The presentation today will focus on the following four points:
1. Stop Large Model Hallucinations, AIGC Era’s CVP Stack
2. A Database Born for AI – Vector Database
3. Application Scenarios
4. Future Prospects of LLM + Vector Database
Speaker|Jiao Enwei, Chief Engineer of Zilliz
Editor|Liu Hua
Content Proofreader|Li Yao
Produced by Community|DataFun
01
Stop Large Model Hallucinations, AIGC Era’s CVP Stack
1. Zilliz – Building Open Source + Cloud-Based Large Model Enhancement Solutions
Milvus is a high-performance vector database developed by Zilliz, which has been contributed to the Linux Foundation. Another project by Zilliz is Towhee, which addresses the complex logic of embedding operations required for unstructured data transmission using vector databases. The purpose of the Towhee project is to solve these issues. Another project is GPTCache, aimed at solving large model caching problems by embedding and storing user questions and answers in a vector database to enhance large model inference speed and help users save costs.

2. Large Model Hallucinations
The hallucination problem is a common issue during the training and inference processes of large models. This occurs because large models only store their parameters and architecture, not the text information required for real-time inference. Therefore, when large models perform inference, they generate based on probabilities derived from previously learned corpora and knowledge. If the training corpus has poor support for Chinese or if the annotations are not done well during fine-tuning, it can lead to low relevance between Lu Xun and Zhou Shuren, resulting in hallucination issues.

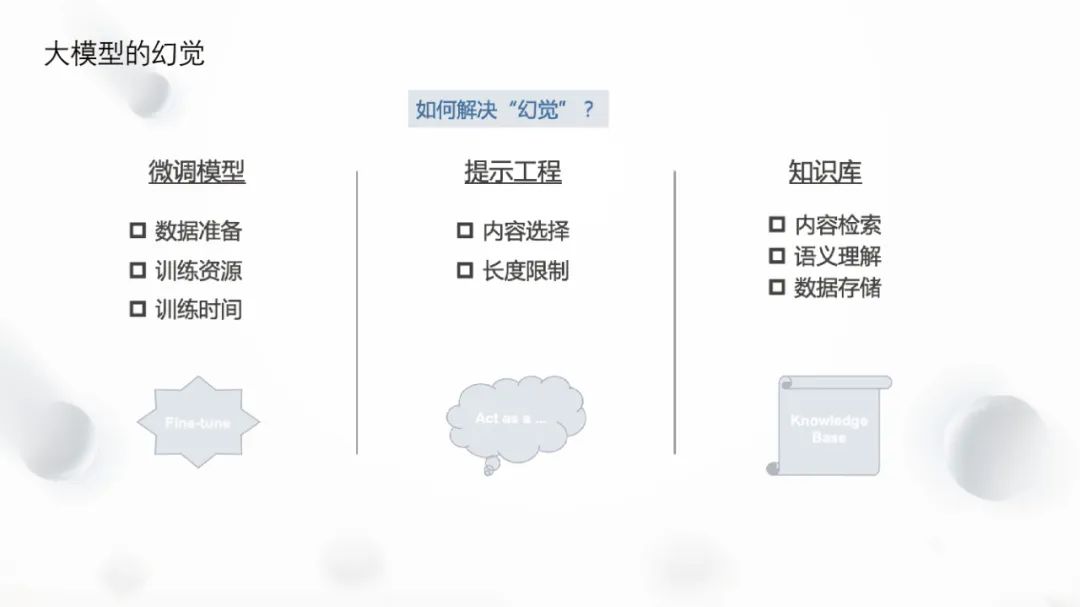
3. How to Solve Hallucinations
How to address this issue has become a focal point in the industry. Several solutions have been adopted in attempts to solve this problem.
-
First is fine-tuning, which adjusts the model through training, but many vendors are reluctant to fine-tune due to cost, data security, and other issues, and fine-tuning also has its limitations.
-
Secondly, passing preconditions to large models through prompt engineering is necessary, but this requires reasonable design and adjustment to ensure that the model can correctly process these conditions.

-
Additionally, using a knowledge base as a solution is also a common method. It can leverage existing enterprise internal wikis and Feishu documents, and achieve semantic understanding and data storage through vector databases by storing and retrieving text. Vector databases can help enterprises effectively segment documents into embeddings and store them in the database for text similarity retrieval and clustering to discover associations between knowledge.
