

Alibaba Voice Recognition Technology Overview:
As a crucial component of artificial intelligence technology, voice recognition technology has become a core component influencing human-computer interaction. From voice interaction capabilities in various smart home IoT devices to applications in public services and smart government, voice recognition technology is impacting all aspects of people’s lives.
This article will comprehensively introduce the important model-end technologies in Alibaba Cloud’s voice recognition technology, hoping to engage in discussions with industry colleagues.
Authors:
Yan Zhijie, Xue Shaofei, Zhang Shiliang, Zheng Hao, Lei Ming
The acoustic model, language model, and decoder can be seen as the three core components of modern voice recognition systems. Although some researchers have recently attempted to build end-to-end voice recognition systems, the modern voice recognition systems that include acoustic models, language models, and decoders remain the most mainstream and widely used systems today. Among these, the acoustic model is primarily used to construct the probabilistic mapping relationship between the input speech and the output acoustic units; the language model is used to describe the probabilistic pairing relationships between different words, making the recognized sentences more like natural text; the decoder is responsible for filtering based on the acoustic unit probability values and scoring the language model in different combinations to ultimately obtain the most likely recognition result.
With the recent boom in deep learning, the field of voice recognition has also joined the wave of deep learning. By replacing the traditional HMM-GMM acoustic model with an HMM-DNN acoustic model, a relative improvement of over 20% can be achieved. Further improvements can also be obtained by overlaying the NN-LM language model on the traditional N-gram language model.
In this process, the acoustic model has garnered more attention from researchers because it is more suitable for deep neural network modeling. This article mainly introduces the acoustic model technology and language model technology used in Alibaba Cloud’s voice recognition technology, including the LC-BLSTM acoustic model, LFR-DFSMN acoustic model, and NN-LM language model. The LC-BLSTM is an improvement of the traditional BLSTM model, providing low latency while maintaining high accuracy; DFSMN is a novel non-recursive structured neural network that can model long-term correlations in signals like RNNs, while achieving more stable training effects and better recognition accuracy. The NN-LM language model is a further improvement based on the traditional N-gram language model.
Latency-Controlled BLSTM Model
The advantage of the DNN (fully connected DNN) model lies in its ability to extend the network’s abstract and modeling capabilities for complex data by increasing the number of layers and nodes in the neural network. However, the DNN model also has some shortcomings. For example, DNN typically uses frame-stacking to consider the influence of contextual information on the current speech frame, which is not the best method to reflect the correlations between speech sequences. Recurrent Neural Networks (RNNs) solve this problem to some extent by achieving the goal of utilizing the correlations between sequential data through self-connections of network nodes. Further research has proposed a Long Short-Term Memory network (LSTM-RNN), which can effectively alleviate the gradient explosion and gradient vanishing problems that simple RNNs face. Researchers have then extended LSTM by using Bidirectional Long Short-Term Memory networks (BLSTM-RNN) for acoustic model modeling, fully considering the impact of contextual information.
BLSTM models can effectively improve the accuracy of voice recognition, achieving a relative performance improvement of 15%-20% compared to DNN models. However, the BLSTM model also has two very important issues:
-
Sentence-level updates result in slower convergence speeds, and due to the large number of frame-by-frame calculations, the computational capabilities of parallel computing tools like GPUs cannot be effectively utilized, making training very time-consuming;
-
Due to the need to recursively compute the posterior probabilities of each frame for the entire sentence, decoding delays and real-time rates cannot be effectively guaranteed, making it difficult to apply in practical services.
To address these two issues, the academic community first proposed the Context-Sensitive-Chunk BLSTM (CSC-BLSTM) method, followed by the Latency Controlled BLSTM (LC-BLSTM) improved version, which more effectively alleviates these two problems. Based on this, we adopted an LC-BLSTM-DNN hybrid structure combined with multi-machine multi-card and 16-bit quantization training and optimization methods for acoustic model modeling, achieving a relative recognition error rate reduction of about 17-24% compared to the DNN model.
