
Click the above “Beginner Learning Vision“, choose to add “Starred” or “Pinned“
Heavyweight content delivered at the first time

Convolutional Neural Networks (CNNs) have achieved unprecedented success in the field of computer vision, but we currently do not have a comprehensive understanding of the reasons for their remarkable effectiveness. In March 2018, Isma Hadji and Richard P. Wildes from the Department of Electrical Engineering and Computer Science at York University published a paper titled “What Do We Understand About Convolutional Networks?”, which outlines the technical foundations, constituent modules, current status, and research prospects of convolutional networks, introducing our current understanding of CNNs. This article summarizes that paper; for more detailed information, please refer to the original paper and the related literature indexed within it.

1.1 Motivation
In recent years, research in computer vision has primarily focused on Convolutional Neural Networks (commonly referred to as ConvNet or CNN). These works have achieved new state-of-the-art performance on a wide range of classification and regression tasks. In contrast, although the history of these methods can be traced back many years, the theoretical understanding of how these systems achieve outstanding results is still lagging. In fact, many achievements in the current field of computer vision treat CNNs as black boxes, which is effective, but the reasons for their effectiveness remain very vague, severely failing to meet the requirements of scientific research. In particular, there are two complementary questions: (1) What exactly is being learned in the aspects being learned (e.g., convolutional kernels)? (2) In terms of architectural design (e.g., number of layers, number of kernels, pooling strategies, choice of non-linearity), why are some choices better than others? The answers to these questions not only benefit our scientific understanding of CNNs but can also enhance their practicality.
Moreover, the current methods for implementing CNNs require a large amount of training data, and design decisions have a significant impact on performance. A deeper theoretical understanding should alleviate the dependence on data-driven design. Although empirical studies have investigated how the implemented networks operate, to date, these results have largely been limited to visualizing internal processing, aiming to understand what happens in different layers of CNNs.
1.2 Objectives
In response to the above situation, this report will outline the most prominent methods proposed by researchers that utilize multilayer convolutional architectures. It is important to highlight that this report will discuss the various components of typical convolutional networks by summarizing different approaches and will introduce the biological findings and/or reasonable theoretical basis on which their design decisions are based. Additionally, this report will summarize different attempts to understand CNNs through visualization and empirical studies. The ultimate goal of this report is to clarify the role of each processing layer involved in CNN architectures, consolidate our current understanding of CNNs, and indicate the problems that remain to be solved.
1.3 Report Outline
The structure of this report is as follows: This chapter provides the motivation for reviewing our understanding of convolutional networks. Chapter 2 will describe various multilayer networks and present the most successful architectures used in computer vision applications. Chapter 3 will focus more specifically on each construction module of typical convolutional networks and will discuss the design of different components from both biological and theoretical perspectives. Finally, Chapter 4 will discuss the current trends in CNN design and understanding, and will highlight some key shortcomings that still exist.
Overall, this chapter will briefly outline the most prominent multilayer architectures used in the field of computer vision. It should be noted that although this chapter covers the most important contributions in the literature, it will not provide a comprehensive overview of these architectures, as such overviews already exist elsewhere (e.g., [17, 56, 90]). Instead, the purpose of this chapter is to set the discussion foundation for the remaining parts of this report, so that we can detail and discuss the current understanding of convolutional networks used for visual information processing.
2.1 Multilayer Architectures
Before the recent success of deep learning-based networks, state-of-the-art computer vision systems for recognition relied on two separate but complementary steps. The first step is to transform the input data into an appropriate form through a set of manually designed operations (such as convolutions with a basic set, local or global encoding methods). This transformation of the input typically requires finding a compact and/or abstract representation of the input data while injecting some invariance according to the current task. The goal of this transformation is to change the data in a way that is easier for classifiers to separate. Secondly, the transformed data is usually used to train some types of classifiers (such as support vector machines) to recognize the content of the input signal. Generally speaking, the performance of any classifier is severely affected by the transformation method used.
Multilayer learning architectures bring a different perspective to this problem, proposing that not only should classifiers be learned, but the necessary transformation operations should also be learned directly from the data. This form of learning is often referred to as “representation learning,” and when applied in deep multilayer architectures, it is called “deep learning.”
