
Click the above “Beginner Learning Vision” to select “Star” or “Pin”
Heavyweight content delivered first time
This article is reprinted from | Machine Learning Beginner
Introduction: Recently, the autonomous driving project requires learning some content about semantic segmentation, so I reviewed some papers and videos and made a simple summary. The note structure is: Machine Learning >> Deep Learning >> Semantic Segmentation
Table of Contents:
-
Review of Machine Learning
-
Review of Deep Learning
-
Introduction to Semantic Segmentation
-
Representative Algorithms of Semantic Segmentation
1. Review of Machine Learning


2. Review of Deep Learning
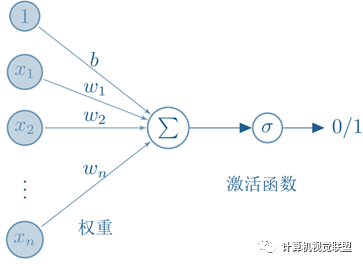
Activation Function

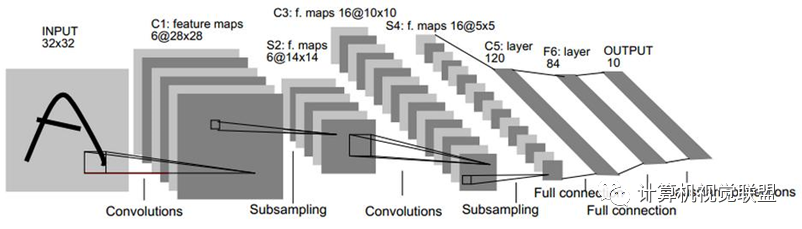
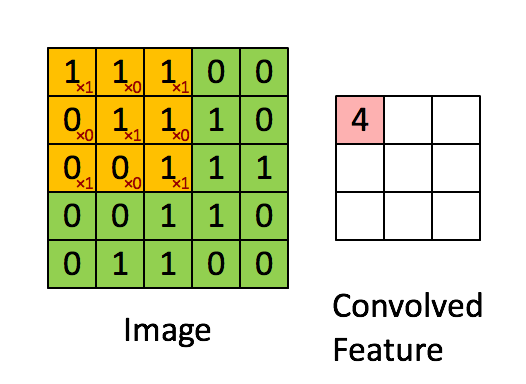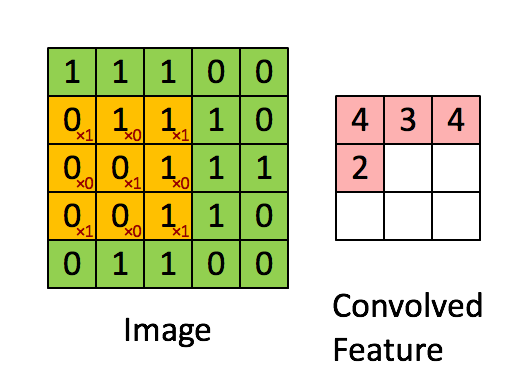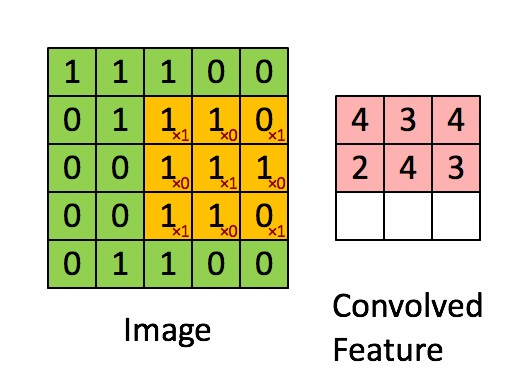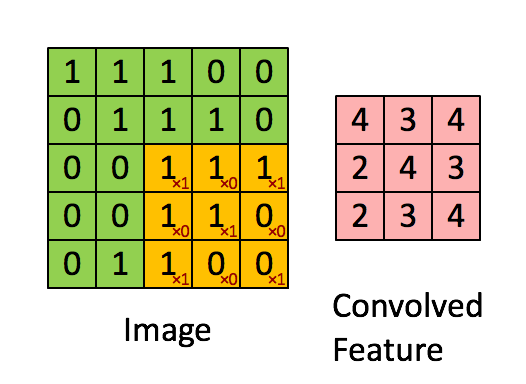
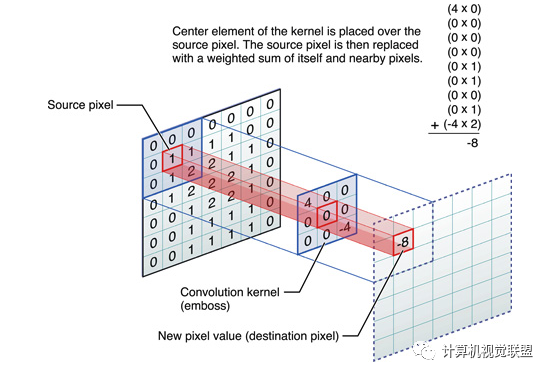
These Convolutions are a Core Component of Semantic Segmentation!