A typical LSTM node structure consists of three gates: input gate, forget gate, output gate, and one cell. The input, output nodes, and cell have connections with each gate; the input gate, forget gate, and cell also have connections, and the cell has self-connections. By controlling the states of different gates, better long-term and short-term information retention and error propagation can be achieved.
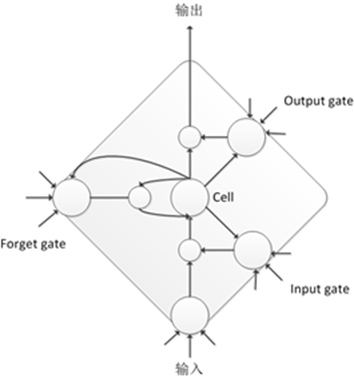
LSTM can be stacked layer by layer like DNN to form Deep LSTM. To better utilize contextual information, BLSTM can also be stacked layer by layer to construct Deep BLSTM. The structure is shown in the following figure, where the network has both forward and backward information transfer processes along the time axis. The computation of each time frame depends on the computation results of all previous and subsequent time frames. For speech signals, which are sequential data, this model fully considers the impact of context on the current speech frame, significantly improving the classification accuracy of phoneme states.
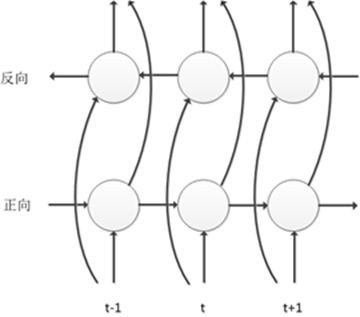
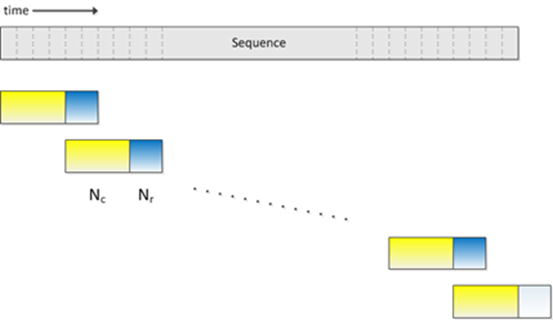
However, since the standard BLSTM models the entire sentence of speech data, there are issues with slow convergence, high latency, and low real-time rates during training and decoding. To address these drawbacks, we adopted Latency Controlled BLSTM. Unlike standard BLSTM, which uses entire sentences for training and decoding, Latency Control BLSTM employs a truncated BPTT-like update method and has its own characteristics in cell intermediate state processing and data usage, as shown in the following figure. During training, a small segment of data is used for updates, consisting of a center chunk and a rightward additional chunk, where the rightward additional chunk is only used for computing the cell’s intermediate state, and the error is only propagated in the center chunk.
The network moving forward in time uses the cell’s intermediate state from the end of the previous data segment as the initial state for the next data segment, while the network moving backward in time resets the cell’s intermediate state to zero at the start of each data segment. This method can greatly accelerate the convergence speed of the network and help achieve better performance. The data processing during the decoding phase is fundamentally the same as during training, with the difference being that the dimensions of the center chunk and rightward additional chunk can be adjusted according to needs and do not have to match the training configuration.
LFR-DFSMN Model
FSMN is a recently proposed network structure that effectively models long-term correlations in signals by adding some learnable memory modules to the hidden layers of feedforward fully-connected neural networks (FNN).
Compared to LC-BLSTM, FSMN can control latency more conveniently and often achieve better performance while requiring fewer computational resources. However, standard FSMN struggles to train very deep structures due to the vanishing gradient problem, leading to poor training results. Deep structure models have proven to have stronger modeling capabilities in many fields. Thus, we proposed an improved FSMN model called Deep FSMN (DFSMN).
Furthermore, we constructed an efficient real-time speech recognition acoustic model by combining low frame rate (LFR) technology, which can achieve over 20% relative performance improvement compared to the LFR-LCBLSTM acoustic model launched last year, while also achieving 2-3 times faster training and decoding, significantly reducing the computational resources needed for our system in practical applications.