Multilayer architectures can be defined as computational models that allow useful information to be extracted from multiple layers of abstraction of input data. Generally, the design goal of multilayer architectures is to highlight important aspects of the input at higher layers while becoming increasingly robust to less important variations. Most multilayer architectures stack simple building blocks with alternating linear and non-linear functions. Over the years, researchers have proposed many different types of multilayer architectures, and this chapter will cover the most prominent of these architectures used in computer vision applications. Artificial neural networks are a focus, as their performance is outstanding. For simplicity, we will refer to these networks directly as “neural networks”.
2.1.1 Neural Networks
A typical neural network consists of an input layer, an output layer, and multiple hidden layers, each containing multiple units.
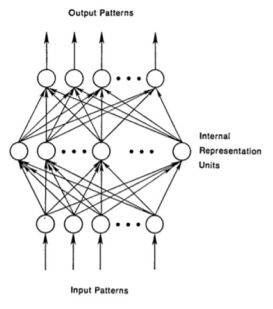
Figure 2.1: Schematic diagram of a typical neural network architecture, image from [17]
Autoencoders can be defined as multilayer neural networks consisting of two main parts. The first part is the encoder, which transforms the input data into a feature vector; the second part is the decoder, which maps the generated feature vector back to the input space.

Figure 2.2: Structure of a typical autoencoder network, image from [17]
2.1.2 Recurrent Neural Networks
When it comes to tasks that rely on sequential input, Recurrent Neural Networks (RNNs) are one of the most successful multilayer architectures. RNNs can be viewed as a special type of neural network where the input to each hidden unit is the data observed at its current time step and the state from the previous time step.
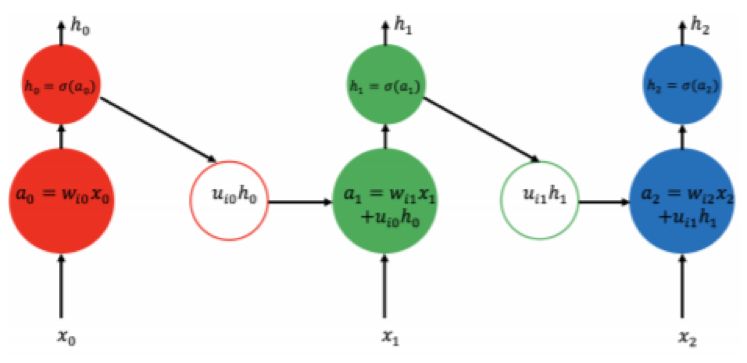
Figure 2.3: Schematic diagram of the operations of a standard recurrent neural network. The input to each RNN unit is the new input at the current time step and the state from the previous time step; then based on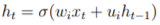 the calculations, a new output is obtained, which can then be fed to the next layer of the multilayer RNN for processing.
the calculations, a new output is obtained, which can then be fed to the next layer of the multilayer RNN for processing.
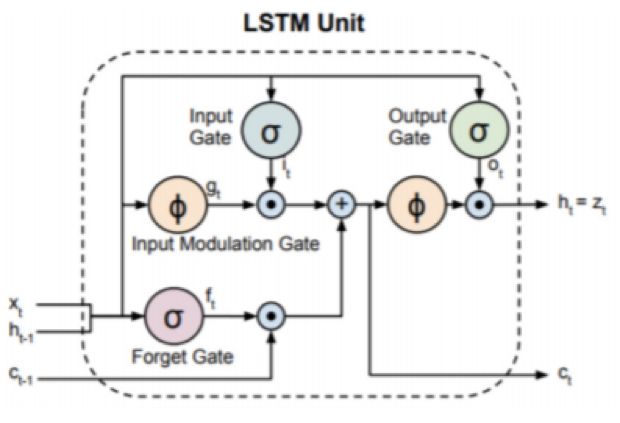
Figure 2.4: Schematic diagram of a typical LSTM unit. The input to this unit is the input at the current time and the input from the previous time, and then it returns an output and feeds it to the next time. The final output of the LSTM unit is controlled by the input gate, output gate, and memory cell state. Image from [33]
2.1.3 Convolutional Networks
Convolutional Networks (CNNs) are a class of neural networks especially suited for computer vision applications because they can use local operations to achieve hierarchical abstraction of representations. Two key design ideas have driven the success of convolutional architectures in the field of computer vision. First, CNNs leverage the 2D structure of images, where pixels in adjacent areas are often highly correlated. Therefore, CNNs do not require one-to-one connections between all pixel units (as most neural networks do) but can use grouped local connections. Second, CNN architectures rely on feature sharing, meaning that each channel (i.e., output feature map) is generated by convolving the same filter across all locations.