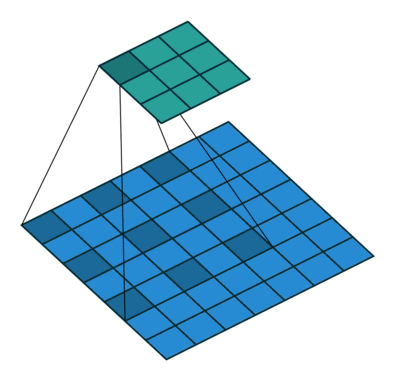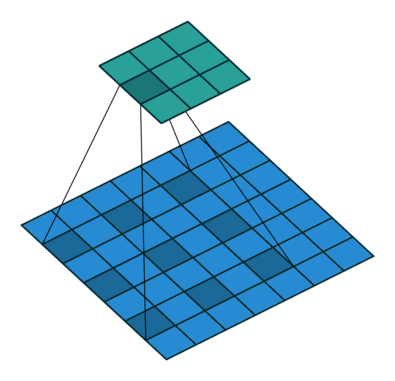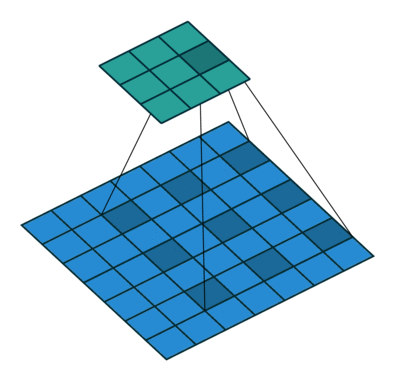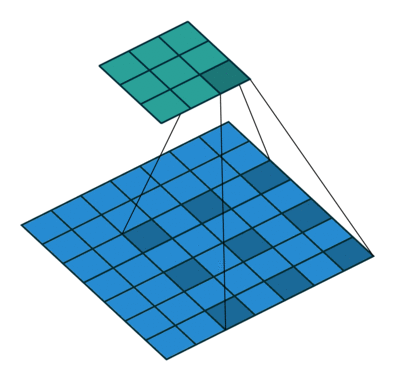
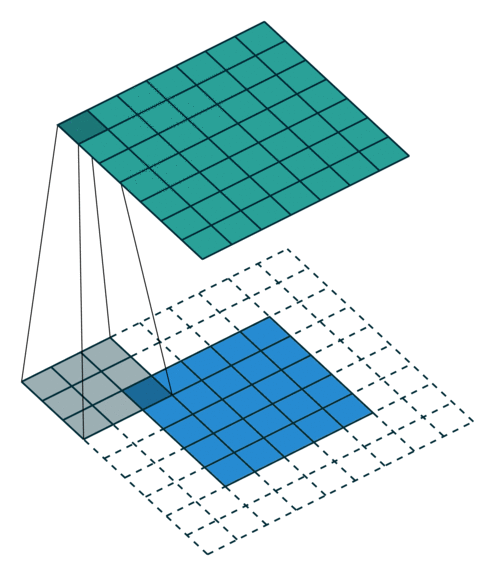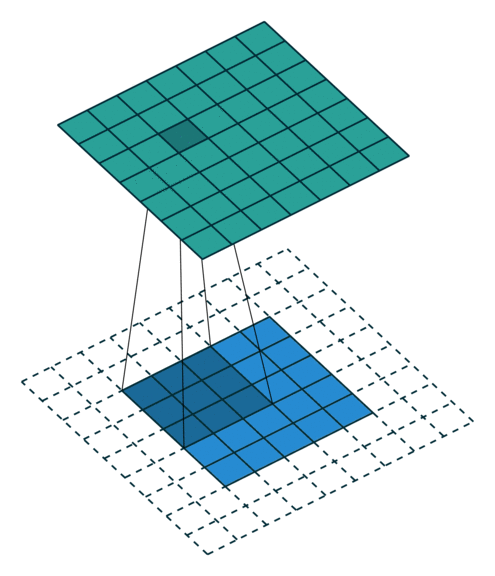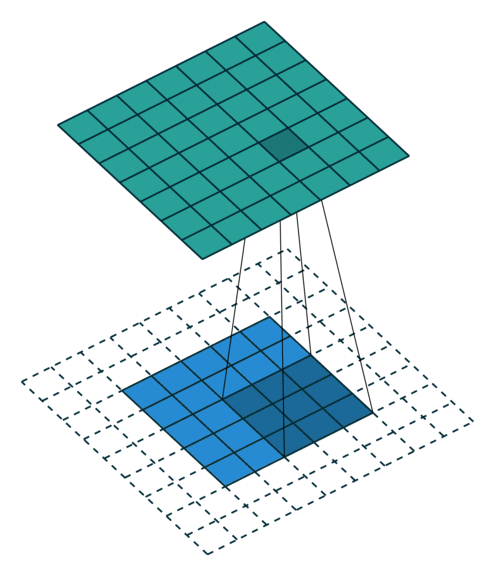