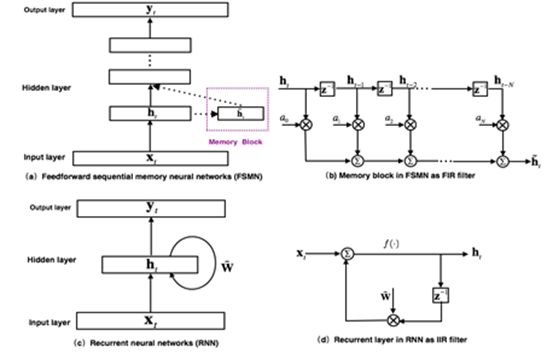
The originally proposed FSMN model structure is shown in the figure above (a). It is essentially a feedforward fully-connected neural network that models the long-term correlations of time-series signals by adding memory modules next to certain hidden layers in the network. The memory module uses a tapped delay structure as shown in the figure above (b) to encode the hidden layer outputs at the current moment and the previous N moments into a fixed representation.
The proposal of FSMN is inspired by the filter design theory in digital signal processing: any infinite impulse response (IIR) filter can be approximated by a high-order finite impulse response (FIR) filter.
From the perspective of filters, the recurrent layer of the RNN model shown in the figure above (c) can be seen as a first-order IIR filter as shown in (d). The memory module used by FSMN can be viewed as a high-order FIR filter. Thus, FSMN can effectively model the long-term correlations of signals like RNNs, while being easier and more stable to train compared to RNN due to the stability of FIR filters over IIR filters.
Depending on the choice of encoding coefficients for the memory module, FSMN can be divided into:
-
Scalar FSMN (sFSMN)
-
Vector FSMN (vFSMN)
sFSMN and vFSMN, as their names imply, use scalars and vectors as encoding coefficients for the memory module, respectively.
The FSMN discussed above only considers the influence of historical information on the current moment. We can call this a unidirectional FSMN. When we consider both historical and future information’s influence on the current moment, we can extend the unidirectional FSMN to obtain a bidirectional FSMN.
Compared to FNN, FSMN needs to use the memory module’s output as an additional input to the next hidden layer, which introduces extra model parameters. The more nodes included in the hidden layer, the more parameters are introduced. Research has proposed an improved FSMN structure based on low-rank matrix factorization, called Compact FSMN (cFSMN). The following figure shows the structure diagram of a cFSMN with memory modules included in the l-th hidden layer.

For cFSMN, a low-dimensional linear projection layer is added after the hidden layer, and the memory module is added on these linear projection layers. Furthermore, cFSMN modifies the encoding formula of the memory module by explicitly adding the current moment’s output to the memory module’s representation, allowing the memory module’s representation to be used as input to the next layer. This effectively reduces the model’s parameter count and speeds up network training.
The figure above illustrates the network structure diagram of the Deep-FSMN (DFSMN) we proposed, where the first box on the left represents the input layer, and the last box on the right represents the output layer. By adding skip connections (red boxes) between the memory modules of cFSMN, the output of the low-level memory modules will be directly added to the high-level memory modules. Thus, during training, the gradients of high-level memory modules will be directly assigned to low-level memory modules, overcoming the vanishing gradient problem caused by the network’s depth, allowing for stable training of deep networks.
Compared to the previous cFSMN, DFSMN has the advantage of being able to train very deep networks through skip connections. For the original cFSMN, since each hidden layer has already been split into a two-layer structure via low-rank matrix decomposition, a network containing 4 layers of cFSMN and 2 layers of DNN would have a total of 13 layers. Increasing the number of cFSMN layers would lead to even more layers, causing the training to experience gradient vanishing problems, leading to instability in training.
The DFSMN we proposed avoids the vanishing gradient problem in deep networks through skip connections, making training deep networks stable. It should be noted that these skip connections can be added not only between adjacent layers but also between non-adjacent layers. The skip connections can be linear or nonlinear transformations. In specific experiments, we can train DFSMN networks containing dozens of layers, achieving significant performance improvements compared to cFSMN.