Figure 2.5: Schematic diagram of the structure of a standard convolutional network, image from [93]
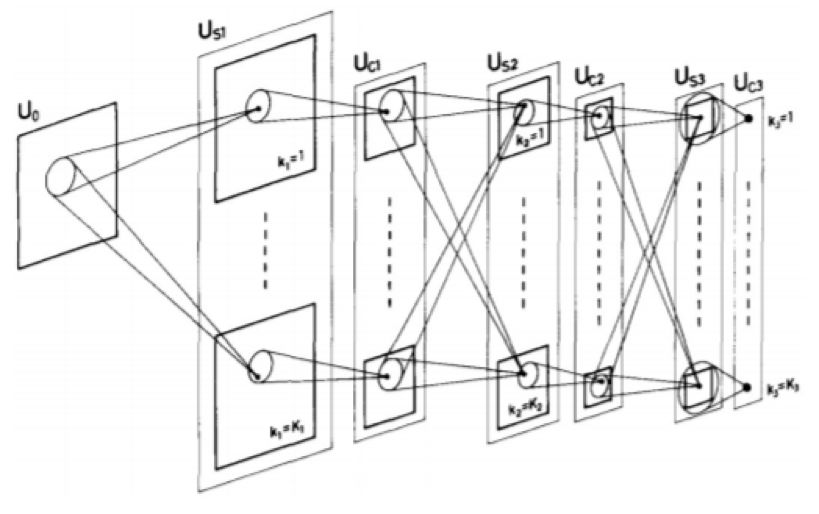
Figure 2.6: Schematic diagram of the structure of Neocognitron, image from [49]
2.1.4 Generative Adversarial Networks
A typical Generative Adversarial Network (GAN) consists of two competing modules or sub-networks: the generator network and the discriminator network.
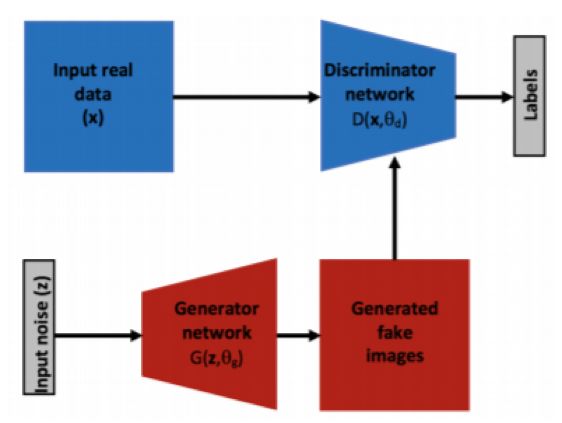
Figure 2.7: Schematic diagram of the general structure of Generative Adversarial Networks
2.1.5 Training Multilayer Networks
As previously discussed, the success of various multilayer architectures largely depends on the success of their learning processes. Their training processes are typically based on the backpropagation of errors using gradient descent. Due to its simplicity, gradient descent has widespread applications in training multilayer architectures.
2.1.6 Brief Discussion on Transfer Learning
The applicability of features extracted using multilayer architectures across various datasets and tasks can be attributed to their hierarchical nature, where representations evolve from simple and local to abstract and global. Therefore, features extracted at lower levels of their hierarchy are often common features shared across different tasks, making it easier to implement transfer learning.