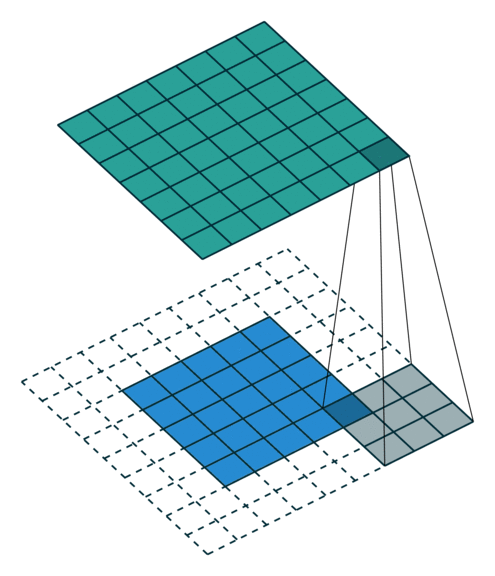
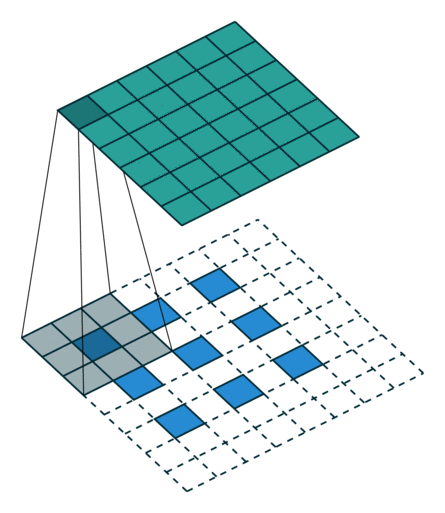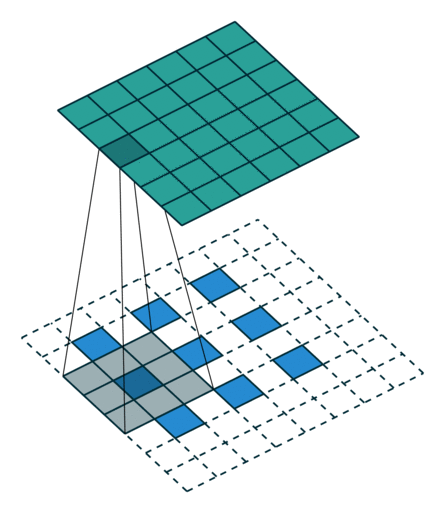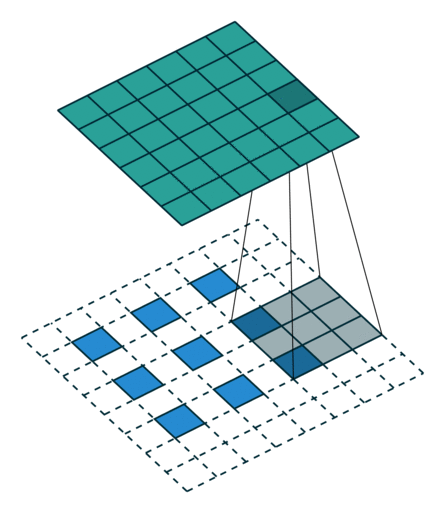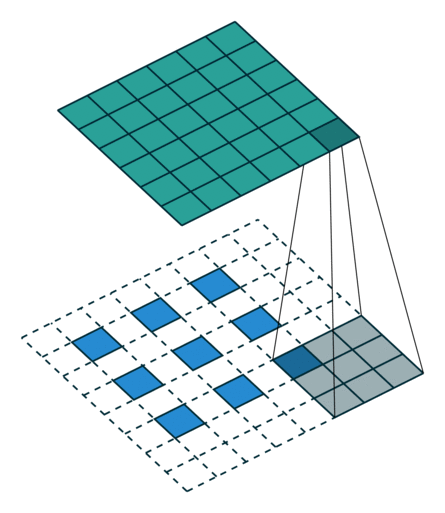
3. Introduction to Semantic Segmentation
What is Semantic Segmentation?