From the initial FSMN to cFSMN, we can effectively reduce the model’s parameters and achieve better performance. Furthermore, based on cFSMN, the DFSMN we proposed can significantly enhance the model’s performance. The table below compares the performance of acoustic models based on BLSTM, cFSMN, and DFSMN on a 2000-hour English task.
|
Model |
BLSTM |
cFSMN |
DFSMN |
|
WER% |
10.9 |
10.8 |
9.4 |
From the table above, we can see that on a task of 2000 hours, the DFSMN model can achieve a relative 14% reduction in error rate compared to the BLSTM acoustic model, significantly improving the performance of the acoustic model.
Traditional acoustic models input the acoustic features extracted from each frame of speech signal, with each frame of speech typically lasting 10 ms, corresponding to a target output for each input speech frame signal. Recently, research has proposed a low frame rate (LFR) modeling scheme: by binding adjacent speech frames as input, it predicts an average target output for these speech frames. In specific experiments, three frames (or more) can be concatenated without losing model performance.
Thus, the input and output can be reduced to one-third or even more of the original, greatly enhancing the efficiency of acoustic scoring calculations and decoding during service in speech recognition systems. We constructed a speech recognition acoustic model based on LFR-DFSMN by combining LFR with the DFSMN proposed above, ultimately determining to use a DFSMN with 10 layers of cFSMN and 2 layers of DNN as the acoustic model, with input and output adopting LFR, reducing the frame rate to one-third of the original. The recognition results compared to the best baseline of LCBLSTM we launched last year are shown in the table below.

By combining LFR technology, we can achieve a threefold acceleration in recognition. As seen in the table above, in practical industrial-scale applications, the LFR-DFSMN model can achieve a 20% reduction in error rate compared to the LFR-LCBLSTM model, demonstrating better modeling characteristics for large-scale data.
NN-LM Language Model
A language model, as the name suggests, is a model that models language. Language expression can be viewed as a sequence of characters, where different combinations of character sequences represent different meanings, and the unit of characters can be words or phrases. The task of a language model can be seen as estimating the probability of a given character sequence or estimating the rationality of that sequence.
P(Shanghai’s workers have strength) > P(Shanghai’s workers eat rotten food have strength)
Taking this sentence as an example: should it be “workers have strength” or “workers eat rotten food have strength”? We can easily judge that the probability of the left sentence is slightly higher. Therefore, we hope that through language model modeling, we can provide a probability distribution that aligns with human expectations. For example, the probability of “workers” is greater than that of “eating rotten food”.
Traditional N-gram models based on statistical word frequencies simplify the model structure and computation through the Markov assumption, calculating through counting methods and using lookup methods. With over thirty years of usage history, they have advantages of easy estimation, stable performance, and quick computation. However, their Markov assumption forces truncation of modeling length, preventing the model from modeling longer histories; the word frequency-based estimation method also makes the model insufficiently smooth, leading to underestimation of low-frequency vocabulary. With the third rise of neural networks (NNs), people have begun to attempt to use NNs for language model modeling.
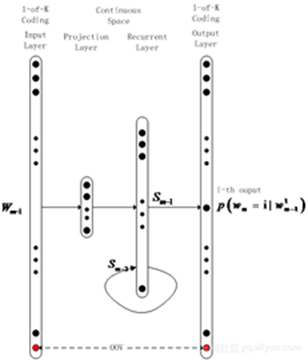
A typical modeling structure is recurrent neural networks (RNNs), whose recursive structure can theoretically model infinite-length sequences, compensating for the N-gram models’ shortcomings in sequence length modeling; moreover, the fully connected structure between layers ensures smooth modeling. Additionally, to enhance model performance, researchers have also attempted to improve the basic RNN’s modeling capabilities using Long Short-Term Memory (LSTM) structures, further enhancing model performance.
When used in large-scale language modeling systems, NN faces some challenges, such as increased storage and computation due to large vocabulary. The vocabulary in actual online systems is often quite large, and as the vocabulary increases, the storage and computation of basic RNN structures can explode geometrically.