2.2 Spatial Convolutional Networks
Theoretically, convolutional networks can be applied to data of any dimension. Their 2D instances are particularly suitable for the structure of a single image, which has garnered significant attention in the field of computer vision. With large-scale datasets and powerful computers for training, CNNs have recently seen rapid growth in applications across various tasks. This section will introduce prominent 2D CNN architectures that incorporate relatively novel components compared to the original LeNet.
2.2.1 Key Architectures in Recent Developments of CNNs
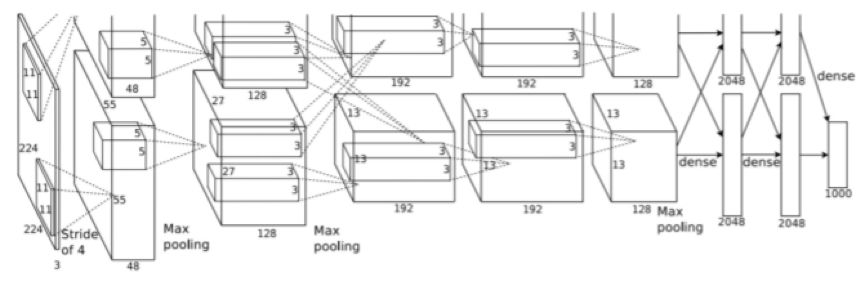
Figure 2.8: AlexNet architecture. It should be noted that although this appears to be a two-stream architecture, it is actually a single-stream architecture; this image simply illustrates the situation where AlexNet is trained in parallel on 2 different GPUs. Image from [88]

Figure 2.9: GoogLeNet architecture. (a) A typical inception module showing sequential and parallel operations. (b) A schematic diagram of a typical inception architecture composed of stacked inception modules. Image from [138]
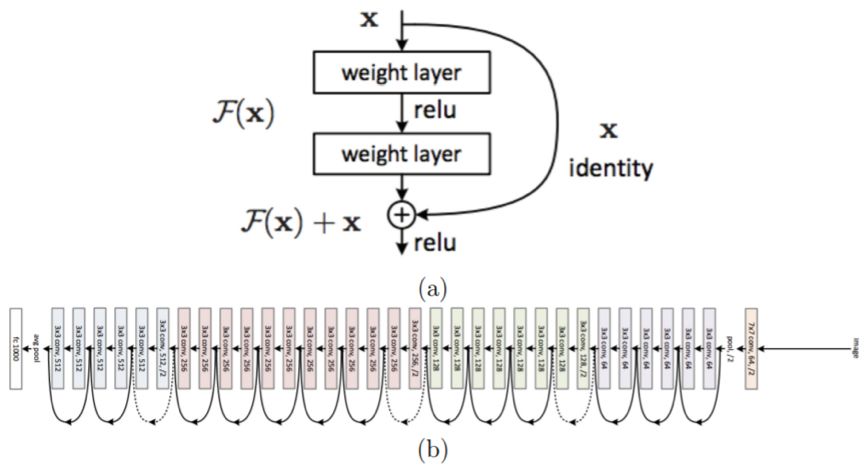
Figure 2.10: ResNet architecture. (a) Residual module. (b) A schematic diagram of a typical ResNet architecture composed of stacked residual modules. Image from [64]
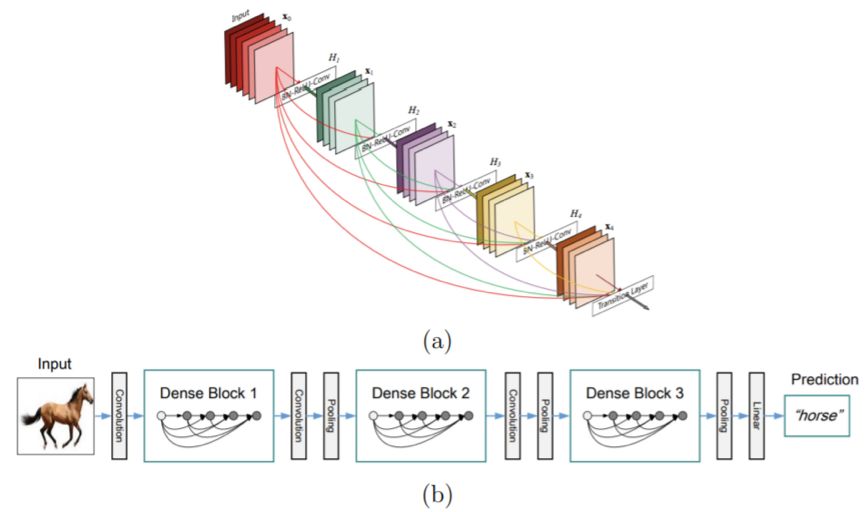
Figure 2.11: DenseNet architecture. (a) Dense module. (b) A schematic diagram of a typical DenseNet architecture composed of stacked dense modules. Image from [72]
2.2.2 Achieving Invariance in CNNs
One major challenge in using CNNs is the need for very large datasets to learn all the basic parameters. Even large-scale datasets like ImageNet, which contain over a million images, are still considered too small when training specific deep architectures. One method to meet this large dataset requirement is to artificially augment the dataset, which includes random flipping, rotation, and jittering of images. One significant advantage of these augmentation methods is that they enable the resulting networks to maintain better invariance when faced with various transformations.