4. CVP Architecture
Zilliz proposed a new architecture called CVP in today’s AIGC era, which includes components such as computing engines, storage, and control units, providing a simpler development approach for applications in the AI era. Large models represented by ChatGPT serve as computing engines, vector databases act as storage units, and Prompt-as-Code serves as control units. Other components, such as caching, drivers, and operating systems, can utilize similar products to solve problems. For instance, operating systems and frameworks can use products like LangChain or LlamaIndex, while drivers correspond to loading data into vector databases with more options available.

-
Demo Product OSSChat
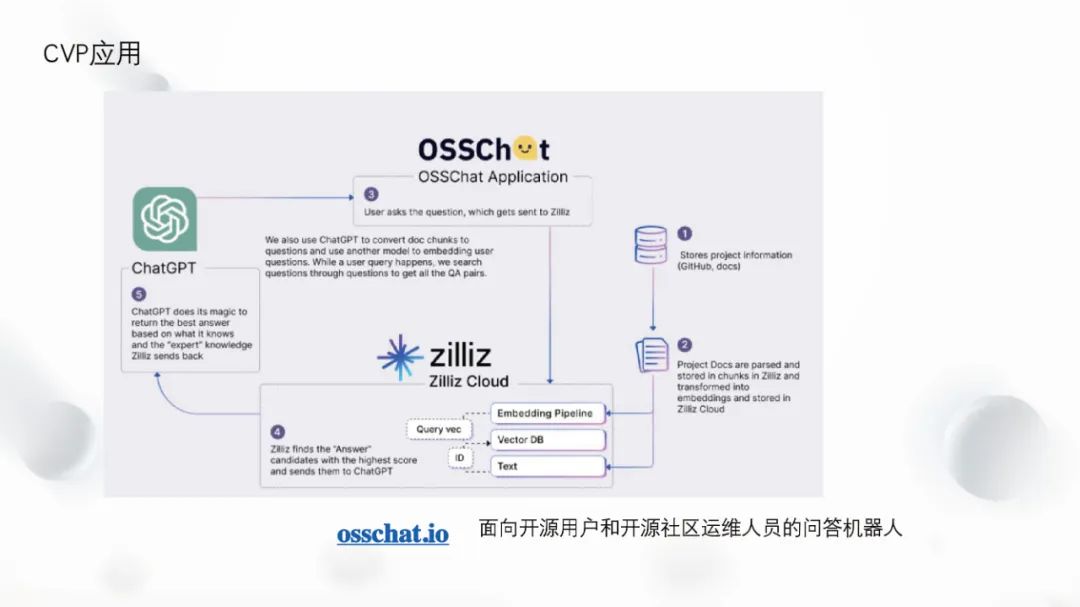
One of Zilliz’s demo products is OSSChat, a Q&A bot aimed at open-source users and community operators. This product helps answer repetitive questions in the open-source community, improving the efficiency of community operators. Using ChatGPT may encounter hallucination issues, while using a vector database can solve this problem as it can store the latest data.
