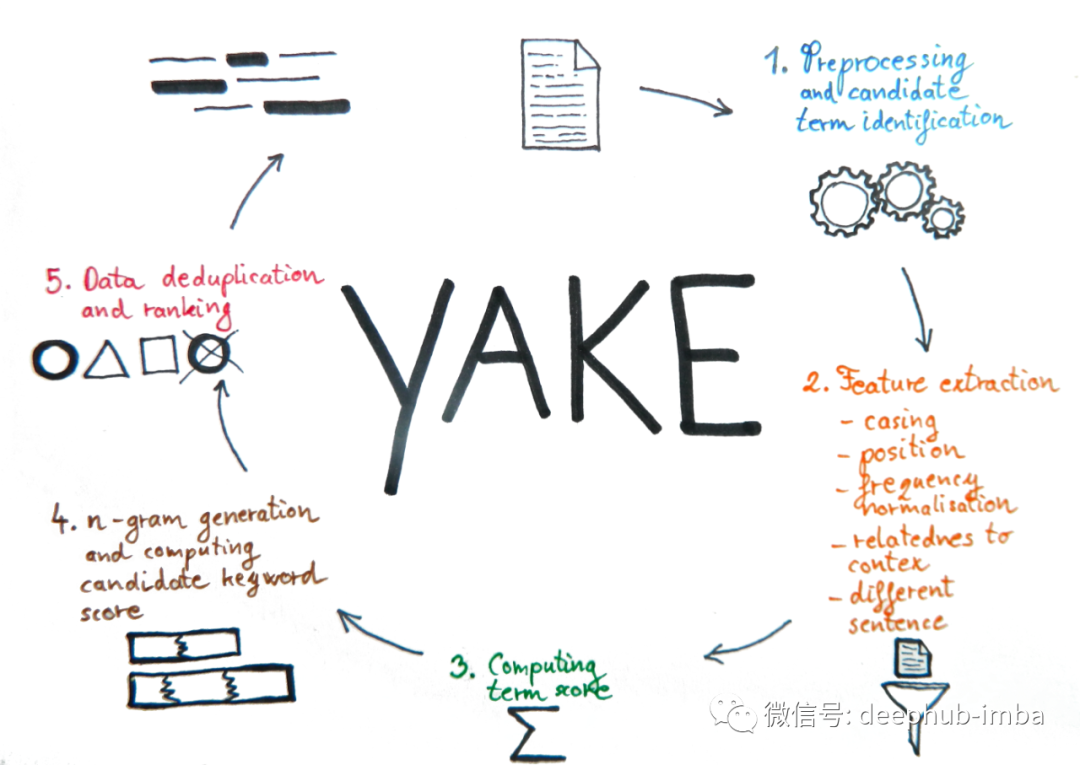
YAKE (Yet Another Keyword Extractor) is a keyword extraction method that utilizes statistical features of a single document to extract keywords. It extracts keywords through five steps:
1. Preprocessing and candidate word identification — The text is divided into sentences, chunks (parts of sentences separated by punctuation), and tokens. The text is cleaned, tokenized, and stop words are identified.
2. Feature extraction — The algorithm calculates the following five statistical features of terms (words) in the document:
a) Case — Counts how many times the term appears capitalized or as an acronym in the text (proportional to all appearances). Important terms typically appear capitalized more frequently.
b) Term position — The middle position of the term in the text. Terms closer to the beginning are generally more important.
c) Term frequency normalization — Measures the balanced term frequency in the document.
d) Term-context relevance — Measures the number of different terms co-occurring with the candidate term. More important terms co-occur with fewer different terms.
e) Term appearances in different sentences — Measures how many times the term appears in different sentences. The higher the score, the more important the term.
3. Calculate term scores — The features from the previous step are combined into a single score using an artificial equation.
4. Generate n-grams and calculate keyword scores — The algorithm identifies all valid n-grams. Words in the n-gram must belong to the same chunk and cannot start or end with a stop word. Then, by multiplying the scores of each member of the n-gram and normalizing it, the influence of n-gram length is reduced. The handling of stop words is done differently to minimize their impact.