üSemantic segmentation: Assign a label to each point in the image according to its “semantic” category, distinguishing different types of objects in the image, which can be understood as a pixel-level classification task.

What Evaluation Metrics are Used for Semantic Segmentation?
ü1. Pixel Accuracy: Number of correctly classified pixels for each class / Actual number of pixels for each class.
ü2. Mean Pixel Accuracy: Average of the accuracy of each class of pixels.
ü3. Mean Intersection over Union (IOU): Average of IOU for each class. IOU refers to the intersection area of two regions / the union of the two areas, such as the green area in figure 2 / total area.
ü4. Frequency Weighted Intersection over Union: Frequency of occurrence of each class as a weight.
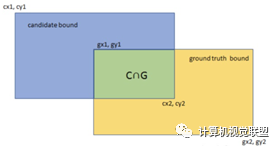
4. Representative Algorithms of Semantic Segmentation
Fully Convolutional Networks
2015 “Fully Convolutional Networks for Semantic Segmentation”
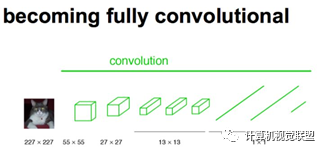
Typically, CNN networks will connect several fully connected layers after the convolutional layers to map the feature maps generated by the convolutional layers into a fixed-length feature vector.
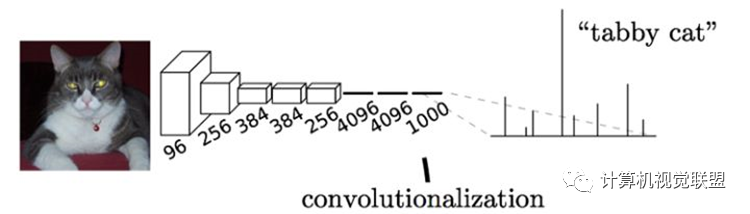
Input AlexNet, resulting in a 1000-length output vector, representing the probability of the input image belonging to each class, with the highest probability in the “tabby cat” class.
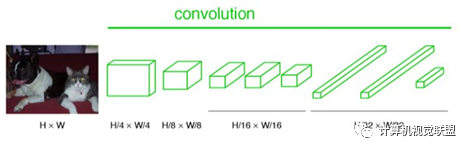
Unlike classic CNNs that use fully connected layers after convolutional layers to obtain a fixed-length feature vector for classification (fully connected layer + softmax output), FCN can accept input images of any size and uses deconvolution layers to upsample the feature map of the last convolutional layer, restoring it to the same size as the input image, thus generating a prediction for each pixel while preserving the spatial information of the original input image, and finally performing pixel-wise classification on the upsampled feature map.
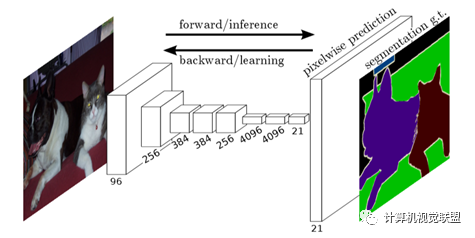
In simple terms, FCN differs from CNN in that it replaces the last fully connected layer of CNN with a convolutional layer, outputting an already labeled image.

Are there any drawbacks?
The results obtained are still not fine enough. Although 8x upsampling performs much better than 32x, the upsampling results are still relatively blurry and smooth, lacking sensitivity to details in the image.
