


Large Language Models (LLMs) have achieved outstanding performance in driving text-based agents, endowing them with human-like decision-making and reasoning capabilities. Meanwhile, an emerging research trend focuses on extending these LLM-driven agents into the multimodal domain. This extension enables agents to interpret and respond to diverse multimodal user queries, thus handling more complex and nuanced tasks. In this paper, we provide a systematic review of LLM-driven multimodal agents, referred to as Large Multimodal Agents (LMAs). First, we introduce the fundamental components involved in developing LMAs and categorize existing research into four distinct types. Next, we review collaborative frameworks that integrate multiple LMAs, enhancing collective efficacy. A key challenge in this field is the diverse evaluation methods used in existing research, which hinder effective comparisons among different LMAs. Therefore, we compile these evaluation methods and establish a comprehensive framework to bridge the gap. This framework aims to standardize evaluations and facilitate more meaningful comparisons. In our review, we highlight the wide-ranging applications of LMAs and propose possible future research directions. A list of the latest resources can be found at https://github.com/jun0wanan/awesome-large-multimodal-agents.
Paper link: https://arxiv.org/abs/2402.15116

An agent is a system that can perceive its environment and make decisions based on those perceptions to achieve specific goals [56]. While early agents [35, 50] were proficient in narrow domains, they often lacked adaptability and generalization capabilities, highlighting significant differences from human intelligence. Recent advances in Large Language Models (LLMs) have begun to bridge this gap, enhancing their capabilities in command interpretation, knowledge assimilation [36, 78], and mimicking human reasoning and learning [21, 66]. These agents utilize LLMs as their primary decision-making tools and further enhance critical human-like features such as memory. This enhancement enables them to handle various natural language processing tasks and interact with the environment using language [40, 38].
However, real-world scenarios often involve information beyond text, incorporating multiple modalities, particularly emphasizing visual aspects. Therefore, the next evolutionary step for LLM-driven agents is to acquire the ability to process and generate multimodal information, especially visual data. This capability is crucial for these agents to evolve into more powerful AI entities that reflect human-level intelligence. Agents equipped with this capability are referred to as Large Multimodal Agents (LMAs) in our paper. Generally, they face challenges that are more complex than those of language-only agents. For example, in web searching, an LMA first needs to input user requirements and search for relevant information through a search bar. Then, it navigates to web pages through mouse clicks and scrolling, browsing real-time web content. Finally, the LMA needs to process multimodal data (e.g., text, video, and images) and perform multi-step reasoning, including extracting key information from web articles, video reports, and social media updates and integrating this information to respond to user queries. We note that existing LMA research has been conducted in isolation, thus necessitating further advancement in the field by summarizing and comparing existing frameworks. Several reviews related to LLM-driven agents [60, 42, 49] exist, yet few focus on the multimodal aspect.
In this paper, we aim to fill this gap by summarizing the main developments of LMAs. First, we introduce the core components (§2) and propose a new taxonomy of existing research (§3), followed by a further discussion of existing collaborative frameworks (§4). Regarding evaluation, we outline existing methods for assessing LMA performance and subsequently provide a comprehensive summary (§5). The application section offers a detailed overview of the wide-ranging practical applications of multimodal agents and their related tasks (§6). We conclude this work by discussing and suggesting possible future directions for LMAs to provide useful research guidance.
Core Components of LMAs
In this section, we detail the four core elements of LMAs, including perception, planning, action, and memory.
Perception. Perception is a complex cognitive process that enables humans to gather and interpret information from their environment. In LMAs, the perception component primarily focuses on processing multimodal information from diverse environments. As shown in Table 1, LMAs in different tasks involve various modalities. They need to extract key information from these different modalities that is most beneficial for task completion, thereby facilitating more effective planning and execution of tasks.
Early research on processing multimodal information [57, 43, 70, 9] often relied on simple correlational models or tools to convert images or audio into text descriptions. However, this conversion method often generates a large amount of irrelevant and redundant information, especially for complex modalities (e.g., video). With input length limitations, LLMs often face challenges in effectively extracting relevant information needed for planning. To address this issue, recent studies [71, 47] have introduced the concept of subtask tools designed to handle complex data types. In real-world-like environments (i.e., open-world games), [51] proposed a new method for processing non-textual modal information. This method first extracts key visual vocabulary from the environment and then uses the GPT model to further refine these vocabularies into a series of descriptive sentences. When LLMs perceive visual modalities in the environment, they use these modalities to retrieve the most relevant descriptive sentences, effectively enhancing their understanding of the surrounding environment.