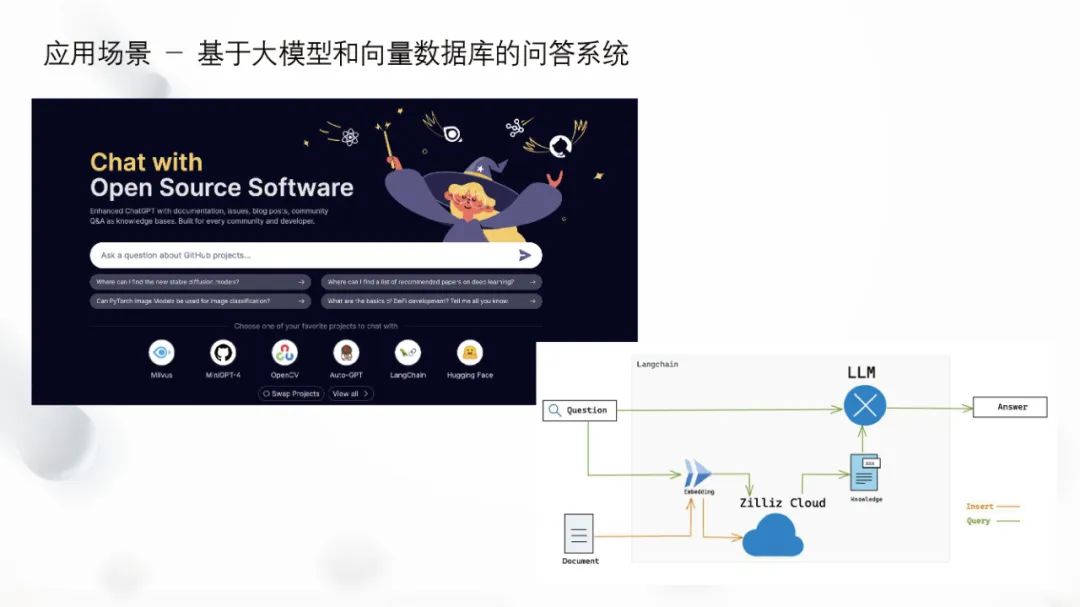
Refer to the architecture diagram below. Data can be obtained from the project’s official homepage or open-source community, and after loading the data, it can be stored in the vector database through embedding or other methods (original data can also be stored in object storage or relational databases). When users ask questions, the correct answer is first retrieved from the vector database and then fed as a prompt to ChatGPT, which infers a more accurate and effective answer to provide to the user. This process not only solves the hallucination problem but also ensures the authenticity and effectiveness of the data. The OSSChat project differs from ChatGPT in that it also provides information about the source of the answer, such as where it originated. This is because it stores the source of information in the vector database, allowing it to provide such information only with real and reliable data sources.
In the CVP architecture, LLMs can not only use ChatGPT. If there is a need for private deployment, such as when enterprises do not allow connections to the external network or have data security restrictions, open-source large models can be used for private deployment. However, to achieve better results, fine-tuning or retraining is necessary.

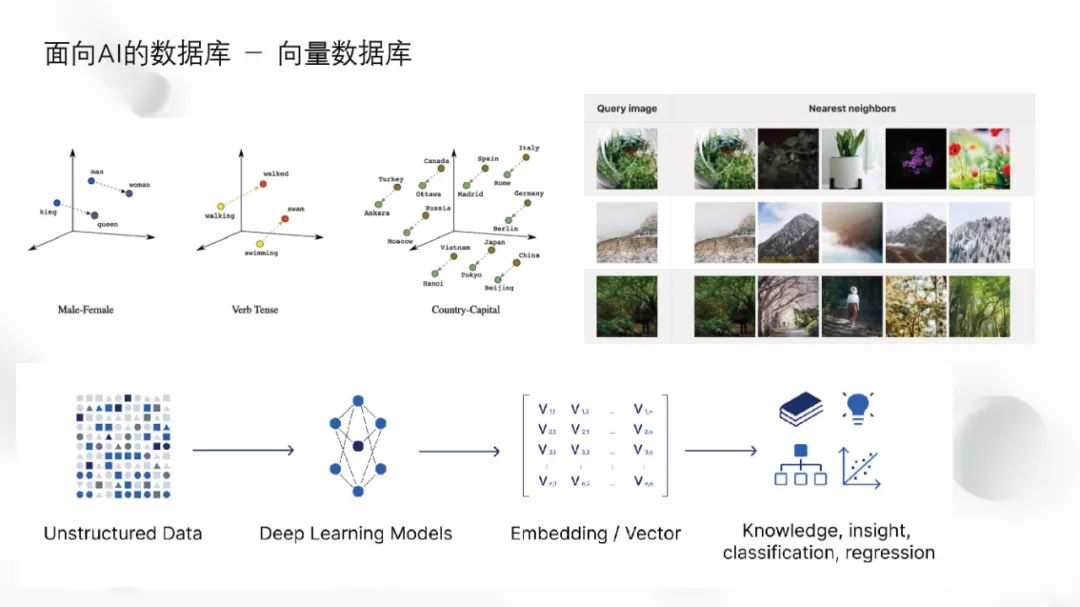
Vector databases treat vectors as first-class citizens, while traditional databases view them as supplements. Traditional database designs are unlikely to compromise for vectors, and vector retrieval differs from traditional database loads. Traditional databases focus on heavy I/O operations, emphasizing disk I/O, CPU utilization, and other metrics, while vector databases often need to consider CPU and GPU when designing computing nodes and storage.