It classifies each pixel without fully considering the relationship between pixels. It ignores the spatial regularization step used in the usual pixel-based classification segmentation methods, lacking spatial consistency.
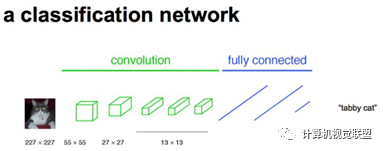
For any classification neural network, we can replace the FC layers with convolutional layers, just changing the way information is distributed. If we directly upsample the heatmap, we obtain FCN-32s.
Three Models: FCN-32S, FCN-16S, FCN-8S
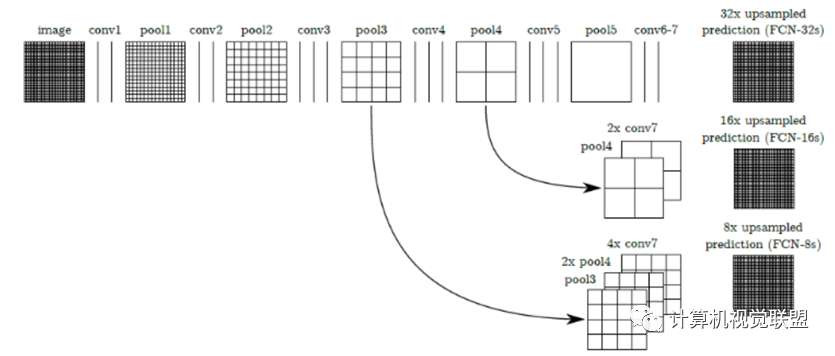
Main Contributions:
üNo fully connected layers (fc) in fully convolutional (fully conv) networks. Adapts to any input size.
üDeconvolution layers increase data size. Able to output fine results.
üSkip structure combines results from different depth layers. Ensures robustness and accuracy.
Drawbacks:
ØThe results obtained are still not fine enough. Although 8x upsampling performs much better than 32x, the upsampling results are still relatively blurry and smooth, lacking sensitivity to details in the image.
ØIt classifies each pixel without fully considering the relationship between pixels. It ignores the spatial regularization step used in the usual pixel-based classification segmentation methods, lacking spatial consistency.
SegNet
2015 “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation”
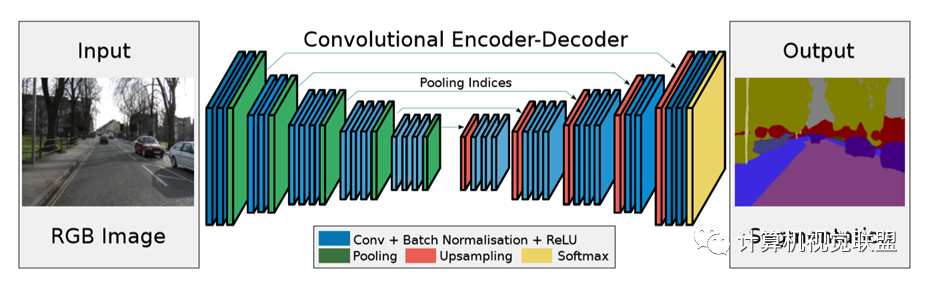
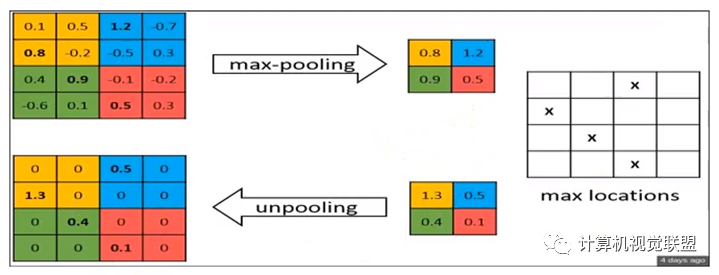
Max Pooling: Deconvolution
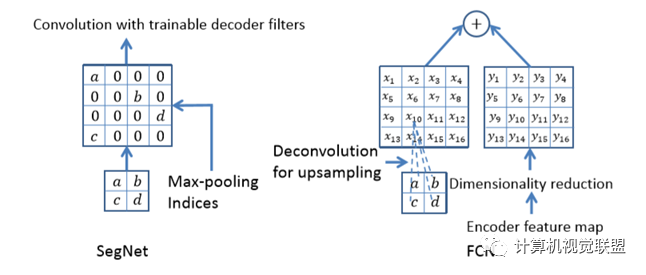
Compared to FCN, the difference of SegNet lies in the upsampling deconvolution.