2.2.3 Achieving Localization in CNNs
In addition to simple classification tasks such as object recognition, CNNs have also shown excellent performance in tasks requiring precise localization, such as semantic segmentation and object detection.
2.3 Spatio-Temporal Convolutional Networks
The use of CNNs has brought significant performance improvements to various image-based applications and has also sparked researchers’ interest in extending 2D spatial CNNs to 3D spatio-temporal CNNs for video analysis. Generally, various spatio-temporal architectures proposed in the literature attempt to extend the 2D architecture in the spatial domain (x,y) into the temporal domain (x,y,t). In the field of training spatio-temporal CNNs, there are three prominent different architectural design decisions: LSTM-based CNNs, 3D CNNs, and Two-Stream CNNs.
2.3.1 LSTM-Based Spatio-Temporal CNNs
LSTM-based spatio-temporal CNNs are some of the early attempts to extend 2D networks to handle spatio-temporal data. Their operations can be summarized in three steps as shown in Figure 2.16. The first step is to use a 2D network to process each frame and extract feature vectors from the last layer of these 2D networks. The second step is to use these features from different time steps as input to the LSTM to obtain results over time. The third step is to average or linearly combine these results and then pass them to a softmax classifier to obtain the final prediction.
2.3.2 3D CNNs
This prominent spatio-temporal network is the most direct generalization of 2D CNNs to the spatio-temporal domain of images. It directly processes the temporal flow of RGB images and handles these images by applying the learned 3D convolutional filters.
2.3.3 Two-Stream CNNs
This type of spatio-temporal architecture relies on a dual-stream design. The standard dual-stream architecture employs two parallel pathways—one for processing appearance and another for processing motion; this approach is similar to the dual-stream hypothesis in studies of biological visual systems.
2.4 Overall Discussion
It should be emphasized that although these networks have achieved competitive results in many computer vision applications, their main drawbacks still exist: limited understanding of the exact nature of the learned representations, dependence on large-scale training datasets, lack of support for accurate performance boundaries, and unclear selection of network hyperparameters.
Given the many unresolved issues in the field of CNNs, this chapter will introduce the role and significance of each processing layer in typical convolutional networks. To this end, this chapter will outline the most prominent work in addressing these issues. It is particularly noteworthy that we will demonstrate the modeling of CNN components from both theoretical and biological perspectives. After introducing each component, we will summarize our current level of understanding.
3.1 Convolutional Layers
The convolutional layer can be considered one of the most important steps in a CNN architecture. Essentially, convolution is a linear operation with translation invariance, composed of a combination of local weighting applied to the input signal. Depending on the chosen set of weights (i.e., the selected point spread function), different properties of the input signal will be revealed. In the frequency domain, the modulation function associated with the point spread function illustrates how the frequency components of the input are modulated through scaling and phase shifting. Therefore, choosing the appropriate kernel is crucial for extracting the most significant and important information contained in the input signal, allowing the model to make better inferences about the content of that signal. This section will discuss various methods for implementing this kernel selection step.