Vectors were created to solve the problem of applying unstructured data in computers. Unstructured data is not a data structure that computers can inherently understand; people are more concerned about the semantic information rather than the bit length. Vectors are an effective representation method that can map unstructured data into a point in high-dimensional space. For example, a three-dimensional vector can map to a point in three-dimensional space.

02
1. Considerations for Building a Vector Database
-
When developing a database, it is essential to consider how to achieve low-cost storage and persistence.
-
As well as how to efficiently conduct ANN retrieval in the face of massive vectors.
-
It is also necessary to address issues such as concurrency control, data CRUD, mixed storage of metadata information and vector columns, departmental or business partitioning, permission management, GPU acceleration, and domestic support.
-
Once the database development is complete, monitoring, alerting, and continuous operation and maintenance are required to ensure the stability and reliability of the database.

2. Characteristics of Milvus
-
Cloud-native design: Adopting a distributed architecture, supporting high scalability, and stateless node design, it can be easily deployed in environments like k8s or docker. -
High performance: Compared to other competitors, Milvus has at least ten times the performance advantage in scenarios with large data volumes or high concurrency. The recently open-sourced VectorDBBench project code is fully open-source, and the dataset is also public. -
Pluggable engines: Providing a unified interface, users can choose different parameters to adapt to various indexes without needing to integrate different indexing technologies themselves. -
Integrated cloud: Supports deployment in environments like k8s or docker, and can also be deployed locally using docker, allowing for a quick experience with Milvus.
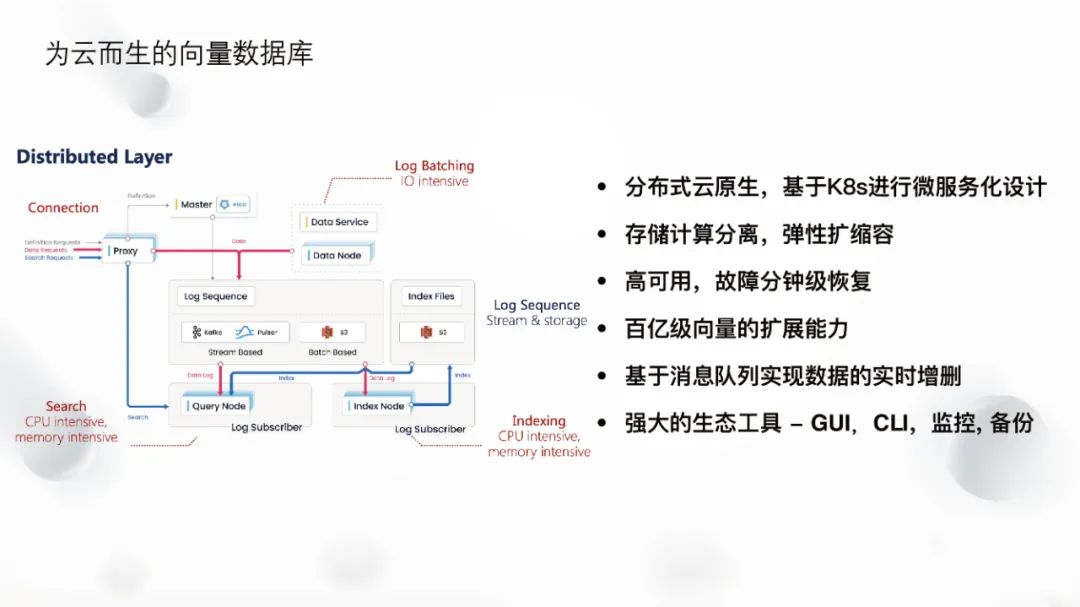
Refer to the Milvus architecture diagram below. The leftmost side represents the proxy node, the top represents the data node, the bottom represents the query node, and the right side represents the index node. Compared to single-node databases, distributed databases require more dependencies to meet the demands for cloud-native elasticity and scalability. Therefore, Milvus splits the nodes, allowing each node to easily achieve elastic scaling. For example, the data node can be turned off when there is no data being written at night and can be turned on during batch insertions to help users save costs on the cloud. The index node is separated because it needs to accumulate a certain amount of data before it can build an index, which is a batch processing task rather than a real-time processing task. In terms of storage, Milvus chooses to use object storage like S3 or MinIO for persistent data, while real-time data is stored in message queues currently supporting Pulsar and Kafka. In the upcoming 2.4 version, Milvus plans to try using a self-developed message queue to reduce user operation and maintenance costs.