5. Duplicate removal and ranking — In the final step, the algorithm removes similar keywords. It retains the more relevant one (the one with the lower score). Similarity is calculated using Levenshtein similarity, Jaro-Winkler similarity, or sequence matchers. Finally, the list of keywords is sorted based on their scores.
The advantage of YAKE is that it does not rely on external corpora, document length, language, or domain. Compared to TF-IDF, it extracts keywords based on a single document and does not require a large corpus.
Graph-Based Methods
Graph-based methods generate graphs of related terms from the document. For example, the graph connects terms that co-occur in the text. Graph-based methods use graph ranking methods that consider the structure of the graph to score the importance of vertices. One of the most famous graph-based methods is TextRank.
TextRank is a graph-based ranking method used to extract relevant sentences or find keywords. I will focus on its use in keyword extraction. The method extracts keywords through the following steps:
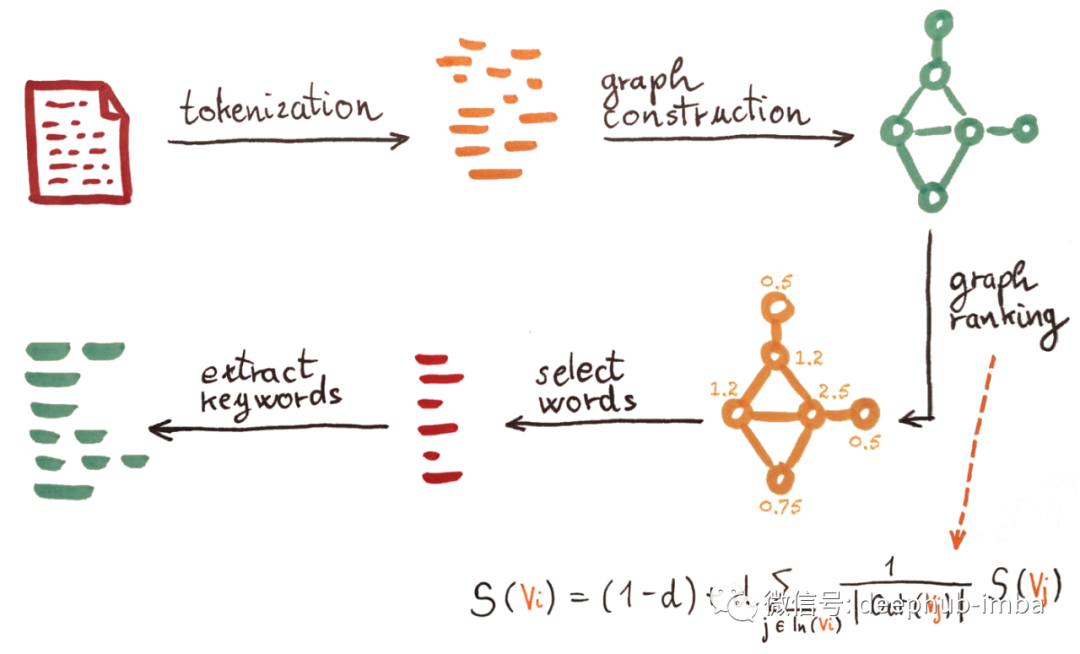
1. Text tokenization and annotation with Part-of-Speech (PoS) tags.
2. Co-occurrence graph construction — The vertices in the graph are words with selected PoS tags (the author only selects nouns and adjectives for best results). If two vertices appear within a window of N words in the text, they are connected by an edge (according to the author’s experiments, the optimal N is 2). The graph is undirected and unweighted.
3. Graph ranking — The score for each vertex is set to 1, and a ranking algorithm is run on the graph. The author uses Google’s PageRank algorithm, which is primarily used for ranking website graphs. The algorithm uses the formula shown above. The weight S(Vi) of vertex Vi is calculated by considering the weights of the vertices connected to node Vi. In the equation, d is set to 0.85, as described in the PageRank article. In(Vi) is the inbound links to vertex Vi, while Out(Vj) is the outbound links from vertex Vj. Since we are considering an undirected graph, the inbound and outbound links of the vertices are the same. The algorithm runs multiple iterations on each node until the weights on the nodes converge — the change between iterations is less than 0.0001.