3.2 Rectification
Multilayer networks are typically highly non-linear, and rectification is often the first processing stage that introduces non-linearity into the model. Rectification refers to applying non-linear activation functions to the output of the convolutional layer. This term is borrowed from signal processing, where rectification refers to converting alternating current into direct current. This is also a processing step that can be traced back to both biological and theoretical origins. The goal of computational neuroscientists in introducing the rectification step is to find a model that best explains current neuroscience data. On the other hand, machine learning researchers use rectification to allow models to learn faster and better. Interestingly, researchers from both fields often agree on this point: they not only need rectification but also converge on the same type of rectification.
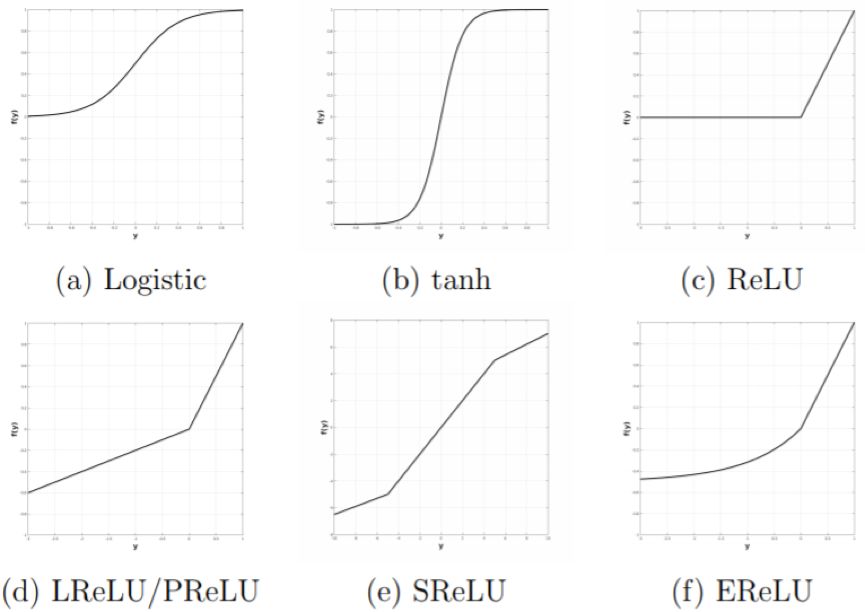
Figure 3.7: Non-linear rectification functions used in the literature on multilayer networks
3.3 Normalization
As mentioned earlier, due to the presence of cascading non-linear operations in these networks, multilayer architectures are highly non-linear. In addition to the rectified non-linearity discussed in the previous section, normalization is another non-linear processing module that plays an important role in CNN architectures. The most widely used form of normalization in CNNs is known as Divisive Normalization (DN), also referred to as Local Response Normalization. This section will describe the role of normalization and how it corrects the shortcomings of the first two processing modules (convolution and rectification). Similarly, we will discuss normalization from both biological and theoretical perspectives.
3.4 Pooling
Whether biologically inspired, purely learning-based, or entirely artificially designed, almost all CNN models include a pooling step. The goal of pooling operations is to provide a degree of invariance to changes in position and size, as well as to aggregate responses within and across feature maps. Similar to the three CNN modules discussed in previous sections, pooling has both biological and theoretical support. The main debate regarding this processing layer in CNN networks is the choice of pooling function. The two most widely used pooling functions are average pooling and max pooling. This section will explore the advantages and disadvantages of various pooling functions described in the relevant literature.

Figure 3.10: Comparison of average pooling and max pooling on images after Gabor filtering. (a) Shows the effects of average pooling at different scales, where the top row in (a) is the result applied to the original grayscale image, and the bottom row in (a) is the result applied to the image after Gabor filtering. Average pooling yields a smoother version of the grayscale image, while the sparse Gabor-filtered image fades away. In contrast, (b) shows the effects of max pooling at different scales, where the top row in (b) is the result applied to the original grayscale image, and the bottom row in (b) is the result applied to the image after Gabor filtering. Here, it can be seen that max pooling leads to a decline in the quality of the grayscale image, while the sparse edges in the Gabor-filtered image are enhanced. Image from [131]
The discussion of the roles of various components in CNN architectures highlights the importance of the convolutional module, which is largely responsible for extracting the most abstract information in the network. In contrast, our understanding of this processing module is the least because it requires the heaviest computation. This chapter will introduce the current trends in attempting to understand what different layers of CNNs learn. At the same time, we will highlight the problems that remain to be solved in these trends.