3. Milvus + AIGC
Milvus has also been optimized for AIGC scenarios, such as supporting JSON and dynamic schema; providing partitioning capabilities; and offering disk indexing for users who are sensitive to costs but do not have high-performance requirements. Additionally, it supports offline import of massive documents to help solve cold start problems and integrates deeply with AI-related products such as LangChain, OpenAI, and AutoGPT. Milvus also provides clients in various languages, including Python, Go, Java, C#, Ruby, etc., encouraging contributors with experience in other languages to contribute clients.

4. Performance Comparison
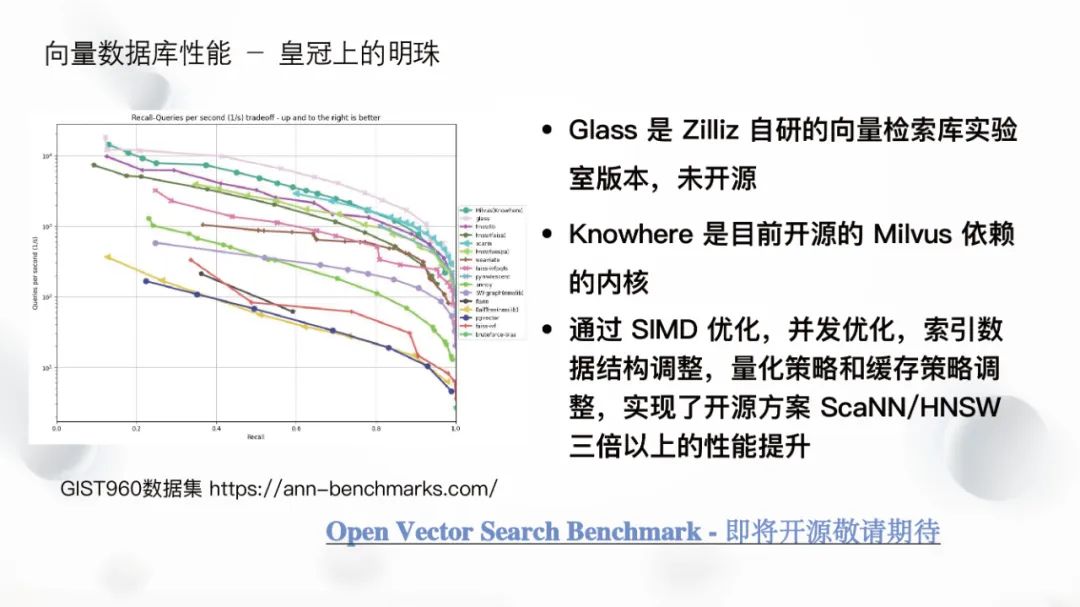
This section shows a performance comparison of ANN benchmarks, where the topmost Glass is a self-developed vector retrieval library experimental version that has not yet been open-sourced. Knowhere is the engine currently used by open-sourced Milvus, and there is a significant performance gap between the two. Furthermore, Milvus supports fast filtering of scalar or real-time inserted data that has not been indexed and deeply optimizes open-source libraries to solve practical engineering problems. Additionally, Milvus will conduct deep optimizations on open-source libraries, combining industrial practices to address issues like memory, thread scheduling, and thread safety.
03
Application Scenarios
1. User Identification

2. OSSChat
OSSChat is a product that helps the open-source community answer questions and generate code, aimed at solving hallucination problems of large models.