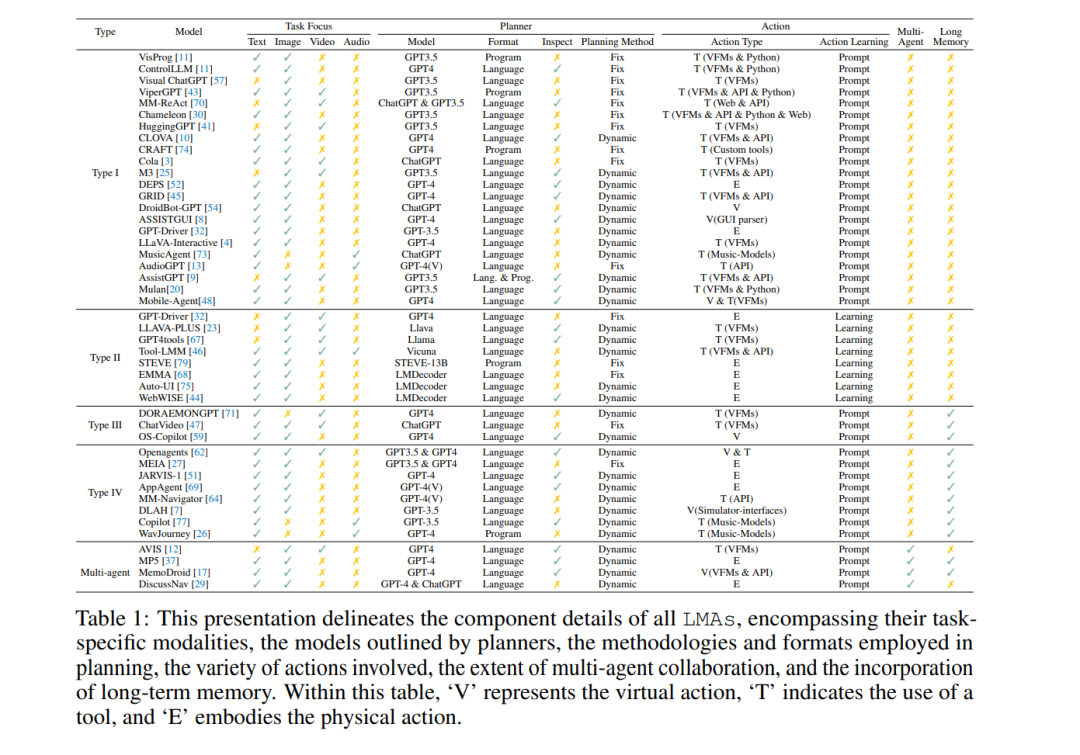
Planning. Planners play a core role in LMAs similar to the functions of the human brain. They are responsible for in-depth reasoning regarding the current task and formulating corresponding plans. Compared to language-only agents, LMAs operate in more complex environments, making reasonable planning more challenging. We detail planners from four perspectives: model, format, checking and reflection, and planning methods:
-
Model: As shown in Table 1, existing research employs different models as planners. Among them, the most popular are GPT-3.5 or GPT-4 [43, 41, 9, 30, 57, 51]. However, these models are not publicly available, so some studies have begun to turn to open-source models like LLaMA [67] and LLaVA [23], which can directly handle information from multiple modalities, enhancing their ability to formulate more optimized plans.
-
Format: It refers to how planners formulate plans. As shown in Table 1, there are two formatting methods. The first is natural language. For example, in [41], the obtained planning content is “The first thing I do is use OpenCV’s openpose control model to analyze the boy’s posture in the image…”, where the formulated plan is to use “OpenCV’s openpose control model”. The second is in programmatic form, such as “image_patch = ImagePatch(image)” [43], which calls the ImagePatch function to execute the planning. There are also mixed forms, as in [9].
-
Checking and Reflection: For LMAs, continuously formulating meaningful and task-completing plans in complex multimodal environments is challenging. This component aims to enhance robustness and adaptability. Some research methods [51, 52] store successful experiences in long-term memory, including multimodal states, to guide planning. During the planning process, they first retrieve relevant experiences to help planners reflect thoughtfully to reduce uncertainty. Additionally, [12] utilizes plans formulated by humans executing the same task under different states. When encountering similar states, planners can refer to these “standard answers” for consideration, thus formulating more reasonable plans. Furthermore, [71] employs more complex planning methods, such as Monte Carlo, to expand the planning search space and find the best planning strategy.