4. Selection of the highest-scoring words — Words (vertices) are sorted from highest to lowest score. Finally, the algorithm selects the top 1/3 of the words.
5. Keyword extraction — In this step, if the words selected in the previous stage co-occur in the text, they are connected to form multi-word keywords. The score of the newly constructed keywords is the total score of the words.
The algorithm is executed for each document individually and does not require a document corpus for keyword extraction. TextRank is also language-independent.
RAKE (Rapid Automatic Keyword Extraction) is another graph-based keyword extraction algorithm. This algorithm is based on the observation that keywords are often composed of multiple words and typically do not include stop words or punctuation.
It includes the following steps:
1. Candidate keyword extraction — The text is split based on stop words and phrase delimiters to extract candidate keywords. Candidate keywords are phrases located between two stop words or phrase delimiters. For example, punctuation marks serve as phrase delimiters.
2. Keyword co-occurrence graph construction — The vertices in the graph are words. If they appear together in the candidate keywords, they are connected. The graph is weighted — the weight is the number of times the connecting words appear together in the candidate keywords. The graph also includes connections to the vertices themselves (each word connected to itself in the candidate keywords).
3. Word scoring — Each word in the graph is scored using one of the following scores:
a) Word degree deg(w) — The number of words that co-occur with word w (total edge weight, including edges pointing to the vertex itself). Degree favors words that appear more frequently and longer keywords.
b) Word frequency freq(w) — The number of times the word appears in any candidate keyword. Frequency favors words that appear more frequently.
c) Degree-to-frequency ratio deg(w)/freq(w) — This metric favors words that primarily appear in longer candidate keywords. It is recommended to use either word degree or the degree-to-frequency ratio. Ranking from these two perspectives will favor shorter keywords.
4. Candidate keyword scoring — The score for each candidate keyword is the sum of its member words’ scores.
5. Adjacent keywords — Candidate keywords do not include stop words. Since stop words may sometimes be part of keywords, this step adds them. The algorithm finds pairs of keywords connected to stop words in the text and adds them to the existing stop word set. They must appear at least twice in the text to be added. The score of the new keywords is the sum of the scores of their member keywords.
6. Keyword extraction — As a result, the top 1/3 of the highest-scoring keywords are extracted.
The main difference between RAKE and TextRank is that RAKE considers co-occurrences within candidate keywords rather than a fixed window. It uses a simpler and more statistical scoring procedure. The algorithm is performed separately for each document, so a document corpus is not needed for keyword extraction.
Based on Deep Learning
The emergence of deep learning has made embedding-based methods possible. Researchers have developed several keyword extraction methods using document embeddings (e.g., Bennani et al.).
These methods primarily look for a list of candidate keywords (e.g., Bennani et al. only consider keywords composed of nouns and adjectives). They embed the document and candidate keywords into the same embedding space and measure the similarity between the document and keyword embeddings (e.g., cosine similarity). They select the keywords most similar to the document text based on the similarity measure.
Conclusion
This article introduced several methods for extracting keywords from statistical, graph-based, and embedding methods. Since this field is very active, I only covered the most common methods. I only considered a subset of unsupervised methods (which do not require training). There are also supervised methods trained on annotated document datasets. They perform well but are less commonly used in practice because they require training and need annotated document datasets, and the results are usually only applicable to topics in the training dataset.
References
[1] Bennani-Smires, Kamil, et al. Simple unsupervised keyphrase extraction using sentence embeddings. arXiv preprint arXiv:1801.04470, 2018.
[1] Campos, Ricardo, et al. YAKE! Keyword extraction from single documents using multiple local features. Information Sciences, 2020, 509: 257–289.
[3] Jones, Karen Sparck. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 1972.
[4] Mihalcea, Rada; Tarau, Paul. TextRank: Bringing order into texts. 2004. In: Association for Computational Linguistics.
[5] Rose, Stuart, et al. Automatic keyword extraction from individual documents. Text mining: applications and theory, 2010, 1: 1–20.
Editor: Wang Jing
Proofreader: Wang Yuqing