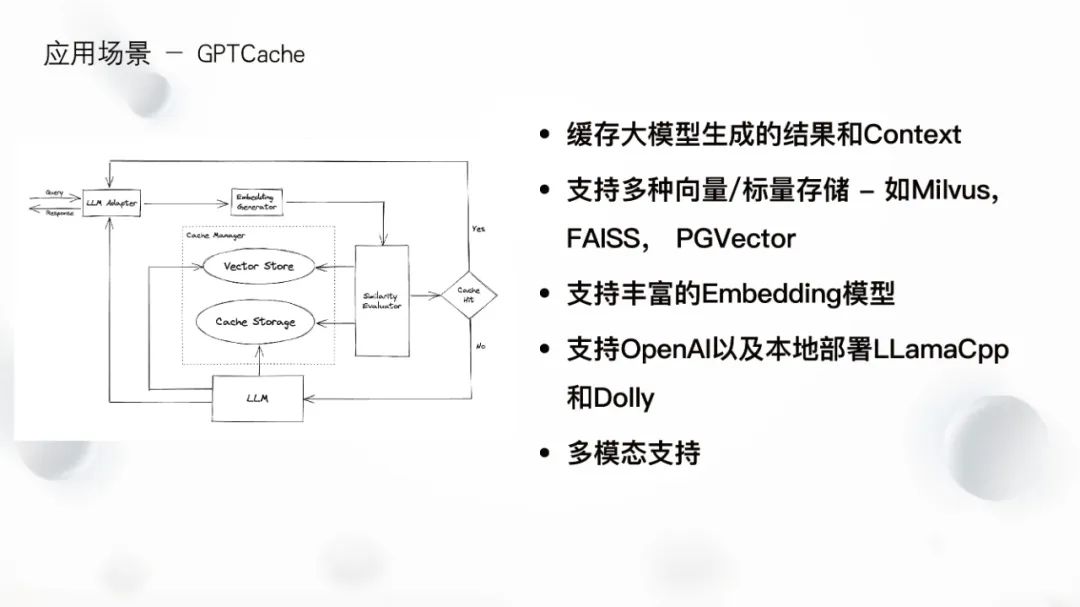
GPTCache is a product that helps users cache large model Q&A results, improving the inference speed of large models. Due to network limitations and instability, using OpenAI may encounter latency issues, while querying the vector database can provide faster latency. GPTCache supports connecting to Milvus, FAISS, and PGVector for vector/scalar data storage, and users can also contribute code to support other products.
4. Multi-Modal Retrieval
Multi-modal retrieval includes mixed queries such as text-to-image, image-to-video, video-to-text, and image-to-video. Some companies have already applied these technologies, such as Meta’s open-source Imagebind model, which can embed multi-modal databases into the same vector space, helping users perform multi-modal mixed queries. In addition to applications combined with large models, vector databases can also be applied in scenarios like recommendation, search, and security risk control, mainly for semantic retrieval and semantic recall. Many companies, including well-known internet companies like Kuaishou, Shopee, and Dewu, have practically applied these technologies.

04
Future Prospects of LLM + Vector Database
1. The Future of Vector Databases
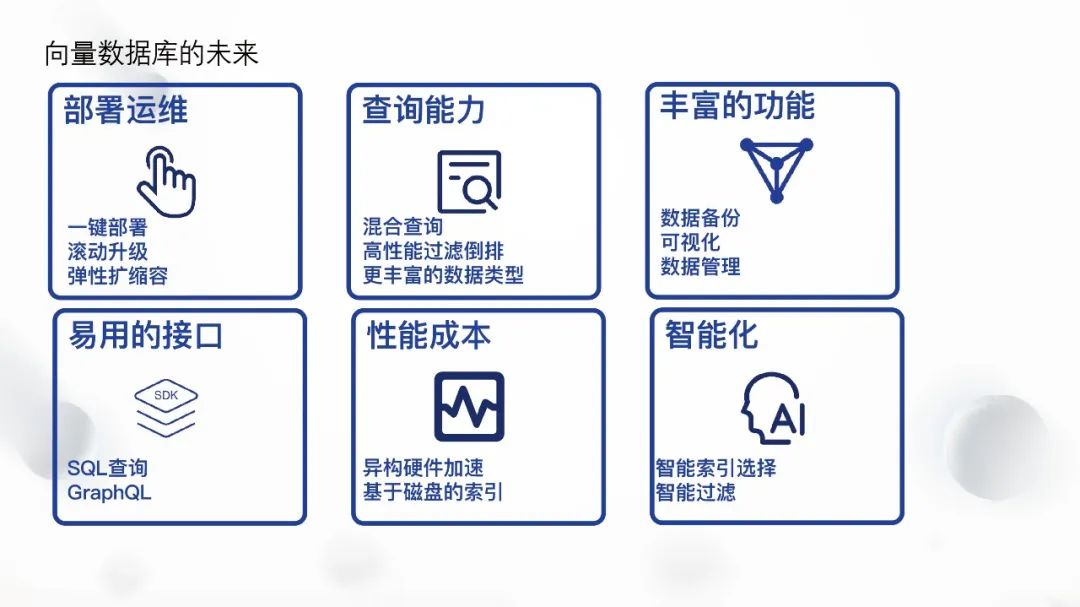
① Deployment and Operation Capabilities
Can help users save costs, but using vector databases requires certain thresholds, including deployment, operation, tuning, upgrading, and scaling issues. Solving these problems requires a dedicated team, which may require choosing cloud solutions or purchasing SaaS services.