-
Planning Methods: Existing planning strategies can be divided into two types: dynamic planning and static planning, as shown in Table 1. The former [57, 43, 70, 30, 41] refers to breaking down the goal into a series of sub-plans based on initial inputs, similar to chain of thought (CoT) [80], where the plan is not restructured even if errors occur during the process; the latter [9, 25, 51, 71] means that each plan is formulated based on current environmental information or feedback. If an error is detected in the plan, it will revert to the original state for re-planning [12].
Action. The action component in multimodal agent systems is responsible for executing the plans and decisions made by the planner. It translates these plans into concrete actions, such as using tools, physical movements, or interacting with interfaces, ensuring that the agents can accurately and efficiently achieve their goals and interact with the environment. Our discussion focuses on two aspects: types and methods.
Memory. Early research indicates that memory mechanisms play a crucial role in the operation of general agents. Similar to humans, memory in agents can be divided into long-term memory and short-term memory. In simple environments, short-term memory is sufficient for agents to handle the task at hand. However, in more complex and realistic settings, long-term memory becomes vital. In Table 1, we can see that only a few LMAs contain long-term memory. Unlike language-only agents, these multimodal agents need to have long-term memory capable of storing information across various modalities. In some studies [71, 47, 69, 7], all modalities are converted into text format for storage. However, in [51], a multimodal long-term memory system was proposed, specifically designed to archive previous successful experiences. Specifically, these memories are stored in key-value pairs, where the key is the multimodal state, and the value is the successful plan.
Classification of LMAs
In this section, we present the classification of LMAs by categorizing existing research into four types.
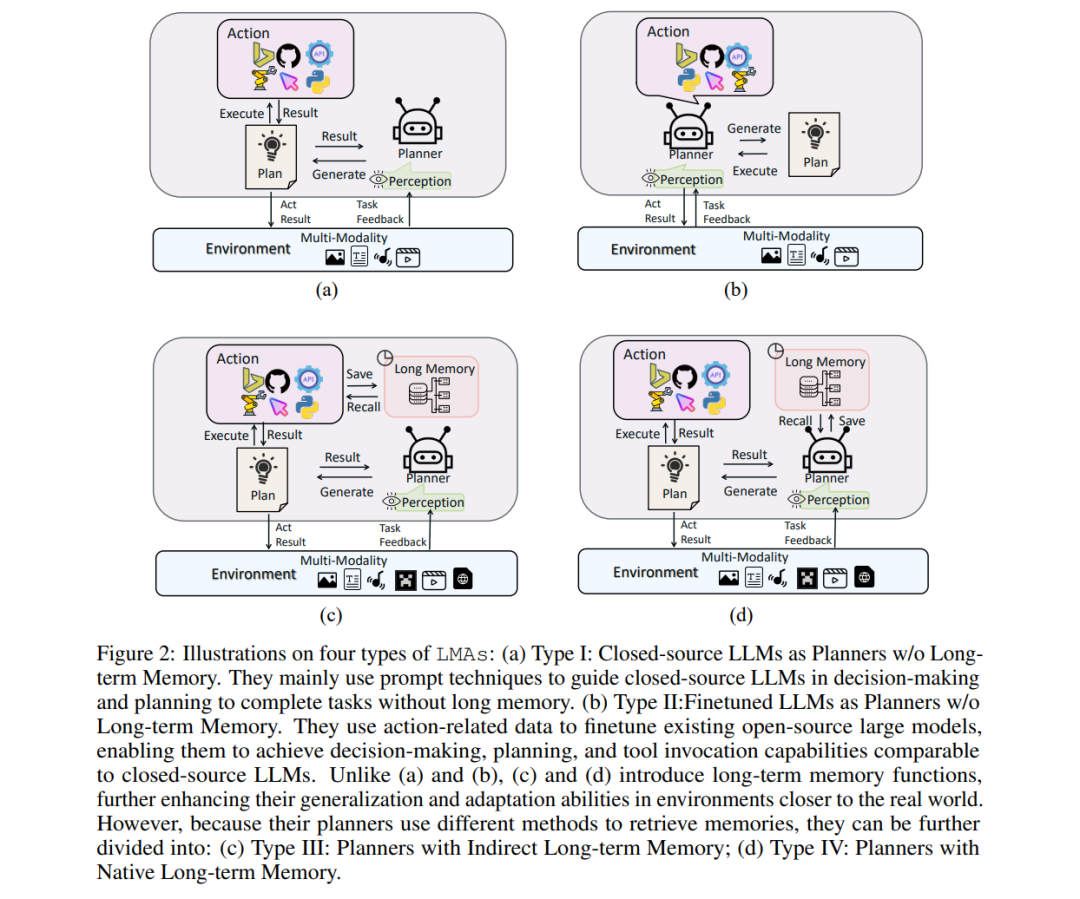
Type I: Closed-source LLMs as planners without long-term memory. Early studies [11, 43, 57, 41, 9, 25] utilized prompts to leverage closed-source large language models (e.g., GPT-3.5) as planners for reasoning and planning, as shown in Figure 2(a). Depending on specific environmental or task requirements, the execution of these plans may be carried out through downstream toolkits or by interacting directly with the environment using physical devices (e.g., mouse or robotic arms). This type of LMAs typically operates in simpler settings, undertaking traditional tasks such as image editing, visual localization, and visual question answering (VQA).