To address this, researchers have made some attempts, with vocabulary size reduction being the most direct solution. A classic method is vocabulary clustering, which can significantly reduce vocabulary size but often leads to some performance degradation. A more direct idea is to filter out low-frequency vocabulary, which still results in performance degradation. An improved strategy is based on the realization that the main constraint on speed performance is the output layer nodes. Since the input layer nodes are large, using a projection layer can effectively resolve this issue. Thus, the input layer adopts a large dictionary, while only suppressing the output layer vocabulary, minimizing loss while filtering out low-frequency vocabulary, which is also beneficial for fully training model nodes, often leading to slight performance improvements.
Vocabulary compression can enhance modeling performance and reduce computation and storage, but only to a certain extent; it cannot be compressed indefinitely. How to continue reducing computational load remains an issue. Some methods have been proposed. For instance, LightRNN, by utilizing a clustering approach similar to embedding, maps the vocabulary to a real-valued matrix, requiring only the sum of the rows and columns of the matrix for actual output, significantly reducing computation.
One reason for the high computational load caused by many nodes is the softmax output, which requires calculating the sum of all nodes to obtain the denominator. If this denominator can be kept constant, during actual computation, only the necessary nodes are calculated, significantly speeding up the testing phase.
This leads to methods related to regularization terms, such as Variance Regularization. If the training speed is acceptable, this method can significantly enhance forward computation speed without compromising model correctness. If training speed is also a concern, sampling methods can be considered, such as NCE, Importance Sampling, Black Sampling, etc. Essentially, this means not computing all nodes during training; only the positive samples (those with labels of 1) and a portion of negative samples obtained through some distribution sampling are computed, avoiding slow calculations caused by high outputs. The speed improvement is quite notable.
Gaining Custom Model Capabilities from Alibaba Cloud
Imagine a developer working on an intelligent phone customer service or intelligent meeting system needing to integrate voice recognition (converting speech to text) capabilities into their system. They might face a dilemma:
One option is to start from scratch to learn how to do voice recognition, which could take a significant amount of time and money. After all, in the realm of artificial intelligence, major internet giants invest vast amounts of human, material, and financial resources, requiring a considerable amount of time to accumulate technology;
The second option is to use the out-of-the-box, one-size-fits-all voice recognition interfaces provided by these giants on the internet. While this saves time, the accuracy of converting speech to text is a matter of luck since these giants are also busy and cannot focus on optimizing the scenarios you care about.
So the question arises: is there a way to achieve the best voice recognition effect in business with minimal investment? The answer is yes.
Alibaba Cloud, leveraging the industry-leading voice interaction intelligence from DAMO Academy, breaks the supply model of traditional voice technology providers, allowing ordinary developers to use the self-learning voice recognition technology provided by Alibaba Cloud in the cloud computing era to obtain a complete set of means to customize and optimize the business scenarios they care about. Alibaba Cloud enables developers to stand on the shoulders of giants, achieving mastery of voice recognition system applications from novice to expert in a short time through self-controlled self-learning, easily attaining industry-leading voice recognition accuracy in the scenarios they care about. This is a new supply model for voice recognition technology in the cloud computing era.
Like other artificial intelligence technologies, the key to voice recognition technology lies in three aspects: algorithms, computing power, and data. Alibaba Cloud, relying on DAMO Academy’s voice interaction intelligence, has continuously evolved its “algorithm” at the forefront of the world in recent years, and has recently open-sourced the latest research results, the DFSMN acoustic model, for researchers worldwide to reproduce the best current results and continue to improve.
Regarding “computing power,” this is inherently the strong point of cloud computing. Based on the Alibaba Cloud ODPS-PAI platform, we have built a mixed training and service platform optimized for voice recognition applications using CPU/GPU/FPGA/NPU, serving massive voice recognition requests on Alibaba Cloud daily. In terms of “data,” we provide out-of-the-box scenario models trained on massive data, including e-commerce, customer service, government affairs, mobile input, and more.
It should also be noted that in specific landing scenarios, there are often some very specific, domain-related “sayings” that need to be recognized. Many times, specific phrases like “clastic rock lithology strata” or “marine carbonate rock” pose challenges for general scenario models’ recognition rates. To achieve the best accuracy in specific scenarios that developers care about, out-of-the-box models generally require some customization and optimization work. Traditionally, such customization is done through voice technology service providers, which has obvious shortcomings in terms of cost, cycle, and controllability.