4.1 Current Trends
Although various CNN models continue to advance the current state-of-the-art performance in many computer vision applications, progress in understanding how these systems work and the reasons for their effectiveness remains limited. This issue has garnered significant interest from many researchers, leading to numerous methods for understanding CNNs. Generally, these methods can be categorized into three directions: visualizing the learned filters and extracted feature maps, ablation studies inspired by biological methods for understanding the visual cortex, and minimizing the learning process by introducing analytical principles into network design. This section will briefly outline each of these methods.
4.2 Problems to Be Solved
Based on the above discussion, key research directions for visualization-based methods include:
-
First and foremost, it is crucial to develop methods that make the evaluation of visualizations more objective, which can be achieved by introducing metrics to assess the quality and/or significance of the generated visualizations.
-
Additionally, while it seems that network-centered visualization methods are more promising (as they do not depend on the network itself to generate visualization results), it also appears necessary to standardize their evaluation processes. One possible solution is to use a benchmark to generate visualization results for networks trained under the same conditions. Such a standardization method can also enable metric-based evaluation, rather than the current interpretative analysis.
-
Another direction for development is to visualize multiple units simultaneously to better understand the distributed aspects of the representations under study, and even to follow a controlled method simultaneously.
Here are potential research directions based on ablation studies:
-
Using a common systematic organization of datasets that contain different common challenges in the field of computer vision (e.g., variations in perspective and lighting), and also require more complex categories (e.g., complexity in texture, parts, and objects). In fact, such datasets have recently emerged [6]. Using ablation studies on such datasets, combined with an analysis of the resulting confusion matrix, can identify patterns of errors in CNN architectures, leading to better understanding.
-
Moreover, systematic studies on the effects of multiple coordinated ablations on model performance are of great interest. Such studies should extend our understanding of how independent units work.
Finally, these controlled methods are promising future research directions; because compared to completely learning-based methods, these methods can provide deeper insights into the operations and representations of these systems. Some interesting research directions include:
-
Gradually fixing network parameters and analyzing their impact on network behavior. For example, fixing the convolutional kernel parameters of one layer at a time (based on existing prior knowledge of the task) to analyze the applicability of the kernels used at each layer. This progressive method is expected to reveal the role of learning and can also serve as an initialization method to minimize training time.
-
Similarly, the design of the network architecture (e.g., number of layers or number of filters per layer) can be studied by analyzing the nature of the input signals (e.g., common content in the signals). This approach helps to achieve an appropriate complexity of the architecture for the application.
-
Finally, while applying controlled methods to network implementations, systematic studies can also be conducted on the roles of other aspects of CNNs that have received less attention due to the focus on the learned parameters. For instance, various pooling strategies and residual connections can be studied while most learned parameters are fixed.
Good news!
The "Beginner Learning Vision" knowledge group is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Extension Module Chinese Tutorial" in the background of the "Beginner Learning Vision" public account to download the first Chinese version of the OpenCV extension module tutorial on the internet, covering more than twenty chapters of content including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: Python Vision Practical Projects 52 Lectures
Reply "Python Vision Practical Projects" in the background of the "Beginner Learning Vision" public account to download 31 visual practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: OpenCV Practical Projects 20 Lectures
Reply "OpenCV Practical Projects 20 Lectures" in the background of the "Beginner Learning Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning in OpenCV.
Discussion Group
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will be gradually subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction". For example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes, otherwise, you will not be approved. After successful addition, you will be invited to join the relevant WeChat group based on your research direction. Please do not send advertisements in the group, otherwise, you will be removed from the group. Thank you for your understanding~