Type II: Fine-tuned LLMs as planners without long-term memory. This type of LMAs involves collecting multimodal instruction-following data or using self-guidance to fine-tune open-source large language models (e.g., LLaMA) [67] or multimodal models (e.g., LLaVA) [23, 46], as shown in Figure 2(b). This enhancement not only allows the model to serve as the central “brain” for reasoning and planning but also to execute these plans. The environments and tasks faced by Type II LMAs are similar to those of Type I, typically involving traditional visual or multimodal tasks. Compared to typical scenarios characterized by relatively simple dynamics, closed environments, and basic tasks, LMAs in open-world games like Minecraft need to execute precise planning in dynamic contexts, handle high-complexity tasks, and engage in lifelong learning to adapt to new challenges. Therefore, based on Types I and II, Types III and IV LMAs integrate memory components, demonstrating significant potential in evolving into general agents in the field of artificial intelligence.
Type III: Planners with indirect long-term memory. For Type III LMAs [71, 47], as shown in Figure 2(c), LLMs serve as central planners equipped with long-term memory. These planners access and retrieve long-term memory by calling relevant tools, utilizing these memories for enhanced reasoning and planning. For example, the multimodal agent framework developed in [71] is tailored for dynamic tasks (e.g., video processing). This framework consists of planners, toolkits, and a task-related memory repository that records spatial and temporal attributes. Planners use specialized subtask tools to query the memory repository for spatiotemporal attributes related to video content, enabling them to infer task-relevant spatiotemporal data. Each tool is stored within the toolkit, specifically designed for a particular type of spatiotemporal reasoning and acts as an executor within the framework.
Type IV: Planners with native long-term memory. Unlike Type III, Type IV LMAs [51, 37, 7, 76] are characterized by LLMs directly interacting with long-term memory, bypassing the need to access long-term memory using tools, as shown in Figure 2(d). For example, the multimodal agent proposed in [51] demonstrates proficiency in completing over 200 different tasks in the open-world context of Minecraft. In their multimodal agent design, the interactive planner combines multimodal foundational models with LLMs, first converting the multimodal input from the environment into text. The planner further adopts a self-checking mechanism to predict and evaluate each step in execution, actively discovering potential flaws and rapidly correcting and optimizing plans based on environmental feedback and self-explanation without additional information. Furthermore, this multimodal agent framework includes a novel multimodal memory. Successful task plans and their initial multimodal states are stored, with planners retrieving similar states for new tasks from this database, using accumulated experiences to achieve faster and more efficient task completion.