U-Net
2015 “U-Net: Convolutional Networks for Biomedical Image Segmentation”
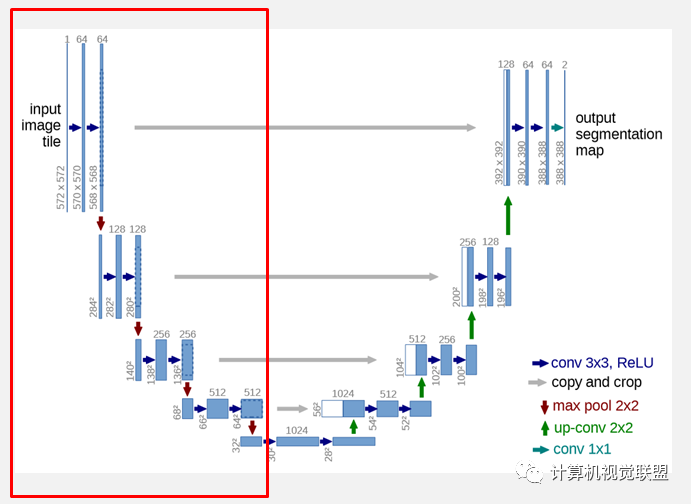
The left side of the network (red dashed line) consists of a series of downsampling operations made up of convolutions and Max Pooling, referred to as the contracting path in the paper. The contracting path consists of 4 blocks, each using 3 valid convolutions and 1 Max Pooling downsampling, doubling the number of Feature Maps after each downsampling, resulting in the size changes of Feature Maps shown in the figure. Finally, a Feature Map of size is obtained.
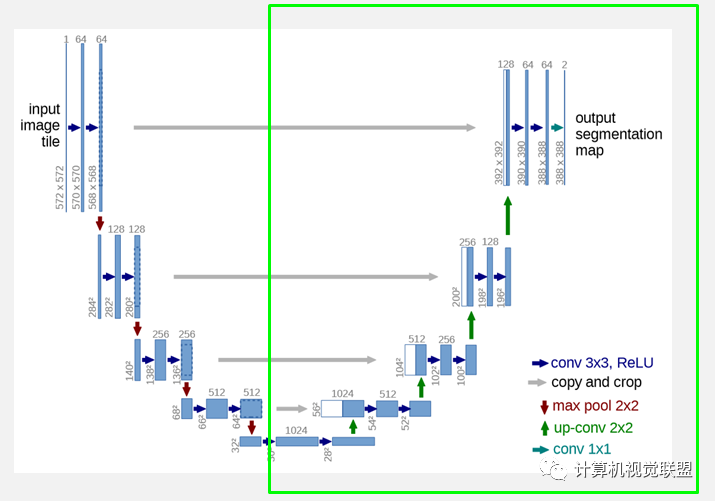
The right side of the network (green dashed line) is referred to as the expansive path in the paper. It also consists of 4 blocks, where before each block, the Feature Map size is doubled through deconvolution while halving its number (with slight differences in the last layer), and then merged with the Feature Map from the contracting path that is symmetric to the left side. Since the sizes of the Feature Maps from the contracting path and the expansive path differ, U-Net normalizes the Feature Map from the contracting path to match the size of the Feature Map from the expansive path (as shown in the dashed part on the left side of figure 1). The convolution operations in the expansive path still use valid convolution operations, resulting in a Feature Map of size . Since this task is a binary classification task, the network has two output Feature Maps.
U-Net does not utilize pooling location index information but instead transmits the entire feature map from the encoding phase to the corresponding decoder (at the cost of more memory), and connects it before upsampling (through deconvolution) to obtain the decoder feature map.