Alibaba Cloud’s voice customization “self-learning” platform service can provide various means to allow developers to fully control model customization, optimization, and launch work in a very short time and at a low cost. Alibaba Cloud’s innovative tool platform and service technology, relying on robust infrastructure, make large-scale customized voice services feasible in the context of cloud computing. Developers need not concern themselves with the backend technology and service details; they can simply use Alibaba Cloud’s easy-to-use “self-learning” tools, leveraging scenario knowledge and data to achieve the optimal effect in specific scenarios and continuously iterate and improve as needed.
Alibaba Cloud’s intelligent voice self-learning platform has the following advantages:
-
Easy: The intelligent voice self-learning platform provides a revolutionary one-click self-service voice optimization solution, significantly lowering the threshold for voice intelligence optimization, allowing non-technical business personnel to significantly improve their business recognition accuracy.
-
Fast: The self-learning platform can complete the optimization testing and launch of business-specific customized models within minutes, supporting real-time optimization of business-related hot words, changing the traditional custom optimization delivery time from weeks or even months to a matter of minutes.
-
Accurate: The optimization effects of the self-learning platform have been fully validated in many internal and external partner projects, with many projects solving not only usability issues but also outperforming competitors who used traditional optimization methods.
For example, developers can use various “self-learning” means to customize models in their areas of concern:
a) Business Hot Word Customization
In many specific scenarios, there is a requirement to rapidly enhance the recognition ability for specific words (note: including two modes, mode one where other words are easily recognized as specific words; mode two where specific words are easily recognized as other words). By employing real-time hot word loading technology, the recognition ability for hot words can be strengthened in real-time scenarios through different settings.
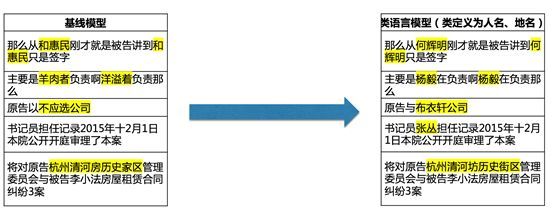
b) Class Hot Word Customization
Often, the same pronunciation and attributes require different recognition effects in different contexts. Contact names and place names are typical cases. For different friends, we must accurately recognize the corresponding names “Zhang Yang” and “Zhang Yang.” Similarly, if “Anxi” and “Anxi” are misrecognized, it could cause significant navigation issues. The intelligent voice self-learning platform believes that “everyone deserves respect,” providing customization capabilities for contact names and place names, “ensuring that no road is hard to recognize.”
c) Business-Specific Model Customization
Users can quickly generate a customized model within the relevant industry by inputting corresponding industry-related texts, such as basic introductions of the industry or company, customer service chat records, commonly used terms, and proper nouns. The entire customization process requires no manual intervention from the user.
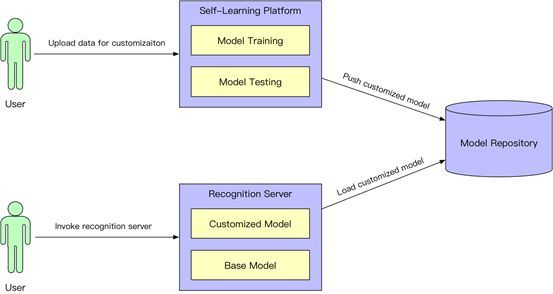
Through these means, Alibaba Cloud allows developers to focus on their vertical domain knowledge and data collection without worrying about the algorithms and engineering service details of voice technology, realizing a new cloud supply model for voice technology that benefits a wide range of developers and their business outcomes.

You Might Also Like
Click the image below to read

Alibaba added 1.2 billion lines of code last year; will open-source self-developed scientific computing engine and graph learning framework; pedestrian re-identification algorithm wins world first | Zhou Botong

How to “realistically restore” a data center? Alibaba cooperated with NTU to create an industrial-grade precision simulation sandbox
 Report! This group of Alibaba engineers is secretly raising pigs
Report! This group of Alibaba engineers is secretly raising pigs

Follow “Alibaba Technology”
Keep up with cutting-edge technology trends