Multi-Agent Collaboration
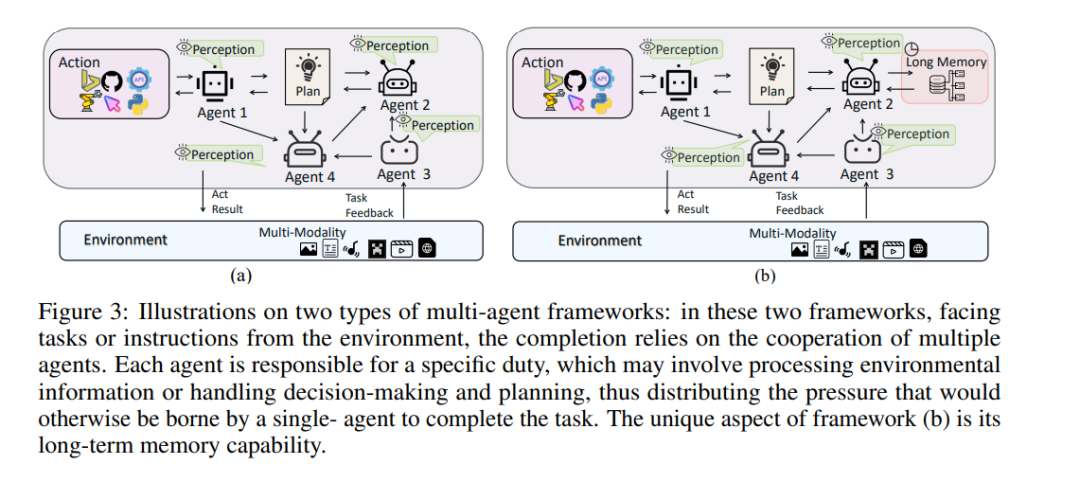
In this section, we further introduce the collaborative framework of LMAs that goes beyond the discussion of individual agents.
As shown in Figures 3(a)(b), these frameworks adopt multiple LMAs working in coordination. The key difference between the two frameworks lies in whether they possess memory components, but their fundamental principles are consistent: multiple LMAs have different roles and responsibilities, allowing them to coordinate actions to achieve a common goal. This structure alleviates the burden on a single agent, thereby improving task performance [12, 37, 17, 29].
For example, in Table 1, the multimodal agent framework in [37] introduces a perceiver agent to perceive the multimodal environment composed of large multimodal models. An agent designated as a patroller is responsible for multiple interactions with the perceiver agent, conducting real-time checks and feedback on the perceived environmental data to ensure the accuracy of current plans and actions. When execution failures are detected or reevaluation is needed, the patroller provides relevant information to the planner, prompting a reorganization or update of the action sequence under the sub-goals. The MemoDroid framework [17] includes several key agents that work together to automate mobile tasks. The exploration agent is responsible for the offline analysis of the target application interface, generating a potential subtask list based on UI elements, which is then stored in application memory. In the online execution phase, the selection agent determines which specific subtask to execute from the exploration set based on user commands and the current screen state. The inference agent further identifies and completes the underlying action sequences required for the selected subtask by prompting the LLM. Meanwhile, when encountering tasks similar to previously learned tasks, the recall agent can directly invoke and execute corresponding subtasks and action sequences from memory.
Conclusion
In this review, we provide a comprehensive overview of the latest research on Large Multimodal Agents (LMAs) driven by Large Language Models (LLMs). We first introduce the core components of LMAs (i.e., perception, planning, action, and memory) and categorize existing research into four categories. Next, we compile existing methods for evaluating LMAs and design a comprehensive evaluation framework. Finally, we focus on a series of current and significant application scenarios within the field of LMAs. Despite significant progress, this field still faces many unresolved challenges and has considerable room for improvement. Based on the reviewed progress, we ultimately highlight several promising directions:
-
Regarding frameworks: Future frameworks for LMAs may evolve from two different perspectives. From the perspective of a single agent, development may progress towards creating more unified systems. This involves planners interacting directly with multimodal environments [71], utilizing a comprehensive set of tools [30], and directly operating memory [51]; from the perspective of multiple agents, advancing effective coordination among multiple multimodal agents to execute collective tasks becomes a key research direction. This includes fundamental aspects such as collaboration mechanisms, communication protocols, and strategic task allocation.
-
Regarding evaluation: There is an urgent need for a systematic and standardized evaluation framework in this field. An ideal evaluation framework should encompass a range of evaluation tasks [58, 16], varying from simple to complex, each having significant relevance and practicality for humans. It should contain clear and insightful evaluation metrics, carefully designed to comprehensively and non-redundantly assess the diverse capabilities of LMAs. Moreover, the datasets used for evaluation should be meticulously curated to closely reflect real-world scenarios.
-
Regarding applications: The potential applications of LMAs in the real world are vast, providing solutions to previously challenging problems for traditional models, such as web browsing. Furthermore, the intersection of LMAs with the human-computer interaction domain [54, 44] represents an important direction for future applications. Their ability to process and understand information from different modalities enables them to perform more complex and nuanced tasks, thereby enhancing their practicality in real-world scenarios and improving interactions between humans and machines.

Scan the QR code to add the assistant WeChat
About Us