DeepLabV1
2015 “Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs”
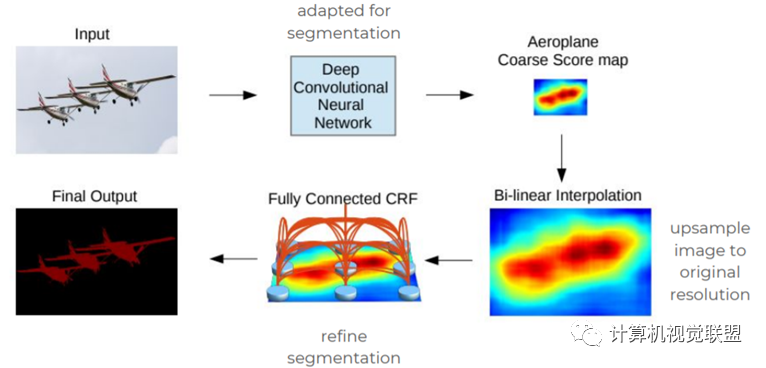
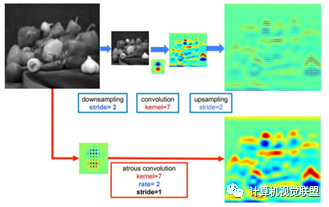
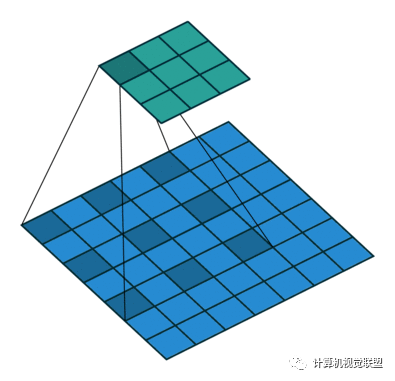
Increased Receptive Field
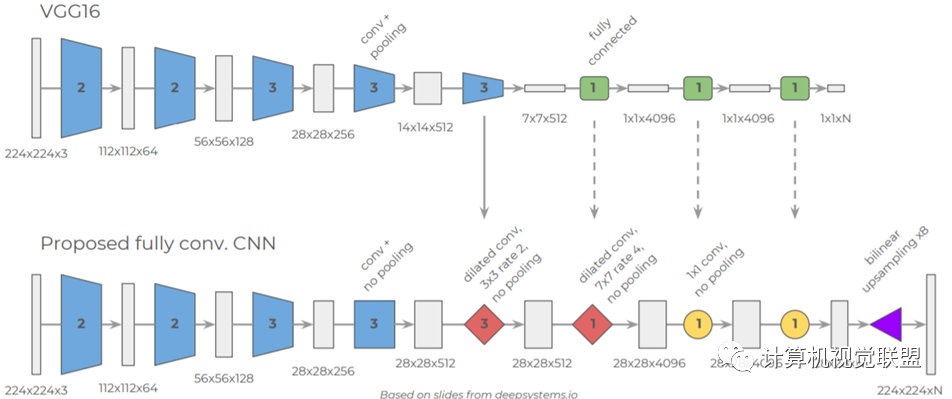
DeepLabV2
2015 “DeepLab-v2: Semantic Image Segmentation”
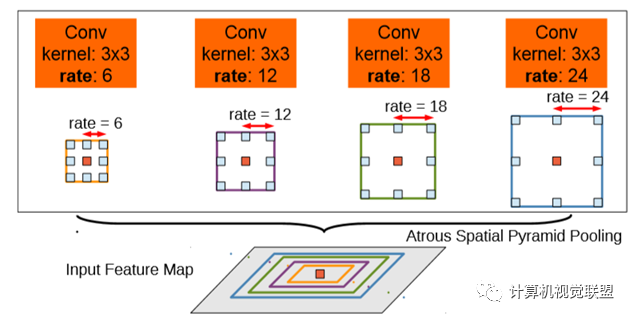
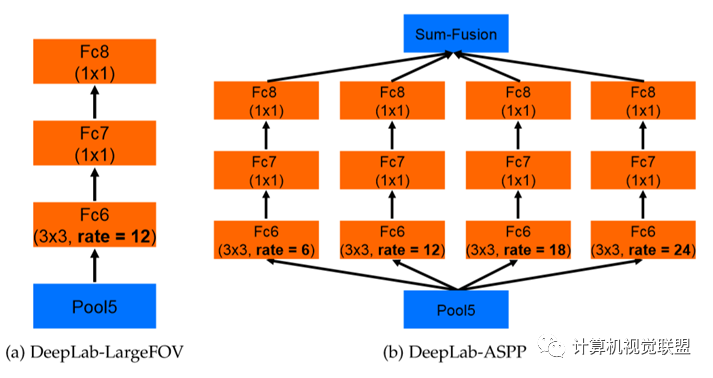
ASPP, Atrous Convolution Pyramid Pooling; VGG modified to ResNet
DeepLabv2 enhances the model’s ability to capture details using fully connected CRFs.