② Query Capabilities:
More complex comprehensive scoring and ranking capabilities will meet user needs. For example, users can apply two models (like meta models) to two columns of vectors in text or images, and then perform mixed ranking based on the similarity of these two vectors.
③ Rich Features
Including data backup, visual data management, etc.
④ Query interfaces will also become richer
Including familiar SQL interfaces for a wide range of users.
⑤ Performance and Hardware Costs
Are key concerns for many users. To reduce costs and improve efficiency, different types of hardware can be used, such as GPU and ARM. By utilizing these advanced hardware, system performance can be enhanced, providing better services to users.
⑥ Through Intelligent Tuning
To improve system performance. In the commercial version, Zilliz provides an auto index feature that helps users automatically choose whether to use HNSW or IVF indexing, allowing users to focus only on recall rates and latency without worrying about the differences between various indexing parameters. This intelligent tuning capability will provide users with more efficient services, reducing maintenance costs.
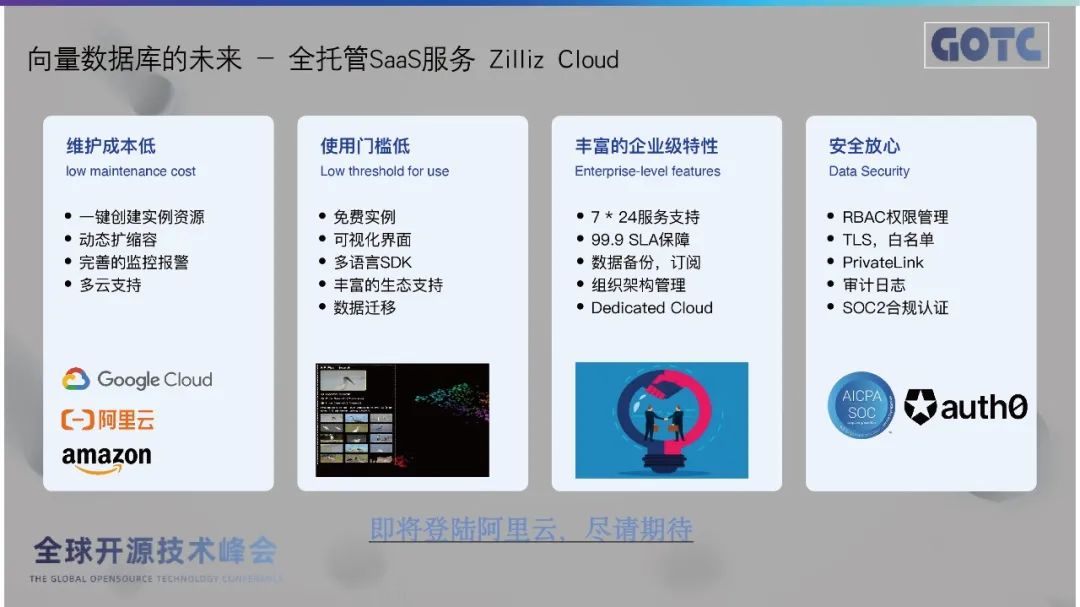
2. Zilliz Cloud Services
Zilliz Cloud services have launched on Alibaba Cloud, allowing domestic users to utilize them. It offers 7×24 hour service support, 99.9% SLA guarantee, data backup, subscription capabilities, and organizational management features. In terms of security, it provides RBAC permission management, whitelisting, and private link audit logs to ensure system security. Additionally, free instances are available on AWS and GCP, allowing users to quickly deploy vector databases during development to meet rapid validation needs.