DeepLabv2 removed the downsampling layers in the last few max pooling layers, replacing them with atrous convolutions.
DeepLabV3
2017 “Rethinking Atrous Convolution for Semantic Image Segmentation”
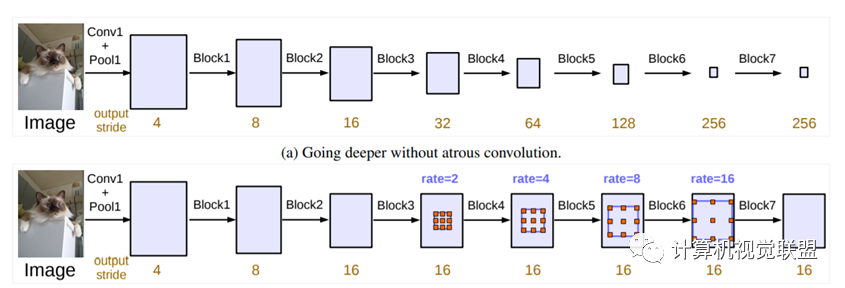

DeepLabV3+
2018 “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation”
Used two types of neural networks, employing spatial pyramid modules and encoder-decoder structures for semantic segmentation.
üSpatial Pyramid: Captures rich contextual information through pooling operations at different resolutions.
üEncoder-Decoder Architecture: Gradually achieves clear object boundaries.
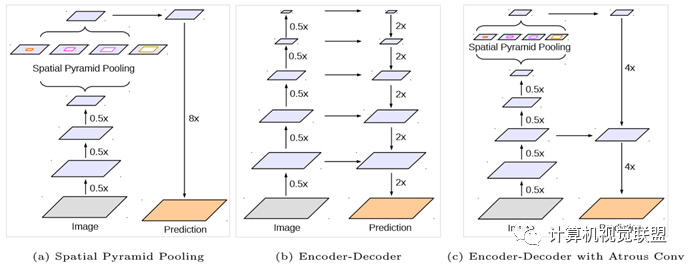
Encoder is the original DeepLabv3, with two main points:
The ratio of input size to output size (output stride = 16), with the dilation rate of the last stage being 2.
Atrous Spatial Pyramid Pooling module (ASPP) has four different rates, plus an additional global average pooling.
The decoder clearly shows that the encoder’s result is upsampled by 4 times, then concatenated with the Conv2 feature before downsampling in ResNet, followed by a 3×3 convolution, and finally upsampled by 4 times to obtain the final result. Notable points:
Before merging low-level information, a 1×1 convolution is performed to reduce channels (e.g., from 512 channels to 256 channels from the encoder’s result).
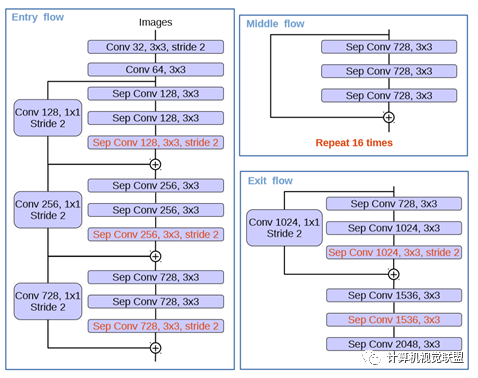
The red part indicates modifications.
(1) More layers: Changed from 8 times to 16 times (based on MSRA object detection work).
(2) The original simple pooling layer was changed to a deepwise separable convolution with a stride of 2.
(3) Additional RELU layers and normalization operations are added after each 3 × 3 depthwise convolution (originally only after the 1×1 convolution).
DeepLabv1: https://arxiv.org/pdf/1412.7062v3.pdf DeepLabv2: https://arxiv.org/pdf/1606.00915.pdf DeepLabv3: https://arxiv.org/pdf/1706.05587.pdf DeepLabv3+: https://arxiv.org/pdf/1802.02611.pdf Code: https://github.com/tensorflow/models/tree/master/research/deeplab
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D Vision, Sensors, Autonomous Driving, Computational Photography, Detection, Segmentation, Recognition, Medical Imaging, GAN, and Algorithm Competitions (these will be gradually subdivided in the future). Please scan the WeChat number below to join the group, with the note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Vision SLAM”. Please follow the format; otherwise, you will not be approved. After successful addition, you will be invited to the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise you will be removed from the group, thank you for your understanding~

